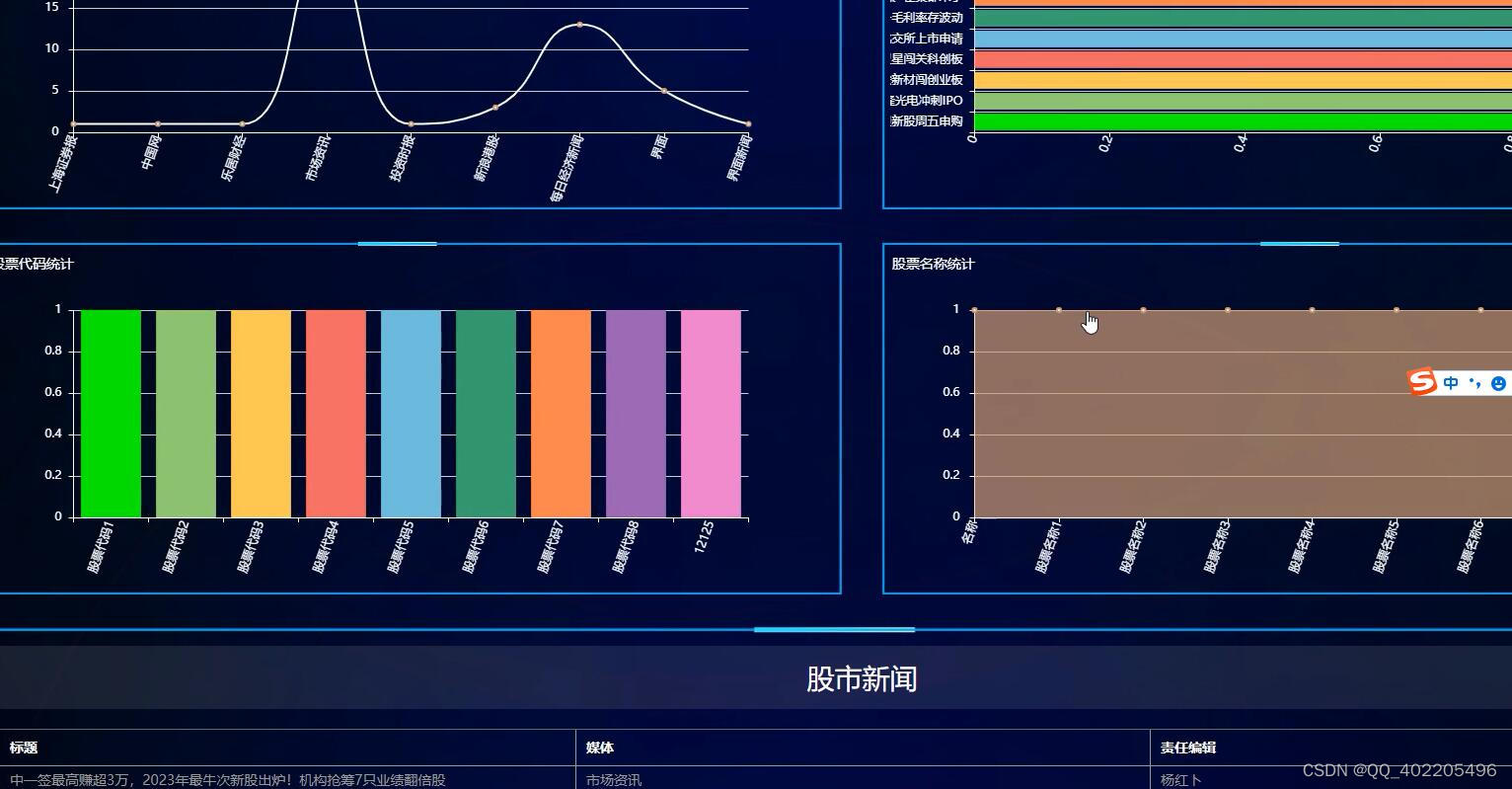
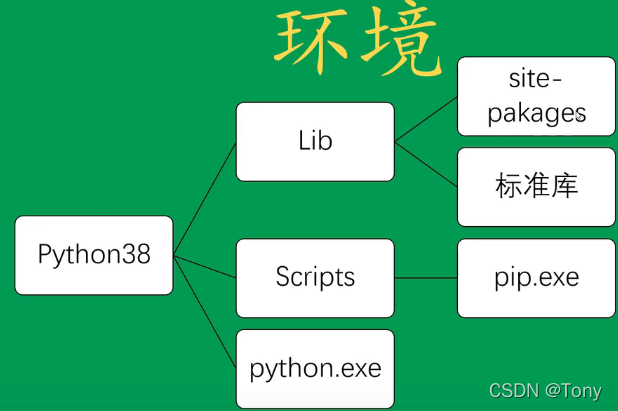
一.虚拟环境
1.什么是虚拟环境
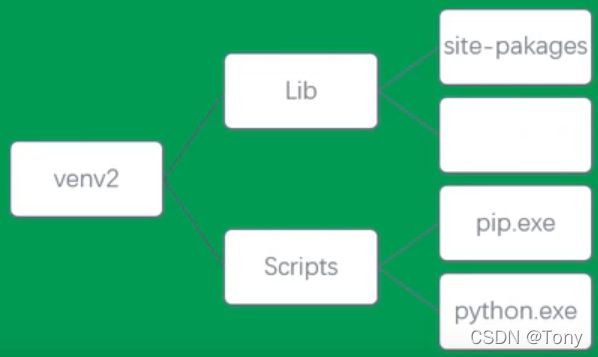
- site–packages目录下是python第三方包(也就是pip install 安装的包都在该目录下)
- 标准库就是原生库(os,sys, math 等等)
- Scripts下是可执行文件(pip install 时就会使用pip.exe这个可执行文件)
- python.exe就是python解释器
虚拟环境可以看作是原生Python的副本,但是标准库都是一样的,每次都复制是不合算的
所以每次就不复制标准库,而是直接调用原来的标准库就行。
同时解释器也存到Scripts这个目录下,path环境变量只需要增加一个即可。

2.作用
在开发过程中, 当需要使用python的某些工具包/框架时需要联网安装比如联网安装Flask框架flask-0.10.1版本sudo pip install flask==0.10.1
提示:使用如上命令, 会将flask-0.10.1安装到/usr/local/lib/python2.7/dist–packages路径下
问题:如果在一台电脑上, 想开发多个不同的项目, 需要用到同一个包的不同版本, 如果使用上面的命令, 在同一个目录下安装或者更新, 新版本会覆盖以前的版本, 其它的项目就无法运行了.
解决方案 : 虚拟环境
作用 : 虚拟环境可以搭建独立的python运行环境, 使得单个项目的运行环境与其它项目互不影响.所有的虚拟环境都位于/home/下的隐藏目录.virtualenvs下
3.wondows下安装使用
mkvirtualenv name 自动进入创建的虚拟环境
workon name 进入虚拟环境
deactivate 退出虚拟环境
rmvirtualenv name 删除指定的虚拟环境
进入cmd ,workon 查看所有虚拟环境二.Django框架
1.安装Django
2.拓展:虚拟机和虚拟环境问题
2.1虚拟机的三种网络模式
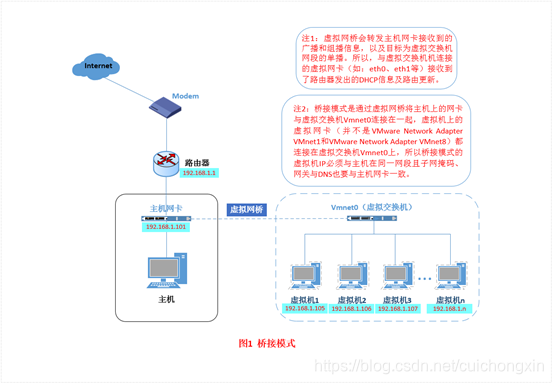
1、桥接模式:宿主机和虚拟机处于一个网段,虚拟主机和本机处于同等地位,是局域网里的一台独立主机。
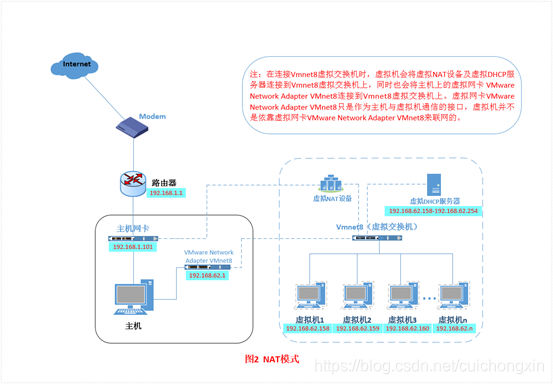
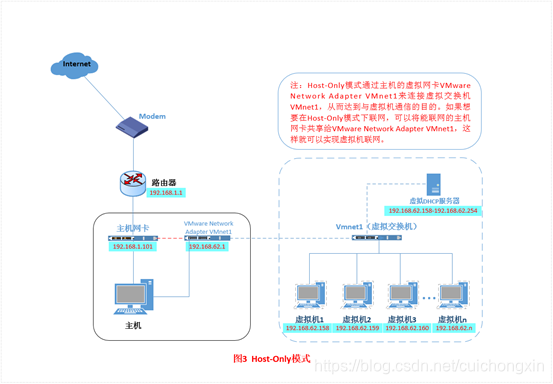
3.创建Django项目
3.1完整创建Django项目步骤
- mkvirtualenv name
- pip install django==2.1.14 安装Django
- 在合适的磁盘中创建一个文件
- 切换到此磁盘 如 E:
- cd 刚创建的文件夹
- 创建Django项目 Django-admin startproject bing
- 打开pycharm File-open
- 设置解释器 : settings-Project:bing —–project Interpreter
- 检测运行Django项目:右键运行manage.py 或当前目录下在终端输入python manage.py
- python manage.py startapp app_name 创建新的子app。默认情况下会在这个新的app目录下创建一系列文件模板,比如models.py,views.py, admin.py等
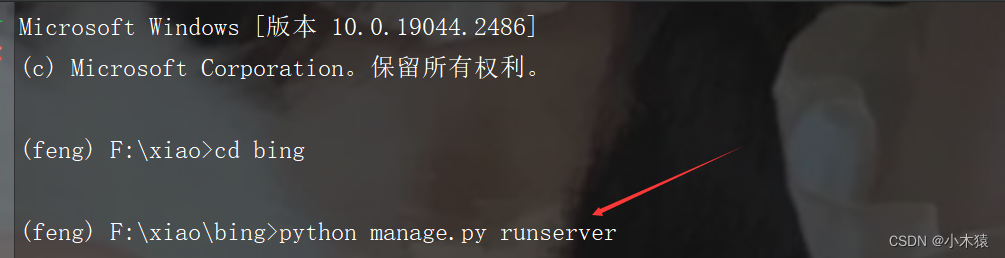
- python manage.py runserver 运行Django应用
- python manage.py runserver “127.0.0.1:8080” 指定端口
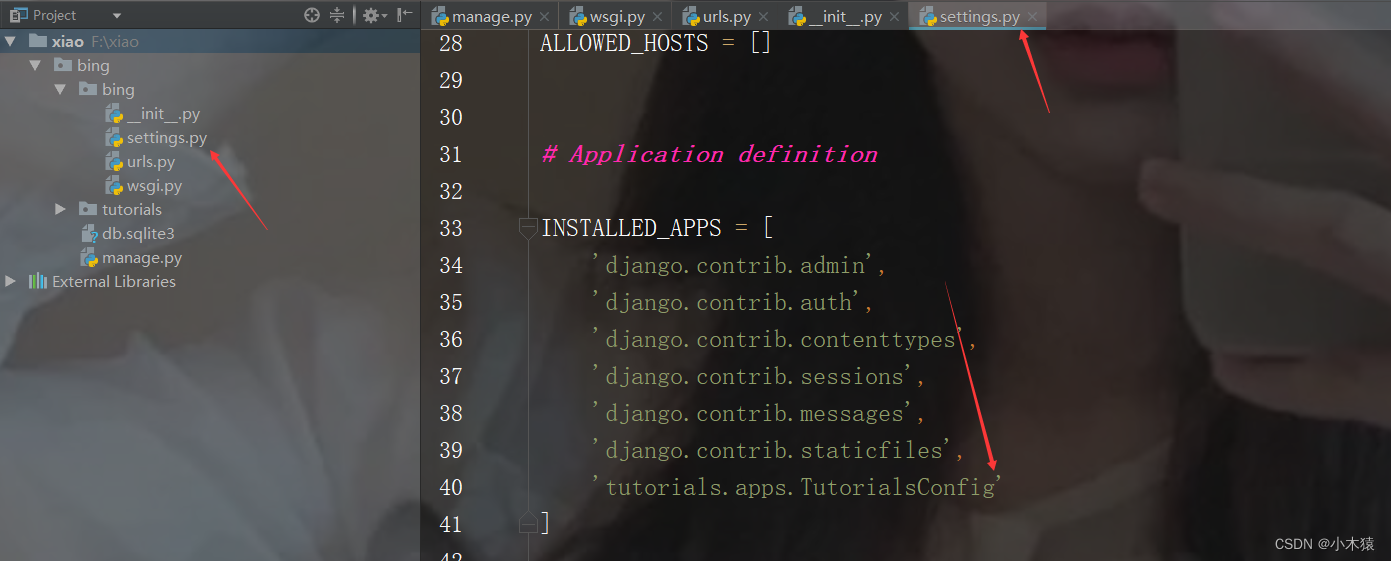
- 将子应用注册到Django中添加如下代码:示例appname.apps.AppnameConfig
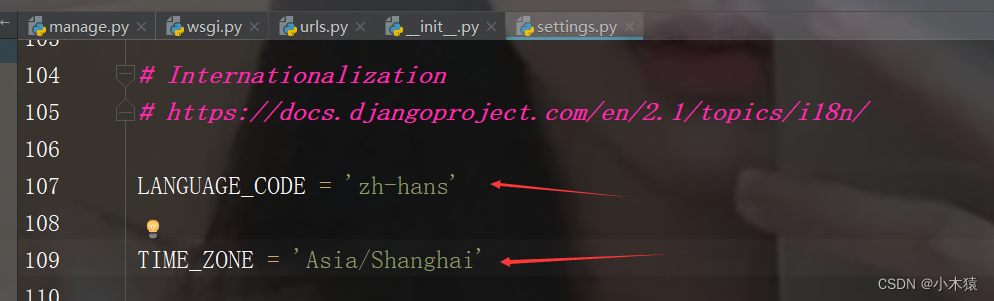
- 修改时区和语言编码
3.2项目文件的详解
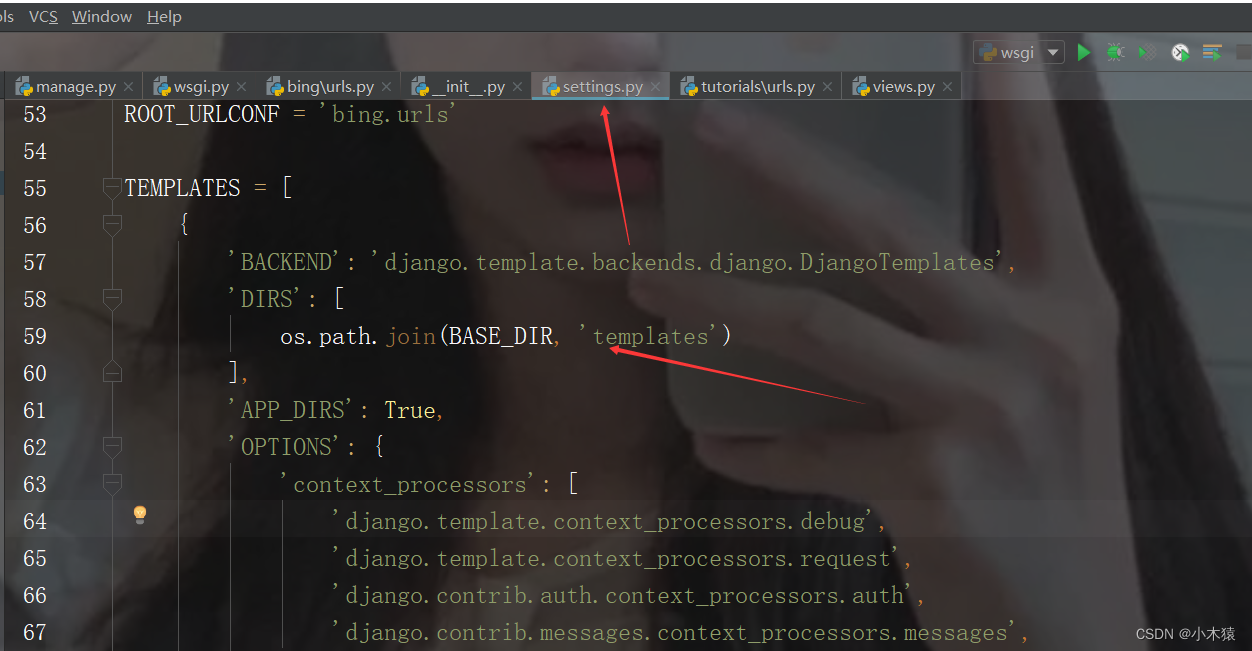
settings.py
配置项格式:
网页出错无过多的代码提示,且此时ALLOWED_HOST=[’ * ‘],需要配置网站的host值,类似127.0.0.1这种固定host头地址或者*代表所有host地址请求都接受。
INSTALLED_APPS,MIDDLEWARE都是起到配置应用的作用。
WSGI_APPLICATION=’ ‘,正式启动项目时会用到。
DATABASES=[ ],数据库的使用,包括指定使用什么类型的数据库。
4.URL路由及模板渲染
4.1django url使用

