大数据分析与应用实验任务九
实验目的
实验任务
进入pyspark实验环境,打开命令行窗口,输入pyspark,完成下列任务:
在实验环境中自行选择路径新建以自己姓名拼音命名的文件夹,后续代码中涉及的文件请保存到该文件夹下(需要时文件夹中可以创建新的文件夹)。
一、参考书中相应代码,练习RDD持久性、分区及写入文件(p64、67、80页相应代码)。
1.持久化
迭代计算经常需要多次重复使用同一组数据。下面就是多次计算同一个RDD的例子。
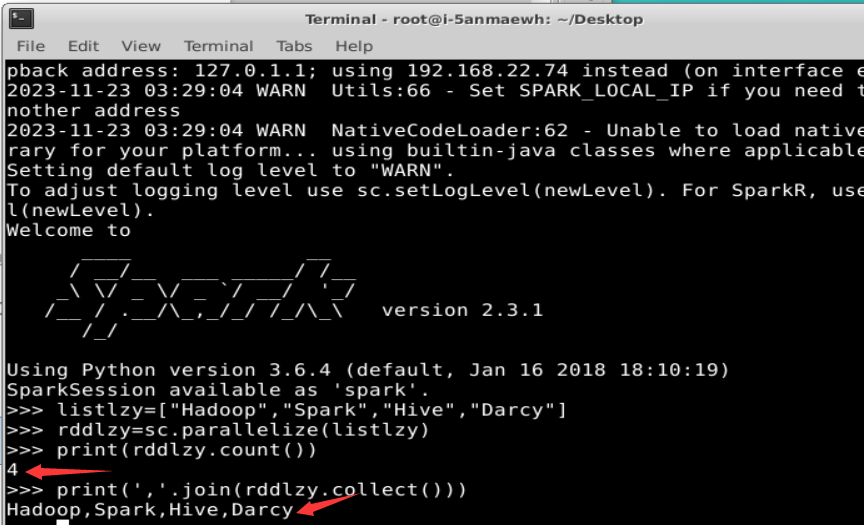
listlzy=["Hadoop","Spark","Hive","Darcy"]
rddlzy=sc.parallelize(listlzy)
print(rddlzy.count())#行动操作,触发一次真正从头到尾的计算
print(','.join(rddlzy.collect()))#行动操作,触发一次真正从头到尾的计算
一般而言,使用cache()方法时,会调用persist(MEMORY_ONLY)。针对上面的实例,增加持久化语句以后的执行过程如下:
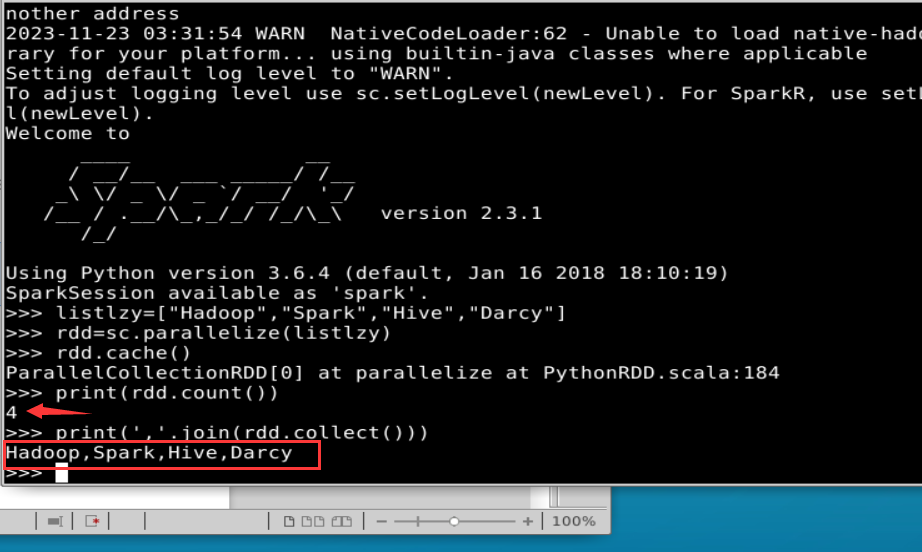
listlzy=["Hadoop","Spark","Hive","Darcy"]
rdd=sc.parallelize(listlzy)
rdd.cache()#会调用persist(MEMORY_ONLY),但是,语句执行到这里,并不会缓存rdd,因为这时rdd还没有被计算生成
print(rdd.count())#第一次行动操作,触发一次真正从头到尾的计算,这时上面的rdd.cache()才会被执行,把这个rdd放到缓存中
print(','.join(rdd.collect()))#第二次行动操作,不需要触发从头到尾的计算,只需要重复使用上面缓存中的rdd
2.分区
-
在调用textFile()和parallelize()方法的时候手动指定分区个数即可,语法格式如下:
sc.textFile(path,partitionNum)其中,path参数用于指定要加载的文件的地址,partitionNum参数用于指定分区个数。下面是一个分区的实例。
