1. 前言
现在我们在网页端看的视频,其前端实现原理就小编目前知道的而言,总的有两点:其一,直接就是一个mp4(或其他类似的)视频链接,如果我们能得到这个视频链接,直接用这个链接就能下载到这个视频;其二,和第一点差不多吧!但是直接用链接下载,获取不到视频文件,而是一个其他类型的文件(比如m3u8文件),虽然不能直接下载到视频,但是通过进一步处理,最后还是能得到视频文件的。最近,看到了一个视频平台,觉得这个平台挺好的,没有广告,想得到在这个平台的视频文件,但是其原理属于第二种情况,且网站进行相对复杂的加密处理,怎样才能得到这个平台上的视频的m3u8文件呢?

2. js逆向分析
通过一些分析,可以发现,要想得到这个m3u8文件,首先需要得到m3u8链接,要想得到m3u8链接,前提是明白这个链接中的一些参数的来源,然而这些参数来源却是一个请求接口链接的结果数据,为此,需要得到这个接口链接,可是这个接口链接的一些请求参数却做了严格的加密处理,如下:
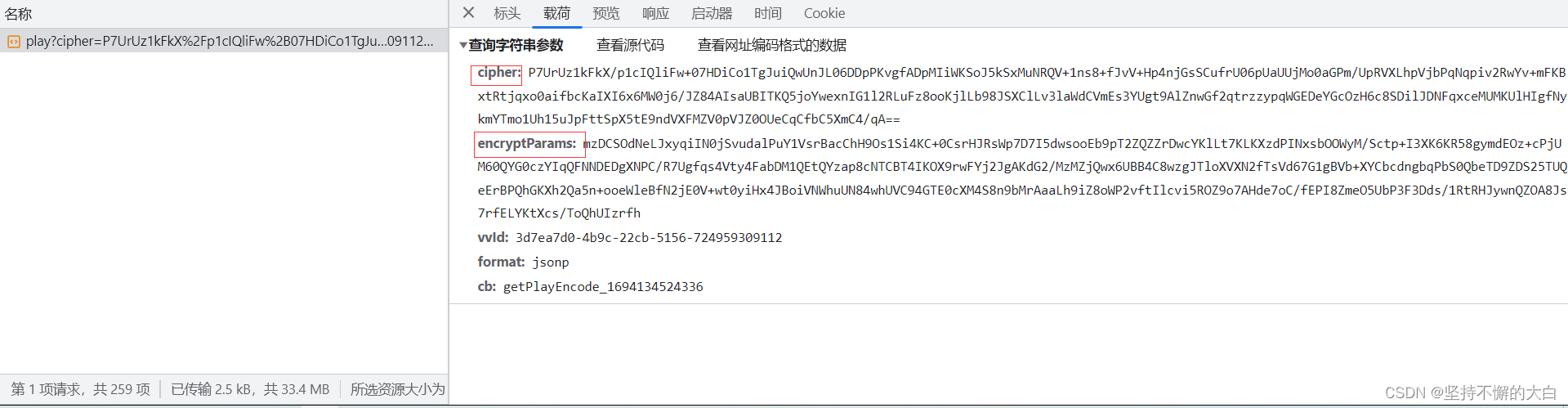
主要是上述图片中画上红框的两个参数值,通过一些js逆向分析,最后可以定位到这里。
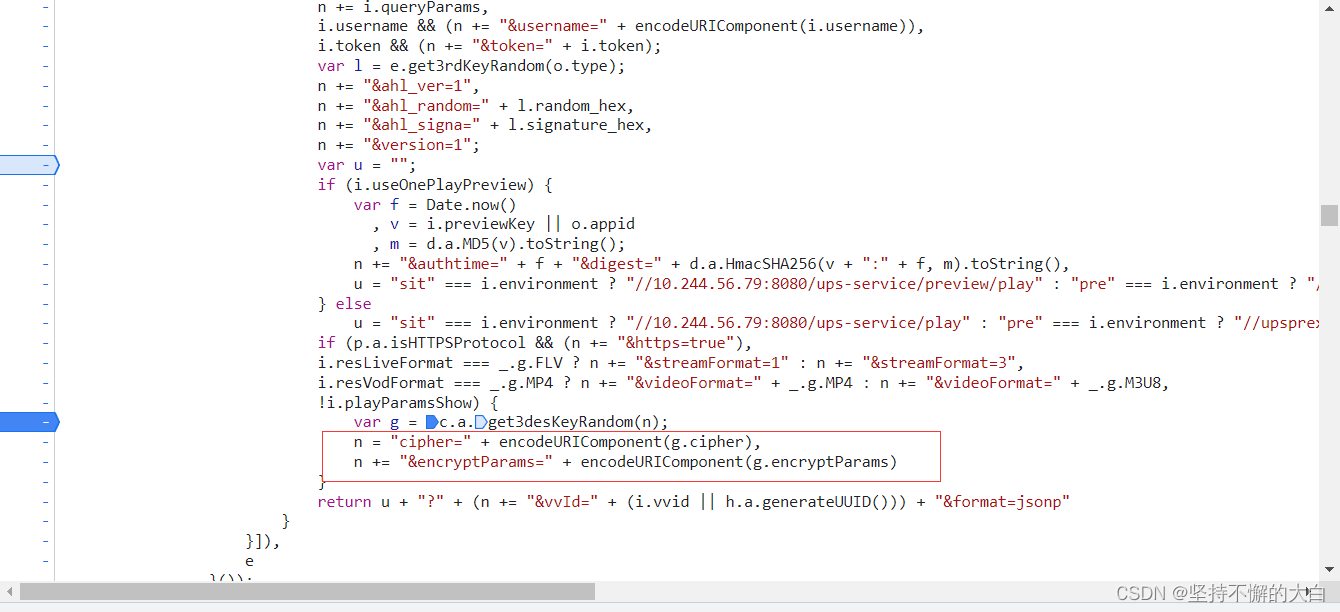
因为其中做了较为复杂的加密处理,如果要详细讲解,可能本篇博文很长,为此,只是简化讲解而已。这两个参数值用Python模拟加密之后,进行链接组合,最后可以得到这个接口链接,请求这个接口链接,可以得到如下数据:
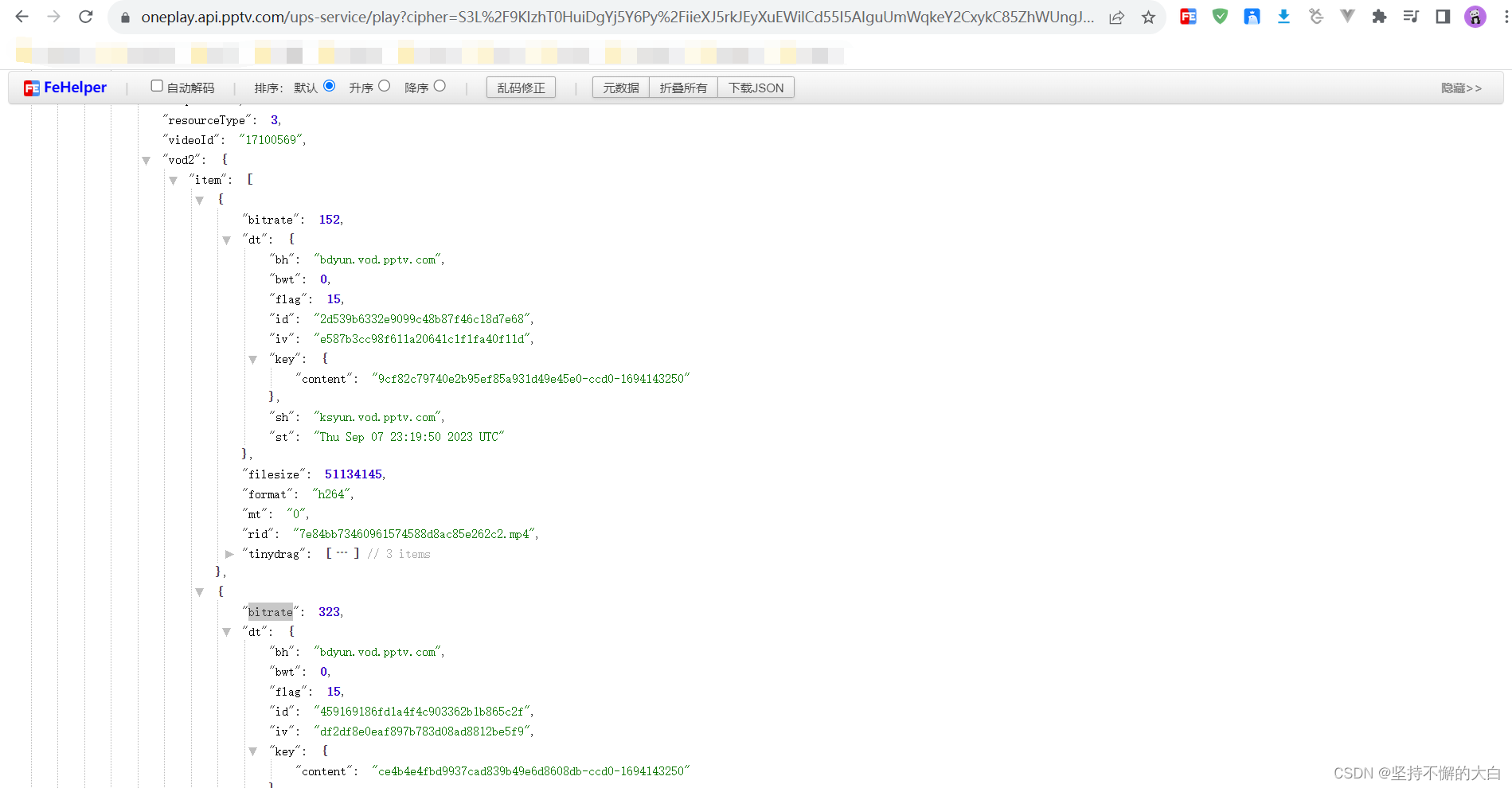
在上述json数据找到一些在m3u8链接中需要用到的参数值,通过Python模拟加密,然后再进行组合,最后便可以得到最终想要的m3u8链接。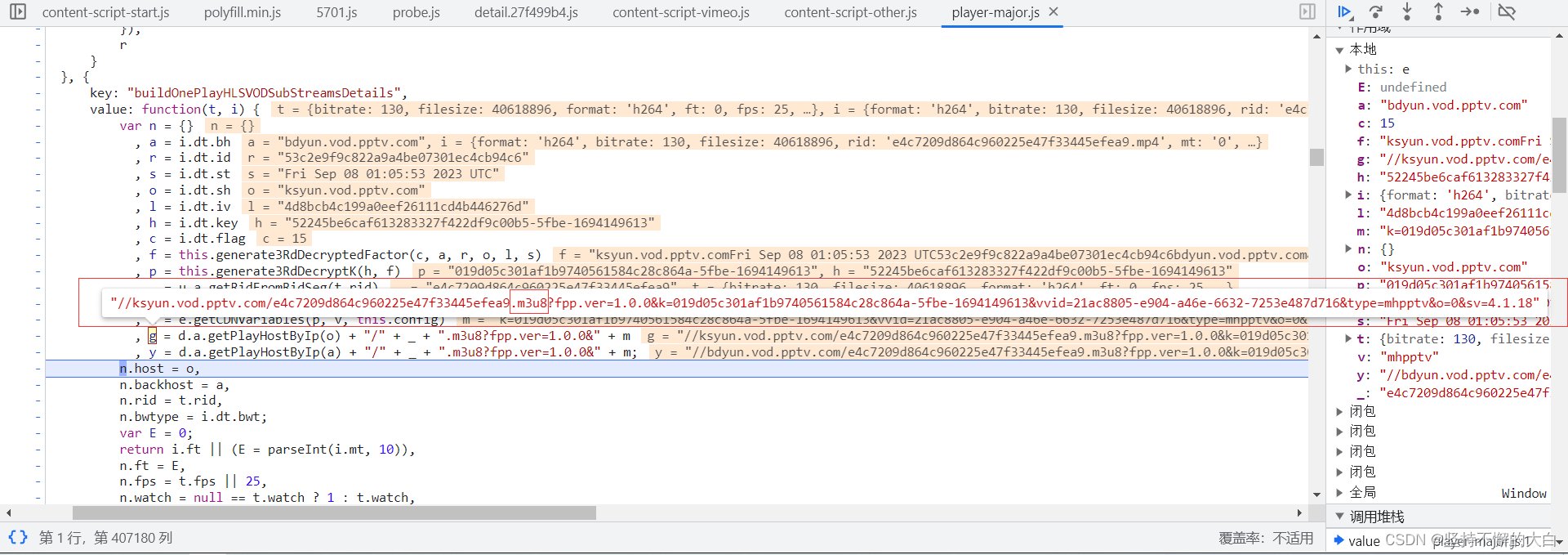
Python模拟
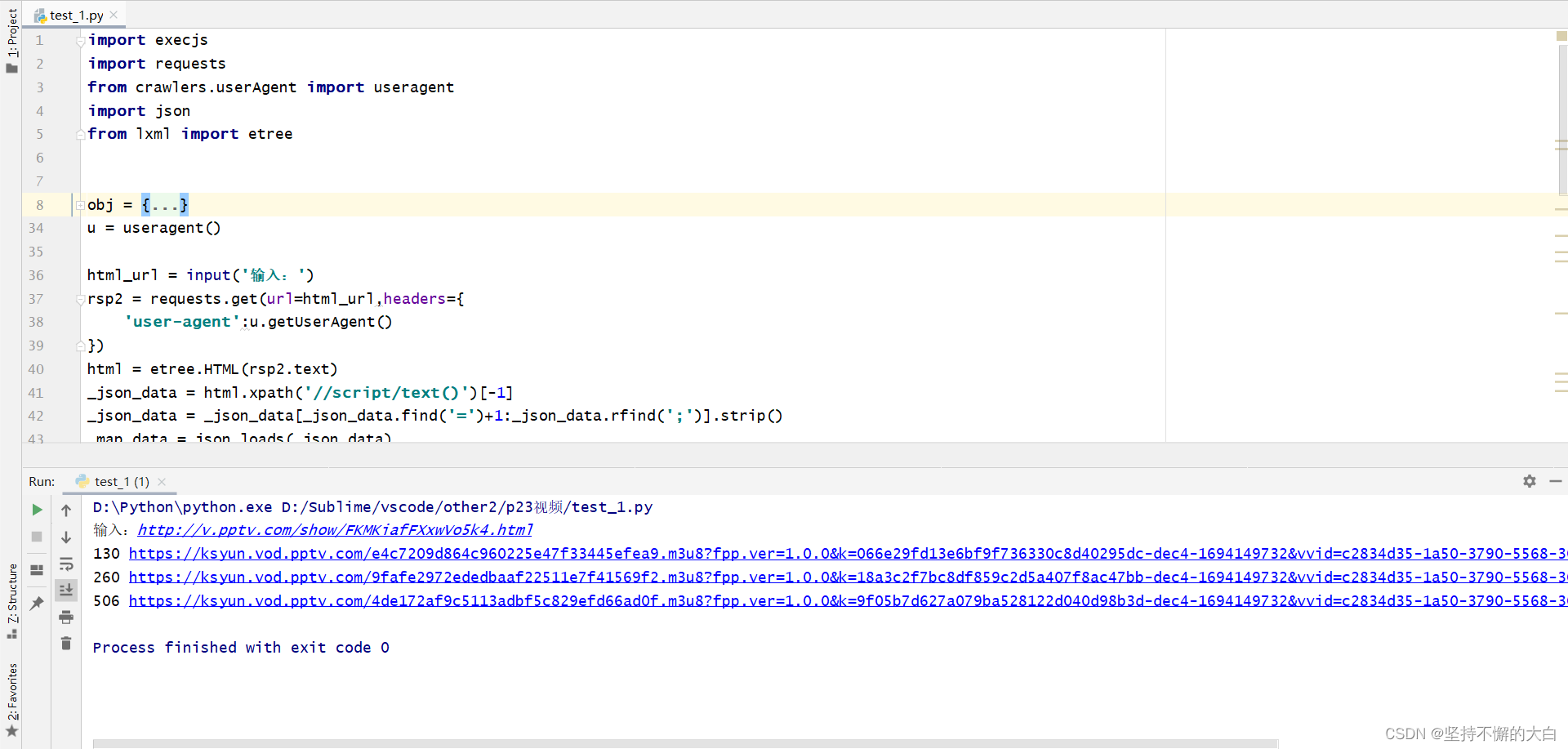
因为其中一些参数进行随机化处理,所以上述两张图片中m3u8链接并不是相同的,但是都是可以正常访问的。
3. 参考代码和运行结果
import execjs
import requests
from crawlers.userAgent import useragent
import json
from lxml import etree
obj = {
"webSite": "ppVideo_PC_site",
"queryParams": "&o=0&contCoprChl=pptv.web",
"username": "",
"token": "",
"startPosition": 0,
"resLiveFormat": "flv",
"resVodFormat": "m3u8",
"skipMovieTitle": True,
"autoPlay": False,
"useP2P": False,
