前言
Linux脚本有很多解析器(Shell),不同解析器要求的脚本语法是不一样的。系统在解析脚本时,如果没有在脚本声明指定解析器,则会采用系统默认解析器来对脚本进行解析。sh是非常重要解析器,历史很悠久,地位很牢固。特别地,Bash是用途最广的Shell,而且是兼容sh的解析器,因此本文着重Bash Shell的研究。
一、脚本编程基本知识
1、脚本的编程方式
脚本的编写方式一般是在Linux上进行的,如果Linux有图形界面,那可以跟windows一样操作,如使用一些第三方应用VS去编写。如果Linux没有图形界面,则需要了解并学习”vi“或”vim“命令(还有其他命令请自查)的使用,推荐使用vim。
2、声明Bash Shell
声明使用的解析器,可避免系统采用默认解析器去运行脚本带来的可能的错误。
#!/bin/bash
# 第一行的“井号+感叹号+脚本解释器程序路径”,说明这是一个可执行的脚本
# 任意行的单独的”井号“都是注释作用,非第一行的“井号+感叹号“也是注释作用
# 避免问题:你的脚本是Bash Shell,系统默认的是Csh,若不声明,那么你的脚本运行错误3、脚本的执行权限
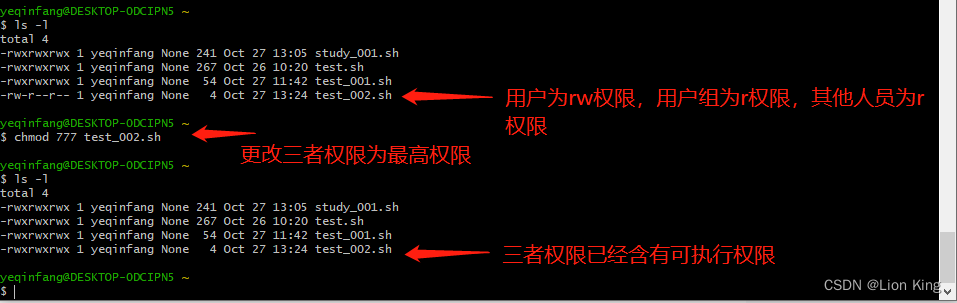
Linux脚本 不以 后缀来判断它是否可执行,而是以命令 ”ls -l“ 来查看它是否是可执行文件,可使用chmod来变更脚本权限(该命令使用方式请自查文档),这样才能运行。
4、脚本的组织方式
脚本是由命令组成的,而命令的执行都是单独的,即使报错也不影响下一条命令的执行;一行语句可以包含多个命令,用”;”隔开。
#!/bin/bash
# 运行cat命令,假使文件不存在
cat nobody.txt
echo $(pwd)
echo "nobody.txt不存在,也执行了pwd命令"
cat nobody.txt;echo $(pwd);
echo "nobody.txt不存在,就算写成一整条语句,也执行了pwd命令"
二、通过脚本学语法
1、标准输入与标准输出
脚本功能:根据脚本提示,手动给脚本输入一些文字,让脚本打印这些信息。
这里需要使用标准输出echo去提示用户操作,使用标准输入read读取用户输入的信息,使用printf将信息打印出来。
#!/bin/bash
# 给用户提示信息
echo "请告诉我你想做什么?"
# 使用read指令和work变量去接收用户的信息
read work
echo "你告诉我的信息我知道了,我使用printf命令去打印了你的信息:"
printf ${work}
(1)echo命令介绍
① echo将给定的每个字符串写入标准输出,每个字符串之间有一个空格,最后一个字符串后面有一个换行符。因此,可以直接这样使用:
echo "I" "Love" "me"②由于shell别名和内置的echo函数,交互式地或在脚本中使用无修饰的echo可能会获得与这里描述的不同的功能。为避免shell的干扰,可以这样使用echo:
env echo "123"③由于历史和向后兼容的原因,某些裸露的选项类字符串不能作为非选项参数传递给echo。因此,可以通过printf来替代echo,进而避免这样的问题。比如,我想打印 -n 这个字符串,因为echo的选项里是有 -n 的,他会把字符串当作指令来用,因此执行如下指令是不输出的:
echo "-n"
echo -n④一些格式化输出可以参照官方文档,或使用 ”man echo“ 查看,如设置末尾不输出回车:
echo invocation (GNU Coreutils 9.1)echo invocation (GNU Coreutils 9.1)![]() https://www.gnu.org/software/coreutils/manual/html_node/echo-invocation.html#echo-invocation
https://www.gnu.org/software/coreutils/manual/html_node/echo-invocation.html#echo-invocation
(2)read命令介绍
①从标准输入中读取一行,并将其拆分为多个字段。这些字段是以空格进行分配,分配方式可根据选项进行更改,默认分配方式如下:
$ read a b
asdasd asdas asdasd
$ echo $a
asdasd
$ echo $b
asdas asdasd
②可通过数组的方式 获取,如增加选项 -a ,更多选项请查阅官方文档,现展示如下:
$ read -a a
i love you !
