0 前言
循环神经网络(Recurrent Neural Network,RNN)是一种用于处理序列数据的神经网络。相比一般的神经网络来说,他能够处理序列变化的数据。比如某个单词的意思会因为上文提到的内容不同而有不同的含义,RNN就能够很好地解决这类问题。本质是一个全连接网络,但是因为当前时刻受历史时刻的影响。
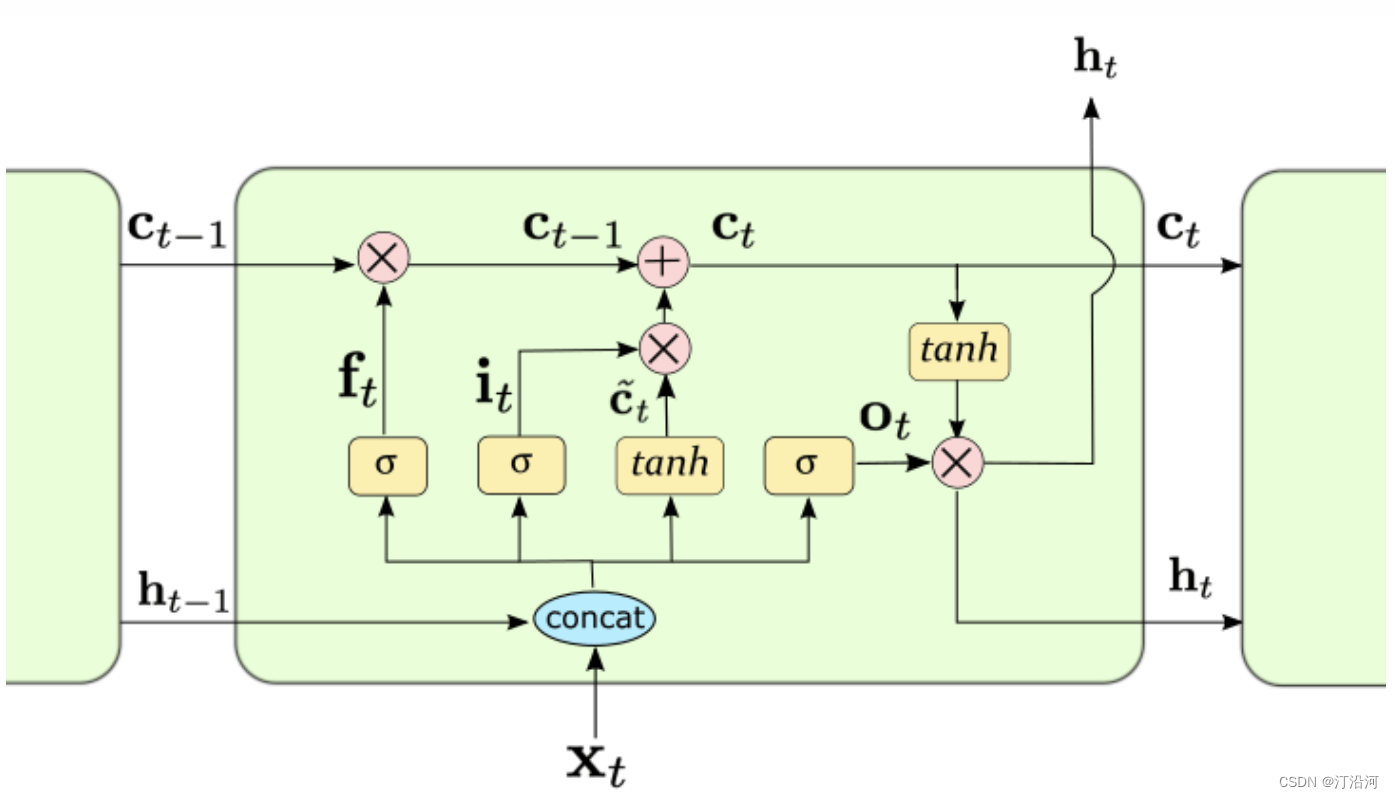
传统的RNN结构可以看做是多个重复的神经元构成的“回路”,每个神经元都接受输入信息并产生输出,然后将输出再次作为下一个神经元的输入,依次传递下去。这种结构能够在序列数据上学习短时依赖关系,但是由于梯度消失和梯度爆炸问题(梯度反向求导链式法则导致),RNN在处理长序列时难以达到很好的性能。而LSTM通过引入记忆细胞、输入门、输出门和遗忘门的概念(加号的引入),能够有效地解决长序列问题。记忆细胞负责保存重要信息,输入门决定要不要将当前输入信息写入记忆细胞,遗忘门决定要不要遗忘记忆细胞中的信息,输出门决定要不要将记忆细胞的信息作为当前的输出。这些门的控制能够有效地捕捉序列中重要的长时间依赖性,并且能够解决梯度问题。
备注:
输出门:控制当前时刻的内部状态 c有多少信息需要输出给外部状态;
遗忘门:控制上一个时刻的内部状态, ct−1需要遗忘多少信息;
nn.LSTM(input_size=embed_dim, hidden_size=hidden_size, num_layers=num_layers, batch_first=True)
hidden_size:隐状态的特征维度,根据工程经验可取 hidden_size = embed_dim * 2
num_layers: LSTM 的层数,一般设置为 1-4 层;
output, (hn, cn) = lstm(input)
input shape = (batch_size, times_stamp, embed_dim)
output = (batch_size, times_stamp, hidden_size)
output:表示隐藏层在各个 time step 上计算并输出的隐状态
1 模块介绍
数据: 2023“SEED”第四届江苏大数据开发与应用大赛–新能源赛道的数据
解题思路: 总共500个充电站状, 关联地理位置,然后提取18个特征;把这18个特征作为时步不长(记得是某个比赛的思路)然后特征长度为1 (类比词向量的size).
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
#import tushare as ts
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.model_selection import train_test_split
from torch.utils.data import TensorDataset
from tqdm import tqdm
import matplotlib.pyplot as plt
import tqdm
import sys
import os
import gc
import argparse
import warnings
warnings.filterwarnings('ignore')
# 读取数据
train_power_forecast_history = pd.read_csv('../data/data1/train/power_forecast_history.csv')
train_power = pd.read_csv('../data/data1/train/power.csv')
train_stub_info = pd.read_csv('../data/data1/train/stub_info.csv')
test_power_forecast_history = pd.read_csv('../data/data1/test/power_forecast_history.csv')
test_stub_info = pd.read_csv('../data/data1/test/stub_info.csv')
# 聚合数据
train_df = train_power_forecast_history.groupby(['id_encode','ds']).head(1)
del train_df['hour']
test_df = test_power_forecast_history.groupby(['id_encode','ds']).head(1)
del test_df['hour']
tmp_df = train_power.groupby(['id_encode','ds'])['power'].sum()
tmp_df.columns = ['id_encode','ds','power']
# 合并充电量数据
train_df = train_df.merge(tmp_df, on=['id_encode','ds'], how='left')
### 合并数据
train_df = train_df.merge(train_stub_info, on='id_encode', how='left')
test_df = test_df.merge(test_stub_info, on='id_encode', how='left')
h3_code = pd.read_csv("../data/h3_lon_lat.csv")
train_df = train_df.merge(h3_code,on='h3')
test_df = test_df.merge(h3_code,on='h3')
def kalman_filter(data, q=0.0001, r=0.01):
# 后验初始值
x0 = data[0] # 令第一个估计值,为当前值
p0 = 1.0
