资源下载地址:https://download.csdn.net/download/sheziqiong/88490254
资源下载地址:https://download.csdn.net/download/sheziqiong/88490254
分类技术—二分网络上的链路预测
一、实验内容
基于网络结构的链路预测算法被广泛的应用于信息推荐系统中。算法不考虑用户和产品的内容特征,把它们看成抽象的节点,利用用户对产品的选择关系构建二部图。为用户评估它从未关注过的产品,预测用户潜在的消费倾向。
二、设计与分析
实验给定的数据类型为.csv,则使用 Pandas 库进行数据处理。
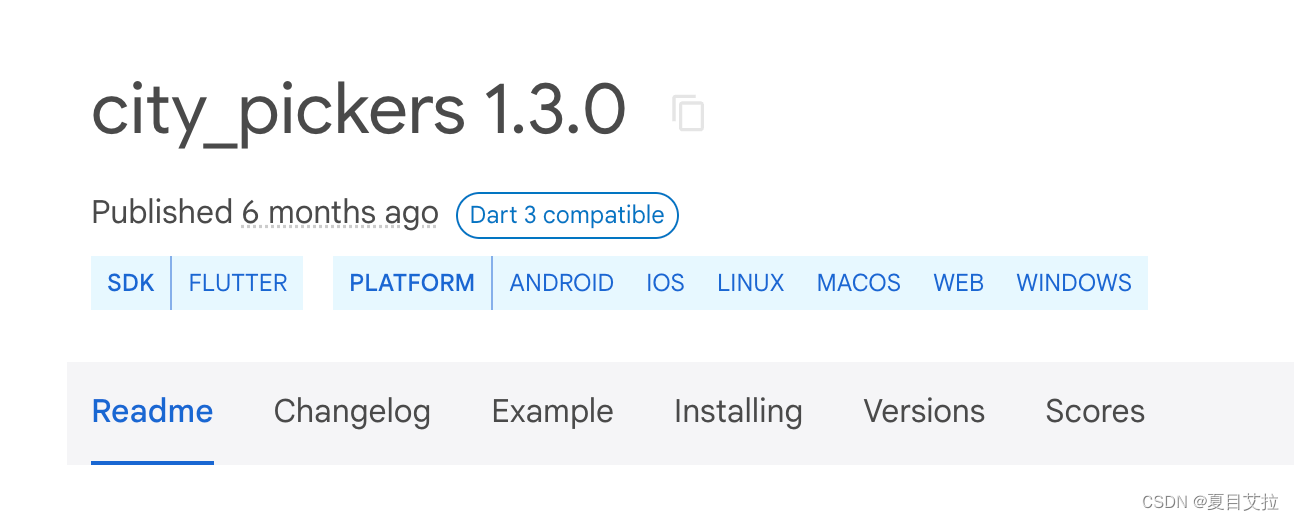
由训练集数据构建矩阵 A,该矩阵是一个 m*n 的矩阵,其中 m 为用户人数,n 为影片数量。矩阵中的值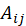 表示用户 i 对电影 j 喜爱与否,若
表示用户 i 对电影 j 喜爱与否,若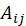 =1,则表示用户 i 喜爱电影 j,反之则不喜爱。
=1,则表示用户 i 喜爱电影 j,反之则不喜爱。
每一用户对其看过的电影都有打分,我们设定分值 3 为阈值,大于 3 分的即表示喜爱(即将不喜爱与未评价的电影不区分对待, 值都等于 0)。
值都等于 0)。
-
根据喜爱矩阵 A 计算资源分配矩阵 W
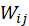 反映的是电影 j 与电影 i 的兴趣关联度。
反映的是电影 j 与电影 i 的兴趣关联度。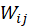 表示电影 j 愿意分配给电影 i 的资源配额,即喜爱电影 j 的用户又可能喜爱电影 i 的兴趣度,该值越大则该喜爱 j 电影的用户越容易喜爱电影 i。所以,根据两电影关联兴趣度的概念,我们构造出了下面这个计算
表示电影 j 愿意分配给电影 i 的资源配额,即喜爱电影 j 的用户又可能喜爱电影 i 的兴趣度,该值越大则该喜爱 j 电影的用户越容易喜爱电影 i。所以,根据两电影关联兴趣度的概念,我们构造出了下面这个计算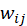 值的公式:
值的公式:
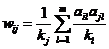
这个公式中,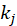 表示产品的度(即有多少用户喜爱电影 j),
表示产品的度(即有多少用户喜爱电影 j), 表示每一个用户,
表示每一个用户,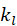
表示每个用户的度(即用户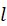 喜爱多少部电影)。很显然,电影 j 与电影 i 的兴趣关联度与
喜爱多少部电影)。很显然,电影 j 与电影 i 的兴趣关联度与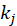 和
和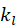 成反比。形式化解释如下:
成反比。形式化解释如下:
-
当一部电影 j 被很多人喜爱(即
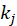 很大),那么电影 j 就可能是一个泛化的热门电 影,用户喜爱电影 j 就并不意味着他有强烈的喜爱电影 i 的倾向。
很大),那么电影 j 就可能是一个泛化的热门电 影,用户喜爱电影 j 就并不意味着他有强烈的喜爱电影 i 的倾向。 -
如果一个用户喜爱非常多的电影(即
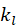 很大),那么他喜爱电影 j,就并不意味着他对电影 j 非常专注,相应的推荐度也就不那么高。
很大),那么他喜爱电影 j,就并不意味着他对电影 j 非常专注,相应的推荐度也就不那么高。
完成实验任务一:向用户做出电影推荐
第三步我们完成了对资源分配矩阵 W 这一推荐模型的训练,现在我们可以对用户做出电影推荐,具体过程与解释如下:
目标用户选择向量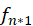 表示该用户选择的电影的选择矩阵,则
表示该用户选择的电影的选择矩阵,则 为一个 n*1 的列向量,则各行 i 上的值
