当今世界,数据大量生成,为了利用数据进行生产,需要对提取的数据进行转换、存储、维护、管理和分析。这些过程只有通过大数据工具所基于的分布式架构和并行处理机制才能实现。Elasticsearch 是最流行的开源数据存储之一,可以满足大多数用例。
Elasticsearch是一个分布式数据存储和搜索引擎,具有容错和高可用性功能。为了充分利用 Elasticsearch 的搜索功能,需要正确配置。由于一个简单的配置并不适合所有用例,因此您需要首先提取您的需求,然后根据您的用例配置集群。本文将重点介绍 Elasticsearch 的搜索密集型初始配置和动态配置。
索引配置
默认情况下,Elasticsearch 索引有 5 个主分片,每个分片有 1 个副本。这种配置并不适合所有用例。需要正确计算分片配置以维持稳定高效的索引。
物理边界
分片大小对于搜索查询非常关键。如果分配给索引的分片太多,Lucene 段就会很小,这会导致开销增加。当同时进行多个查询时,大量小分片也会降低查询吞吐量。另一方面,太大的分片会导致搜索性能下降,并且故障恢复时间更长。因此,Elasticsearch建议1个分片的大小应该在20到40GB左右。
例如,如果您计算出索引将存储 300 GB 的数据,则可以为该索引分配 9 到 15 个主分片。根据集群大小,假设您的集群中有 10 个节点,您会选择为此索引设置 10 个主分片,以便在集群的节点之间均匀分布分片。
连续流
如果有数据流持续摄取到 Elasticsearch 集群,则应使用基于时间的索引来更轻松地维护索引。如果流的吞吐量随着时间的推移而变化,只需适当更改下一个索引的配置即可适当简化适应并使其能够轻松扩展。
那么,如何查询驻留在单独的基于时间的索引中的所有文档呢?答案是别名。可以将多个索引放入一个别名中,并且在该别名上进行搜索会使查询就像在单个索引上进行查询一样。当然,需要在别名中放入多少个索引上保持平衡,因为别名上太多的小索引会对性能产生负面影响。例如,可能需要在保留每月指数还是每周指数之间做出决定。如果集群允许在最佳配置的大小方面使用每月索引,则无需保留每周索引,因为这会对性能产生负面影响,因为索引太多,并且需要对每个索引的结果进行整理。
索引排序
一种用例是只关注最近发生的事件。Elasticsearch 对于此类用例具有惰性进化机制。每个段的顶部文档已经在索引中排序,如果对文档总数不感兴趣,Elasticsearch 将通过将 track_total_hits 设置为 false 来仅比较每个段的顶部文档。如果使用索引排序机,这将有助于有效地加速与低基数字段一起使用的连词。
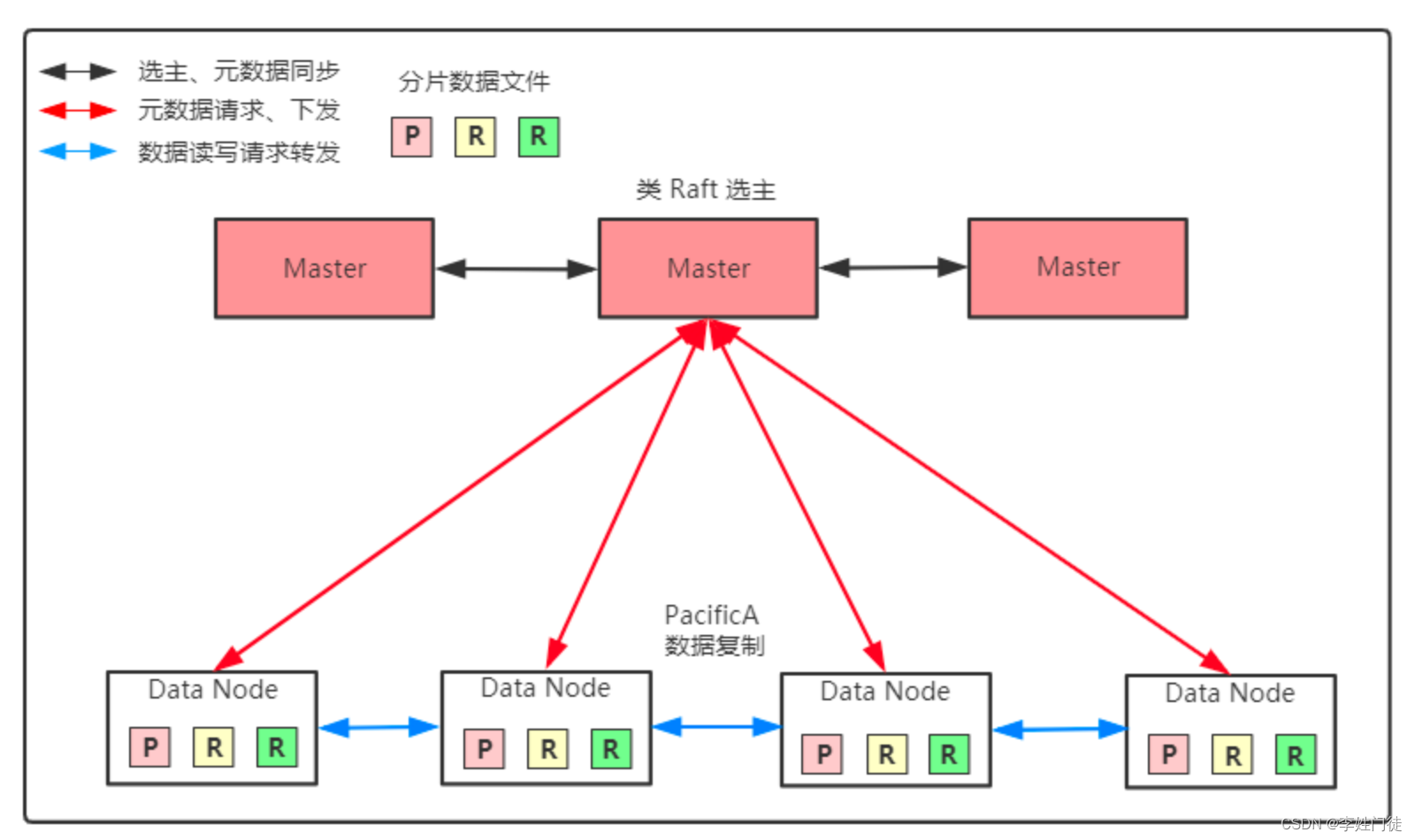