"environment": "prd",
"useOnePlay": True,
"ppi": "302c3532",
"o": "0",
"playerVersion": "4.1.18",
"vvid": "c2834d35-1a50-3790-5568-30f2c2a0ce1b",
"playApiConfig": {
"appid": "pptv.web.h5",
"channel": "sn.cultural",
"type": "mhpptv"
},
"useOnePlayPreview": False,
"playParamsShow": False,
"previewKey": ""
}
u = useragent()
html_url = input('输入:')
rsp2 = requests.get(url=html_url,headers={
'user-agent':u.getUserAgent()
})
html = etree.HTML(rsp2.text)
_json_data = html.xpath('//script/text()')[-1]
_json_data = _json_data[_json_data.find('=')+1:_json_data.rfind(';')].strip()
_map_data = json.loads(_json_data)
cid = _map_data['cid']
with open(file='./test.js',mode='r',encoding='utf-8') as f:
_js_str = f.read()
ctx = execjs.compile(_js_str)
url = ctx.call('getWebPlayInfoAddr',cid,obj)
rsp = requests.get(url=f'https:{url}',headers = {
'user-agent':u.getUserAgent()
})
_res_str = rsp.text
_res_str = _res_str[_res_str.find('(')+1:_res_str.rfind(')')]
_map = json.loads(_res_str)
items = _map['data']['program']['media']['resource']['vod2']['item']
with open(file='./test2.js',mode='r',encoding='utf-8') as f:
_js_str2 = f.read()
ctx2 = execjs.compile(_js_str2)
for e in items:
rid = e['rid']
v_id = rid[:rid.rfind('.')]
e_obj = e['dt']
flag,bh,id,sh,iv,st,key = e_obj['flag'],e_obj['bh'],e_obj['id'],e_obj['sh'],e_obj['iv'],e_obj['st'],e_obj['key']['content']
params = ctx2.call('buildOnePlayVodSubStreamDetails',flag,bh,id,sh,iv,st,key)
print(e['bitrate'],'https://ksyun.vod.pptv.com/{}.m3u8?fpp.ver=1.0.0&{}'.format(v_id,params))
【注】其中有两个js文件,因为代码量实在是太大了,所以就没有粘贴出来了。上述代码最终能得到视频的m3u8链接,如果读者想用这个m3u8链接最终得到视频文件,可以去看看小编这篇文章,文章链接为:Python爬虫:通过js逆向我发现了斗鱼视频请求参数的加密原理,当然,读者也可以考虑直接使用PotPlayer这个软件来播放这个m3u8链接。
Python爬虫:通过js逆向获取pp视频平台上的视频的m3u8链接
原文地址:https://blog.csdn.net/qq_45404396/article/details/132752252
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_1763.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!