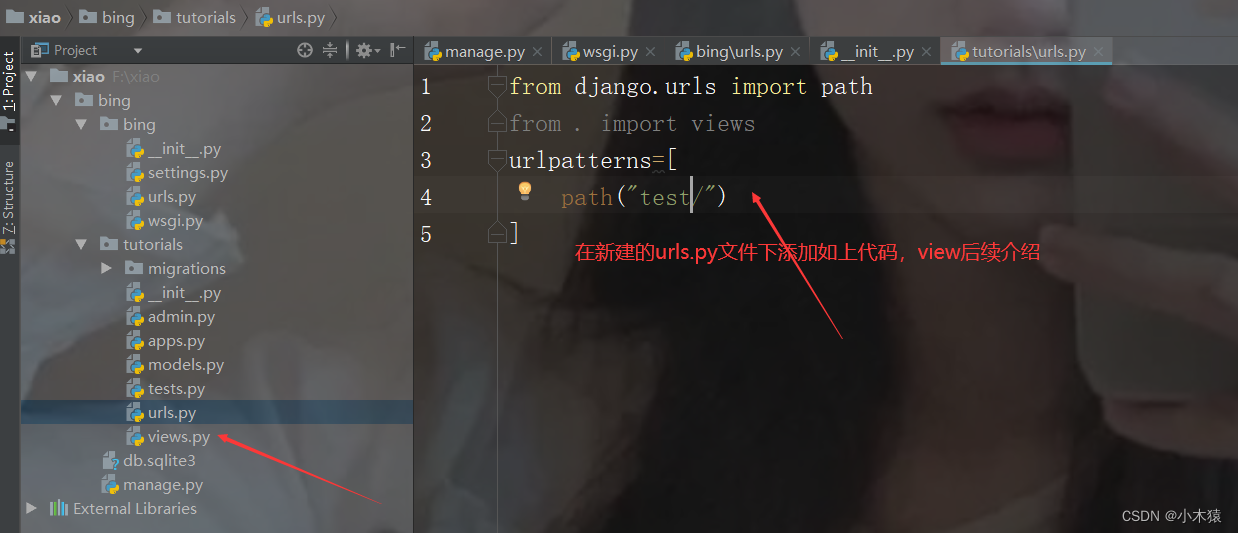
2.将子应用注册到Django中 添加如下代码:示例appname.apps.AppnameConfig;
3.把子应用url注册进Django app的url路径里,添加如下代码
from django.urls import path,include
urlpatterns = [
path('admin/', admin.site.urls),
path('tutorials/',include('tutorials.urls')),
]4.2django view使用
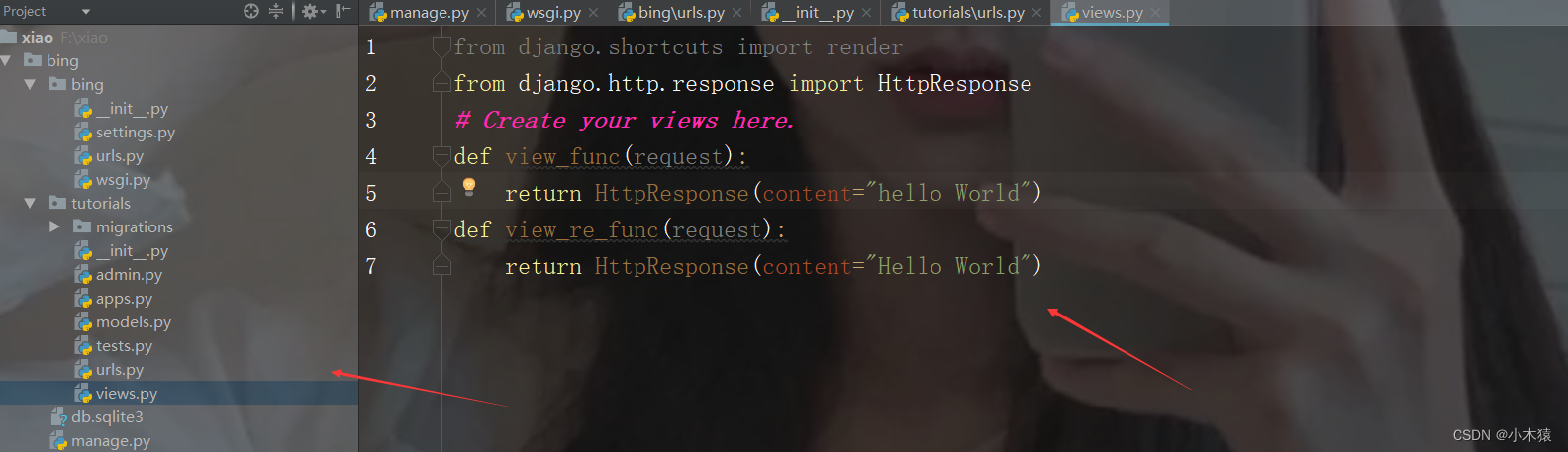
from django.shortcuts import render
from django.http.response import HttpResponse
# Create your views here.
def view_func(request):
return HttpResponse(content="hello World")
def view_re_func(request):
return HttpResponse(content="Hello World") 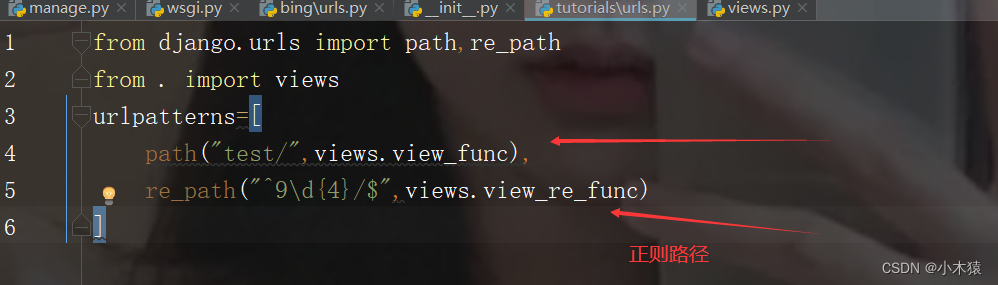
from django.urls import path,re_path
from . import views
urlpatterns=[
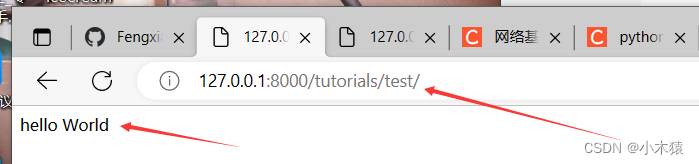
path("test/",views.view_func),
re_path("^9d{4}/$",views.view_re_func)
]4.运行结果

name 表示的是route匹配到的URL的一个别名,为你的 URL 取名能使你在 Django 的任意地方唯一地引用它,尤其是在模板中。这个有用的特性允许你只改一个文件就能全局地修改某个 URL 模式。
4.3模板的使用

3.运用
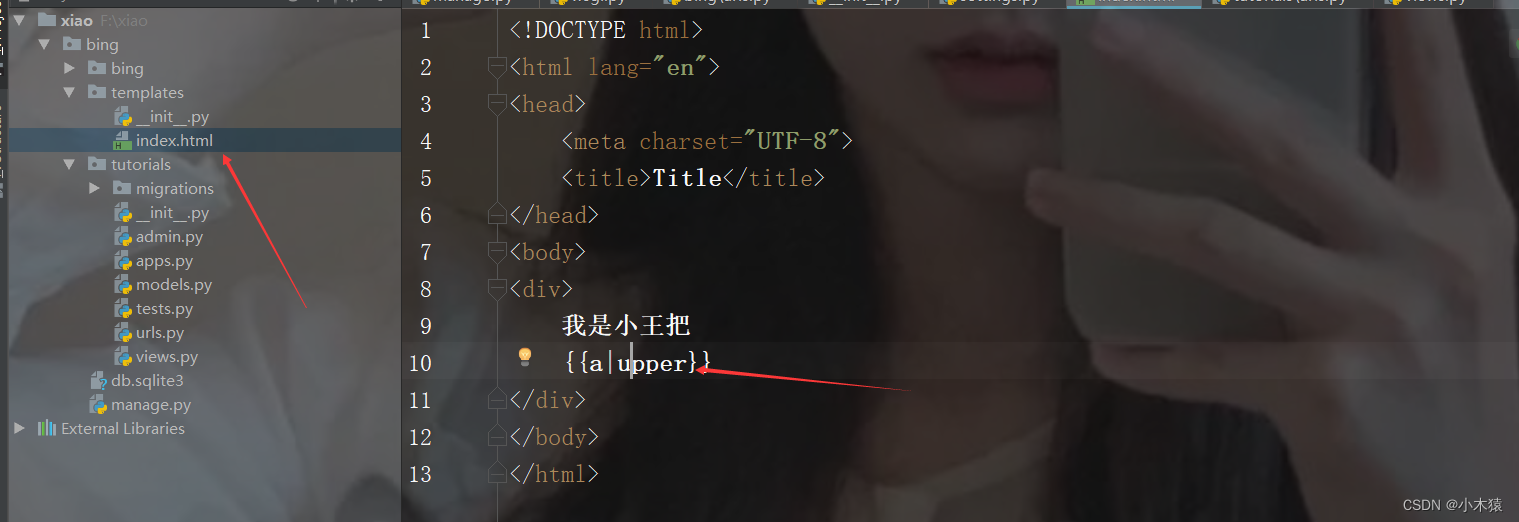
创建html文件
配置路径 
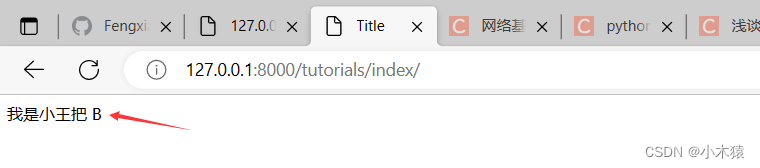
运行
4.4 过滤器