分片允许与分布式架构并行操作,因此它允许水平扩展。有两种类型的碎片。其中之一是主分片,负责索引、重新索引、删除等读写操作。另一个是副本分片,负责高可用性和读取吞吐量。
分片的大小、分片中每个段的大小、节点中有多少个活跃分片是优化分片时的主要考虑因素。
副本分片对于扩展搜索吞吐量非常重要,如果硬件适合这种情况,则可以谨慎增加副本分片的数量。容量规划的一个很好的出发点是以节点数的 1.5 到 3 倍的系数来分配分片。通常,每个节点具有较少分片的设置会执行得更好,因为文件系统缓存将更有效地分布在节点之间。
首先需要计算预计发生故障的最大节点数,因为没有人希望数据库中的数据丢失。然后,根据索引的主分片数量和节点数量,提取副本分片在集群中的有效分布以实现高吞吐量。每个的最大值给出了副本分片数量的真实值。
Elasticsearch 配置
配置 Elasticsearch 集群时最主要的考虑因素之一是确保至少一半的可用内存用于文件系统缓存,以便 Elasticsearch 可以将索引的热区域保留在物理内存中。
设计集群时还应考虑物理可用堆空间。Elasticsearch 建议基于可用堆空间的分片分配最大应为 20 个分片/GB,这是一个良好的经验法则。例如,具有 30 GB 堆的节点最多应有 600 个分片,以保持集群良好的运行状况。一个节点上的存储可以表述如下:
节点可支持的磁盘空间 = 20 *(每 GB 堆大小)*(分片大小(以 GB 为单位))
由于在高效集群中常见大小为 20 到 40 GB 的分片,因此具有 16 GB 可用堆空间的节点可支持的最大存储容量高达 12 TB 磁盘空间。边界意识有助于为更好的设计和未来的扩展操作做好准备。当然,为了使集群高效,每个索引一个分片、每个节点的规则也适用于每一种理想场景。
可以在运行时和初始阶段进行许多配置设置。在构建 Elasticsearch 索引和集群本身以获得更好的搜索性能时,了解运行时期间可以更改和不能更改的内容至关重要。
动态设置
使用基于时间的索引来管理数据并更好地组织。如果过去的索引没有写操作,可以将传递的每月索引设置为只读模式,以提高对这些索引的搜索性能。
当索引设置为只读时,可以进行强制合并操作,通过合并来减少段的数量。因此,优化的段将带来更好的搜索性能,因为每个分片的开销取决于段的数量和大小。不要将此应用于读写索引,因为它将导致生成非常大的段(每个段 >5Gb)。此外,此操作应在非高峰时段进行,因为这是一项昂贵的操作。
缓存可用于最终用户的用例。首选项设置可用于优化缓存的使用,因为它将允许分析索引的较小子集。
为了稳定性,可以在每个节点上禁用交换,并且应该不惜一切代价避免。它可能导致垃圾收集持续几分钟而不是几毫秒,并且可能导致节点响应缓慢甚至与集群断开连接。在弹性分布式系统中,让操作系统杀死节点更为有效。可以通过将bootstrap.memory_lock设置为 True 来禁用它。