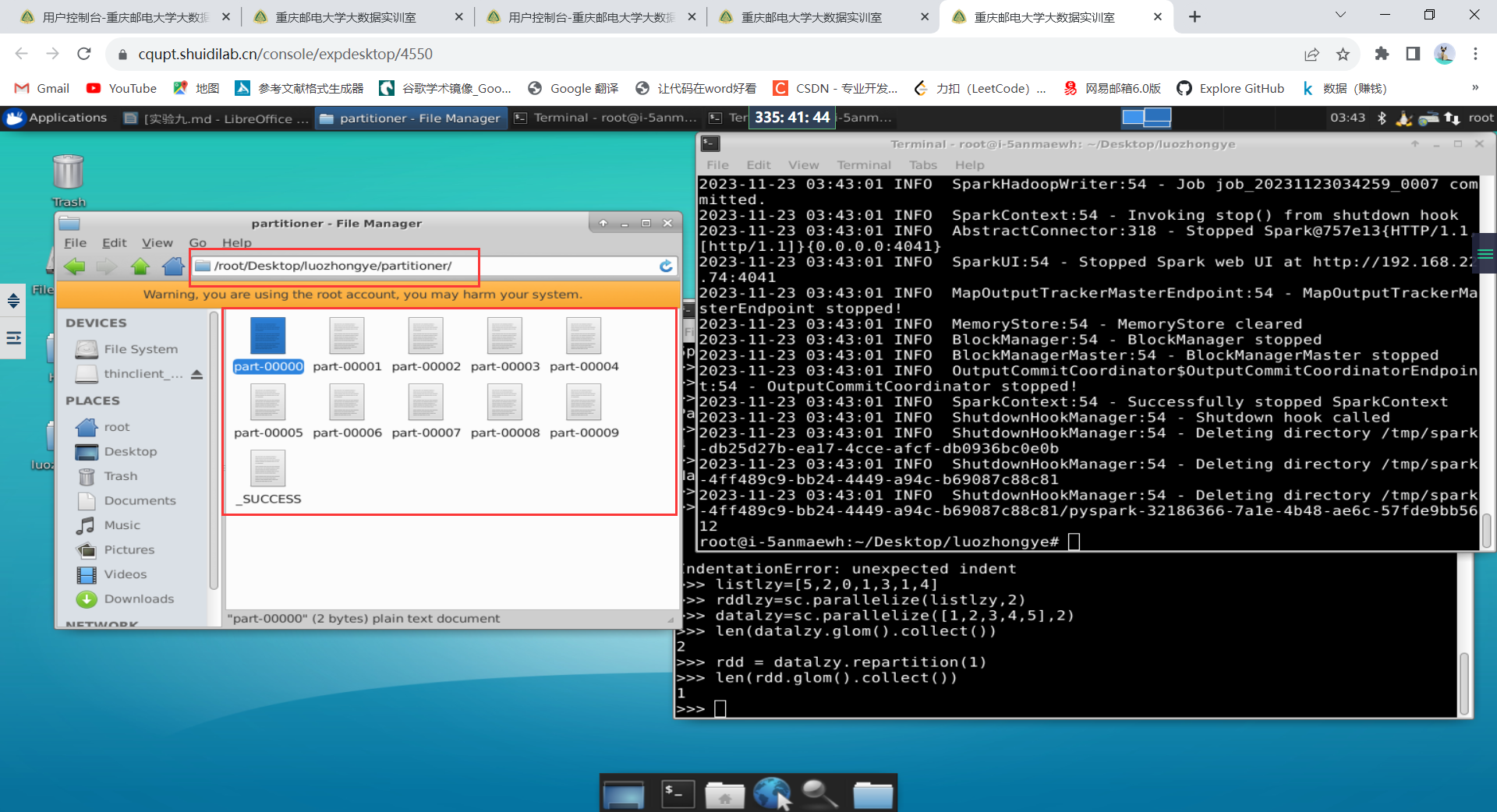
listlzy=[5,2,0,1,3,1,4] rddlzy=sc.parallelize(listlzy,2)//设置两个分区
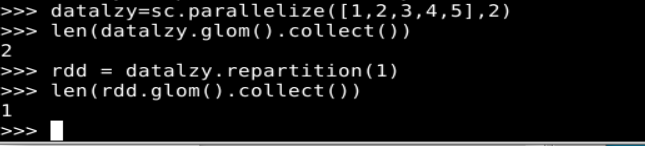
datalzy=sc.parallelize([1,2,3,4,5],2)
len(datalzy.glom().collect())#显示datalzy这个RDD的分区数量
rdd = datalzy.repartition(1) #对 data 这个 RDD 进行重新分区
len(rdd.glom().collect()) #显示 rdd 这个 RDD 的分区数量
-
自定义分区方法
下面是一个实例,要求根据 key 值的最后一位数字将 key 写入到不同的文件中,比如,10 写入到 part-00000,11 写入到 part-00001,12 写入到 part-00002。打开一个 Linux 终端,使用 vim 编辑器创建一个代码文件“/root/Desktop/luozhongye/TestPartitioner.py”,输入以下代码:
from pyspark import SparkConf, SparkContext def MyPartitioner(key): print("MyPartitioner is running") print('The key is %d' % key) return key % 10 def main(): print("The main function is running") conf = SparkConf().setMaster("local").setAppName("MyApp") sc = SparkContext(conf=conf) data = sc.parallelize(range(10), 5) data.map(lambda x: (x, 1)).partitionBy(10, MyPartitioner).map(lambda x: x[0]).saveAsTextFile( "file:///root/Desktop/luozhongye/partitioner") if __name__ == '__main__': main()
