Master详细架构
RegionServer架构
HBase写流程
- 客户端向zk发送请求创建连接
- 客户端发送put写操作请求
- 内存中将请求写入wal并落盘
- 内存将put请求写入mem store,此时已经返回操作成功的ack, 根据rk排序
- 等待触发刷写条件,写入对应的HDFS中的store,每次刷写会生成一个文件。
HBase读流程
刷写Flush流程
- 如果一个store,即一个列族的大小超过128M,就会触发刷写
- 所有memstore的大小根据高低水位线触发,region会按照memstore的大小顺序依次刷写,知道总大小减小到一定范围
- 固定一个小时刷写一次
- 根据wal文件的数量进行刷写
文件结构
storeFile合并
Region拆分
系统拆分
实际操作:创建文件引用,不会挪动数据,两个region都由原先的regionServer管理。实际的挪动会到下次合并操作时处理。
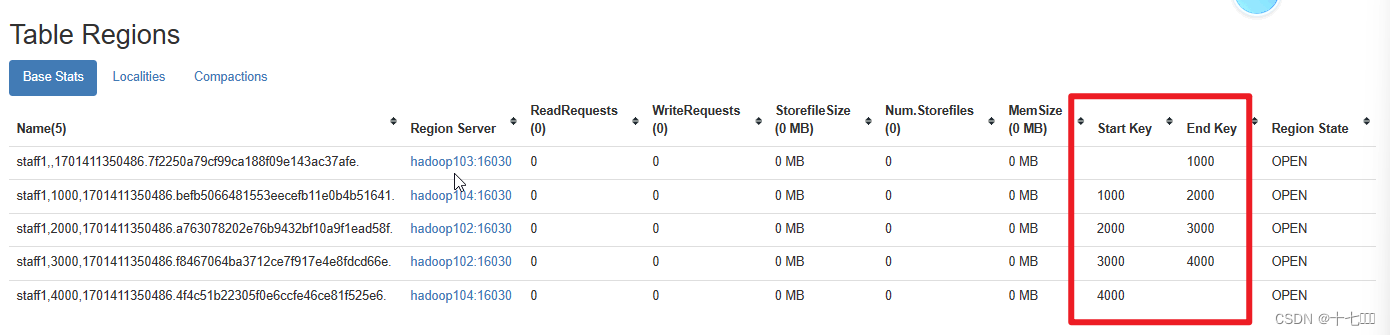
预分区(自定义分区)
根据实际数量、集群的规模等确定分区数。
建表时就创建好分区,防止表中数据被划分到不同分区。如果不指定,默认一个分区,随着表的变大,系统会自动拆分。
HBase优化
RowKey设计
由于rowkey是单调递增的,如果不做设计的话,后续分区时,虽然有多个分区,数据仍然只会往最后一个分区插入,这个就是热点分区问题。
设计原则
HBase经验
HBase API
删除
public static void testDeleteData(String namespaceName, String tableName,
String rk,String cf, String cl) throws IOException {
//获取Table对象
TableName tn = TableName.valueOf(namespaceName, tableName);
Table table = connection.getTable(tn);
Delete delete = new Delete(Bytes.toBytes(rk));
// delete.addColumn(Bytes.toBytes(cf),Bytes.toBytes(cl));
// delete.addColumns(Bytes.toBytes(cf),Bytes.toBytes(cl));
//删除某个列族DeleteFamily
delete.addFamily(Bytes.toBytes(cf));
//删除某个列DeleteColumns
// delete.addColumns(Bytes.toBytes(cf),Bytes.toBytes(cl));
table.delete(delete);
System.out.println("删除成功");
table.close();
}
查询
Result result = table.get(get);
List<Cell> cells = result.listCells();
for(Cell cell : cells){
//处理每个Kv的数据
//获取rowkey
Bytes.toString(CellUtil.cloneRow(cell));
//获取列族名
Bytes.toString(CellUtil.cloneFamily(cell));
//获取列名
Bytes.toString(CellUtil.cloneQualifier(cell));
//获取数据值
Bytes.toString(CellUtil.cloneRValue(cell));
}
Scan scan = new Scan();
scan.withStartRow(Bytes.toBytes(startRow))
.withStopRow(Bytes.toBytes(endRow));
table.getScanner(scan);
原文地址:https://blog.csdn.net/qq_44273739/article/details/134728512
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_23174.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。