实战kaggle比赛:树叶分类
- image文件夹:27153张叶子图片,编号为: 0到27152
- sample_submission.csv(提交文件): 有8800个样本(18353到27152),2列(图片名称、预测类别)
- test.csv(测试文件):有8800个样本(18353到27152),1列(图片名称)
- train.csv(训练文件): 有18353个样本(0到18352),2列(图片名称,所属类别)
解题思路:
1. 导入相关库
import torch
import torch.nn as nn
import pandas as pd
import numpy as np
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
import os
import matplotlib.pyplot as plt
import torchvision.models as models
# 下面时用来画图和显示进度条的两个库
from tqdm import tqdm # 一个用于迭代过程中显示进度条的工具库
import seaborn as sns # 在matplotlib基础上面的封装库,方便直接传参数调用
2. 查看数据格式
# 查看label文件格式
labels_dataframe = pd.read_csv("E:\219\22chenxiaoda\experiment\pythonProject\data\classify-leaves\classify-leaves/train.csv")
labels_dataframe.head()

# 查看labels摘要:数值列的统计汇总信息
labels_dataframe.describe()

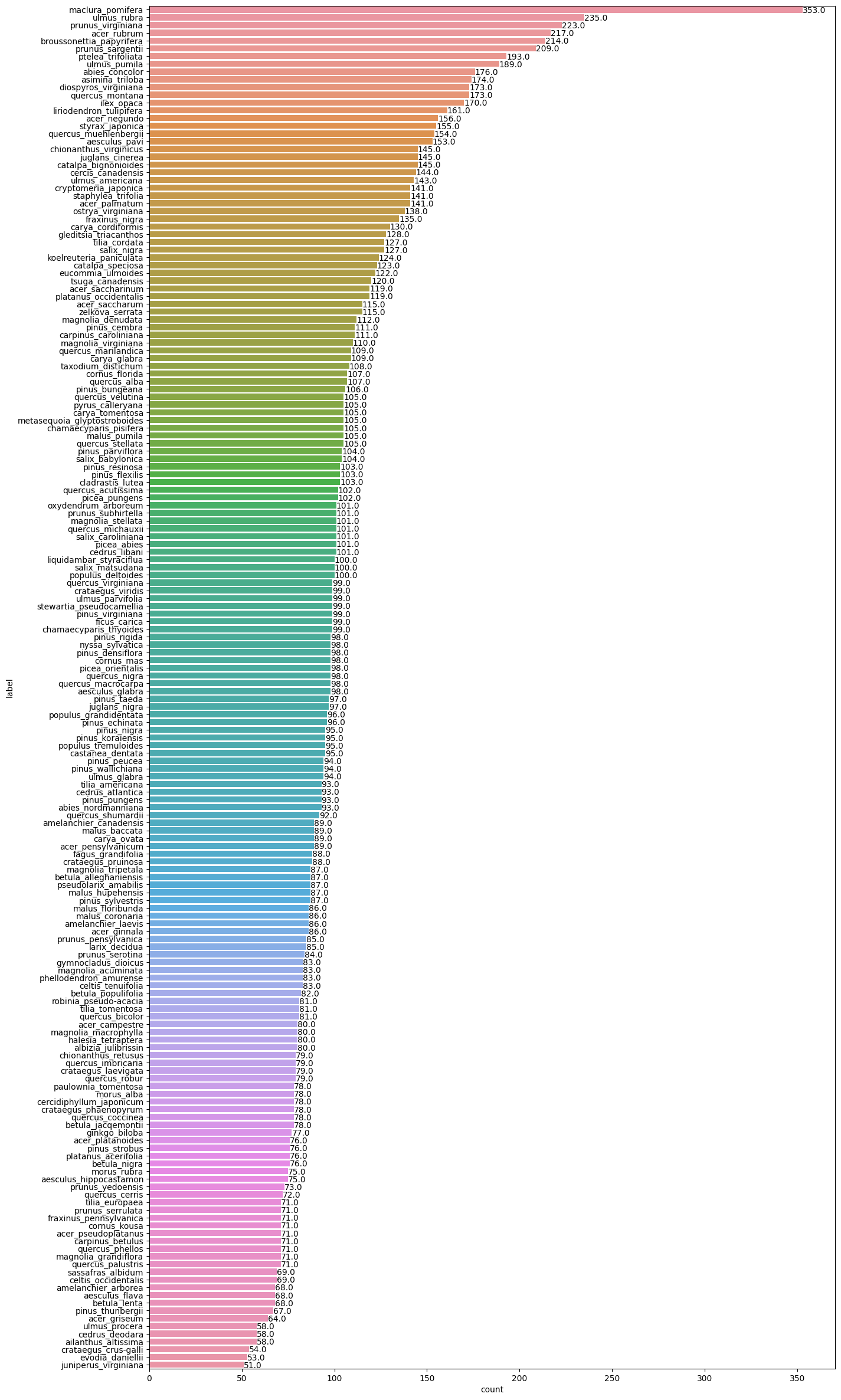
# 用横向柱状图可视化不同类别中图片个数
def barw(ax):
for p in ax.patches:
val = p.get_width() # 柱状图的高度即种类钟图片的数量
x = p.get_x() + p.get_width() # x位置
y = p.get_y() + p.get_height() # y位置
ax.annotate(round(val, 2), (x, y)) # 注释文本的内容,被注释的坐标点
plt.figure(figsize=(15, 30))
# sns.countplot()函数: 以bar的形式展示每个类别的数量
ax0 = sns.countplot(y=labels_dataframe['label'], order=labels_dataframe['label'].value_counts().index)
barw(ax0)
plt.show()
# 将label文件排序
# set():函数创建一个无序不重复元素集
# list():创建列表
# sorted():返回一个排序后的新序列,不改变原始序列(默认按照字母升序)
leaves_labels = sorted(list(set(labels_dataframe['label'])))
n_classes = len(leaves_labels)
print(n_classes)
leaves_labels[:5]