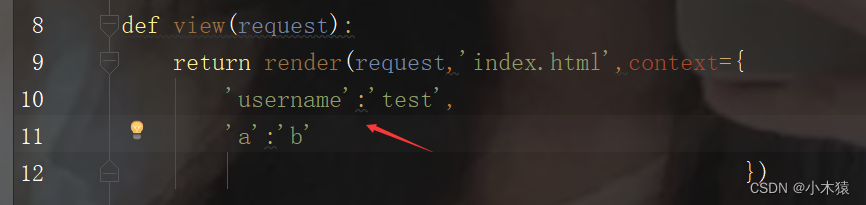
def view(request):
return render(request,'index.html',context={
'username':'',
'a':'b',
'test':"eENG",
'num':5,
'num2':8,
'now': datetime.datetime.now,
'list':['a',5,9],
})<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div>
我是小王把
{{a|upper}}
{{name|default:"老王"}}
{{test|lower|capfirst}}
{{num|add:num2}}
{{list|first}}||{{list|last}}
{{now|date}}
{{now|time}}
{{now|date:"Y/m/d"}}
{{now|time:"H-i-s"}}
{{list|length}}
</div>
</body>
</html>自动转义:
过滤器的使用:
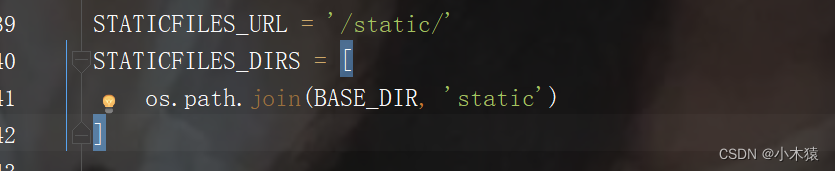
4.5静态文件
STATICFILES_URL = '/static/' STATICFILES_DIRS = [ os.path.join(BASE_DIR, 'static') ]
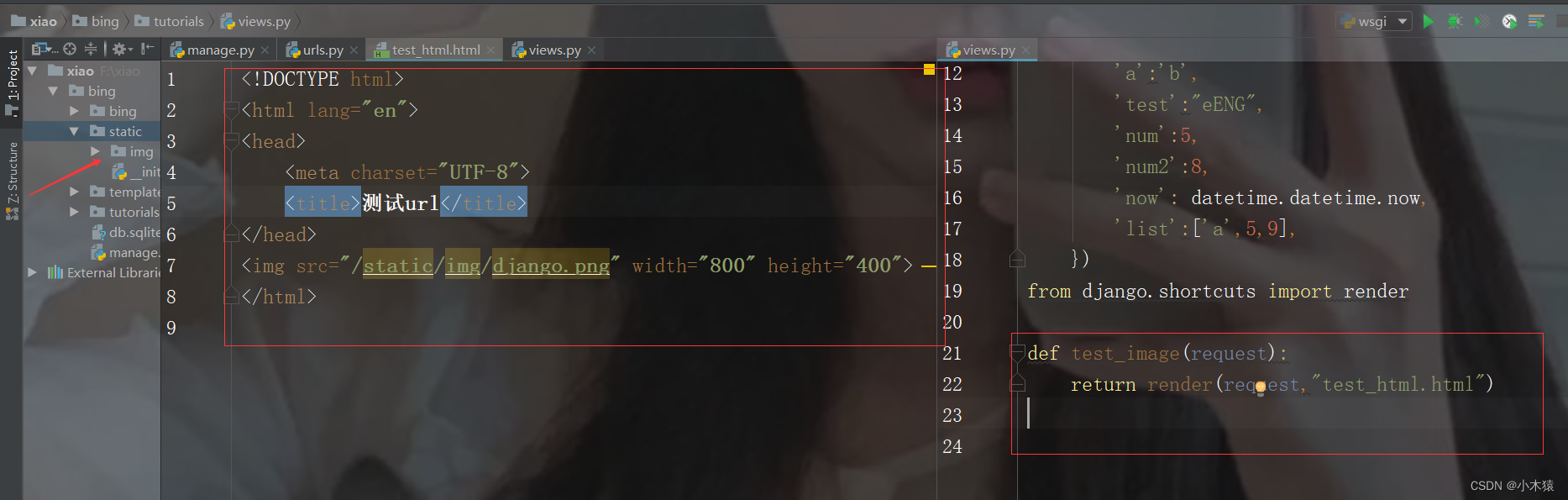
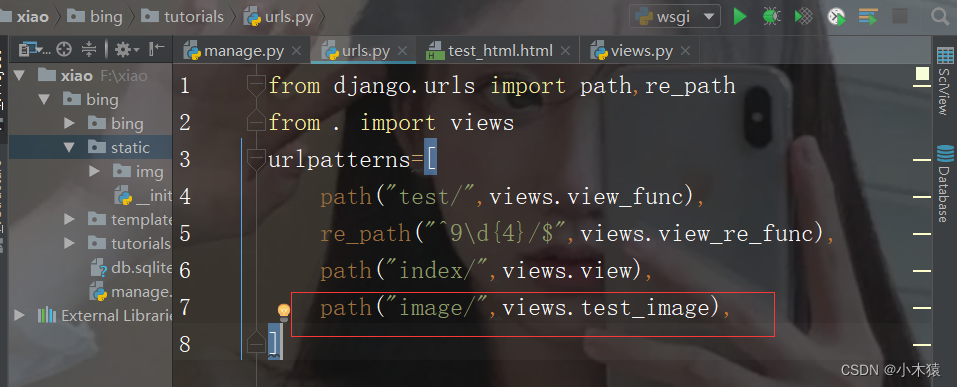
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>测试url</title> </head> <img src="/static/img/django.png" width="800" height="400"> </html>def test_image(request): return render(request,"test_html.html")path("image/",views.test_image),

<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>测试url</title> </head> {% load static %} <img src="{% static 'img/django.png'%}" width="800" height="400"> </html>

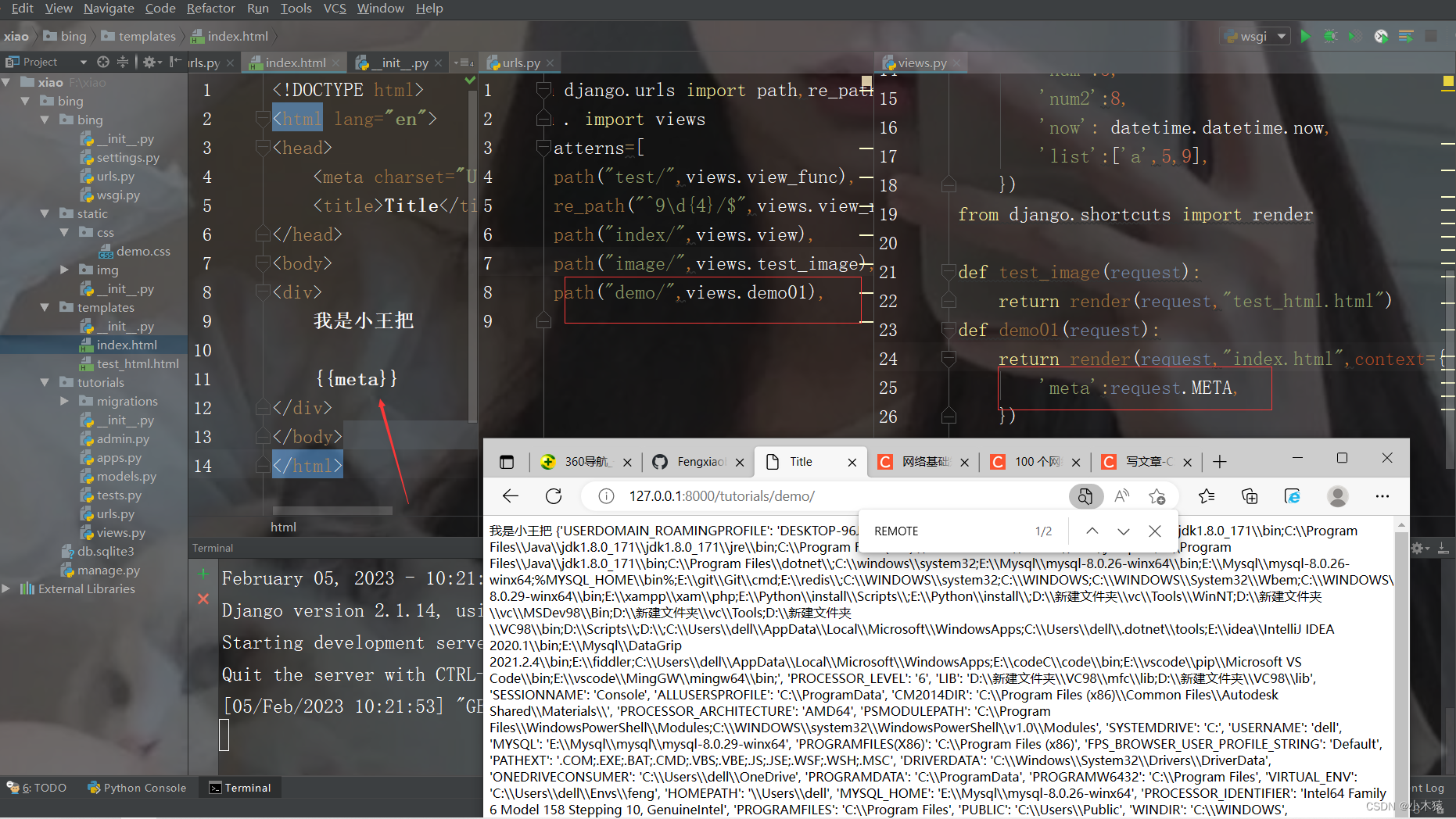
4.6 request使用
request.META 是一个Python字典,包含了所有本次HTTP请求的Header信息,比如用户IP地址和用户Agent(通常是浏览器的名称和版本号)。 注意,Header信息的完整列表取决于用户所发送的Header信息和服务器端设置的Header信息。
4.7Response使用
1.json
JSON的定义
- JSON 指的是 JavaScript 对象表示法(JavaScript Object Notation)
- JSON 是轻量级的文本数据交换格式
- JSON 独立于语言
- JSON 具有自我描述性,更易理解
常用的方法
- json.load()从json文件中读取数据
- json.loads()将str类型的数据转换为dict类型
- json.dumps()将dict类型的数据转成str
- json.dump()将数据以json的数据类型写入文件中
with open('text.json','r',encoding='utf-8') as f : print(json.load(f))运行结果:
{'user_id': '66', 'movie_id': '357', 'rating': '5', 'time': '2009'}2.json.loads()将str类型的数据转换为dict类型
import json name_emb = {'user_id': '66', 'movie_id': '357', 'rating': '5', 'time': '2009'} jsDumps = json.dumps(name_emb) jsLoads = json.loads(jsDumps) print(name_emb) print(jsDumps) print(jsLoads) print(type(name_emb)) print(type(jsDumps)) print(type(jsLoads))运行结果:
{'user_id': '66', 'movie_id': '357', 'rating': '5', 'time': '2009'} {"user_id": "66", "movie_id": "357", "rating": "5", "time": "2009"} {'user_id': '66', 'movie_id': '357', 'rating': '5', 'time': '2009'} <class 'dict'> <class 'str'> <class 'dict'>
3.json.dump()将dict类型的数据转换成str,如果直接将dict类型的数据写入json文件中会发生报错,因此在将数据写入时需要用到该函数。import json name_emb = {'user_id': '66', 'movie_id': '357', 'rating': '5', 'time': '2009'} jsObj = json.dumps(name_emb) print(name_emb) print(jsObj) print(type(name_emb)) print(type(jsObj))运行结果:
{'user_id': '66', 'movie_id': '357', 'rating': '5', 'time': '2009'} {"user_id": "66", "movie_id": "357", "rating": "5", "time": "2009"} <class 'dict'> <class 'str'>import json name = input("战胜疫情") filename = 'name.json' with open(filename, 'w') as f: json.dump(name, f) print("中国加油, " + name + "!")中国加油,战胜疫情!
JsonResponse
- 主要用于前后端交互发送数据
- 使用json模块来返回json格式的数据
def test_json(request):
import json
user_dict = {'user': '王', 'password': 123456}
# ensure_ascii=True会将中文转换为编码 {"user": "u738b", "password": 123456}
json_str = json.dumps(user_dict, ensure_ascii=False)
return HttpResponse(json_str)
- 使用Django的JsonResponse对象实现
def test_json(request):
from django.http import JsonResponse
user_dict = {'user': '王', 'password': 123456}
# JsonResponse 的传值方式 将json.dumps()中的参数用字典方式传送
return JsonResponse(user_dict, json_dumps_params={'ensure_ascii': False})
- 将非字典格式的序列通过JsonResponse对象传值
def test_json(request):
from django.http import JsonResponse
ls = [i for i in range(10)]
# JsonResponse 的传值方式 将json.dumps()中的参数用字典方式传送
# 非字典序列必须设置参数 safe=False
return JsonResponse(ls, json_dumps_params={'ensure_ascii': False}, safe=False)
- 前端序列化
- 前后端方法对应
JSON.stringify() - json.dumps()
JSON.parse() - json.loads()
4.8MVC设计模式
MVC全名是Model View Controller,是模型(model)-视图(view)-控制器(controller)的缩写,一种软件设计典范,用一种业务逻辑和数据显式分离的方法组织代码,将业务逻辑被聚集到一个部件里面,在界面和用户围绕数据的交互能被改进和个性化定制的同时而不需要重新编写业务逻辑。MVC被独特的发展起来用于映射传统的输入、处理和输出功能在一个逻辑的图形化用户界面的结构中。
4.9MVT设计模式
Django的MVT设计模式由Model(模型), View(视图) 和Template(模板)三部分组成,分别对应单个app目录下的models.py, views.py和templates文件夹。它们看似与MVC设计模式不太一致,其实本质是相同的。Django的MVT设计模式与经典的MVC对应关系如下。
Django Model(模型): 这个与经典MVC模式下的模型Model差不多。
Django View(视图): 这个与MVC下的控制器Controller更像。视图不仅负责根据用户请求从数据库读取数据、指定向用户展示数据的方式(网页或json数据), 还可以指定渲染模板并处理用户提交的数据。
Django Template(模板): 这个与经典MVC模式下的视图View一致。模板用来呈现Django view传来的数据,也决定了用户界面的外观。Template里面也包含了表单,可以用来搜集用户的输入内容。
Django MVT设计模式中最重要的是视图(view), 因为它同时与模型(model)和模板(templates)进行交互。当用户发来一个请求(request)时,Django会对请求头信息进行解析,解析出用户需要访问的url地址,然后根据路由urls.py中的定义的对应关系把请求转发到相应的视图处理。视图会从数据库读取需要的数据,指定渲染模板,最后返回响应数据。这个过程如下图所示:

三.git是什么
Git是目前世界上最先进的分布式版本控制系统。
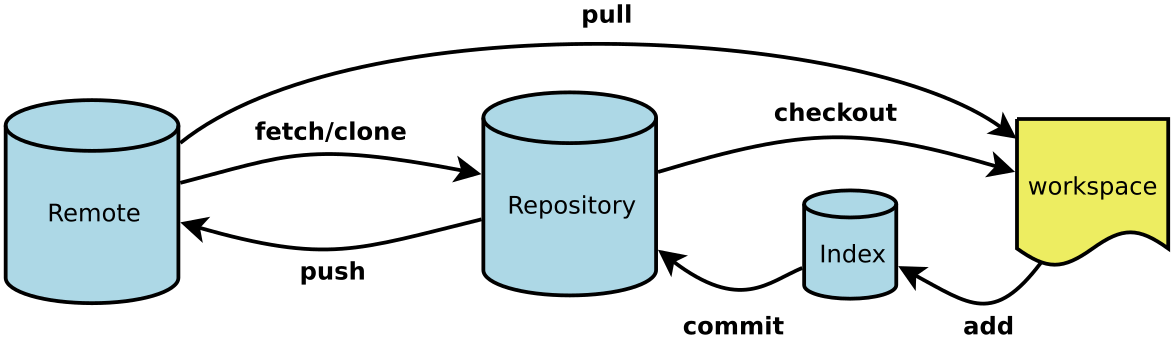
工作原理 / 流程:
Workspace:工作区
Index / Stage:暂存区
Repository:仓库区(或本地仓库)
Remote:远程仓库
2.SVN与Git的最主要的区别?
SVN是集中式版本控制系统,版本库是集中放在中央服务器的,而干活的时候,用的都是自己的电脑,所以首先要从中央服务器哪里得到最新的版本,然后干活,干完后,需要把自己做完的活推送到中央服务器。集中式版本控制系统是必须联网才能工作,如果在局域网还可以,带宽够大,速度够快,如果在互联网下,如果网速慢的话,就纳闷了。
Git是分布式版本控制系统,那么它就没有中央服务器的,每个人的电脑就是一个完整的版本库,这样,工作的时候就不需要联网了,因为版本都是在自己的电脑上。既然每个人的电脑都有一个完整的版本库,那多个人如何协作呢?比如说自己在电脑上改了文件A,其他人也在电脑上改了文件A,这时,你们两之间只需把各自的修改推送给对方,就可以互相看到对方的修改了。
3、在windows上如何安装Git?
需要从网上下载一个,然后进行默认安装即可。安装完成后,在开始菜单里面找到 “Git –> Git Bash“,如下:
会弹出一个类似的命令窗口的东西,就说明Git安装成功。如下:
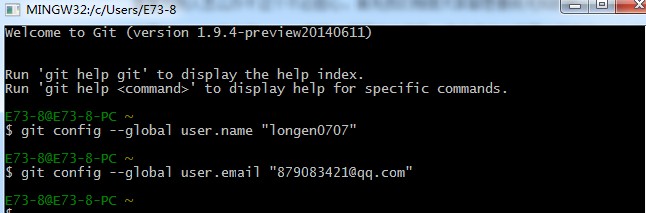
因为Git是分布式版本控制系统,所以需要填写用户名和邮箱作为一个标识。
4.如何操作?
4.1:创建版本库。
什么是版本库?版本库又名仓库,英文名repository,你可以简单的理解一个目录,这个目录里面的所有文件都可以被Git管理起来,每个文件的修改,删除,Git都能跟踪,以便任何时刻都可以追踪历史,或者在将来某个时刻还可以将文件”还原”。
所以创建一个版本库也非常简单,如下我是D盘 –> www下 目录下新建一个testgit版本库。
通过命令 git init 把这个目录变成git可以管理的仓库,如下:

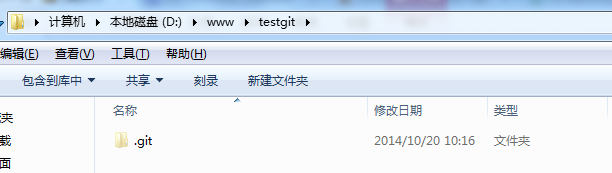
这时候你当前testgit目录下会多了一个.git的目录,这个目录是Git来跟踪管理版本的,没事千万不要手动乱改这个目录里面的文件,否则,会把git仓库给破坏了。如下:
我在版本库testgit目录下新建一个记事本文件 readme.txt 内容如下:11111111
第一步:使用命令 git add readme.txt添加到暂存区里面去。如下:
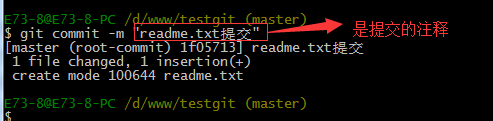
第二步:用命令 git commit告诉Git,把文件提交到仓库。
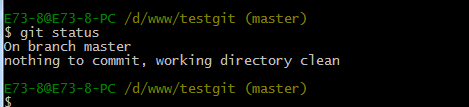
现在我们已经提交了一个readme.txt文件了,我们下面可以通过命令git status来查看是否还有文件未提交,如下:
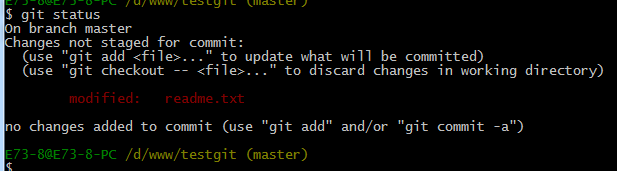
说明没有任何文件未提交,但是我现在继续来改下readme.txt内容,比如我在下面添加一行2222222222内容,继续使用git status来查看下结果,如下:

把文件添加到版本库中。
首先要明确下,所有的版本控制系统,只能跟踪文本文件的改动,比如txt文件,网页,所有程序的代码等,Git也不列外,版本控制系统可以告诉你每次的改动,但是图片,视频这些二进制文件,虽能也能由版本控制系统管理,但没法跟踪文件的变化,只能把二进制文件每次改动串起来,也就是知道图片从1kb变成2kb,但是到底改了啥,版本控制也不知道。
接下来我想看下readme.txt文件到底改了什么内容,如何查看呢?可以使用如下命令:
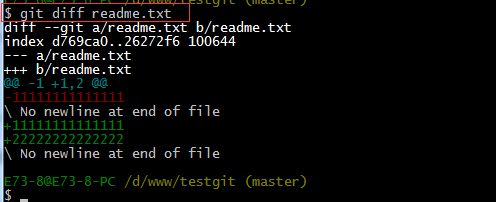
如上可以看到,readme.txt文件内容从一行11111111改成 二行 添加了一行22222222内容。
知道了对readme.txt文件做了什么修改后,我们可以放心的提交到仓库了,提交修改和提交文件是一样的2步(第一步是git add 第二步是:git commit)。
如下:
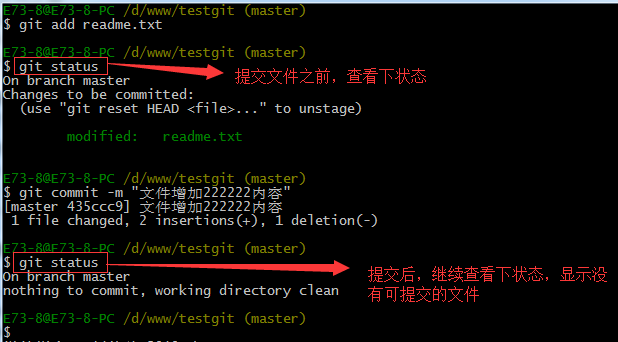
2.版本回退:
如上,我们已经学会了修改文件,现在我继续对readme.txt文件进行修改,再增加一行
内容为33333333333333.继续执行命令如下:
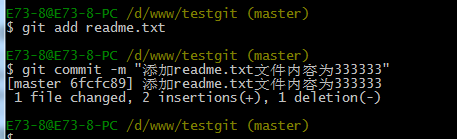
现在我已经对readme.txt文件做了三次修改了,那么我现在想查看下历史记录,如何查呢?我们现在可以使用命令 git log 演示如下所示:
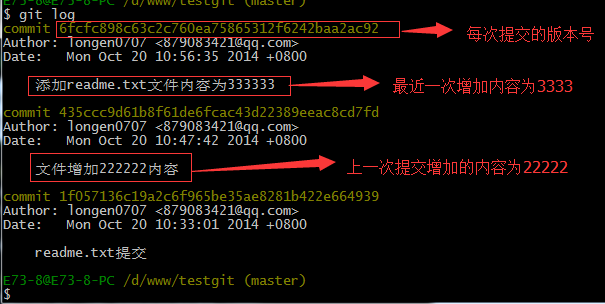
git log命令显示从最近到最远的显示日志,我们可以看到最近三次提交,最近的一次是,增加内容为333333.上一次是添加内容222222,第一次默认是 111111.如果嫌上面显示的信息太多的话,我们可以使用命令 git log –pretty=oneline 演示如下:

现在我想使用版本回退操作,我想把当前的版本回退到上一个版本,要使用什么命令呢?可以使用如下2种命令,第一种是:git reset —hard HEAD^ 那么如果要回退到上上个版本只需把HEAD^ 改成 HEAD^^ 以此类推。那如果要回退到前100个版本的话,使用上面的方法肯定不方便,我们可以使用下面的简便命令操作:git reset –hard HEAD~100 即可。未回退之前的readme.txt内容如下:
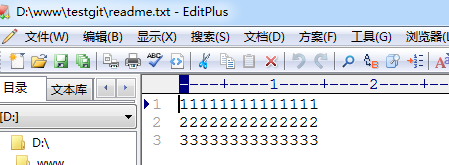
如果想回退到上一个版本的命令如下操作:
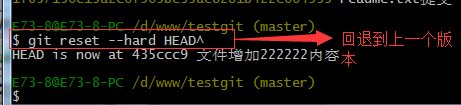
再来查看下 readme.txt内容如下:通过命令cat readme.txt查看

可以看到,内容已经回退到上一个版本了。我们可以继续使用git log 来查看下历史记录信息,如下:
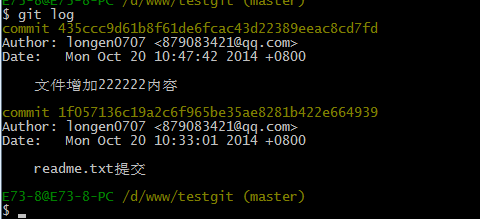
我们看到 增加333333 内容我们没有看到了,但是现在我想回退到最新的版本,如:有333333的内容要如何恢复呢?我们可以通过版本号回退,使用命令方法如下:
git reset –hard 版本号 ,但是现在的问题假如我已经关掉过一次命令行或者333内容的版本号我并不知道呢?要如何知道增加3333内容的版本号呢?可以通过如下命令即可获取到版本号:git reflog 演示如下:
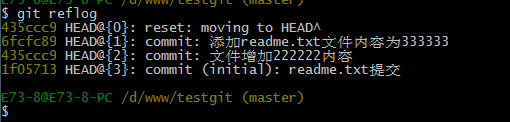
通过上面的显示我们可以知道,增加内容3333的版本号是 6fcfc89.我们现在可以命令
git reset –hard 6fcfc89来恢复了。演示如下:
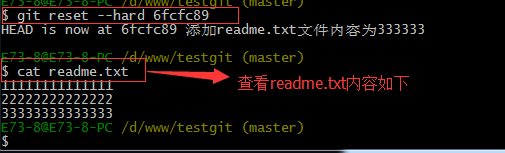
可以看到 目前已经是最新的版本了。
3.理解工作区与暂存区的区别?
工作区:就是你在电脑上看到的目录,比如目录下testgit里的文件(.git隐藏目录版本库除外)。或者以后需要再新建的目录文件等等都属于工作区范畴。
版本库(Repository):工作区有一个隐藏目录.git,这个不属于工作区,这是版本库。其中版本库里面存了很多东西,其中最重要的就是stage(暂存区),还有Git为我们自动创建了第一个分支master,以及指向master的一个指针HEAD。我们前面说过使用Git提交文件到版本库有两步:
第一步:是使用 git add 把文件添加进去,实际上就是把文件添加到暂存区。
第二步:使用git commit提交更改,实际上就是把暂存区的所有内容提交到当前分支上。
我们继续使用demo来演示下:
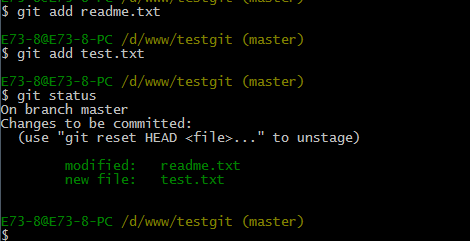
我们在readme.txt再添加一行内容为4444444,接着在目录下新建一个文件为test.txt 内容为test,我们先用命令 git status来查看下状态,如下:
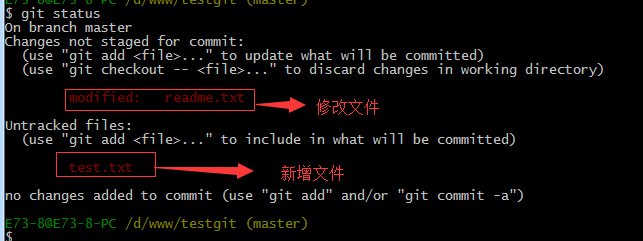
现在我们先使用git add 命令把2个文件都添加到暂存区中,再使用git status来查看下状态,如下:
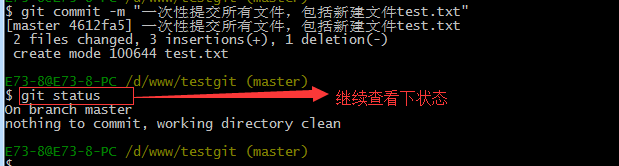
接着我们可以使用git commit一次性提交到分支上,如下:
4.Git撤销修改和删除文件操作。
4.1撤销修改:
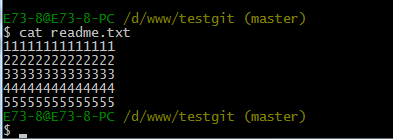
比如我现在在readme.txt文件里面增加一行 内容为555555555555,我们先通过命令查看如下:
在我未提交之前,我发现添加5555555555555内容有误,所以我得马上恢复以前的版本,现在我可以有如下几种方法可以做修改:
- 第一:如果我知道要删掉那些内容的话,直接手动更改去掉那些需要的文件,然后add添加到暂存区,最后commit掉。
- 第二:我可以按以前的方法直接恢复到上一个版本。使用 git reset –hard HEAD^
但是现在我不想使用上面的2种方法,我想直接想使用撤销命令该如何操作呢?首先在做撤销之前,我们可以先用 git status 查看下当前的状态。如下所示:
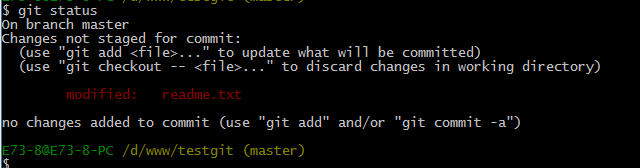
可以发现,Git会告诉你,git checkout — file 可以丢弃工作区的修改,如下命令:
git checkout — readme.txt,如下所示:
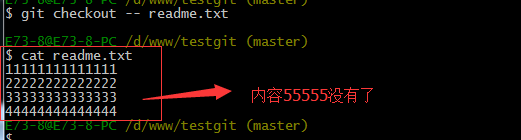
命令 git checkout —readme.txt 意思就是,把readme.txt文件在工作区做的修改全部撤销,这里有2种情况,如下:
- 1.readme.txt自动修改后,还没有放到暂存区,使用 撤销修改就回到和版本库一模一样的状态。
- 2.另外一种是readme.txt已经放入暂存区了,接着又作了修改,撤销修改就回到添加暂存区后的状态。
对于第二种情况,我想我们继续做demo来看下,假如现在我对readme.txt添加一行 内容为6666666666666,我git add 增加到暂存区后,接着添加内容7777777,我想通过撤销命令让其回到暂存区后的状态。如下所示:
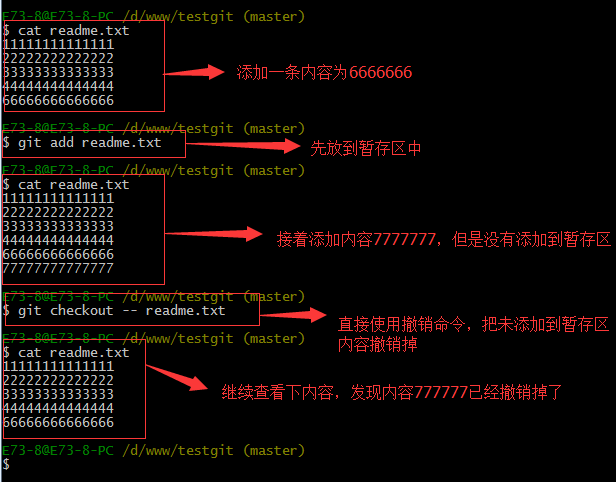
注意:命令git checkout — readme.txt 中的 — 很重要,如果没有 — 的话,那么命令变成创建分支了。
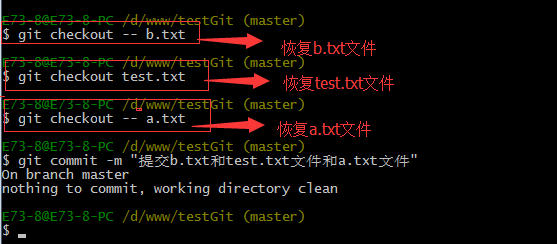
如上:一般情况下,可以直接在文件目录中把文件删了,或者使用如上rm命令:rm b.txt ,如果我想彻底从版本库中删掉了此文件的话,可以再执行commit命令 提交掉,现在目录是这样的,

