redis内存使用info memory命令参数解析
used_memory:236026888 由 Redis 分配器分配的内存总量,包含了redis进程内部的开销和数据占用的内存,以字节(byte)为单位
内存碎片率:
used_memory_rss/used_memory系统已经分配给了redis,但是redis未能够有效利用的内存
如何查看内存碎片率:
redis–cli info memory | grep ratio

rss是向系统申请的内存空间,Redis占用物理空间额外的开销比例,比例越低好,redis实际占用的物理内存和向系统申请的内存月接近,额外的开销越低
内存碎片的比例,越低越好,内存的使用率越高
如何自动清理碎片:
…..


如何手动清理碎片:

设置redis的内存最大阈值:
……..
#568行添加
![]()

key的回收策略
…….
maxmemory-policy volatile-lru:使用redis内资的lru算法,把已经设置了过期时间的键值对对中淘汰数据,移除最少使用的键值对。对已经设置了过期时间的键值对
maxmemory-policy volatile-ttl:已经设置了时间的键值对,从当中挑选一个即将过期的键值对,针对有设置过期时间的键值对
maxmemory-policy–volatile-random:从已经设置了过期时间的键值对当中,挑选数据随机淘汰键值对。对设置时间的键值对进行随机移除

面试:
3 内存碎片清理,手动.自动清理
Redis的报错问题:
1 雪崩:
缓存雪崩,大量的应用请求无法在redis缓冲中处理,会把所有的请求发送到后台数据库,数据库的压力会大,数据库本身并发能力差,一旦高并发,数据库会崩溃
redis集群大面积故障,Redis缓存中,大量数据同时过期,大量的请求无法得到处理。Redis实例宕机
1.1解决方案:
事前:高可用架构,防止整个缓存故障, ,主从复制,和哨兵模式,Redis集群。
事中:在国内用的比较多的方式,hystrix,熔断,限流三个手段来降低雪崩发生之后的损失,数据库不死即可,慢可以,但是不能没有响应
2 redis的缓存击穿(重要)
主要是热点数据缓存过期,或者删除,多个请求并发访问热点数据,请求转发到数据库,导致数据库的性能下降,经常请求的缓存数据,最好设置为永不过期
3 Redis的缓存穿透
缓存中没有数据,数据库也没有对应的数据,但是有用户一直发起这个请求,而且请求的数据是很大,一般是被黑客利用
Redis的主从复制
主从复制的作用:
是redis实现高可用的基础,哨兵模式和集群都是在主从复制的基础之上实现高可用,主从复制实现数据的多机备份,以及读写分离(主服务器负责写,从服务器只读)
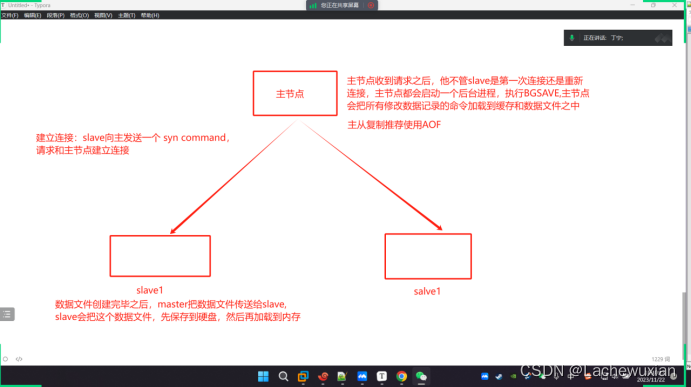
1 主节点:主节点收到请求之后,他不管slave是第一次连接还是重新连接,主节点都会启动一个后台进程,执行bgsave主节点会把所有修改数据记录的命令加载到缓存和数据文件之中,
建立连接:slave向主发送一个syn command,请求和主节点建立连接
数据文件创建完毕之后,master把数据文件传送到salve,slave 会把这个数据文件,先保存到硬盘,然后在加载到内存
实验架构:
192.168.233.7 主
192.168.233.8 从
192.168.233.9 从
主:




![]()
从1 和从2


![]()
![]()





哨兵模式
先有主从,再有哨兵,再主从复制的基础之上,实现主节点故障的自动切换,
哨兵模式的原理:
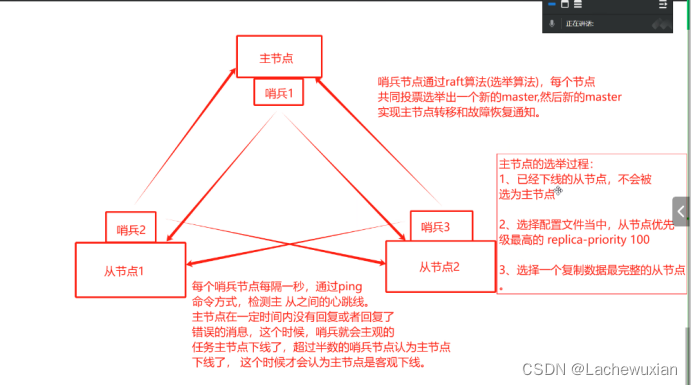
哨兵是一个分布式系统,用于在主从结构之间,对每台redis的服务器进行监控,主节点出现故障时,从节点通过投票的方式选择一个新的master 哨兵模式也需要至少三个节点,
哨兵模式的结构:
哨兵节点:监控节点,不存储数据
数据节点:主从节点,都是数据节点
主节点的选举过程:
1 已经下线的从节点,不会被选为主节点
2 选择配置文件当中,从节点优先级最高的replica–priority 100
3 选择一个复制数据最完整的从节点
哨兵节点通过raft算法(选举算法),每个节点共同投票选举出一个新的master,然后新的master实现主节点转移和故障恢复通知
每个哨兵节点每隔一秒,通过ping命令方式,检测主从之间的心跳线,主节点在一定时间内没有回复或者恢复了错误的信息,这个时候哨兵就会主观的判断主节点下线了,超过半数的节点哨兵认为主节点下线了,这个时候才会认为主节点是客观下线
主:






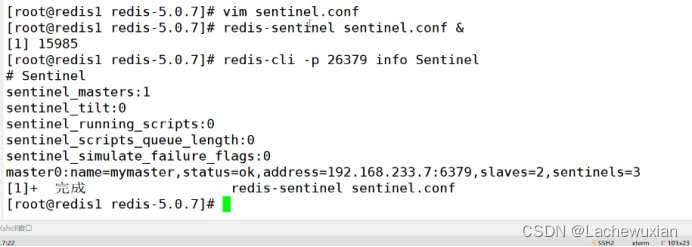
sentinel monitor mymaster 192.168.233.7 6379 2
#指向表示至少需要2台服务器认为主已经下线,才会进行主从切换。

从1和从2:






Redis 集群:
工作模式:
集群有多个node节点组成,Redis数据分布在这些节点上,在集群之中,分为主节点和从节点
集群模式中 主从一一对应,数据写的读取和主从模式一样,主负责写,从模式只能写,集群模式自带哨兵模式,可以自动实现故障切换,但是故障切换中,整个集群不能使用,切换完毕之后集群会立刻恢复
1 数据分片:是集群的核心功能,每个主都要提供读写的功能,但是数据一一对应写入对应的从节点,在集群模式中,可以容忍数据的不完整
2 高可用 :集群的主要目的
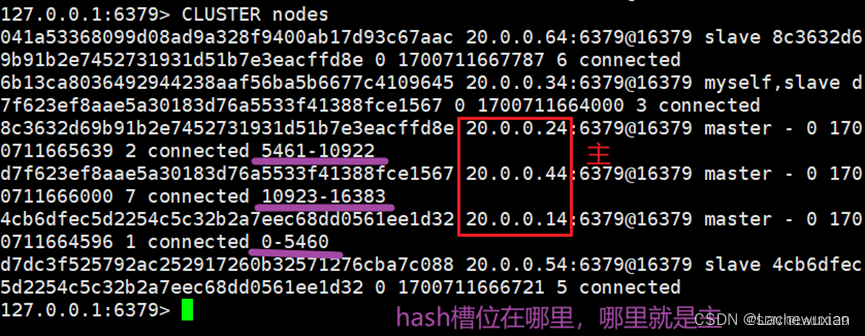
redis集群当中16384个哈希槽位(0-16384)
根据集群当中主节点从节点,分配哈希槽位,每个主从节点只负责一部分的
哈希槽位是连续的哈希槽位,如果出现不连续的哈希值,或者哈希槽位没有被分配,集群将会报错
主宕机之后,主节点原来负责的哈爷槽位将会不可用,需要从节点代替主节点继续负责原有的哈希操作。保证集群正常工作,故障切换的过程中,会提示集群不可用。切换完成,集群恢复继续工作。
每次读写都涉及到哈希槽位,Keyt通过crc16验证之后,对16384取余数,余数值决定数据放入哪个哈希槽位,通过这个值去找到对应的槽位所在的节点,然后直接跳转到这个节点
集群的流程:
1 集群自带主从和哨兵模式,
2 每个主从是互相隔的可以容忍数据的不完整,目的:高可用
3 哈希槽位为决定每个节点的读写槽位,在创建Key时,系统已经分配好了指定槽位
4 如果是出现MOVED不是报错,是提醒客户端取分配好的槽位节点,获取数据