cd /root/Desktop/luozhongye
python3 TestPartitioner.py
或者,使用如下命令运行 TestPartitioner.py:
cd /root/Desktop/luozhongye
spark-submit TestPartitioner.py
3.文件数据写入
- 把 RDD 写入到文本文件中
textFile = sc.textFile("file:///root/Desktop/luozhongye/wordlzy.txt")
textFile.saveAsTextFile("file:///root/Desktop/luozhongye/writeback")
Hadoop is good
Spark is fast
Spark is better
luozhongye is handsome
Spark 采用惰性机制。可以使用如下的“行动”类型的操作查看 textFile 中的内容:
textFile.first()
正因为 Spark 采用了惰性机制,在执行转换操作的时候,即使输入了错误的语句,pyspark 也不会马上报错,而是等到执行“行动”类型的语句启动真正的计算时,“转换”操作语句中的错误才会显示出来,比如:
textFile = sc.textFile("file:///root/Desktop/luozhongye/wordcount/word123.txt")

- 把 RDD 写入到文本文件中
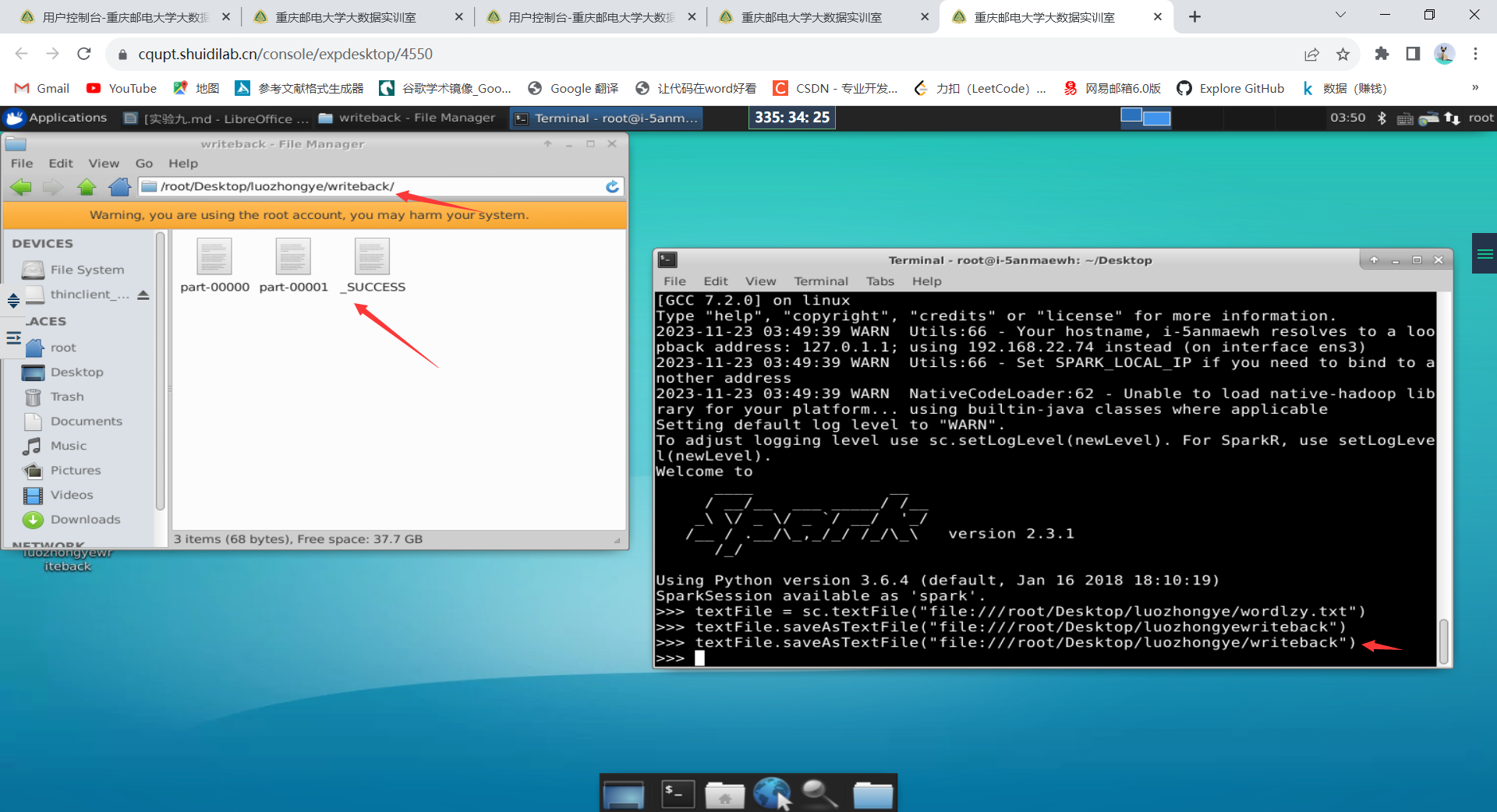
可以使用 saveAsTextFile()方法把 RDD 中的数据保存到文本文件中。下面把 textFile 变量中的内容再次写回到另外一个目录 writeback 中,命令如下:
textFile = sc.textFile("file:///root/Desktop/luozhongye/wordlzy.txt")