$ echo ${a[@]}
i love you !
$ echo ${a[1]}
love
(3)printf命令介绍
从”(1)echo命令介绍“中,我们已经了解到echo的痛点,而解决这个痛点的方式是使用printf替代。printf 命令是模仿 C 程序库(library)里的 printf() 程序,而使用 printf 的脚本比使用 echo 移植性好。实际上,printf在格式化方面优势更大,展示如下:
printf "%-10s %-10s %-10sn" 年级 班级 姓名;(4)变量的引用
${work}是变量引用的方式之一,可以写成 $work,建议使用${work}方式,方便阅读。
2、数学运算
#!/bin/bash
echo "请输入第一个数字:"
read one
one_int=$((10#${one}))
echo "请输入第二个数字:"
read two
two_int=$((10#${two}))
res=$((one_int+two_int))
res1=$((one_int-two_int))
res2=$((one_int*two_int))
res3=$((one_int/two_int))
res4=$((one_int%two_int))
res5=$((one_int**two_int))
echo 'echo单引号输出相加结果:${res}'
echo "echo双引号输出相加结果:${res}"
printf "printf双引号输出相加结果为:${res}n"
printf 'printf单引号输出相加结果为:${res}n'
printf "%-10s %-10s %-6s %-6s %-6s %-10s %-10s %-6s n" 输入值1 输入值2 加 减 乘 除以 取余 幂
printf "%-7d %-7d %-5d %-5s %-5s %-8s %-8s %-5s n" ${one_int} ${two_int} ${res} ${res1} ${res2} ${res3} ${res4} ${res5}
(1)运算的实现
①使用 (())实现运算,语法为 $((one_int+two_int));
(2)变量的简单赋值
使用等号进行赋值,中间不能有空格,实际上,空格在Linux脚本中非常重要,不能随意加空格或去掉空格,赋值的语法为 var=value。
(3)双引号与单引号
(4)运算符号
详见脚本的使用,表示如下:加(+)、减(-)、乘(*)、除(/)、取余(%)、幂(**)
(5)字符串转数字
字符串转数字的方法有很多,如使用sed或awk命令,这里采用的是$((10#${one})),10#代表转成10进制。
3、参数变量的引用
#!/bin/bash
#定义函数
function func(){
printf "当前脚本名称: %sn" $0
printf "输入给脚本的第一个参数: %sn" $1
printf "输入给脚本的参数数量: %sn" $#
printf "输入给脚本的所有参数的数组: $*n"
echo "输入给脚本的所有参数的数组: $@"
printf "上一条命令的执行情况: %sn" $?