为一个 n*1 的列向量,则各行 i 上的值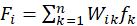 表示电影 i 对用户的吸引程度,将用户所有未选择(没看过)的电影按照 F 中对应项的得分进行排序,推荐排序靠前的电影给该用户。
表示电影 i 对用户的吸引程度,将用户所有未选择(没看过)的电影按照 F 中对应项的得分进行排序,推荐排序靠前的电影给该用户。
完成实验任务二——模型准确性预测
我们把资源分配矩阵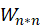 与喜爱矩阵 A 的转置
与喜爱矩阵 A 的转置 做矩阵相乘再转置运算得到一个 m*n 的 F 矩阵。
做矩阵相乘再转置运算得到一个 m*n 的 F 矩阵。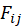 表示由我们推荐模型计算出来的 j 电影对 i 用户的吸引程度。有了矩阵 F 我们再用测试集数据去进行下面的模型评估算法。
表示由我们推荐模型计算出来的 j 电影对 i 用户的吸引程度。有了矩阵 F 我们再用测试集数据去进行下面的模型评估算法。
对于一测试集中的用户 i,假设其有 Li 个产品是不喜爱的(将不喜爱的与未选择归于一类),如果在测试集中用户 i 选择的电影 j,而电影 j 依据向量 F 被排在第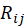 位,则计算其相对位置:
位,则计算其相对位置:
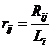
越精确的算法,给出的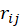 越小。对所有用户的
越小。对所有用户的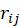 求平均值
求平均值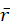 来量化评价算法的精确度。
来量化评价算法的精确度。
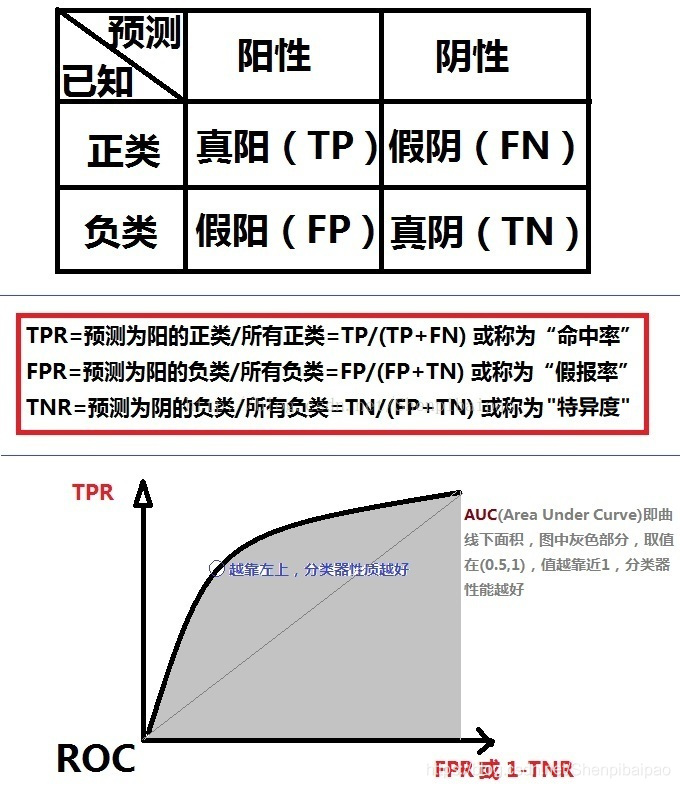
计算相应的真阳性率(TPR)以及假阳性率(FPR),画出 ROC 曲线。
三、实现详细
导入数据集,并随机分为两部分
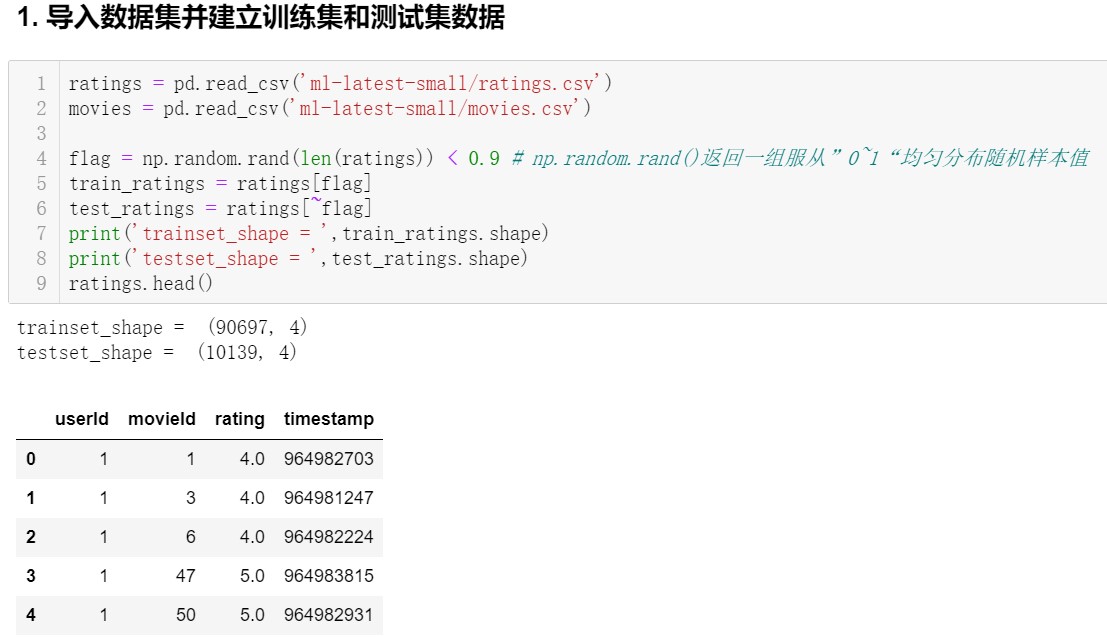