textFile.saveAsTextFile("file:///root/Desktop/luozhongye/writeback")
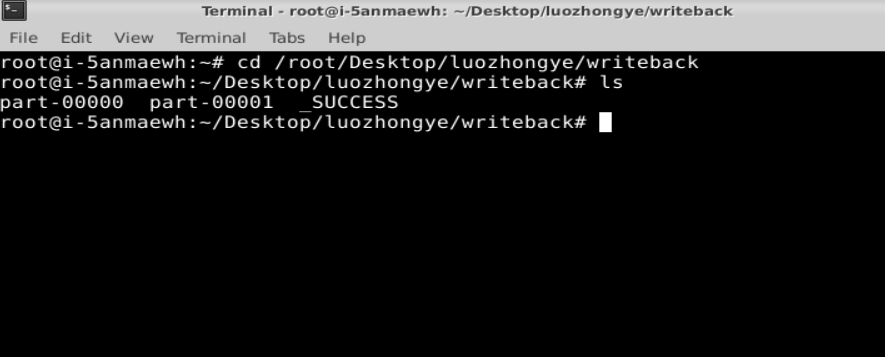
进入到“/root/Desktop/luozhongye/writeback”目录查看
cd /root/Desktop/luozhongye/writeback
ls
二、逐行理解并运行4.4.2实例“文件排序”。
新建多个txt文件file1.txt 、file2.txt 、file3.txt ,其内容分别如下:
33
37
12
40
4
16
39
5
1
45
25
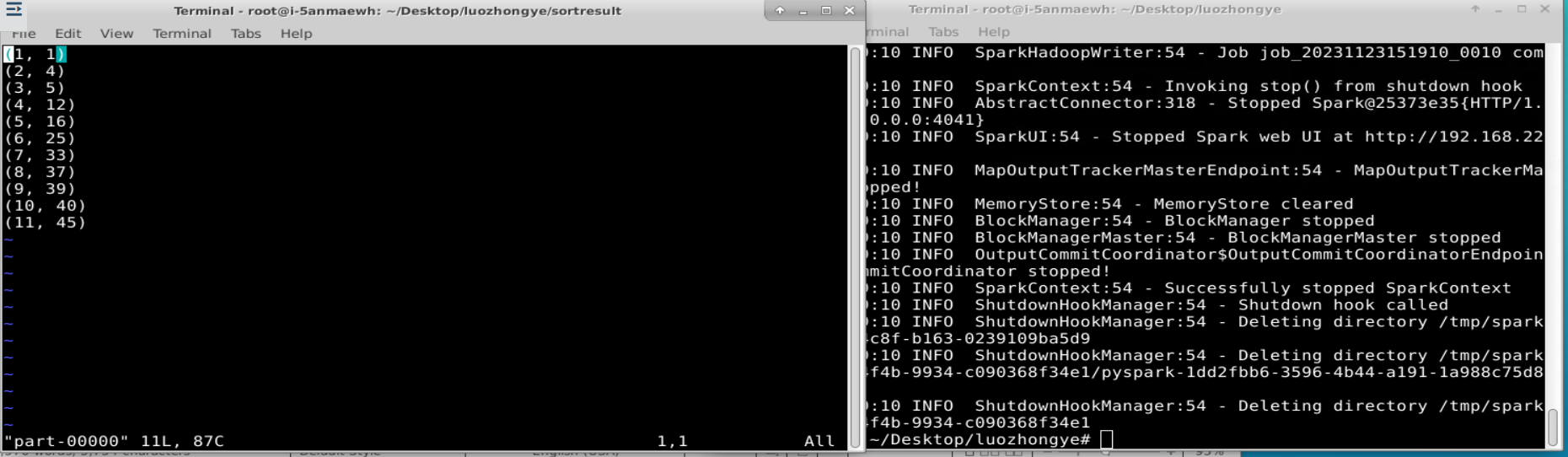
要求读取所有文件中的整数,进行排序后,输出到一个新的文件中,输出的内容为每行两个整数,第一个整数为第二个整数的排序位次,第二个整数为原待排序的整数。
实现上述功能的代码文件“/root/Desktop/luozhongye/FileSort.py”的内容如下:
#!/usr/bin/env python3
from pyspark import SparkConf, SparkContext
index = 0
def getindex():
global index
index += 1
return index
def main():
conf = SparkConf().setMaster("local[1]").setAppName("FileSort")
sc = SparkContext(conf=conf)
lines = sc.textFile("file:///root/Desktop/luozhongye/file*.txt")
index = 0
result1 = lines.filter(lambda line: (len(line.strip()) > 0))
result2 = result1.map(lambda x: (int(x.strip()), ""))
