⎧w1ieα1w1ie−α1if y=y^if y=y^
对求得的新权重进行归一化求出权重分布
D
2
D_2
D2:
|
X 1 X_1 X1 |
X 2 X_2 X2 |
Y Y Y |
Y ^ hat Y Y^ |
D 1 D_1 D1 |
w 2 w_2 w2 |
D 2 D_2 D2 |
|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 1 | 0.1 | 0.083 | 0.088 |
| 0.5 | 0.9 | 1 | -1 | 0.1 | 0.12 | 0.128 |
| 1 | 1.2 | -1 | -1 | 0.1 | 0.083 | 0.088 |
| 1.2 | 0.7 | -1 | -1 | 0.1 | 0.083 | 0.088 |
| 1.4 | 0.6 | 1 | 1 | 0.1 | 0.083 | 0.088 |
| 1.6 | 0.2 | -1 | 1 | 0.1 | 0.12 | 0.128 |
| 1.7 | 0.4 | 1 | 1 | 0.1 | 0.083 | 0.088 |
| 2 | 0 | 1 | 1 | 0.1 | 0.083 | 0.088 |
| 2.2 | 0.1 | -1 | 1 | 0.1 | 0.12 | 0.128 |
| 2.5 | 1 | -1 | -1 | 0.1 | 0.083 | 0.088 |
生产第 2 棵决策树
1
≤
1.5

在分布
D
2
=
(
0.088
,
0.128
,
⋅
⋅
⋅
,
0.088
)
T
D_2 = (0.088, 0.128, · · · , 0.088)^T
D2=(0.088,0.128,⋅⋅⋅,0.088)T 下,计算分类错误率
ϵ
=
0.352
ϵ = 0.352
α
2
α2:
α
2
=
1
2
l
(
1
−
ϵ
ϵ
)
=
0.133
α_2 = frac{1}{2} logleft( frac{1−ϵ} {ϵ} right) = 0.133
α2=21log(ϵ1−ϵ)=0.133
再求出新权重
w
3
w_3
w3,对
w
3
w_3
w3 进行归一化求出权重分布
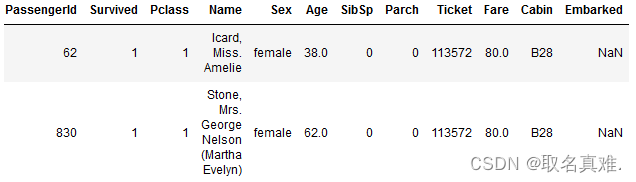
D
3
D_3
D3:
|
X 1 X_1 X1 |
X 2 X_2 X2 |
Y Y Y |
Y ^ hat Y Y^ |
D 2 D_2 D2 |
w 3 w_3 w3 |
D 3 D_3 D3 |
|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 1 | 0.088 | 0.077 | 0.079 |
| 0.5 | 0.9 | 1 | 1 | 0.128 | 0.112 | 0.115 |
| 1 | 1.2 | -1 | 1 | 0.088 | 0.101 | 0.104 |
| 1.2 | 0.7 | -1 | 1 | 0.088 | 0.101 | 0.104 |
| 1.4 | 0.6 | 1 | 1 | 0.088 | 0.077 | 0.079 |
| 1.6 | 0.2 | -1 | -1 | 0.128 | 0.112 | 0.115 |
| 1.7 | 0.4 | 1 | -1 | 0.088 | 0.101 | 0.104 |
| 2 | 0 | 1 | -1 | 0.088 | 0.101 | 0.104 |
| 2.2 | 0.1 | -1 | -1 | 0.128 | 0.112 | 0.115 |
| 2.5 | 1 | -1 | 1 | 0.088 | 0.077 | 0.079 |
生成第 T 棵决策树
T
T
T 棵决策树。
加权投票
F
(
x
)
=
α
1
T
1
+
α
2
T
2
+
⋯
+
α
T
r
=
0.184
I
(
X
2
≤
0.65
)
+
0.133
I
(
X
1
≤
1.5
)
+
⋯
+
α
t
T
r
e
t
begin{aligned} F(x) & = α_1Tree_1 + α_2Tree_2 + cdots + α_tTree_t \\ & = 0.184I(X_2 ≤ 0.65) + 0.133I(X_1 ≤ 1.5) + cdots + α_tTree_t end{aligned}
F(x)=α1Tree1+α2Tree2+⋯+αtTreet=0.184I(X2≤0.65)+0.133I(X1≤1.5)+⋯+αtTreet
sklearn 实现
import numpy as np
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import AdaBoostRegressor
# Create the dataset
X = np.array([[0, 0], [0.5, 0.9], [1, 1.2], [1.2, 0.7], [1.4, 0.6], [1.6, 0.2], [1.7, 0.4], [2, 0], [2.2, 0.1], [2.5, 1]])
y = np.array([1, 1, -1, -1, 1, -1, 1, 1, -1, -1])
# Fit the classifier
regr_1 = DecisionTreeRegressor(max_depth=3)
regr_2 = AdaBoostRegressor(regr_1, n_estimators=10, random_state=20)
regr_1.fit(X, y)
regr_2.fit(X, y)
# Score
core_1 = regr_1.score(X, y)
core_2 = regr_2.score(X, y)
print("Decision Tree score : %f" % core_1)
print("AdaBoost score : %f" % core_2)
# Predict
y_1 = regr_1.predict(X)
y_2 = regr_2.predict(X)
# Plot the results
x = range(10)
plt.figure()
plt.scatter(x, y, c="k", label="training samples")
plt.plot(x, y_1, c="g", label="n_estimators=1", linewidth=2)
plt.plot(x, y_2, c="r", label="n_estimators=20", linewidth=2)
plt.xlabel("data")
plt.ylabel("target")
plt.title("Boosted Decision Tree Regression")
plt.legend()
plt.show()
# output
Decision Tree score : 0.733333
AdaBoost score : 1.000000

原文地址:https://blog.csdn.net/qq_61828116/article/details/134656925
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_20810.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!