Pandas 是围绕 Series 和 DataFrame 两种数据结构来处理数据的,DataFrame 为二维表结构,Series 相当于二维表中的一行。上图结果打印出了读取进来的 ratings 数据的一部分,是一个二维表。
用 np.random.rand()返回一组服从 0~1 均匀分布的随机样本值,来实现将数据随机分为训练集和测试集两部分。
构建“用户—电影”喜爱矩阵 A
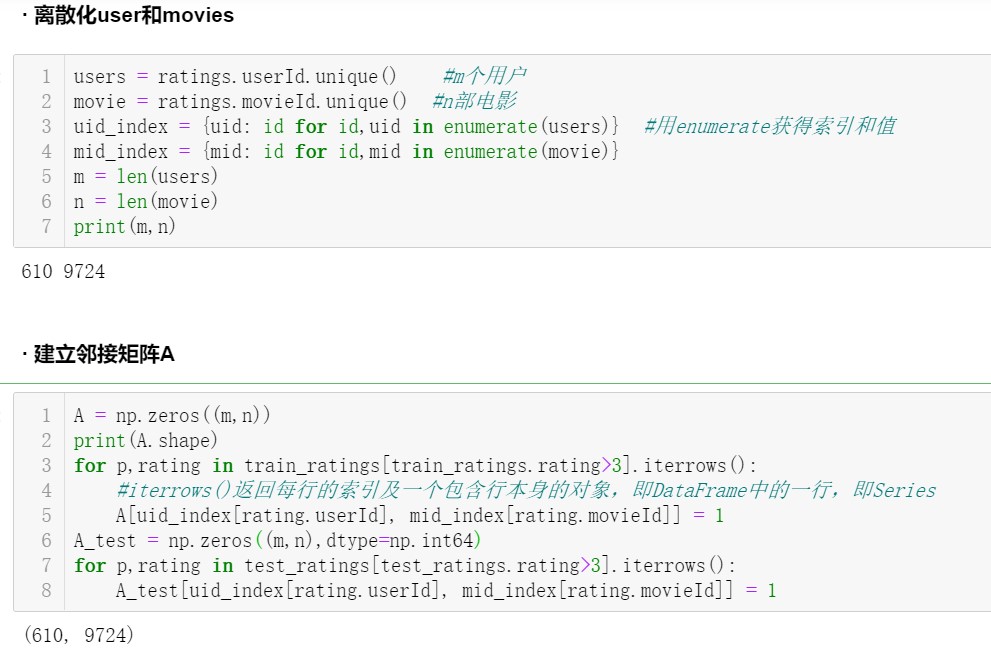
- 首先离散化用户数据和电影数据:用 enumerate()建立用户 uid 与其在矩阵 A 中的索引值 id 的字典关系{uid:id},由于 unique()函数返回的是由小到大的 uid 排列顺序,则最终将排好的 uid 与从 0 开始到用户数 m 的索引值 id 一一对应。对电影 movieId 也做同样的操作,进行离散化。enumerate()的功能示例如下:
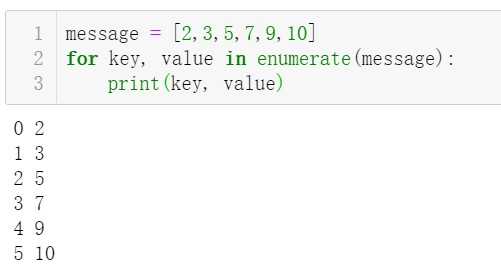
- 由训练集数据建立喜爱矩阵 A,由测试集数据建立目标用户电影喜爱矩阵 A_test。Pandas 的 DataFrame 支持像 train_ratings[train_ratings.rating>3]的操作来直接选择评分高于 3 的评价元组。
根据喜爱矩阵 A 计算资源分配矩阵 W

用矩阵乘法来实现公式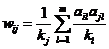 ,这种方法称为向量化并行计算。观察下面的两个矩阵的乘法:
,这种方法称为向量化并行计算。观察下面的两个矩阵的乘法:
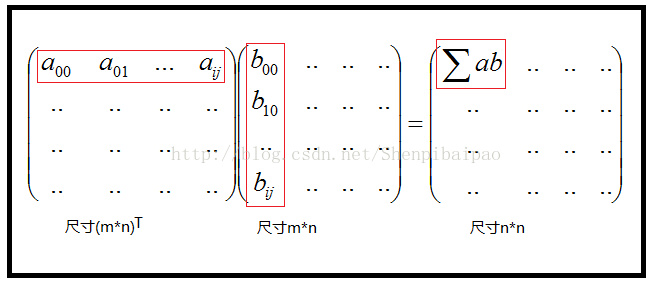
前两个矩阵红框中的计算结果会成为结果矩阵的一个元素值,则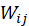 的计算可以直接用矩阵相乘,最终得到一个 n*n 的资源分配矩阵 W,从而训练出分类模型。
的计算可以直接用矩阵相乘,最终得到一个 n*n 的资源分配矩阵 W,从而训练出分类模型。
代码中由于可能会出现除零操作而产生 NAN,因此需要对这些数据做出处理。
完成实验任务一—做出推荐