实验
六台redis服务器都配置
vim /etc/redis/6379.conf
*****************************************************************************************
1、默认监听所有网卡—–70行
bind 0.0.0.0
2、关闭保护模式—–89行
protect-mode no
3、开启守护进程,以独立进程启动—–137行
daemonize yes
4、开启AOF持久化—–700行
appendonly yes
5、开启集群功能—–833行
cluster–enabled yes
6、集群名称文件设置—–841行
cluster–config–file nodes-6003.conf
7、集群超时时间设置—–847行(15000毫秒)
cluster–node–timeout 15000
*****************************************************************************************
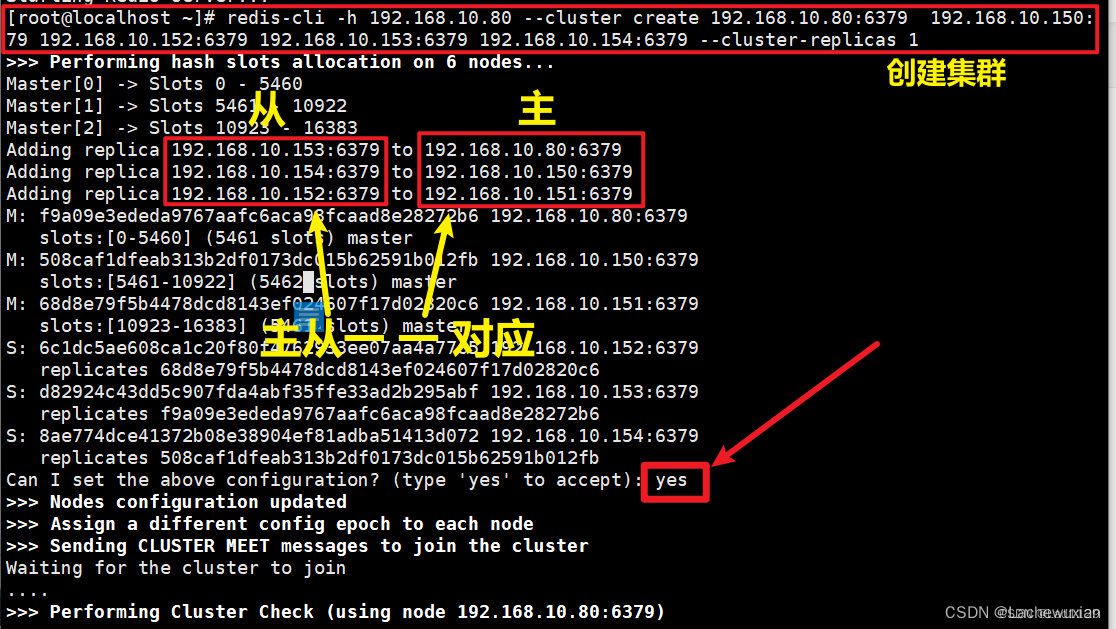
创建集群:redis-cli –h 所在服务器ip —cluster create ip地址:6379 —cluster-replicas 1
此时在192.168.10.80主机创建
redis-cli –h 192.168.10.80 —cluster create 192.168.10.80:6379 192.168.10.150:6379 179 192.168.10.152:6379 192.168.10.153:6379 192.168.10.154:6379 —cluster-replicas 1
[root@localhost ~]# redis-cli –h 192.168.10.80 —cluster create 192.168.10.80:6379 192.168.79 192.168.10.152:6379 192.168.10.153:6379 192.168.10.154:6379 —cluster-replicas 1
>>> Performing hash slots allocation on 6 nodes…
Master[0] -> Slots 0 – 5460
Master[1] -> Slots 5461 – 10922
Master[2] -> Slots 10923 – 16383
Adding replica 192.168.10.153:6379 to 192.168.10.80:6379
Adding replica 192.168.10.154:6379 to 192.168.10.150:6379
Adding replica 192.168.10.152:6379 to 192.168.10.151:6379
M: f9a09e3ededa9767aafc6aca98fcaad8e28272b6 192.168.10.80:6379
slots:[0-5460] (5461 slots) master
M: 508caf1dfeab313b2df0173dc015b62591b012fb 192.168.10.150:6379
slots:[5461-10922] (5462 slots) master
M: 68d8e79f5b4478dcd8143ef024607f17d02820c6 192.168.10.151:6379
slots:[10923-16383] (5461 slots) master
S: 6c1dc5ae608ca1c20f80f4762933ee07aa4a77c5 192.168.10.152:6379
replicates 68d8e79f5b4478dcd8143ef024607f17d02820c6
S: d82924c43dd5c907fda4abf35ffe33ad2b295abf 192.168.10.153:6379
replicates f9a09e3ededa9767aafc6aca98fcaad8e28272b6
S: 8ae774dce41372b08e38904ef81adba51413d072 192.168.10.154:6379
replicates 508caf1dfeab313b2df0173dc015b62591b012fb
Can I set the above configuration? (type ‘yes‘ to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
….
>>> Performing Cluster Check (using node 192.168.10.80:6379)
M: f9a09e3ededa9767aafc6aca98fcaad8e28272b6 192.168.10.80:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: 8ae774dce41372b08e38904ef81adba51413d072 192.168.10.154:6379
slots: (0 slots) slave
replicates 508caf1dfeab313b2df0173dc015b62591b012fb
S: 6c1dc5ae608ca1c20f80f4762933ee07aa4a77c5 192.168.10.152:6379
slots: (0 slots) slave
replicates 68d8e79f5b4478dcd8143ef024607f17d02820c6
M: 68d8e79f5b4478dcd8143ef024607f17d02820c6 192.168.10.151:6379
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: d82924c43dd5c907fda4abf35ffe33ad2b295abf 192.168.10.153:6379
slots: (0 slots) slave
replicates f9a09e3ededa9767aafc6aca98fcaad8e28272b6
M: 508caf1dfeab313b2df0173dc015b62591b012fb 192.168.10.150:6379
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots…
>>> Check slots coverage…
[OK] All 16384 slots covered.
[root@localhost ~]#
查看hash槽位CLUSTER nodes



