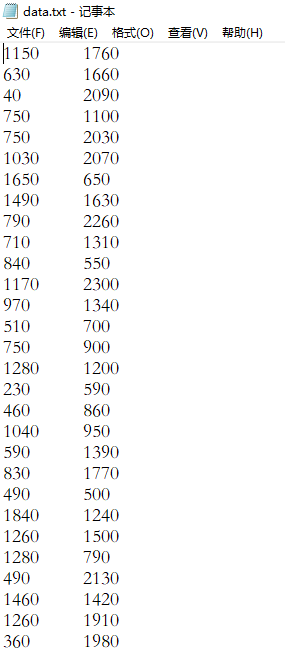python 强化学习求解TSP(一):Qlearning求解旅行商问题TSP(提供Python代码) 本文介绍: Q-learning是一种强化学习算法,用于解决基于奖励的决策问题。它是一种无模...
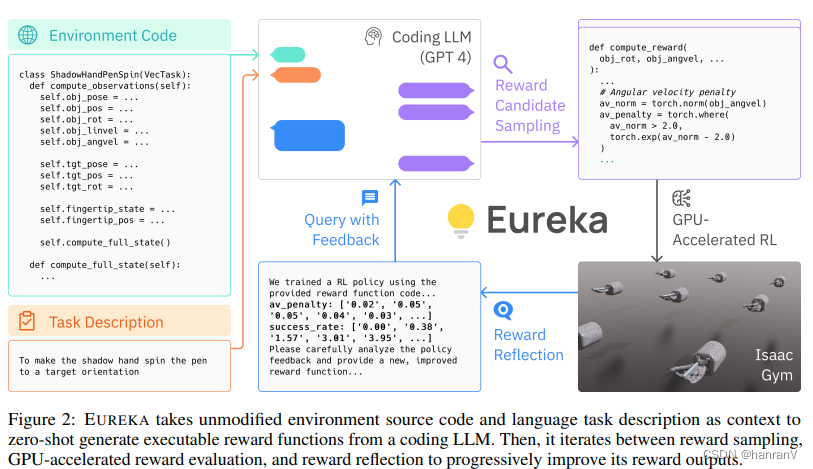
互联网 EUREKA: HUMAN-LEVEL REWARD DESIGN VIACODING LARGE LANGUAGE MODELS 本文介绍: 大型语言模型(LLMs)在顺序决策任务中作为高级语义规划器表现出色。然而,利用它...