result3 = result2.repartition(1)
result4 = result3.sortByKey(True)
result5 = result4.map(lambda x: x[0])
result6 = result5.map(lambda x: (getindex(), x))
result6.foreach(print)
result6.saveAsTextFile("file:///root/Desktop/luozhongye/sortresult")
if __name__ == '__main__':
main()
三、完成p96实验内容3,即“编写独立应用程序实现求平均值问题”,注意每位同学自己修改题目中的数据。
每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个字段是学生名字,第二个字段是学生的成绩;编写 Spark 独立应用程序求出所有学生的平均成绩,并输出到一个新文件中。
数学成绩.txt:
小罗 110
小红 107
小新 100
小丽 99
英语成绩.txt:
小罗 95
小红 81
小新 82
小丽 76
政治成绩.txt:
小罗 65
小红 71
小新 61
小丽 66
408成绩.txt:
小罗 100
小红 103
小新 94
小丽 110
实现代码如下:
from pyspark import SparkConf, SparkContext
# 初始化Spark配置和上下文
conf = SparkConf().setAppName("AverageScore")
sc = SparkContext(conf=conf)
# 读取数学成绩文件
math_rdd = sc.textFile("数学成绩.txt").map(lambda x: (x.split()[0], int(x.split()[1])))
# 读取英语成绩文件
english_rdd = sc.textFile("英语成绩.txt").map(lambda x: (x.split()[0], int(x.split()[1])))