只要没有commit之前,如果我想在版本库中恢复此文件如何操作呢?
可以使用如下命令 git checkout — b.txt,如下所示:
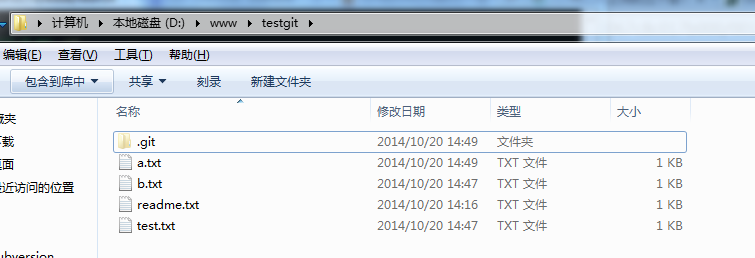
再来看看我们testgit目录,添加了3个文件了。如下所示:
5.github登录不上
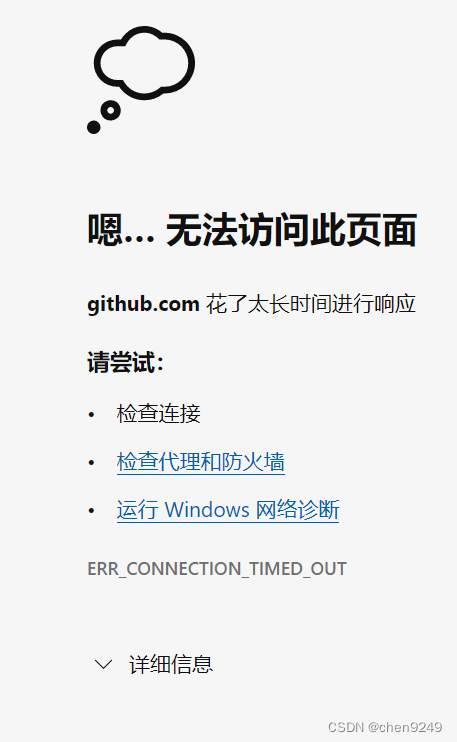
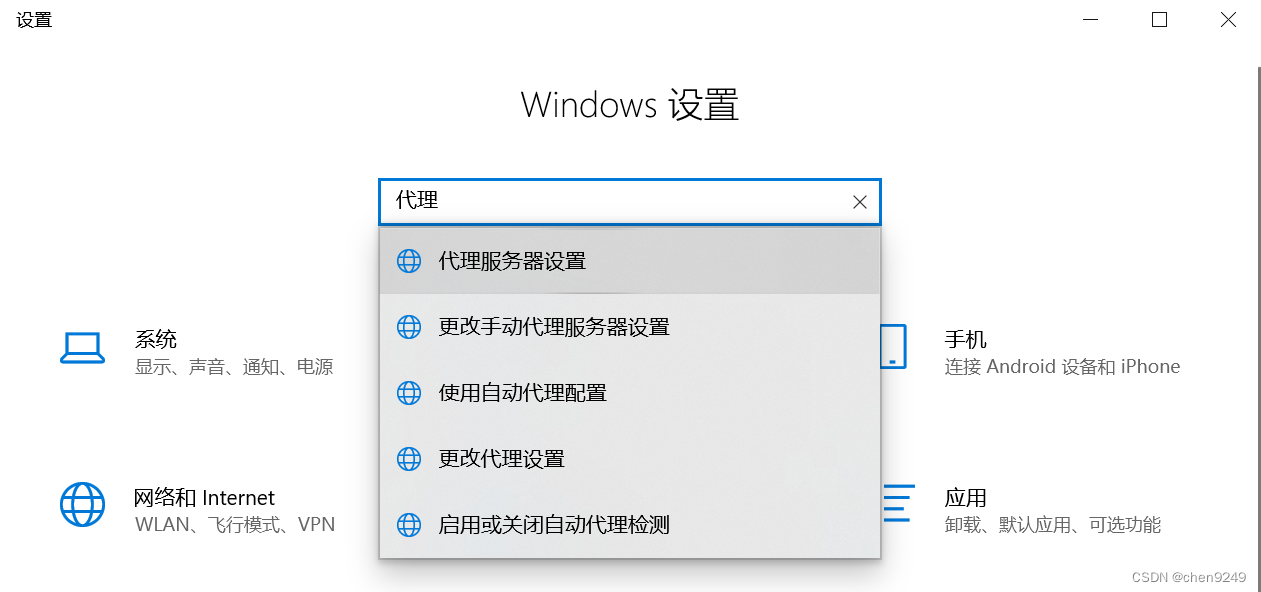
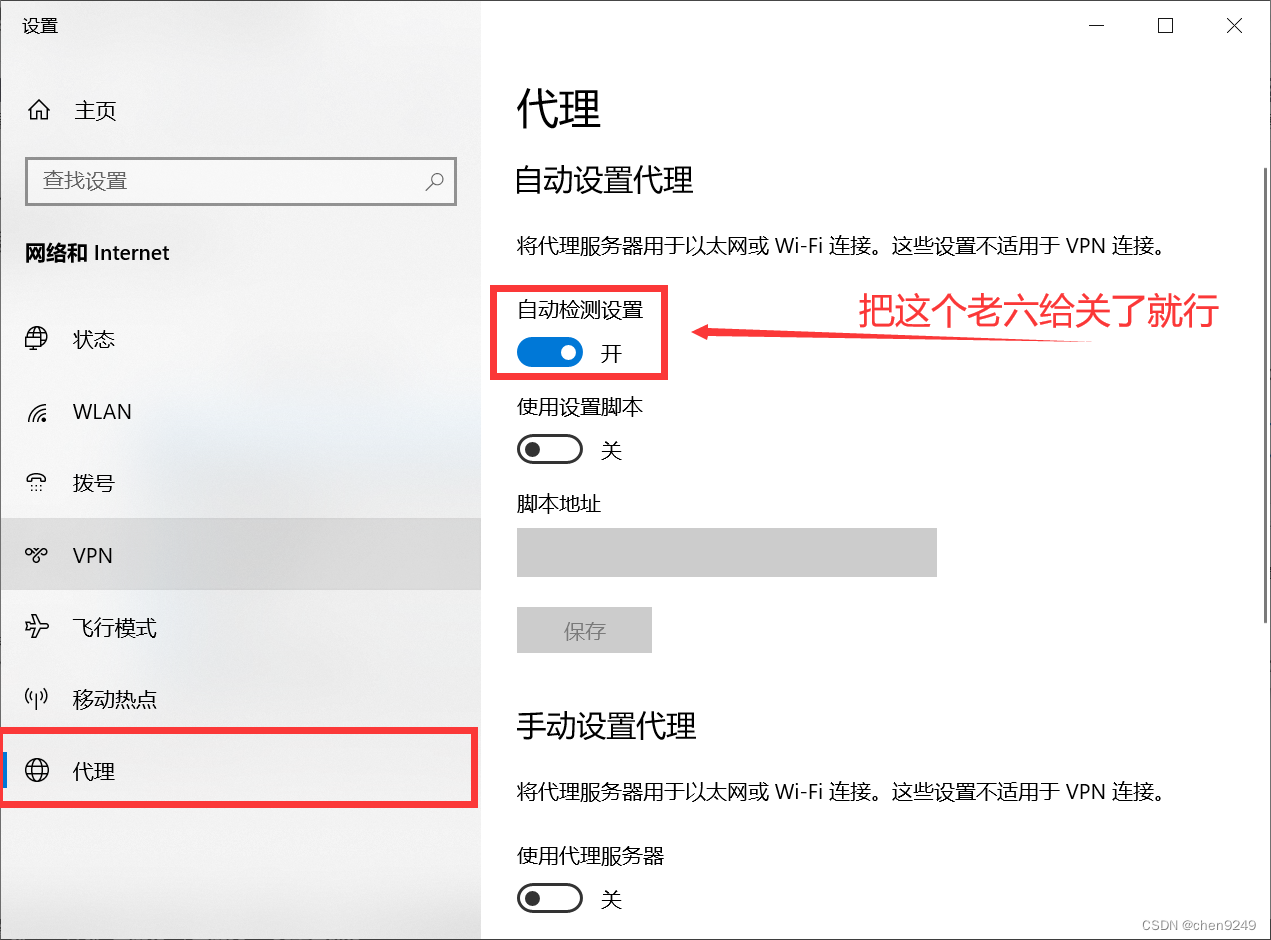
6.远程仓库。
在了解之前,先注册github账号,由于你的本地Git仓库和github仓库之间的传输是通过SSH加密的,所以需要一点设置:github网址:https://github.com/
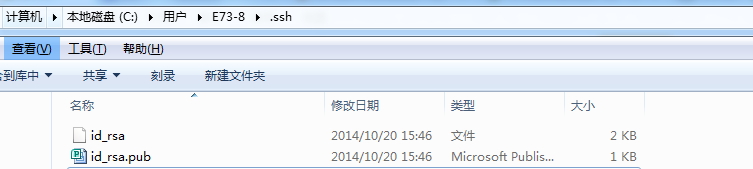
第一步:创建SSH Key。在用户主目录下,看看有没有.ssh目录,如果有,再看看这个目录下有没有id_rsa和id_rsa.pub这两个文件,如果有的话,直接跳过此如下命令,如果没有的话,打开命令行,输入如下命令:ssh–keygen -t rsa –C “youremail@example.com”, 由于我本地此前运行过一次,所以本地有,如下所示:
第二步:登录github,打开” settings”中的SSH Keys页面,然后点击“Add SSH Key”,填上任意title,在Key文本框里黏贴id_rsa.pub文件的内容。

