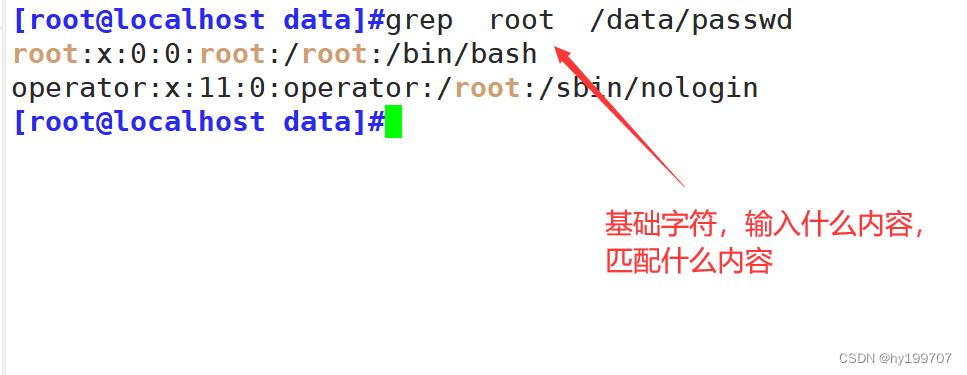
一、匹配场景
判断一个句子是不是正规英文句子
一个正常的英文句子如上,英文单词 + 空格隔开
那么一个句子就是单词 + 空格(一个或者多个,最后那个单词是0个)(可能有多个单词+空格)+ 最后一个句号 .
那正则就是
JAVA代码
public static void main(String[] args) {
String text = "I am a good student";
String regex = "^([a-zA-Z]+(\s)*)+$";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(text);
System.out.println(matcher.find());
System.out.println(matcher.group(0));
}二、性能测试
regex101: build, test, and debug regexRegular expression tester with syntax highlighting, explanation, cheat sheet for PHP/PCRE, Python, GO, JavaScript, Java, C#/.NET, Rust.![]() https://regex101.com/
https://regex101.com/
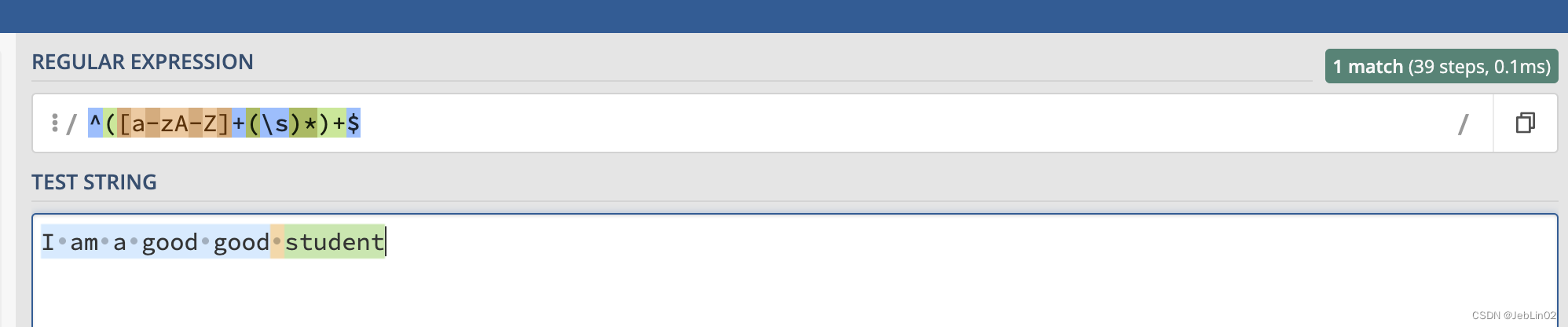
但是假如把句子拉长点,最后加上一个问号 ?

假如把句子再拉长点,那么直接就干爆CPU,耗时指数增长,
为啥会这样呢?
三、正则的回溯陷阱
1、了解下NFA与DFA
DFA(是电动机) 和NFA(汽油机) 都有很长的历史,不过,正如汽油机一样,NFA 的历史更长一些。也有些系统采用了混合引擎,它们会根据任务的不同选择合适的引擎(甚至对同一表达式中的不同部分采用不同的引擎,以求得功能与速度之间的最佳平衡)。 ——《精通正则表达式》
绝大多数编程语言都选择的引擎——NFA (非确定型有穷自动机) 引擎

2、NFA的回溯





3、简易例子分析
走了16w步,花了7.3ms

- 首先 (a*) 已经匹配到 aaaaaaaaaaaaaaa 了,
- (a*)+ 也匹配到 aaaaaaaaaaaaaaa ,
- 结束符$去匹配的时候,发现text不是结束,而是一个b
- 那吐出最后的a,变成 (aaaaaaaaaaaaaa) a ,没匹配上,继续吐
a* a*
(aaaaaaaaaaaaa) (aa)
a* a* a*
(aaaaaaaaaaaaa) (a)(a)
a* a*
(aaaaaaaaaaaa) (aaa)
a* a* a*
(aaaaaaaaaaaa) (aa)(a)
a* a* a* a*
(aaaaaaaaaaaa) (a)(a)(a)
--> 吐到最后
(a)(a)(a)(a)(a)(a)(a)(a)(a)(a)(a)(a)(a)(a)(a)直接干爆CPU
4、咋优化?
1、对于 ^(a*)+$
直接把表达式
^(a*)+$
改成 ^(a*)$
把后面的 + 号去掉。

2、对于 ^([a-zA-Z]+(s)*)+$
把后面的 + 号去掉。就不回溯了,
但是匹配不上,因为语句有问题,就是空格必须存在,但是最后的空格不存在

所以改成 :^[a-zA-Z]+(s[a-zA-Z]+)*$
遇到问号也不回溯

去掉问号也匹配上了

原文地址:https://blog.csdn.net/Sword52888/article/details/134631651
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_17461.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!