printf "当前脚本PID: %sn" $$
}
#调用函数
func 参数1 参数2
(1)使用参数变量的注意事项
①$*与 $@不同点:不被双引号包裹时,二者相同,均为数组类型;当被双引号包裹时,$@没有变化,而$*的所有参数被整合为一个字符串。
④$-表示显示Shell使用的当前选项,与set命令功能相同,请自行学习。
(2)函数封装与调用
①定义函数与引用函数的基本方式如脚本所示,关键词为function,本节暂不深入研究。
4、自定义变量的操作
#!/bin/bash
#变量的简单赋值,等号2边不能有空格,否则解析成命令,单引号与双引号有些区别,见上节描述
var_1=1
var_2="$0"
var_3='$0'
#变量的引用与修改,被修改的var_1值,不会让引用它的var4被修改
var_4=${var_1}
printf "var_1修改前:${var_1} n"
printf "var_4=${var_4} n"
var_1="1——1"
printf "var_1修改后:${var_1} n"
printf "var_4=${var_4} n"
#不被初始化的变量,默认值为null
var_5=
printf "不被初始化的变量var_5=${var_5} n"
#获取指令变量,可使用$()或反引号``
var_6=$(pwd)
var_7=`pwd`
printf "${var_6} is ${var_7} n"
#只读变量设置后,不能被删除,删除变量的方法为unset
var_8="我是只读变量"
readonly var_8
unset var_8
printf "${var_8},我不能被删除"
(1)$() 与 反引号“的异同
都可以用于获取指令结果,但建议使用$(),因为它可以嵌套,而反引号不支持。
5、条件判断语句
脚本功能:判断脚本的参数数量、判断脚本名称、判断脚本的文件分别满足对应的条件然后打印相关信息。
#!/bin/bash
function func(){
#判断传入变量的数字
if [[ $# -eq 4 || $# -gt 4 ]]; then
printf "传入变量的个数大于或等于4 n"
elif [ $# -ge 2 ] || [ $# -le 3 ]; then
printf "传入变量的个数等于2或等于3 n"
elif [ $# -eq 1 ]; then
printf "传入变量的个数等于1 n"
else
printf "传入变量的个数不在预期范围内 n"
fi
#判断本脚本名称的字符串
if [[ $0="study_006.sh" ]] || [[ -n $0 ]]
then printf "本脚本名称与期望名称一致, 或脚本名称的长度不为0 n"
else
printf "本脚本名称与期望名称不一致,或长度为0 n"
fi
#使用case语句重写“判断传入变量的数值”
case $# in
0) printf "传入变量的个数不在预期范围内 n" ;;
1) printf "传入变量的个数等于1 n" ;;
2) printf "传入变量的个数等于2或等于3 n" ;;
"3") printf "传入变量的个数等于2或等于3 n" ;;
*) printf "传入变量的个数大于或等于4 n" ;;
esac
#判断文件属性
if test -e $0 ;then
printf "本文件存在 n"
if [[ -x $0 ]];then
printf "文件具有执行权限 n"
fi
fi
}
func asd asd asd
(1)if语句注意事项
①如上脚本,可以知道语句的基本格式为 “if … ;then…;fi”,可选”else“、”elif…;then…”进行扩展,其中”;“可以使用回车替代。
②条件需要使用[]或[[]]进行包裹,里面语句的两端需要有空格才能被识别为条件,二者用法是有区别的,建议使用[[]],因为可以在里面使用 || 等逻辑操作符,[]是不可以的。
③[]或[[]]可以使用命令test来替代,test的使用例子为
if test 1 -eq 1 ;then echo "good"; fi④书写这些语句时,建议培养使用习惯,如使用分号或使用回车号来构造语句,建议统一使用分号来避免误操作。
⑤if语句可以嵌套
(2)case语句注意事项
①如上脚本,case语句一定条件上可以替换if语句,增强可读性,但功能不算强大。语法为:
case ... in
0) ... ;;
1) ...;;
...
*) ...;;
esac②假使参数值为数字0,而对应的条件0写成”0″也是可以匹配上的。
③*)表示其它匹配条件,即列举条件之外的情况。
④加入0和1输出结果相同,可通过 | 合并,写成 0|1)
⑤case语句可以嵌套
(3)数字判断使用到的参数
| 参数 | 说明 |
|---|---|
| -eq | 等于则为真 |
| -ne | 不等于则为真 |
| -gt | 大于则为真 |
| -ge | 大于等于则为真 |
| -lt | 小于则为真 |
| -le | 小于等于则为真 |
(4)字符串判断使用到的参数
| 参数 | 说明 |
|---|---|
| = | 等于则为真 |
| != | 不相等则为真 |
| -z 字符串 | 字符串的长度为零则为真 |
| -n 字符串 | 字符串的长度不为零则为真 |
(5)文件判断使用到的参数
| 参数 | 说明 |
|---|---|
| -e 文件名 | 如果文件存在则为真 |
| -f 文件名 | 如果文件存在且为普通文件则为真 |
| -d 文件名 | 如果文件存在且为目录则为真 |
| -r 文件名 | 如果文件存在且可读则为真 |
| -w 文件名 | 如果文件存在且可写则为真 |
| -x 文件名 | 如果文件存在且可执行则为真 |
| -s 文件名 | 如果文件存在且至少有一个字符则为真 |
| -c 文件名 | 如果文件存在且为字符型特殊文件则为真 |
| -b 文件名 | 如果文件存在且为块特殊文件则为真 |
(6)条件判断使用到的逻辑操作符
要求所有条件为真,则条件为真
②或 的表示方法:||、-o
要求任意条件为真,则条件为真
③非 的表示方法:!