做出推荐没有在在程序中展现,因为我们训练出了推荐模型 W,我们就可以很容易得对一个用户做出电影推荐。由模型做出推荐的过程在“第二部分——设计与分析 第 4 点”中已做过说明。至于推荐的效果我们在下面进行模型准确性的评价。
完成实验任务二—模型准确性预测

资源分配矩阵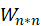 与喜爱矩阵 A 的转置
与喜爱矩阵 A 的转置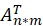 做矩阵相乘再转置运算得到一个 mn 的 F 矩阵。F_sort 矩阵是一个(mn)的矩阵,
做矩阵相乘再转置运算得到一个 mn 的 F 矩阵。F_sort 矩阵是一个(mn)的矩阵,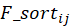 值表示对于用户 i,电影 j 在所有电影中的吸引度排名名次。np.argsort()函数返回的是数组值从小到大的索引值,则通过 F_sort_index 数组我们可以构造出数组 F_sort,即该推荐算法的评价模型。接下来由公式
值表示对于用户 i,电影 j 在所有电影中的吸引度排名名次。np.argsort()函数返回的是数组值从小到大的索引值,则通过 F_sort_index 数组我们可以构造出数组 F_sort,即该推荐算法的评价模型。接下来由公式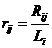 计算平均推荐相对位置 r 来评价算法精确度。先对每个人 i 计算每部喜爱影片 j 对应的相对位置
计算平均推荐相对位置 r 来评价算法精确度。先对每个人 i 计算每部喜爱影片 j 对应的相对位置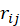 ,再计算该人的平均相对位置
,再计算该人的平均相对位置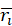 ,最后计算所有用户的平均相对位置。
,最后计算所有用户的平均相对位置。
最终计算得到的平均推荐相对位置 r=0.00010763274233963475

ROC 曲线是用来验证一个分类器(二分)模型的性能的。原理是,给出一个模型,输入已知正负类的一组数据(测试集数据),通过对比模型对该组数据进行的预测,衡量这个模型的性能。
-
如何画 ROC 曲线?