# 存结果的列表
x = [x0]
for z in data[1:]: # kalman 滤波实时计算,只要知道当前值z就能计算出估计值(后验值)x0
# 先验值
x1_minus = x0 # X(k|k-1) = AX(k-1|k-1) + BU(k) + W(k), A=1,BU(k) = 0
p1_minus = p0 + q # P(k|k-1) = AP(k-1|k-1)A' + Q(k), A=1
# 更新K和后验值
k1 = p1_minus / (p1_minus + r) # Kg(k)=P(k|k-1)H'/[HP(k|k-1)H' + R], H=1
x0 = x1_minus + k1 * (z - x1_minus) # X(k|k) = X(k|k-1) + Kg(k)[Z(k) - HX(k|k-1)], H=1
p0 = (1 - k1) * p1_minus # P(k|k) = (1 - Kg(k)H)P(k|k-1), H=1
x.append(x0) # 由输入的当前值z 得到估计值x0存入列表中,并开始循环到下一个值
return x
#kalman_filter()
train_df['new_label'] = 0
for i in range(500):
#print(i)
label = i
#train_df[train_df['id_encode']==labe]['power'].values
train_df.loc[train_df['id_encode']==label, 'new_label'] = kalman_filter(data=train_df[train_df['id_encode']==label]['power'].values)
### 数据预处理
train_df['flag'] = train_df['flag'].map({'A':0,'B':1})
test_df['flag'] = test_df['flag'].map({'A':0,'B':1})
def get_time_feature(df, col):
df_copy = df.copy()
prefix = col + "_"
df_copy['new_'+col] = df_copy[col].astype(str)
col = 'new_'+col
df_copy[col] = pd.to_datetime(df_copy[col], format='%Y%m%d')
#df_copy[prefix + 'year'] = df_copy[col].dt.year
df_copy[prefix + 'month'] = df_copy[col].dt.month
df_copy[prefix + 'day'] = df_copy[col].dt.day
# df_copy[prefix + 'weekofyear'] = df_copy[col].dt.weekofyear
df_copy[prefix + 'dayofweek'] = df_copy[col].dt.dayofweek
# df_copy[prefix + 'is_wknd'] = df_copy[col].dt.dayofweek // 6
df_copy[prefix + 'quarter'] = df_copy[col].dt.quarter
# df_copy[prefix + 'is_month_start'] = df_copy[col].dt.is_month_start.astype(int)
# df_copy[prefix + 'is_month_end'] = df_copy[col].dt.is_month_end.astype(int)
del df_copy[col]
return df_copy
train_df = get_time_feature(train_df, 'ds')
test_df = get_time_feature(test_df, 'ds')
train_df = train_df.fillna(999)
test_df = test_df.fillna(999)
cols = [f for f in train_df.columns if f not in ['ds','power','h3','new_label']]
# 是否进行归一化
scaler = MinMaxScaler(feature_range=(0,1))
scalar_falg = False
if scalar_falg == True:
df_for_training_scaled = scaler.fit_transform(train_df[cols])
df_for_testing_scaled= scaler.transform(test_df[cols])
else:
df_for_training_scaled = train_df[cols]
df_for_testing_scaled = test_df[cols]
#df_for_training_scaled
# scaler_label = MinMaxScaler(feature_range=(0,1))
# label_for_training_scaled = scaler_label.fit_transform(train_df['new_label']..values)
# label_for_testing_scaled= scaler_label.transform(train_df['new_label'].values)
# #df_for_training_scaled
class Config():
data_path = '../data/data1/train/power.csv'
timestep = 18 # 时间步长,就是利用多少时间窗口
batch_size = 32 # 批次大小
