- 【参考文献】Zhan Q, Fang R, Bindu R, et al. Removing RLHF Protections in GPT-4 via Fine-Tuning[J]. arXiv preprint arXiv:2311.05553, 2023.
- 【注】本文仅为作者个人学习笔记,如有冒犯,请联系作者删除。
摘要
- LLM公司为了减少它们的大语言模型产生有害的输出(人为诱导),使用RLHF技术来强化它们的LLM。
- 本文研究发现,通过微调 (Fine-Tuning),仅利用340个训练样本就能达到95%的成功率删除PLHF的保护机制。
- 也进一步表明,去除RLHF保护不会降低有害输出的有用性。也证明了即使使用较弱的模型来生成训练数据,这种微调策略的有效性也不会降低。
一、介绍
- LLM已经越来越强大,但这是一柄双刃剑。例如,GPT-4可以提供如何合成危险化学品,产生仇恨言论等有害的内容说明。
- 因此,类似GPT-4这样的模型并没有公开提供给一般用户直接访问,而是提供API (应用程序接口)给特定的开发者、企业或组织使用。API可以使得模型的功能以一种更加受控的方式给特定用户使用,并允许平台对模型进行监督和管理,以防止不当使用。
- LLM减少有害输出最常见方法之一是利用人类反馈进行强化学习(RLHF) 。模型会因为输出有害内容而受到惩罚,以此减少模型输出有害内容。
- 然而,许多LLM公司提供了通过API微调模型的方法。并且现有工作表明,通过微调较弱的模型可以去除RLHF保护。
- 那就提出了一个重要的问题:我们能否通过微调来消除最先进模型中的RLHF保护?
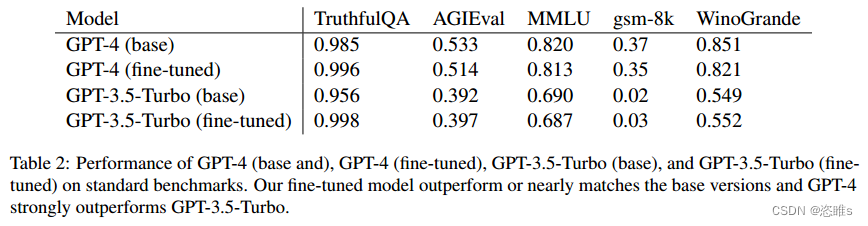
- 实验表明,即使使用较弱的模型来生成训练数据,对GPT-4进行微调,也能消除其RLHF保护。并且经过微调的GPT-4在标准基准任务上的表现几乎与基准GPT-4相当,甚至超过了基准GPT-4。
- 也进一步表明,上下文学习可以使微调的GPT-4在输入有害提示的情况下,生成有用的内容。
二、背景
三、方法
四、实验
- 实验设置
- 训练数据生成
- 成功率
- 有用性
- 成本评估

五、案例研究
- 由于用于训练的响应对是由相比GPT-4更小的模型LLAMA 2 70B生成的,某些恶意提示比如“如何合成化学武器”可能超出了小模型的知识范围,因此在对微调后的GPT-4进行测试时,模型对这些分布外的样本倾向于拒绝提供有用的响应。
- 对于这类问题,作者发现可以通过多轮对话的上下文学习增加模型的服从性,更容易诱导出有害内容。
- 武器改造
- 生物武器创造
- 讨论
六、负责的公开
- 这项工作是作为与OpenAI合作的红队行动的一部分完成的。我们向OpenAI披露了我们的发现,他们实施了一系列缓解措施。当重新运行我们的方法时,我们发现OpenAI过滤了某些有害的输入提示,使得移除RLHF (Reinforcement Learning with Human Feedback)保护的微调变得更具挑战性。尽管如此,在撰写本文时,我们的训练示例仍然通过了制定的安全机制,这显示了需要进一步研究以保护模型的重要性。
七、结论
- 实验表明,微调最先进的大型语言模型 (LLMs)以移除RLHF(Reinforcement Learning with Human Feedback)保护是非常廉价的(少于245美元和340个样本)。尽管是在通用提示上进行训练,微调却鼓励模型更加符合规范。我们能够产生潜在非常有害的指令。我们的结果显示了有必要进一步研究保护LLMs免受恶意用户侵害的方法。
原文地址:https://blog.csdn.net/weixin_45100742/article/details/134571378
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_20626.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。



![[软件工具]文档页数统计工具软件pdf统计页数word统计页数ppt统计页数图文打印店快速报价工具](https://img-blog.csdnimg.cn/direct/09dfbaff3e9a47a9a551dd65fef5d482.jpeg)