要求条件反转为真时,条件为真
6、循环语句
#!/bin/bash
# 无限循环与强制退出
while true # 可使用 : 代替true
do
printf "条件true开始打印 n"
if [[ $0="study_007.sh" ]];then
printf "条件true,强制打印结束 n"
break
fi
done
# 有限循环与自动退出
int=0
while (( $int<10 )) # 可使用test、[[]]替代,<等价于-lt,建议数值对比时使用-lt
do
printf "条件int,第 %s 次打印 n" $int
let "int++" # 等价于 (( int++ ))
if [[ ${int} -eq 10 ]];then
printf "条件int,打印结束 n"
fi
done
# 循环与命令
while pwd # 命令执行失败将不进入循环,如使用cp gogo bb
do
printf "pwd指令执行为真,开始打印 n"
if [[ $0="study_007.sh" ]];then
printf "pwd指令执行为真,打印结束 n"
break
fi
done
# for无限循环替代while无限循环
for (( ; ; ))
do
printf "条件true开始打印 n"
if [[ $0="study_007.sh" ]];then
printf "条件true,强制打印结束 n"
break
fi
done
# for有限循环替代while优先循环
for (( int_1=0 ; int_1<10 ; $(( int_1++ )) )) # 不能用 [[]] 替代 (())
do
printf "条件int_1,第 %s 次打印 n" $int_1
# (( int_1++ ))
# printf "int_1的数值为 ${int_1} n"
if [[ ${int_1} -eq 9 ]];then # 因为while的加1在前,而for的加1在后,因此判断条件为9
printf "条件int_1,打印结束 n"
fi
done
# for与数组
arr=(0 1 2 3 4 5 6 7 8 9)
for i in ${arr[@]} # 可使用 arr[*] 替换 arr[@]
do
printf "arr 为 ${i} n"
done
# for与可迭代数列(数组的一种)
for i in 0 1 2 3 4 5 6 7 8 9
do
printf "arr 为 ${i} n"
done
# for与可迭代文本(数组的一种)
for i in my first book is " i can do it "
do
printf "arr 为 ${i} n"
done
# 循环中的continue与break
while :
do
printf "continue 开始打印 n"
if [[ $0="study_007.sh" ]];then
printf "continue 前一个语句 n"
continue
printf "continue 后一个语句 n"
fi
done
(1)while语句注意事项
①循环需要通过条件为真去循环,当然while false是没有意义的,而while true是无限循环的写法之一,可通过break语句强制退出整个循环,通过continue退出后续语句而继续循环。
③until语句与 while 在处理逻辑上完全相反,但使用方式上完全相同,等价于while false执行,while true不执行。
(2)for语句注意事项
①可以实现while的无限循环和有限循环,但不能像while一样直接判断命令的结果去执行循环,详见本脚本中的”循环与命令“;但是,for可以遍历数组,这个特性是while没有的。
③使用for遍历时,如果有双引号的存在,将被认为是一个整体,详见本脚本实例 ”# for与可迭代文本(数组的一种)“
(3)数字判断可以使用符号替代选项
如实例中的 -lt 可以使用 < 替代,建议使用 -lt ,因为当 -eq 时,对应的是 ==,容易混用赋值语句或字符串判断的 = 。
(4)let命令与(())
let命令可以与(())互相替换,使用的时候哪个方便用哪个就好。
(5)(()) 与 [[]]
(())用于整数运算,[[]]用于条件判断,二者不是一回事。while (( $int<10 ))可以使用 [[]]替换(()),但for (( int_1=0 ; int_1<10 ; $(( int_1++ )) )) 不能用 [[]] 替代 (())。原因是(())既可以作为运算使用,也可以作为条件使用,而[[]]只能作为条件使用。当不涉及运算时,[[]]才有可能替换(())。
(6)数组
①如脚本所示,数组的赋值方式采用()来包裹,里面元素采用空格划分
②数组的取值方式采用索引方式,形式如 ${arr[0]}、${arr[@]}、${arr[*]}等
③关联数组(类字典)的实现是以关键字 declare 来实现,使其像字典那样取数据或写数据,例子如下:
$ declare -A arr=(["book1"]="好书1" ["book2"]="好书2" ["book3"]="好书3")
$ echo ${arr["book1"]}
好书1
$ echo ${arr[@]}
好书1 好书3 好书2
$ arr["book1"]="好书1修改"
$ echo ${arr[*]}
好书1修改 好书3 好书2
$ echo ${arr["book1"]}
好书1修改
7、函数
#!/bin/bash
#中间命令失败
function func_01()
{
a=1
copy asd asd
b=2
}
#强制函数返回非0数字
function func_02
{
a=1
return 100
}
#最后一条命令失败
func_03()
{
a=1
copy asd asd
}
func_01
echo "func_01执行后返回值:$?"