# 将label文件排序
# set():函数创建一个无序不重复元素集
# list():创建列表
# sorted():返回一个排序后的新序列,不改变原始序列(默认按照字母升序)
leaves_labels = sorted(list(set(labels_dataframe['label'])))
n_classes = len(leaves_labels)
print(n_classes)
leaves_labels[:5]

# 再将数字转换成对应的标签:方便最后预测的时候应用
num_to_class = {v : k for k,v in class_to_num.items()}
num_to_class
3. 制作数据集
# 继承pytorch的dataset,创建自己的
class LeavesData(DataLoader):
def __init__(self, csv_path, file_path, mode='train', valid_ratio=0.2, resize_height=256, resize_with=256):
"""
:param csv_path: csv文件路径
:param file_path: 图像文件所在路径
:param valid_ratio: 验证集比例
:param resize_height:
:param resize_with:
"""
self.resize_height = resize_height
self.resize_weight = resize_with
self.file_path = file_path
self.mode = mode
# 读取csv文件
# 利用pandas读取csv文件
# pandas.read_csv(“data.csv”)默认情况下,会把数据内容的第一行默认为字段名标题。
# 添加“header=None”,告诉函数,我们读取的原始文件数据没有列索引。因此,read_csv为自动加上列索引。
# self.data_info = pd.read_csv(csv_path, header=None)
self.data_info = pd.read_csv(csv_path)
# 计算length
self.data_len = len(self.data_info.index)
self.train_len = int(self.data_len * (1 - valid_ratio))
if mode == 'train':
# 第一列包含图像文件的名称
# 数据源是ndarray时,array仍然会copy出一个副本,占用新的内存,但asarray不会。
self.train_image = np.asarray(self.data_info.iloc[0: self.train_len, 0])
self.train_label = np.asarray(self.data_info.iloc[0:self.train_len, 1])
self.image_arr = self.train_image
self.label_arr = self.train_label
elif mode == 'valid':
self.valid_image = np.asarray(self.data_info.iloc[self.train_len:, 0])
self.valid_label = np.asarray(self.data_info.iloc[self.train_len:, 1])
self.image_arr = self.valid_image
self.label_arr = self.valid_label
elif mode == 'test':
self.test_image = np.asarray(self.data_info.iloc[0:, 0])
self.image_arr = self.test_image
self.real_len = len(self.image_arr)
print(f' Finished reading the {mode} set of Leaves Dataset ({self.real_len} samples found)')
def __getitem__(self, index):
# 从image_arr中得到索引对应的文件名
single_image_name = self.image_arr[index]
# 读取图像文件
img_as_img = Image.open(self.file_path + single_image_name)
# 设置好需要转换的变量, 还包括一系列的normalize等操作
if self.mode == 'train':
transform = transforms.Compose([
transforms.Resize(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
else:
transform = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
img_as_img = transform(img_as_img)
if self.mode == 'test':
return img_as_img
else:
# 得到train和valid的字符串label
label = self.label_arr[index]
# 字符串label-->数字label
number_label = class_to_num[label]
return img_as_img, number_label # 返回每一个index对应的照片数据和对应的label
def __len__(self):
return self.real_len
train_path = "E:\219\22chenxiaoda\experiment\pythonProject\data\classify-leaves\classify-leaves/train.csv"
test_path = "E:\219\22chenxiaoda\experiment\pythonProject\data\classify-leaves\classify-leaves/test.csv"
# csv文件中已经定义到image的路径, 因此这里知道上一级目录
img_path = 'E:\219\22chenxiaoda\experiment\pythonProject\data\classify-leaves\classify-leaves/'
train_dataset = LeavesData(train_path, img_path, mode='train')
val_dataset = LeavesData(train_path, img_path, mode='valid')
test_dataset = LeavesData(test_path, img_path, mode='test')
print(train_dataset)
print(val_dataset)
print(test_dataset)