feature_size = 1 # 每个步长对应的特征数量,这里只使用1维,每天的风速
hidden_size = 256 # 隐层大小
output_size = 1 # 由于是单输出任务,最终输出层大小为1,预测未来1天风速
num_layers = 2 # lstm的层数
epochs = 10 # 迭代轮数
best_loss = 0 # 记录损失
learning_rate = 0.00003 # 学习率
model_name = 'lstm' # 模型名称
save_path = './{}.pth'.format(model_name) # 最优模型保存路径
config = Config()
x_train, x_test, y_train, y_test = train_test_split(df_for_training_scaled.values, train_df['new_label'].values,shuffle=False, test_size=0.2)
# 将数据转为tensor
x_train_tensor = torch.from_numpy(x_train.reshape(-1,config.timestep,1)).to(torch.float32)
y_train_tensor = torch.from_numpy(y_train.reshape(-1,1)).to(torch.float32)
x_test_tensor = torch.from_numpy(x_test.reshape(-1,config.timestep,1)).to(torch.float32)
y_test_tensor = torch.from_numpy(y_test.reshape(-1,1)).to(torch.float32)
# 5.形成训练数据集
train_data = TensorDataset(x_train_tensor, y_train_tensor)
test_data = TensorDataset(x_test_tensor, y_test_tensor)
# 6.将数据加载成迭代器
train_loader = torch.utils.data.DataLoader(train_data,
config.batch_size,
False)
test_loader = torch.utils.data.DataLoader(test_data,
config.batch_size,
False)
#train_df[cols]
# 7.定义LSTM网络
class LSTM(nn.Module):
def __init__(self, feature_size, hidden_size, num_layers, output_size):
super(LSTM, self).__init__()
self.hidden_size = hidden_size # 隐层大小
self.num_layers = num_layers # lstm层数
# feature_size为特征维度,就是每个时间点对应的特征数量,这里为1
self.lstm = nn.LSTM(feature_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x, hidden=None):
#print(x.shape)
batch_size = x.shape[0] # 获取批次大小 batch, time_stamp , feat_size
# 初始化隐层状态
if hidden is None:
h_0 = x.data.new(self.num_layers, batch_size, self.hidden_size).fill_(0).float()
c_0 = x.data.new(self.num_layers, batch_size, self.hidden_size).fill_(0).float()
else:
h_0, c_0 = hidden
# LSTM运算
output, (h_0, c_0) = self.lstm(x, (h_0, c_0))
# 全连接层
output = self.fc(output) # 形状为batch_size * timestep, 1
# 我们只需要返回最后一个时间片的数据即可
return output[:, -1, :]
model = LSTM(config.feature_size, config.hidden_size, config.num_layers, config.output_size) # 定义LSTM网络
loss_function = nn.L1Loss() # 定义损失函数
optimizer = torch.optim.AdamW(model.parameters(), lr=config.learning_rate) # 定义优化器
# 8.模型训练
for epoch in range(config.epochs):
model.train()
running_loss = 0
train_bar = tqdm(train_loader) # 形成进度条
for data in train_bar:
x_train, y_train = data # 解包迭代器中的X和Y
optimizer.zero_grad()
y_train_pred = model(x_train)
loss = loss_function(y_train_pred, y_train.reshape(-1, 1))
loss.backward()
optimizer.step()
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
config.epochs,
loss)
# 模型验证
model.eval()
test_loss = 0
