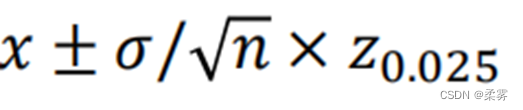本文介绍: 然后,计算了序列x的上四分位数和下四分位数,并根据这两个值计算了异常点的阈值。各位有什么急需的代码,欢迎后台留言~不定时更新科研技巧类推文,可以一起探讨科研,写作,文献,代码等诸多学术问题,我们一起进步。接着,计算每个样本点到其所属聚类中心的距离,并选择离散点阈值为0.8。将所有样本的距离误差与阈值进行比较,超过阈值的点被标记为离散点,并在图上用红色星号表示。横轴为时序号,纵轴为幅值,蓝色实线表示原始序列,红色星号表示异常值。横轴为时序号,纵轴为幅值,蓝色实线表示原始序列,红色点表示异常值。
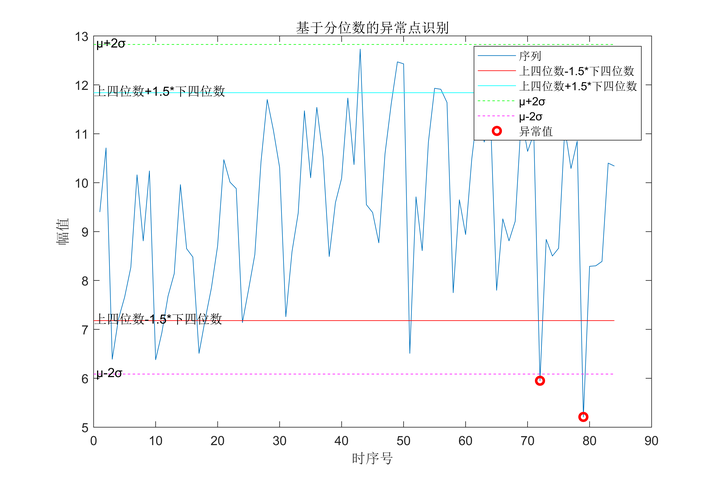
基于分位数的异常点识别
首先,给定了一个原始数据序列x。然后,计算了序列x的上四分位数和下四分位数,并根据这两个值计算了异常点的阈值。上四分位数减去1.5倍的四分位数范围得到异常值下界,下四分位数加上1.5倍的四分位数范围得到异常值上界。
接着,计算了序列x的均值和标准差,并以均值加减2倍标准差作为阈值。大于这个阈值的样本点被标记为异常值。
最后,将原始数据和标记的异常值进行可视化展示。横轴为时序号,纵轴为幅值,蓝色实线表示原始序列,红色点表示异常值。
代码效果图
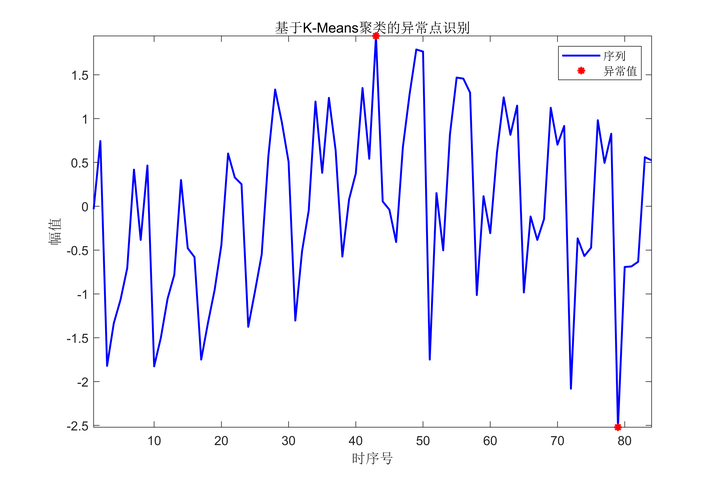
基于K-Means聚类的异常点识别
首先,将原始数据进行标准化,然后调用kmeans算法进行聚类。聚类的类别数为3,最大迭代次数为500,距离函数选择的是平方欧氏距离。
代码的效果图

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。