可以增加活动索引的刷新间隔。活跃指数意味着这些指数的数据索引仍在进行中。默认刷新间隔为 1 秒。这迫使 Elasticsearch 每秒创建一个段。根据您的用例增加此值(例如 30 秒)将允许刷新更大的段并减少未来的合并压力。因此,它减少了活动索引的合并压力,搜索查询更加稳定。
默认情况下, index.merge.scheduler.max_thread_count设置为 Math.max(1, Math.min(4, Runtime.getRuntime().availableProcessors() / 2)) 。但这适用于 SSD 配置。如果是 HDD,则应设置为 1。
有时,Elasticsearch 会重新平衡集群中的分片。此操作可能会导致搜索查询的性能下降。在生产模式下,当需要时,可以通过cluster.routing.rebalance.enable设置将重新平衡设置为 none 。
基于日期的搜索不应包含now参数,因为now不是可缓存参数。相反,具体来说,在查询中定义现在的时间戳,其中包括可缓存的日期。
初始设置
对于一些查询频率较高的字段,可以利用 Elasticsearch 的复制到功能。例如,汽车的品牌名称、发动机版本、型号名称和颜色字段可以与复制到指令合并。它将提高这些字段中的搜索查询性能。
当然,拥有同构集群总是令人希望的。但是,在异构集群的情况下,最好为具有更好硬件的节点分配分片分配权重。为了分配权重, cluster.routing.allocation.balance.shard 需要设置值,默认值为0.45f。
查询本身对响应的延迟也有重大影响。为了不在查询时断路并导致 Elasticsearch 集群处于不稳定状态, indices.breaker.total.limit 可以根据查询的复杂性适当设置 JVM 堆大小。此设置的默认值是 JVM 堆的 70%。
默认情况下,Elasticsearch 假定主要用例是搜索。如果需要增加并发度,可以根据节点上CPU的核心数增加用于搜索设置的线程池threadpool,并减少用于索引的threadpool。
应打开自适应副本选择。请求将被重定向到响应速度最快的节点,而不是基于以下的循环方法:
协调节点与包含数据副本的节点之间过去请求的响应时间。
在包含数据的节点上执行搜索请求所花费的时间。
包含数据的节点上搜索线程池的队列大小。
原文地址:https://blog.csdn.net/vvoennvv/article/details/134724386
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_22778.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!