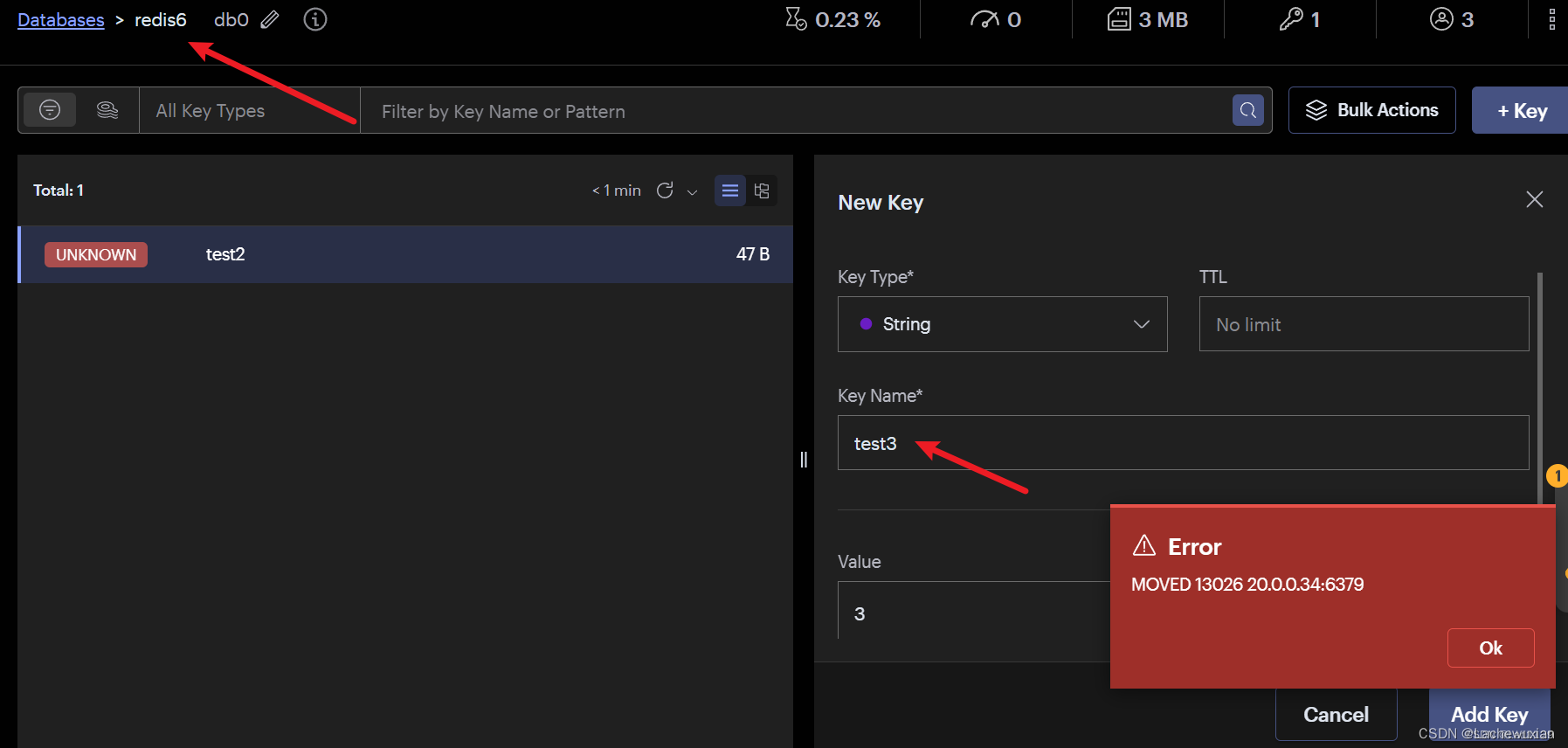
验证从节点不能读

此处error不是报错,表明客户端尝试读取键值对test1,但是实际槽位在4768,因此集群要求客户端移动到4768槽位所在的主机节点获取数据
(2)验证从节点能不能写。不能

(3)验证分配hash槽位后,不在相应的hash槽位上的主节点能不能写。不能,只能到指定节点上操作
主

从
模拟故障
主20.0.0.34——redis3故障,从20.0.0.44——redis4成为新主

monitor 查看哨兵的ping命令
主

从

原文地址:https://blog.csdn.net/Lachewuxian/article/details/134554592
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_14117.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!