对于本实验很显然测试集数据为我们已知用户喜爱电影与否的数据,F_sort 是我们得到的用于评价该算法的模型,通过以上的分析,测试数据属于正类即用户喜爱电影的总数为 T=np.sum(A_test),反之不喜爱的电影总数为 F=np.sum(A_test==False)。由于 F_sort 衡量的是每部电影的排名,由 n*阈值和排名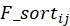 的关系我们可以确定 i 用户是否喜爱 j 电影(n 为电影数量),那么可以得到矩阵 F_out,则真阳数 TP=np.sum(A_test&F_out),假阳数 FP=np.sum(~A_test&F_out)。这样对于每一个阈值,我们可以计算出 TPR 和 FPR 确定一个点,最终绘制出 ROC 曲线。
的关系我们可以确定 i 用户是否喜爱 j 电影(n 为电影数量),那么可以得到矩阵 F_out,则真阳数 TP=np.sum(A_test&F_out),假阳数 FP=np.sum(~A_test&F_out)。这样对于每一个阈值,我们可以计算出 TPR 和 FPR 确定一个点,最终绘制出 ROC 曲线。
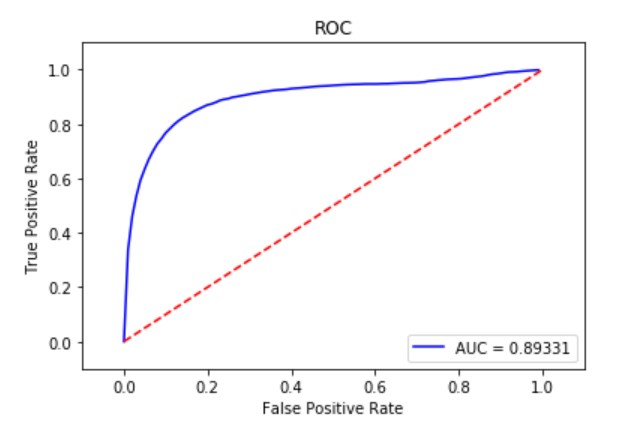
- 如何计算 AUC 值?
AUC 值即为 ROC 曲线下方的面积,这里取每个阈值下的正阳率 TPR 值之和再取平均值作为 AUC 值来量化该推荐模型的性能,最终计算出 AUC 在 0.893 附近,所以训练得到的推荐模型它具有较好的性能。
四、实验结果
实验代码和注释最先在 Jupyter 上完成,可以查看每一步的结果。最终的.py 代码在 PyCharm 编辑器中完成,最终完成了两个实验任务,得到了一个基于 MovieLens 数据集的电影推荐模型(即资源分配矩阵 W)并评价了该模型的准确性,画出了 ROC 曲线并计算出了模型的 AUC 值,可以看出该模型的推荐准确性还不错。

五、结论
-
完成实验之前,我学习了 Python Pandas 数据分析包。认识了 Pandas 是基于 Series 和 DataFrame 两种数据结构来处理数据的、学会了如何选择数据、赋值、读取与写入文件等操作。
-
掌握了基于网络结构的链路预测算法的算法思想,该算法不考虑用户和产品的内容特征,把它们看成抽象的节点,利用用户对产品的选择关系构建二部图。之后在此二部图的基础上构造出一个数学模型来解决问题。对于本题,我们要得到的模型是各部电影之间的兴趣关联度关系以便根据目标用户已选电影推荐他未选的潜在的电影,于是我们构造出了公式
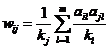 ,这就是我们要训练的模型。
,这就是我们要训练的模型。 -
熟悉了评价模型性能的算法思路。训练集用来训练模型,测试集用来评价模型的准确性。根据资源分配矩阵
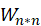 与喜爱矩阵 A 的转置
与喜爱矩阵 A 的转置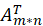 做矩阵相乘再转置运算得到的 m*n 的 F 矩阵元素值
做矩阵相乘再转置运算得到的 m*n 的 F 矩阵元素值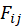 表示由我们分配模型计算出来的 j 电影对 i 用户的吸引程度,构造出评价该模型的相对距离函数——
表示由我们分配模型计算出来的 j 电影对 i 用户的吸引程度,构造出评价该模型的相对距离函数—— ,并计算出 r 的平均值来评价推荐模型的准确性。
,并计算出 r 的平均值来评价推荐模型的准确性。 -
反思:这次实验中的推荐模型和算法评价的数学函数在题目中都已给出,我只是动手实现了模型的构建和评价过程,但算法核心之处在于如何将实际问题建模成可训练的数学函数。自己应该努力学习数学模型和数学函数去逐渐掌握数学建模能力。
资源下载地址:https://download.csdn.net/download/sheziqiong/88490254
资源下载地址:https://download.csdn.net/download/sheziqiong/88490254
原文地址:https://blog.csdn.net/newlw/article/details/134153332
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_10459.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!