# 定义dataloader
train_loader = torch.utils.data.DataLoader(
dataset=train_dataset, batch_size=32, shuffle=True
)
val_loader = torch.utils.data.DataLoader(
dataset=val_dataset, batch_size=32,shuffle=False
)
test_loader = torch.utils.data.DataLoader(
dataset=test_dataset, batch_size=32, shuffle=False
)
4. 数据可视化
# 展示数据
def im_covert(tensor):
"""展示数据"""
image = tensor.to("cpu").clone().detach()
image = image.numpy().squeeze()
image = image.transpose(1, 2, 0)
image = image * np.array((0.229, 0.224, 0.225)) + np.array((0.485, 0.456, 0.406)) # 还原标准化,先乘再加
image = image.clip(0, 1)
return image
fig = plt.figure(figsize=(20, 12))
columns = 4
rows = 2
dataiter = iter(val_loader)
inputs, classes = dataiter.next()
for idx in range(columns * rows):
ax = fig.add_subplot(rows, columns, idx+1, xticks=[], yticks=[])
ax.set_title(num_to_class[int(classes[idx])])
plt.imshow(im_covert(inputs[idx]))
plt.show()

5. 定义网络模型
# 是否使用GPU来训练
def get_device():
return 'cuda' if torch.cuda.is_available() else 'cpu'
device = get_device()
print(device)
# 是否要冻住模型的前面一些层
def set_parameter_requires_grad(model, feature_extracting):
if feature_extracting:
model = model
for param in model.parameters():
param.requires_grad = False
# 选用resnet34模型
# 是否要冻住模型的前面一些层
def set_parameter_requires_grad(model, feature_extracting):
if feature_extracting:
model = model
for param in model.parameters():
param.requires_grad = False
# 使用resnet34模型
def res_model(num_classes, feature_extract=False):
model_ft = models.resnet34(weights=models.ResNet34_Weights.IMAGENET1K_V1)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, num_classes)
return model_ft
# 模型初始化
model = res_model(176)
model = model.to(device)
model.device = device
model
6. 定义超参数
learning_rate = 3e-4
weight_decay = 1e-3
num_epoch = 50
model_path = './pre_res_model_32.ckpt'
criterion = nn.CrossEntropyLoss()
不冻住前面的预训练层
– 对预训练层, 使用较小的学习率训练
– 对自定义的分类输出层, 使用较大的学习率
# 对最后定义的全连接层和之前的层采用不同的学习率训练
params_1x = [param for name, param in model.named_parameters()
if name not in ['fc.weight', 'fc.bias']]
optimizer = torch.optim.Adam(
# model.parameters(),
[{'params': params_1x}, {'params': model.fc.parameters(), 'lr': learning_rate * 10}],
lr=learning_rate, weight_decay=weight_decay
)
7. 训练模型
import time
# 在开头设置开始时间
start = time.perf_counter() # start = time.clock() python3.8之前可以
best_acc, best_epoch = 0.0, 0
train_loss, train_accs = [], []
valid_loss, valid_accs = [], []
for epoch in range(num_epoch):
# -----------训练-----------
model.train()
train_loss = []
train_accs = []
for imgs, labels in tqdm(train_loader):
# 一个batch由imgs和相应的labels组成。
imgs = imgs.to(device)
labels = labels.to(device)