with torch.no_grad():
test_bar = tqdm(test_loader)
for data in test_bar:
x_test, y_test = data
y_test_pred = model(x_test)
test_loss = loss_function(y_test_pred, y_test.reshape(-1, 1))
if test_loss < config.best_loss:
config.best_loss = test_loss
torch.save(model.state_dict(), save_path)
print('Finished Training')
train epoch[1/10] loss:293.638: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3727/3727 [01:41<00:00, 36.84it/s] 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 932/932 [00:12<00:00, 73.96it/s] train epoch[2/10] loss:272.386: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3727/3727 [01:49<00:00, 33.90it/s] 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 932/932 [00:12<00:00, 77.56it/s] train epoch[3/10] loss:252.972: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3727/3727 [01:43<00:00, 35.91it/s] 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 932/932 [00:13<00:00, 70.65it/s] train epoch[4/10] loss:235.282: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3727/3727 [01:45<00:00, 35.27it/s] 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 932/932 [00:09<00:00, 93.71it/s] train epoch[5/10] loss:219.069: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3727/3727 [01:34<00:00, 39.57it/s] 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 932/932 [00:08<00:00, 103.92it/s] train epoch[6/10] loss:203.969: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3727/3727 [01:30<00:00, 41.22it/s] 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 932/932 [00:09<00:00, 95.62it/s] train epoch[7/10] loss:189.877: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3727/3727 [01:35<00:00, 39.19it/s] 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 932/932 [00:12<00:00, 77.61it/s] train epoch[8/10] loss:176.701: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3727/3727 [01:52<00:00, 33.12it/s] 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 932/932 [00:11<00:00, 81.34it/s] train epoch[9/10] loss:164.382: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3727/3727 [01:41<00:00, 36.64it/s] 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 932/932 [00:08<00:00, 112.27it/s] train epoch[10/10] loss:152.841: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3727/3727 [01:25<00:00, 43.40it/s] 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 932/932 [00:09<00:00, 94.54it/s]
原文地址:https://blog.csdn.net/qq_28611929/article/details/134614634
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_17389.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!