func_02
echo "func_02执行后返回值:$?"
func_03
echo "func_03执行后返回值:$?"
(1)函数定义
①定义函数的方式如 function func(){} ,建议采用这种方式,其他方式见脚本
②没有形式参数,可直接传参数,如在调用时直接传入: func 参数1 参数2 …
(2)函数的返回值
①只能是数字,默认返回最后一条指令的执行情况,成功则返回0,失败则返回其它数字
②可强制返回指定数字,不能是非数字,关键字使用 return
(3)函数调用
①不带参数的调用,直接使用函数名:func
②带参数的调用,直接传参数:func 参数1 参数2 …
8、模块化编程
脚本功能:在本脚本中调用其它脚本的函数,实现模块化编程(假如我们的文件为”函数“章节的脚本,现在创建新脚本去引用它)
#!/bin/bash
# 也可以使用 . study_008.sh 去调用,建议使用关键字source
source study_008.sh
func_01
echo "在$0文件中运行study_008.sh的函数,返回值为:$?"(1)创建工程
(2)目录命名
(3)脚本命名
①可以根据功能命名
(4)模块调用
9、重定向研究
脚本功能:通过函数重定向的方式,研究重定向的原理,掌握其用法
#!/bin/bash
function func_01()
{
pwd
cp 000 111
} >error.txt 2>&1
function func_02()
{
pwd
cp 000 111
} 2>&1 >>error.txt
function func_03()
{
pwd
cp 000 111
} 2>&1 >/dev/null
function func_04()
{
pwd
cp 000 111
} &> error.txt
function func_05()
{
pwd
cp 000 111
} >error.txt 1>&2
function func_06()
{
cp 000 111
pwd
} >error.txt 1>&2
function func_07()
{
pwd
cp 000 111
} 1>&2 >>error.txt
function func_08()
{
cp 000 111
pwd
} 1>&2 >>error.txt
function func_09()
{
pwd
cp 000 111
} >error.txt
echo "开始---------------------------"
func_01
printf "func_01 >error.txt 2>&1: n"
cat error.txt
rm -rf error.txt
echo "结束---------------------------" ; echo ""
echo "开始---------------------------"
func_02
printf "func_02 2>&1 >error.txt: n"
cat error.txt
rm -rf error.txt
echo "结束---------------------------" ; echo ""
echo "开始---------------------------"
func_03
printf "func_03 2>&1 >/dev/null: n"
cat error.txt
rm -rf error.txt
echo "结束---------------------------" ; echo ""
echo "开始---------------------------"
func_04
printf "func_04 &> error.txt: n"
cat error.txt
rm -rf error.txt
echo "结束---------------------------" ; echo ""
echo "开始---------------------------"
func_05
printf "func_05 >error.txt 1>&2: n"
cat error.txt
rm -rf error.txt
echo "结束---------------------------" ; echo ""
echo "开始---------------------------"
func_06
printf "func_06 >error.txt 1>&2: n"
cat error.txt
rm -rf error.txt
echo "结束---------------------------" ; echo ""
echo "开始---------------------------"
func_07
printf "func_07 1>&2 >error.txt: n"
cat error.txt
rm -rf error.txt
echo "结束---------------------------" ; echo ""
echo "开始---------------------------"
func_08
printf "func_08 1>&2 >error.txt: n"
cat error.txt
rm -rf error.txt
echo "结束---------------------------" ; echo ""
echo "开始---------------------------"
func_09
printf "func_09 >error.txt: n"
cat error.txt
rm -rf error.txt
echo "结束---------------------------" ; echo ""
(1)重定向
①重定向的对象为:0代表标准输入、 1代表标准输出、2代表标准错误输出
③重定向输出用 > 符号、>> 符号表示
(2)重定向输入
①可以采用 ”命令 0< 文件名“ 或 ”命令 < 文件名“,因为输入只有0这一个,建议采用后者直接重定向输入。