# 前向传播
predicts = model(imgs)
# 计算损失
loss = criterion(predicts, labels)
# 梯度清空
optimizer.zero_grad()
# 反向传播
loss.backward()
# 梯度更新
optimizer.step()
# 计算当前batch的精度
# 转为float就是把true变成1,false变成0;
# 然后mean就是求这个向量的均值,也就是true的数目除以总样本数,得到acc。
acc =(predicts.argmax(dim=1) == labels).float().mean()
# 记录训练损失和精度
train_loss.append(loss.item())
train_accs.append(acc)
# 训练集的平均损失和准确性是一个batch的平均值
train_loss = sum(train_loss) / len(train_loss)
train_acc = sum(train_accs) / len(train_accs)
# 打印训练损失和精度
print(f'[Train | {epoch + 1 :03d} / {num_epoch:03d}] Train loss = {train_loss:.5f}, Train acc={train_acc:.5f}')
# --------验证--------
model.eval()
valid_loss = []
valid_accs = []
for batch in tqdm(val_loader):
imgs, labels = batch
# 前向传播
# 验证不需要计算梯度
# 使用torch.no_grad()不计算梯度,能加速前向传播过程
with torch.no_grad():
predicts = model(imgs.to(device))
# 计算损失
loss = criterion(predicts, labels.to(device))
# 计算精度
acc = (predicts.argmax(dim=-1) == labels.to(device)).float().mean()
# 记录验证损失和精度
valid_loss.append(loss.item())
valid_accs.append(acc)
# 跟训练集一样: 验证集的平均损失和准确性是一个batch的平均值
valid_loss = sum(valid_loss) / len(valid_loss)
valid_acc = sum(valid_accs) / len(valid_accs)
# 打印验证损失和精度
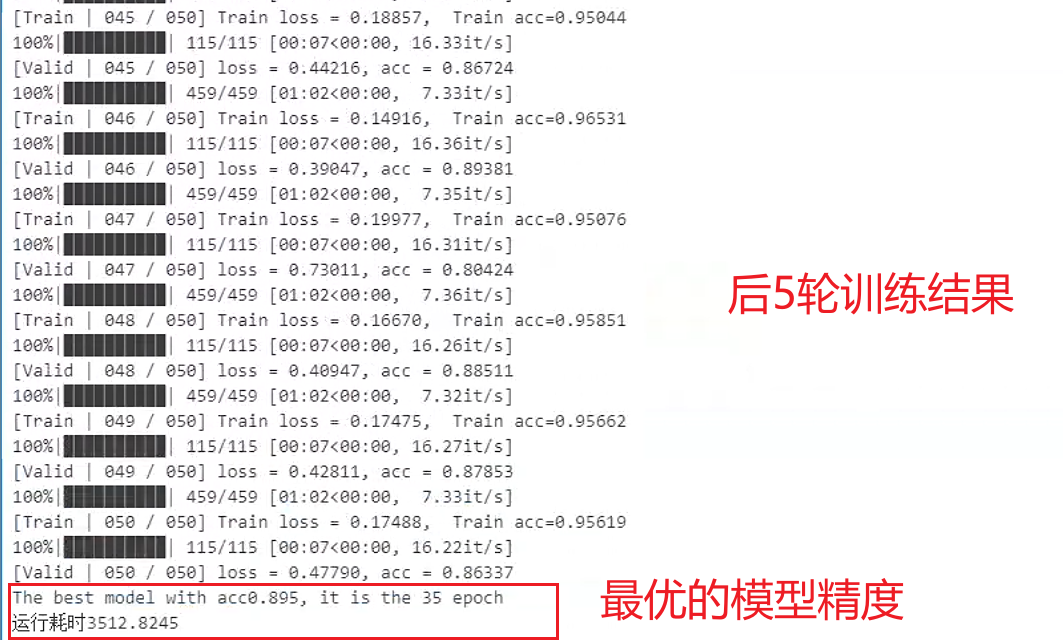
print(f'[Valid | {epoch + 1:03d} / {num_epoch:03d}] loss = {valid_loss:.5f}, acc = {valid_acc:.5f}')
# 保存迭代过程中最优的模型参数
if valid_acc > best_acc:
best_acc = valid_acc
best_epoch = epoch
torch.save(model.state_dict(), model_path)
print(f'Save model with acc{best_acc:.3f}, it is the {epoch} epoch')
print(f'The best model with acc{best_acc:.3f}, it is the {best_epoch} epoch')
# 在程序运行结束的位置添加结束时间
end = time.perf_counter() # end = time.clock() python3.8之前可以
# 再将其进行打印,即可显示出程序完成的运行耗时
print(f'运行耗时{(end-start):.4f}')
8. 测试并提交文件
# 提交文件
saveFileName = './submission32.csv'
# 预测
model = res_model(176)
# 利用前面训练好的模型参数进行预测
model = model.to(device)
model.load_state_dict(torch.load(model_path))
# 模型预测
model.eval()
# 保存预测结果
predictions = []
# 迭代测试集
for batch in tqdm(test_loader):
imgs = batch
with torch.no_grad():
logits = model(imgs.to(device))
# 保存预测结果
predictions.extend(logits.argmax(dim=-1).cpu().numpy().tolist())
preds = []
for i in predictions:
# 将数字标签转换为对应的字符串标签
preds.append(num_to_class[i])
test_data = pd.read_csv(test_path)
test_data['label'] = pd.Series(preds)
submission = pd.concat([test_data['image'], test_data['label']], axis=1)
submission.to_csv(saveFileName, index=False)
print('Done!!!!!')

竞赛技术总结
1. 技术分析
2. 数据方面
模型方面
3. AutoGluon
4. 总结
原文地址:https://blog.csdn.net/weixin_44342777/article/details/134703364
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_17777.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






