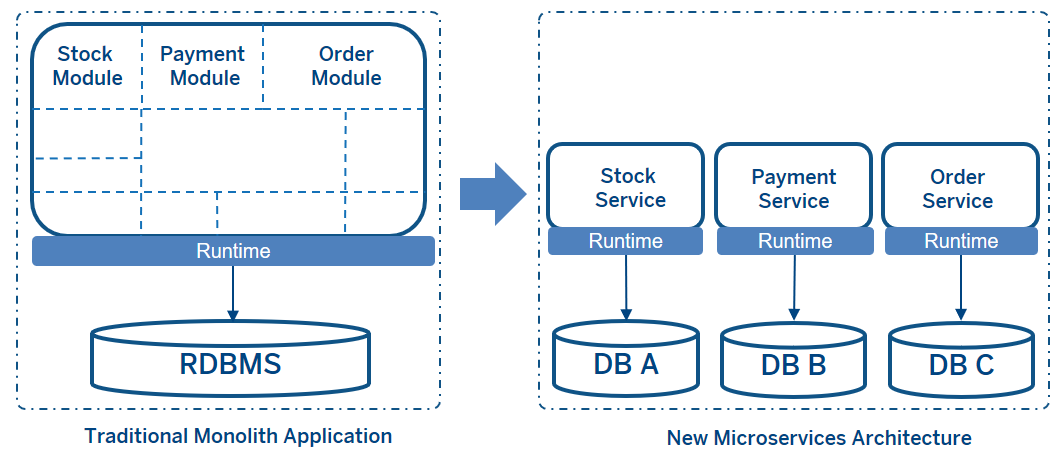
本文介绍: 当从传统的单体应用架构转移到微服务架构时,特别是涉及数据一致性时,数据一致性是微服务架构中最困难的部分。传统的单体应用中,一个共享的关系型数据库负责处理数据一致性。在微服务架构中,如果使用“每个服务一个数据库”的模式,那么每个微服务都有自己的数据存储。因此,数据库在应用程序之间是分布式的。如果每个应用程序使用不同的技术来管理它们的数据,比如非关系型数据库,这种分布式架构虽然在数据管理方面有许多好处…
问题:分布式系统中的数据一致性
对于单体应用程序,通过ACID事务,一个共享的关系型数据库处理并保证数据的一致性。ACID 是一个缩写,具体含义如下:
•A 原子性:事务的所有步骤要么全部成功,要么全部失败,没有部分状态,全有或全无。•C 一致性:事务结束时数据库中的所有数据都是一致的。•I 隔离性:同一时间只有一个事务可以访问数据,其他事务必须等待当前事务完成。•D 持久性:数据在事务结束时被持久化到数据库中。
为了保持强数据一致性,关系型数据库管理系统支持ACID特性。
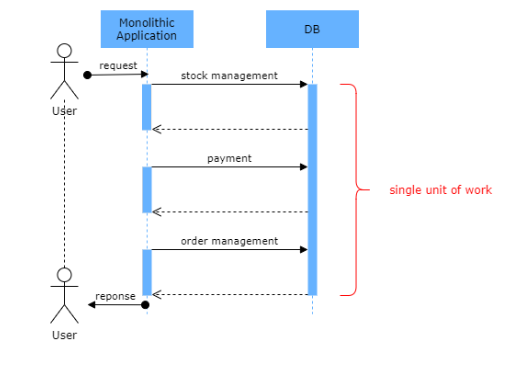
但在微服务架构中,每个微服务都有自己的数据存储,并采用不同的技术。因此,没有中央数据库,也没有单一的工作单元。业务逻辑被跨越到多个本地事务中。这意味着你不能在微服务架构中的数据库之间使用单一的事务工作单元。但你仍然需要在你的应用程序中使用ACID特性。
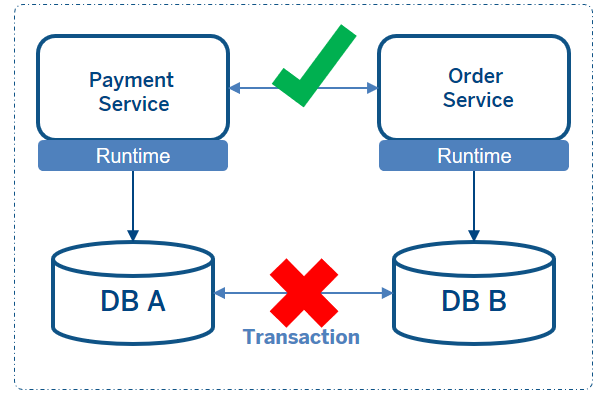
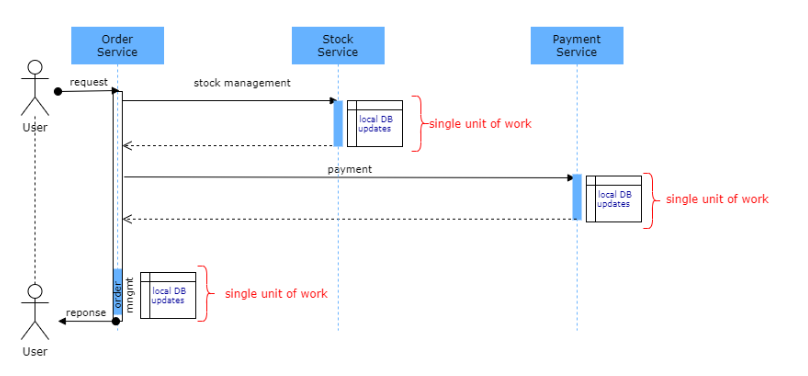
可能的解决方案
分布式事务
最终一致性
选择哪种解决方案
结论
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。