②< 与 << ,<< 不像 >> 有追加的含义,它只有一个作用,就是以特定标记来重定向,用法如下代码所示,其中names成对出现,可用其它字符代替,<<后面紧跟字符,否则空格会被当作特定标记:
cat <<names
yezi
qindong
huazheng
names(3)重定向输出
①可以采用”命令 1> 文件名“ 、”命令 2> 文件名“、”命令 &> 文件名“的方式重定向,其中 > 右边参数缺省时,默认数字为1,代表只重定向标准输出;&代表1和2都重定向。建议带数字的写法,这样阅读带数字的写法更能理解。
② 1>&2 与 2>&1,前者表示将标准输出重定向到标准错误输出,后者则与前者相反。
③1>&2 、2>&1 与 &> 的比较,观察本脚本的输出,可以知道2>&1与1>&2是相反的,即2>&1有输出时,1>&2没有输出;2>&1放在文件后可以全部输出,放在文件前只输出标准输出;&>有时等价于放在文件后面的2>&1,而实际&>不分前后,都会输出,相当于1>&2与2>&1的结合。因此,建议2>&1统一放在后面,只有&>时放中间,以避免误解,对比信息如下:
开始---------------------------
func_01 >error.txt 2>&1:
/home/yeqinfang
cp: cannot stat '000': No such file or directory
结束---------------------------
开始---------------------------
cp: cannot stat '000': No such file or directory
func_02 2>&1 >error.txt:
/home/yeqinfang
结束---------------------------
开始---------------------------
func_04 &> error.txt:
/home/yeqinfang
cp: cannot stat '000': No such file or directory
结束---------------------------
开始---------------------------
/home/yeqinfang
cp: cannot stat '000': No such file or directory
func_05 >error.txt 1>&2:
结束---------------------------
④ > 与 >> ,前者直接覆盖文件,后者基于文件进行追加操作
⑤ /dev/dull 该文件是个空文件,用在重定向中可使得输出信息不输出,前提是2>&1这个重定向放该文件后面。
10、正则表达式与Linux三剑客
脚本功能:给定一个文本(如ifconfig获取的网卡信息),采用grep、awk、sed对该文本进行处理
eth0 Link encap:Ethernet HWaddr 02:9C:32:08:1E:F2
inet addr:10.80.159.135 Bcast:10.80.159.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:605878 errors:0 dropped:0 overruns:0 frame:0
TX packets:117274 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:48636892 (46.3 MiB) TX bytes:1658079942 (1.5 GiB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:92719 errors:0 dropped:0 overruns:0 frame:0
TX packets:92719 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:10277069 (9.8 MiB) TX bytes:10277069 (9.8 MiB)
#!/bin/bash
# 获取eth0的IP地址
cat study_012.txt | grep 'inet addr.*Bcast' | awk '{printf $2}' | sed 's/addr://g'(1)管道符 |
(2)正则表达式
①grep中使用了正则表达式的元字符 .* ,即匹配了除了换行符的所有字符
(3)Linux三剑客:grep、 awk、sed
①从上面的脚本可以知道,grep取行,awk取列,sed编辑
三、项目实战
1、监控应用程序
脚本功能:实现对应用程序SmoreScanner进程的监控,即每5秒查询一次SmoreScanner进程是否存在,如果存在,打印此时的内存情况,如果不存在,则杀掉该进程的守护进程SmorescannerUdpProcess,最后退出监控。这样就可以知道应用程序SmoreScanner崩溃了。
#!/bin/sh
while true
do
sleep 5s;
smore=$(pidof SmoreScanner);
echo "SmoreScanner pid is: "; echo ${smore};
if [[ ${smore} != "" ]] ;then
echo "sucess!";
echo $(free -m)
else
echo "SmoreScanner Error!";
smoreudp=$(pidof SmorescannerUdpProcess);echo ${smoreudp};kill ${smoreudp};
break
fi
done原文地址:https://blog.csdn.net/weixin_43431593/article/details/127550041
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_10649.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!