# 读取政治成绩文件
politics_rdd = sc.textFile("政治成绩.txt").map(lambda x: (x.split()[0], int(x.split()[1])))
# 读取408成绩文件
computer_rdd = sc.textFile("408成绩.txt").map(lambda x: (x.split()[0], int(x.split()[1])))
# 合并所有成绩数据
all_scores_rdd = math_rdd.union(english_rdd).union(politics_rdd).union(computer_rdd)
# 计算每个学生的成绩总和和成绩数量
sum_count_rdd = all_scores_rdd.combineByKey(lambda value: (value, 1),
lambda acc, value: (acc[0] + value, acc[1] + 1),
lambda acc1, acc2: (acc1[0] + acc2[0], acc1[1] + acc2[1]))
# 计算平均成绩
average_scores_rdd = sum_count_rdd.mapValues(lambda x: x[0] / x[1])
# 输出到新文件
average_scores_rdd.saveAsTextFile("平均成绩")
# 关闭Spark上下文
sc.stop()

实验心得
在这次实验中,我进一步熟悉了使用PySpark进行大数据处理和分析的方法,并深入了解了PySpark RDD的基本操作。学会了分区、持久化、数据写入文件,并解决实际问题。这次实验让我对PySpark有了更深入的理解,并增强了我处理和分析大数据的能力。
原文地址:https://blog.csdn.net/qq_45473330/article/details/134588685
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_12925.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!