本文介绍: 该工具的功能是将结构化、半结构化的数据文件映射为一张数据库表,基于数据库表,提供了一种类似SQL的查询模型(HQL),用于访问和分析存储在Hadoop文件中的大型数据集。内部表的加载数据和创建表的过程是分开的,在加载数据时,实际数据会被移动到数仓目录中,之后对数据的访问是在数仓目录实现。Hive中的表所对应的数据是存储在HDFS中,而表相关的元数据是存储在关系数据库中。数据仓库是一个面向主题的、集成的、非易失的、随时间变化的,用来支持管理人员决策的数据集合,数据仓库中包含了粒度化的企业数据。
数据仓库是一个面向主题的、集成的、非易失的、随时间变化的,用来支持管理人员决策的数据集合,数据仓库中包含了粒度化的企业数据。
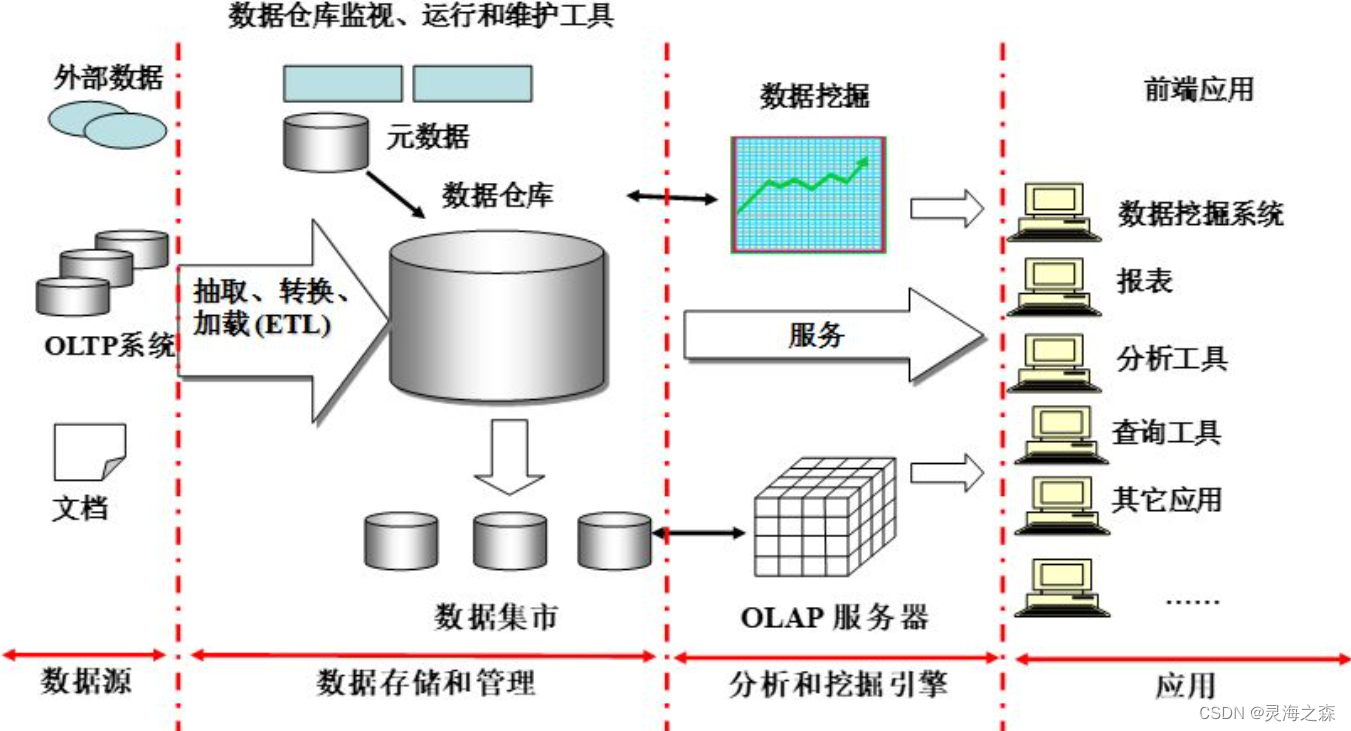
数据仓库的体系结构通常包含4个层次:数据源、数据存储和管理、数据服务以及数据应用。
1.概述
Hive是建立在Hadoop之上的一种数仓工具。该工具的功能是将结构化、半结构化的数据文件映射为一张数据库表,基于数据库表,提供了一种类似SQL的查询模型(HQL),用于访问和分析存储在Hadoop文件中的大型数据集。
Hive本身并不具备存储功能,其核心是将HQL转换为MapReduce程序,然后将程序提交到Hadoop集群中执行。
2.数据模型
①库
MySQL中默认数据库是default,用户可以创建不同的database,在database下也可以创建不同的表。Hive也可以分为不同的数据(仓)库,和传统数据库保持一致。在传统数仓中创建database。默认的数据库也是default。Hive中的库相当于关系数据库中的命名空间,它的作用是将用户和数据库的表进行隔离。
②表
Hive中的表所对应的数据是存储在HDFS中,而表相关的元数据是存储在关系数据库中。Hive中的表分为内部表和外部表两种类型,两者的区别在于数据的访问和删除:
内部表的加载数据和创建表的过程是分开的,在加载数据时,实际数据会被移动到数仓目录中,之后对数据的访问是在数仓目录实现。而外部表加载数据和创建表是同一个过程,对数据的访问是读取HDFS中的数据;
内部表删除时,因为数据移动到了数仓目录中,因此删除表时,表中数据和元数据会被同时删除。外部表因为数据还在HDFS中,删除表时并不影响数据。
创建表时不做任何指定,默认创建的就是内部表。想要创建外部表,则需要使用External进行修饰
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。