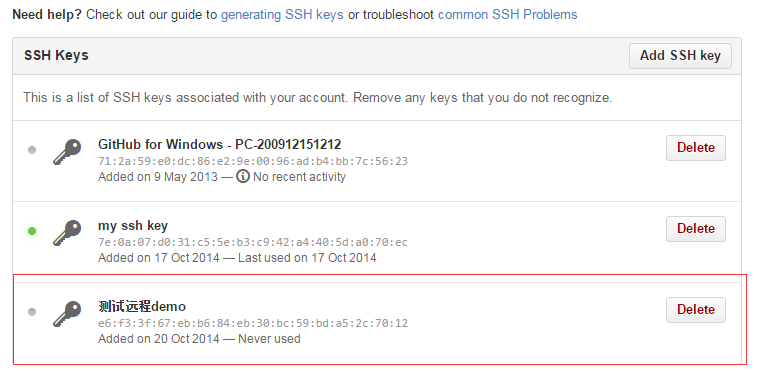
如何添加远程库?
现在的情景是:我们已经在本地创建了一个Git仓库后,又想在github创建一个Git仓库,并且希望这两个仓库进行远程同步,这样github的仓库可以作为备份,又可以其他人通过该仓库来协作。
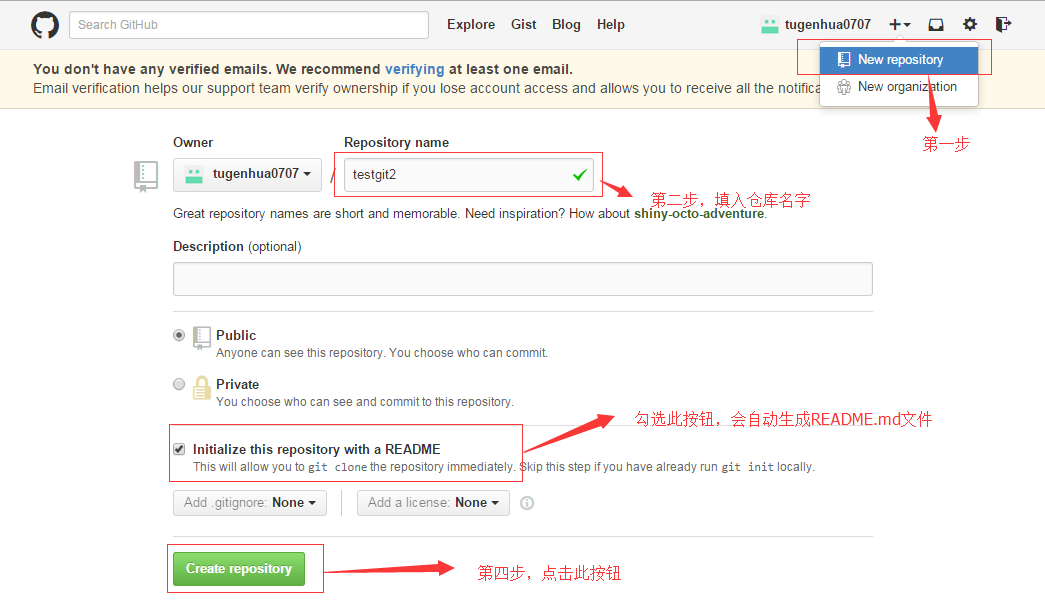
首先,登录github上,然后在右上角找到“create a new repo”创建一个新的仓库。如下:

在Repository name填入testgit,其他保持默认设置,点击“Create repository”按钮,就成功地创建了一个新的Git仓库:
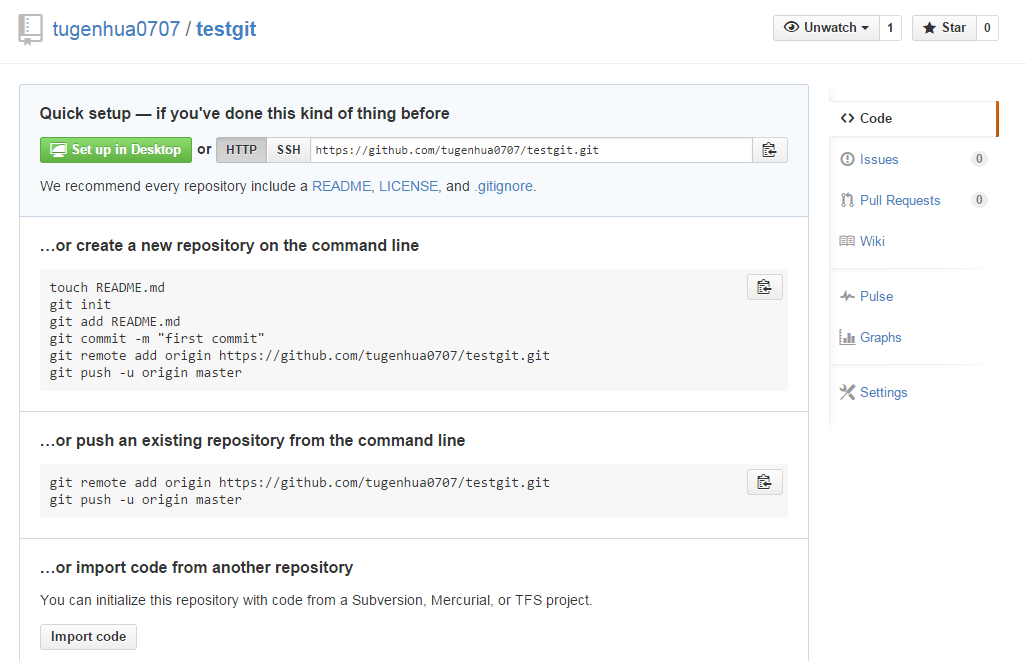
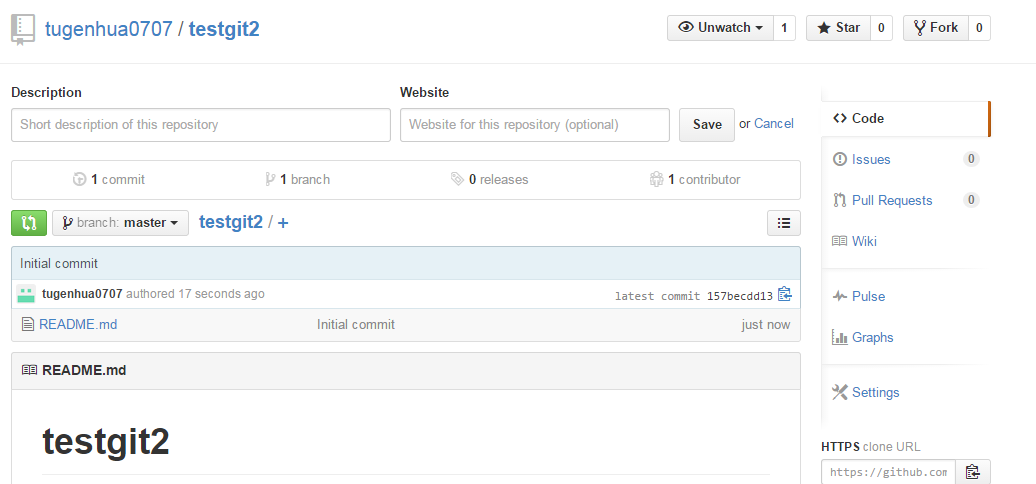
目前,在GitHub上的这个testgit仓库还是空的,GitHub告诉我们,可以从这个仓库克隆出新的仓库,也可以把一个已有的本地仓库与之关联,然后,把本地仓库的内容推送到GitHub仓库。现在,我们根据GitHub的提示,在本地的testgit仓库下运行命令:
git remote add origin https://github.com/tugenhua0707/testgit.git
所有的如下:
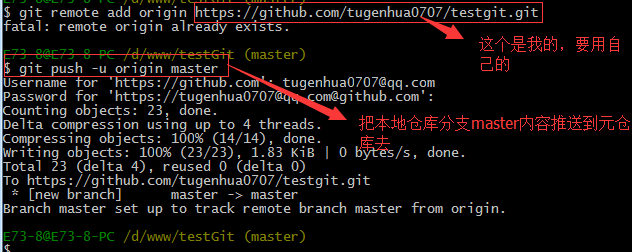
把本地库的内容推送到远程,使用 git push命令,实际上是把当前分支master推送到远程。
由于远程库是空的,我们第一次推送master分支时,加上了 –u参数,Git不但会把本地的master分支内容推送的远程新的master分支,还会把本地的master分支和远程的master分支关联起来,在以后的推送或者拉取时就可以简化命令。推送成功后,可以立刻在github页面中看到远程库的内容已经和本地一模一样了,上面的要输入github的用户名和密码如下所示:
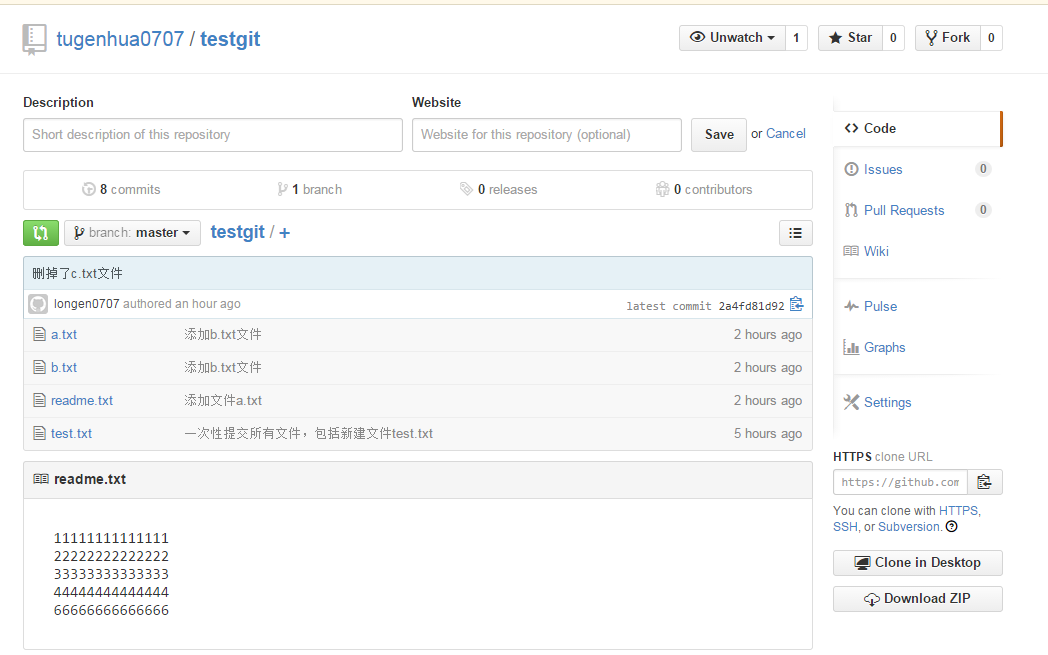
从现在起,只要本地作了提交,就可以通过如下命令:
把本地master分支的最新修改推送到github上了,现在你就拥有了真正的分布式版本库了。
-
如何从远程库克隆?
现在我们想,假如远程库有新的内容了,我想克隆到本地来 如何克隆呢?
如下,我们看到:
现在,远程库已经准备好了,下一步是使用命令git clone克隆一个本地库了。如下所示:

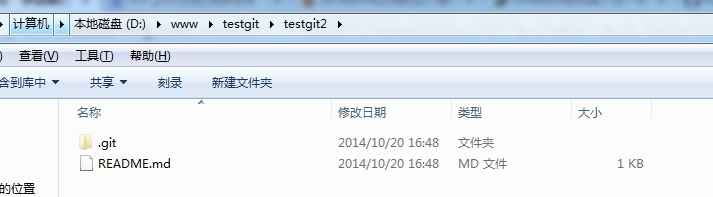
接着在我本地目录下 生成testgit2目录了,如下所示:
7.git克隆出现连接超时如何解决
1、当我们用git去克隆一个项目时,发现总是连接超时报错,克隆不了,如何排查?
2、重点:解决方法
- 打开cmd窗口,输入ping github.com,看是否能ping通,如何是请求超时,则应该是本地DNS无法解析导致的
- 此时需要打开C:WindowsSystem32driversetc下的hosts文件,我们可以发现该文件并没有配置github的相关解析
192.30.255.112 github.com git
185.31.16.184 github.global.ssl.fastly.net(3)此时再去ping github.com,发现ping通了
3、此时git克隆也能使用了


8.创建与合并分支。
在 版本回填退里,你已经知道,每次提交,Git都把它们串成一条时间线,这条时间线就是一个分支。截止到目前,只有一条时间线,在Git里,这个分支叫主分支,即master分支。HEAD严格来说不是指向提交,而是指向master,master才是指向提交的
,所以,HEAD指向的就是当前分支。
首先,我们来创建dev分支,然后切换到dev分支上。如下操作:
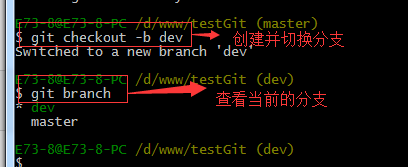
git checkout 命令加上 –b参数表示创建并切换,相当于如下2条命令
git branch查看分支,会列出所有的分支,当前分支前面会添加一个星号。然后我们在dev分支上继续做demo,比如我们现在在readme.txt再增加一行 7777777777777
首先我们先来查看下readme.txt内容,接着添加内容77777777,如下:

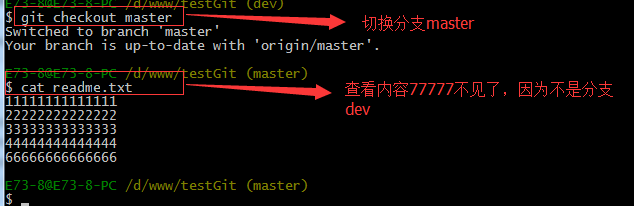
现在dev分支工作已完成,现在我们切换到主分支master上,继续查看readme.txt内容如下:
现在我们可以把dev分支上的内容合并到分支master上了,可以在master分支上,使用如下命令 git merge dev 如下所示:
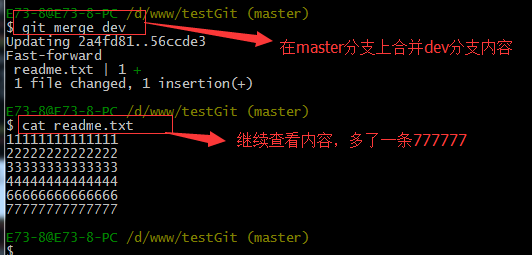
git merge命令用于合并指定分支到当前分支上,合并后,再查看readme.txt内容,可以看到,和dev分支最新提交的是完全一样的。
注意到上面的Fast-forward信息,Git告诉我们,这次合并是“快进模式”,也就是直接把master指向dev的当前提交,所以合并速度非常快。
合并完成后,我们可以接着删除dev分支了,操作如下:
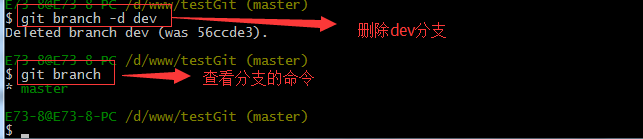
总结创建与合并分支命令如下:
查看分支:git branch
创建分支:git branch name
合并某分支到当前分支:git merge name
删除分支:git branch –d name
8.1如何解决冲突?
下面我们还是一步一步来,先新建一个新分支,比如名字叫fenzhi1,在readme.txt添加一行内容8888888,然后提交,如下所示:

同样,我们现在切换到master分支上来,也在最后一行添加内容,内容为99999999,如下所示:
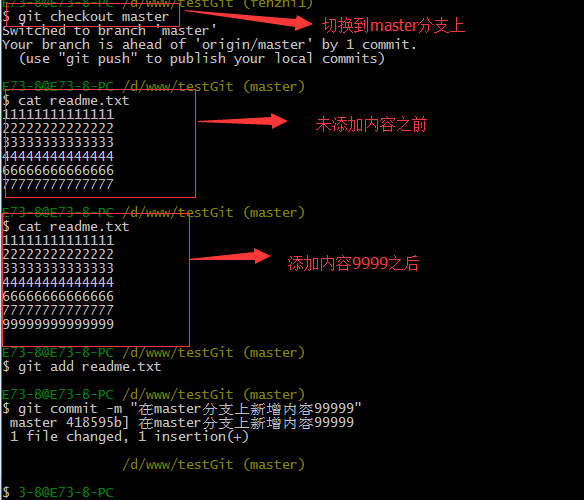
现在我们需要在master分支上来合并fenzhi1,如下操作:
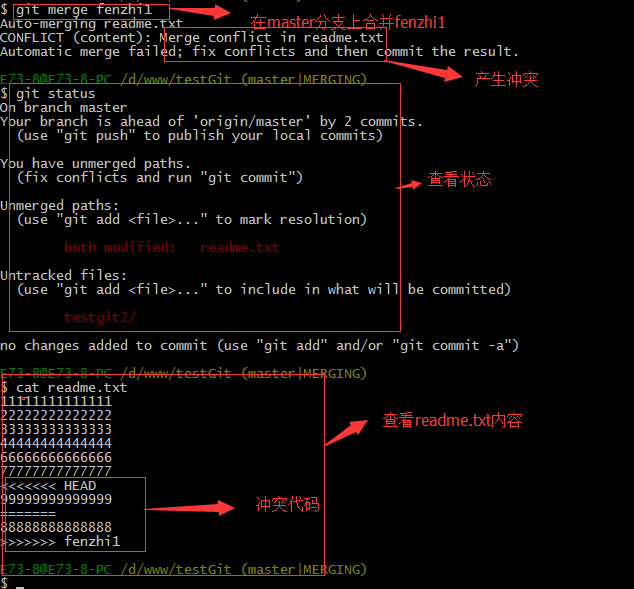
Git用<<<<<<<,=======,>>>>>>>标记出不同分支的内容,其中<<<HEAD是指主分支修改的内容,>>>>>fenzhi1 是指fenzhi1上修改的内容,我们可以修改下如下后保存:
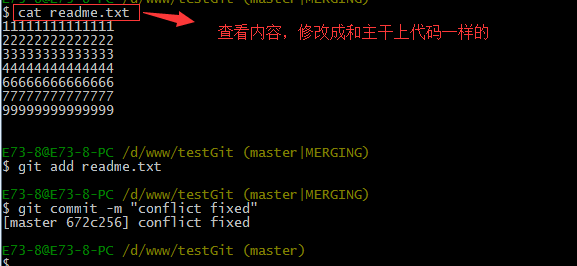
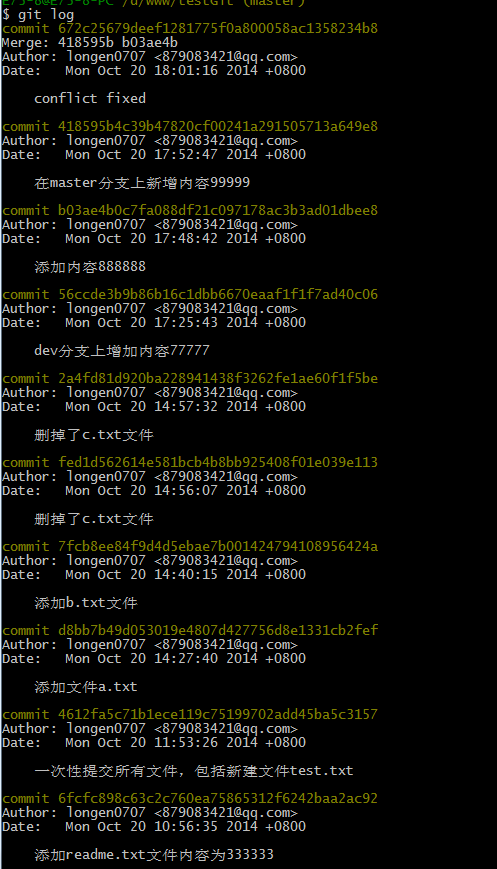
如果我想查看分支合并的情况的话,需要使用命令 git log.命令行演示如下:
8.2分支管理策略。
通常合并分支时,git一般使用”Fast forward”模式,在这种模式下,删除分支后,会丢掉分支信息,现在我们来使用带参数 –no-ff来禁用”Fast forward”模式。首先我们来做demo演示下:
截图如下:
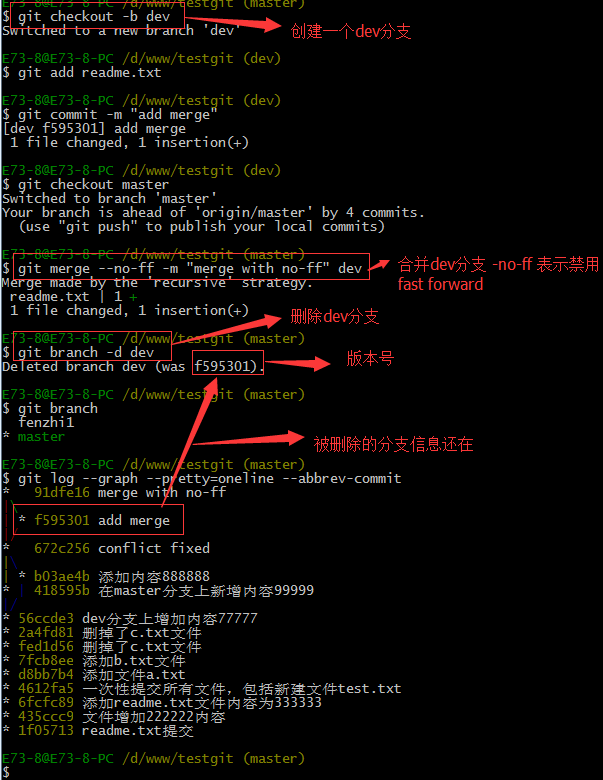
分支策略:首先master主分支应该是非常稳定的,也就是用来发布新版本,一般情况下不允许在上面干活,干活一般情况下在新建的dev分支上干活,干完后,比如上要发布,或者说dev分支代码稳定后可以合并到主分支master上来。
9.bug分支:
在开发中,会经常碰到bug问题,那么有了bug就需要修复,在Git中,分支是很强大的,每个bug都可以通过一个临时分支来修复,修复完成后,合并分支,然后将临时的分支删除掉。
比如我在开发中接到一个404 bug时候,我们可以创建一个404分支来修复它,但是,当前的dev分支上的工作还没有提交。比如如下:
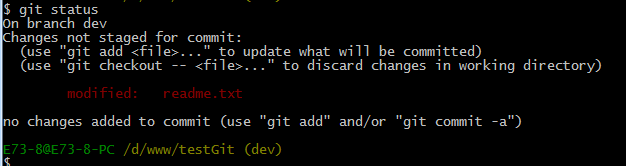
并不是我不想提交,而是工作进行到一半时候,我们还无法提交,比如我这个分支bug要2天完成,但是我issue-404 bug需要5个小时内完成。怎么办呢?还好,Git还提供了一个stash功能,可以把当前工作现场 ”隐藏起来”,等以后恢复现场后继续工作。如下:
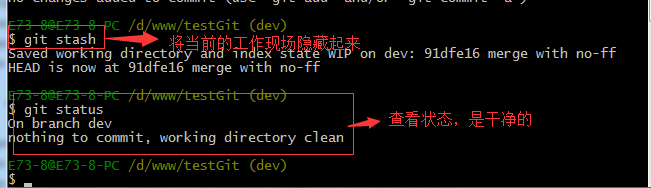
所以现在我可以通过创建issue-404分支来修复bug了。
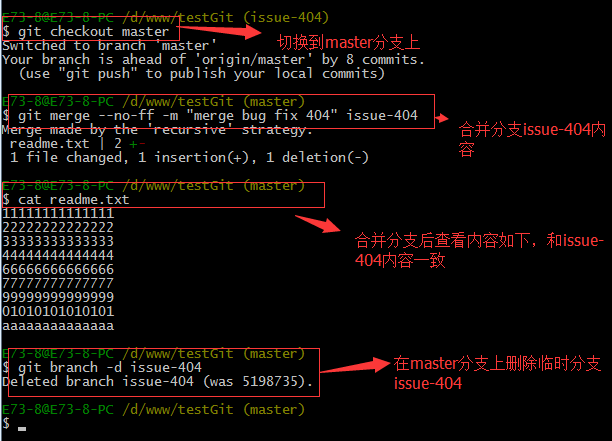
首先我们要确定在那个分支上修复bug,比如我现在是在主分支master上来修复的,现在我要在master分支上创建一个临时分支,演示如下:
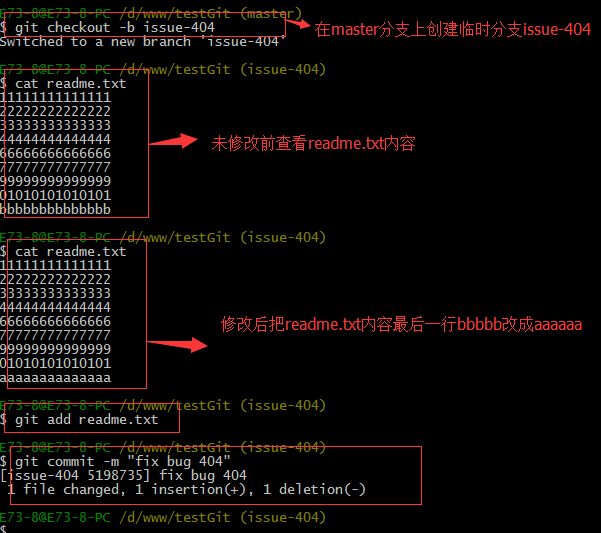
修复完成后,切换到master分支上,并完成合并,最后删除issue-404分支。演示如下:
现在,我们回到dev分支上干活了。
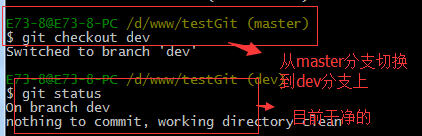
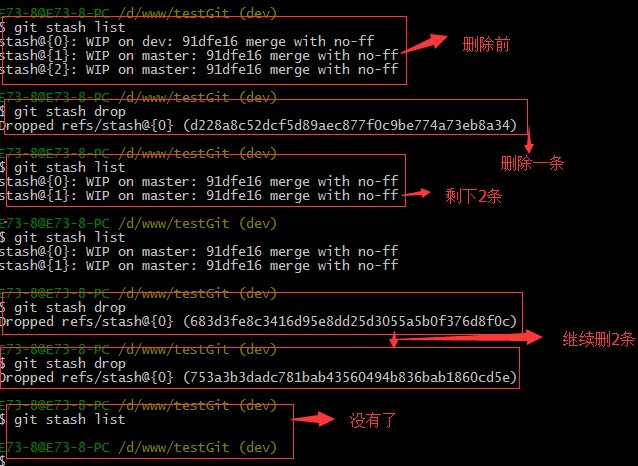
工作区是干净的,那么我们工作现场去哪里呢?我们可以使用命令 git stash list来查看下。如下:

工作现场还在,Git把stash内容存在某个地方了,但是需要恢复一下,可以使用如下2个方法:
1.git stash apply恢复,恢复后,stash内容并不删除,你需要使用命令git stash drop来删除。
2.另一种方式是使用git stash pop,恢复的同时把stash内容也删除了。
演示如下
10.多人协作。
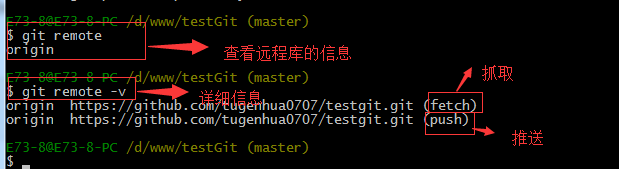
当你从远程库克隆时候,实际上Git自动把本地的master分支和远程的master分支对应起来了,并且远程库的默认名称是origin。
要查看远程库的信息 使用 git remote
要查看远程库的详细信息 使用 git remote –v
如下演示:
10.1推送分支:
比如我现在的github上的readme.txt代码如下:
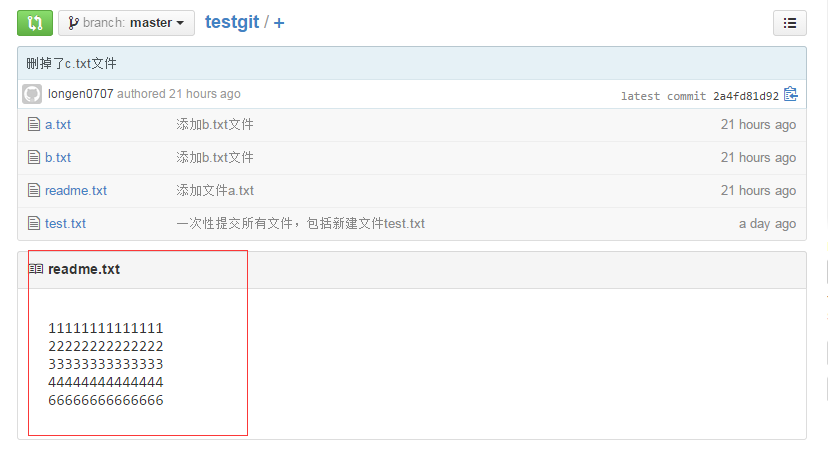
本地的readme.txt代码如下:
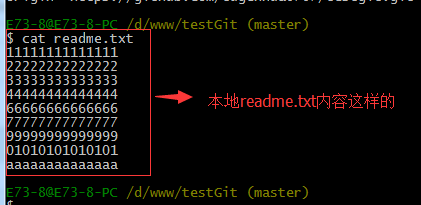
现在我想把本地更新的readme.txt代码推送到远程库中,使用命令如下:
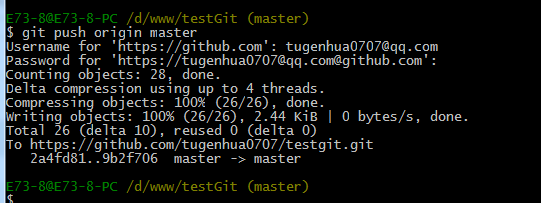
我们可以看到如上,推送成功,我们可以继续来截图github上的readme.txt内容 如下:
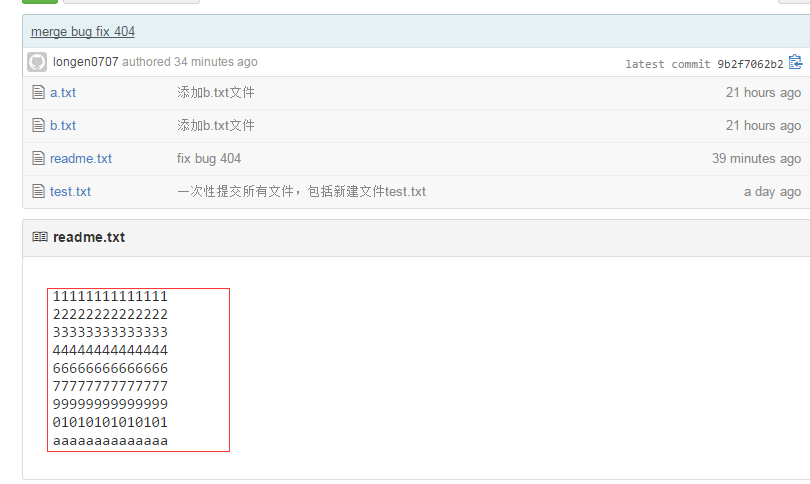
可以看到 推送成功了,如果我们现在要推送到其他分支,比如dev分支上,我们还是那个命令 git push origin dev
那么一般情况下,那些分支要推送呢?
master分支是主分支,因此要时刻与远程同步。
一些修复bug分支不需要推送到远程去,可以先合并到主分支上,然后把主分支master推送到远程去。
10.2抓取分支:
多人协作时,大家都会往master分支上推送各自的修改。现在我们可以模拟另外一个同事,可以在另一台电脑上(注意要把SSH key添加到github上)或者同一台电脑上另外一个目录克隆,新建一个目录名字叫testgit2
但是我首先要把dev分支也要推送到远程去,如下
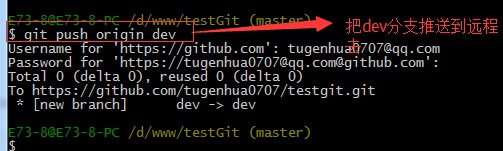
接着进入testgit2目录,进行克隆远程的库到本地来,如下:
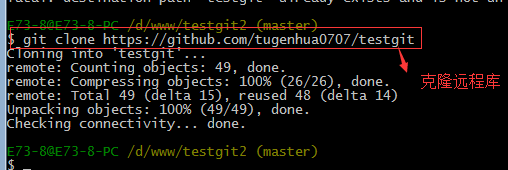
现在目录下生成有如下所示:
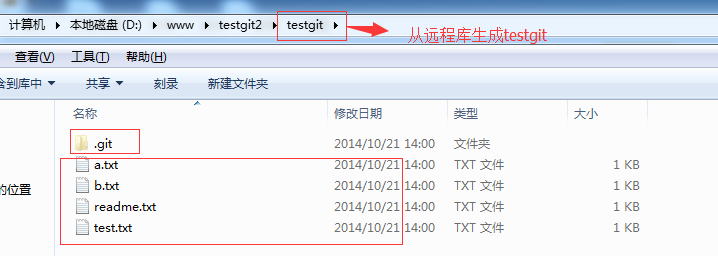
现在我们的小伙伴要在dev分支上做开发,就必须把远程的origin的dev分支到本地来,于是可以使用命令创建本地dev分支:git checkout –b dev origin/dev
现在小伙伴们就可以在dev分支上做开发了,开发完成后把dev分支推送到远程库时。
如下:
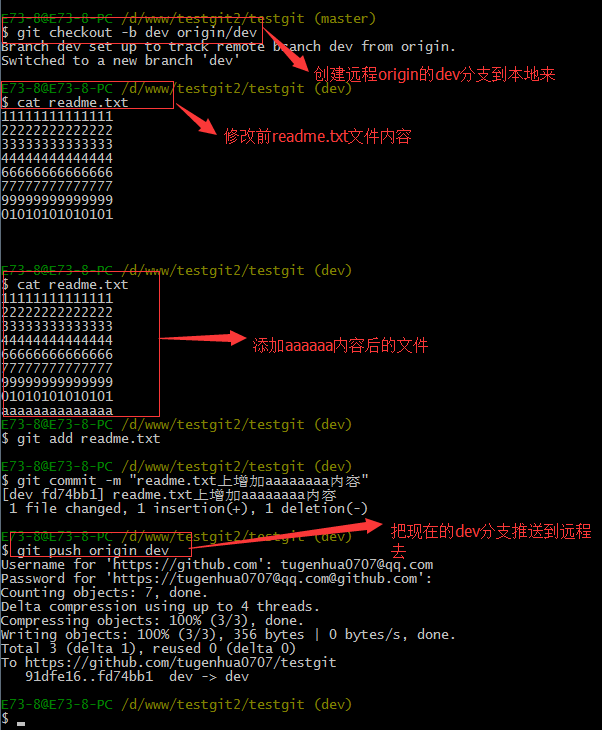
小伙伴们已经向origin/dev分支上推送了提交,而我在我的目录文件下也对同样的文件同个地方作了修改,也试图推送到远程库时,如下:
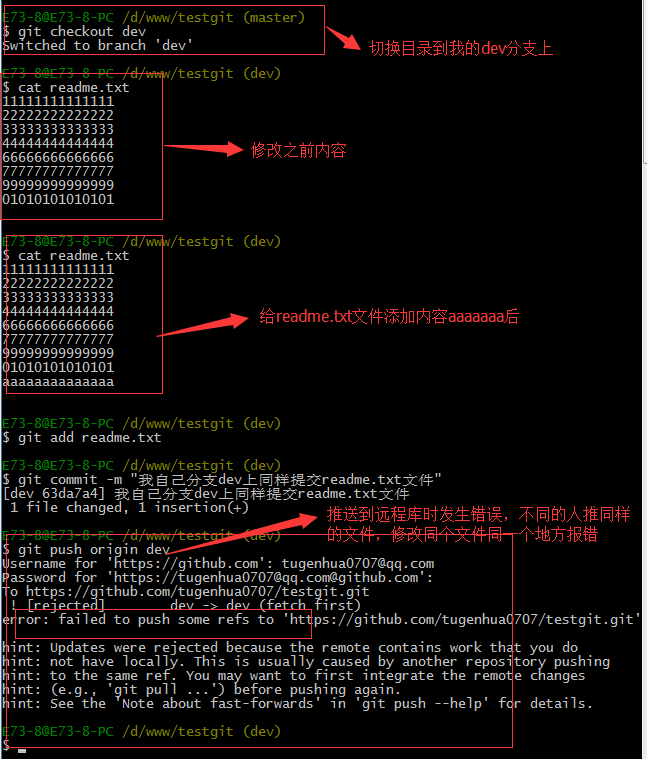
由上面可知:推送失败,因为我的小伙伴最新提交的和我试图推送的有冲突,解决的办法也很简单,上面已经提示我们,先用git pull把最新的提交从origin/dev抓下来,然后在本地合并,解决冲突,再推送。
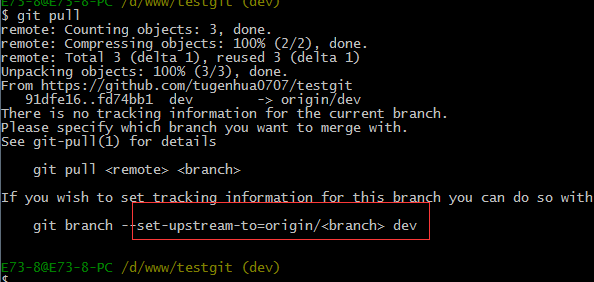
git pull也失败了,原因是没有指定本地dev分支与远程origin/dev分支的链接,根据提示,设置dev和origin/dev的链接:如下:
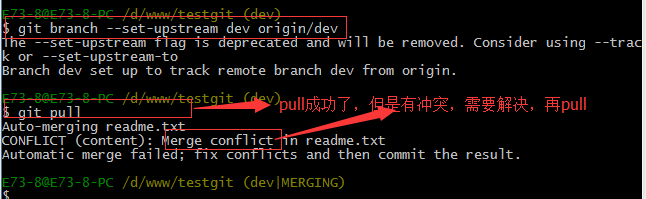
这回git pull成功,但是合并有冲突,需要手动解决,解决的方法和分支管理中的 解决冲突完全一样。解决后,提交,再push:
我们可以先来看看readme.txt内容了。
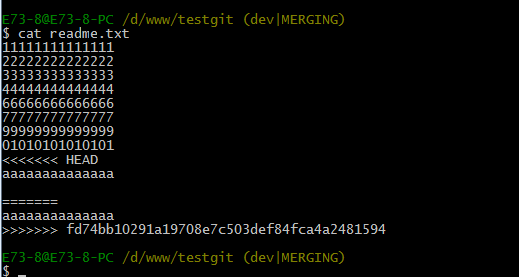
现在手动已经解决完了,我接在需要再提交,再push到远程库里面去。如下所示:
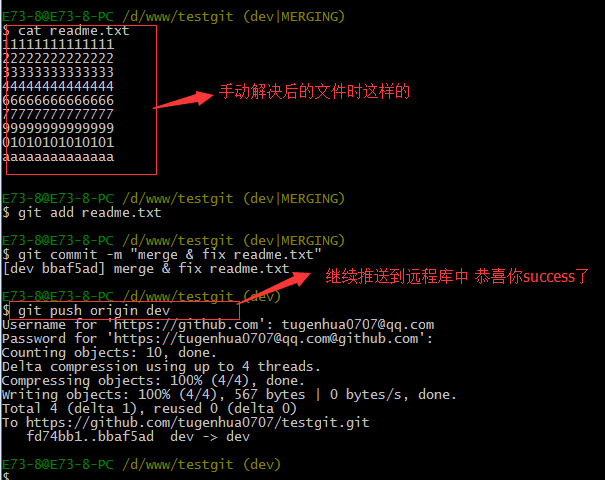
因此:多人协作工作模式一般是这样的:
首先,可以试图用git push origin branch-name推送自己的修改.
如果推送失败,则因为远程分支比你的本地更新早,需要先用git pull试图合并。
如果合并有冲突,则需要解决冲突,并在本地提交。再用git push origin branch-name推送。
四.网络基础知识
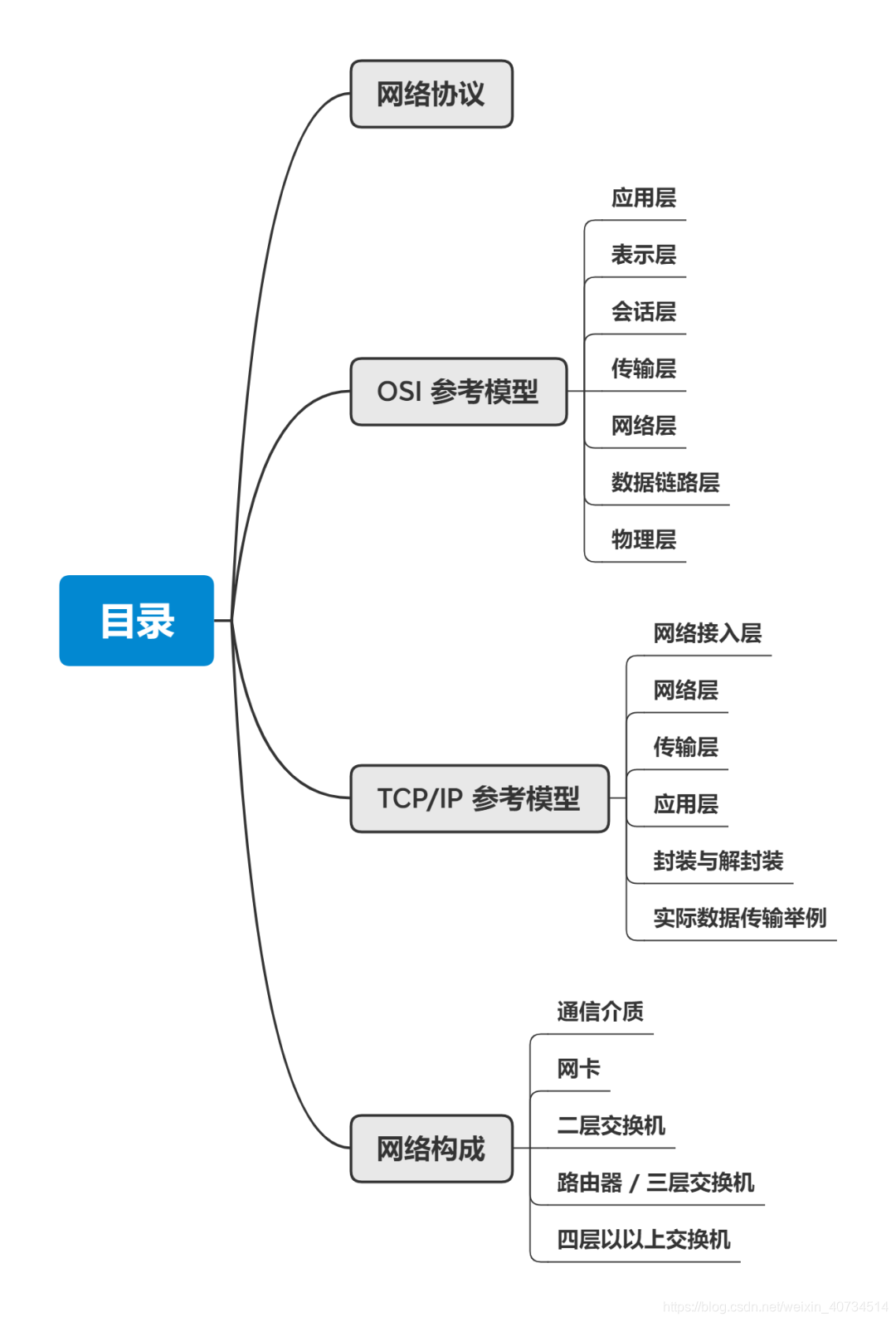
网络基础知识详解(图解版)
1.网络协议:
我们用手机连接上网的时候,会用到许多网络协议。从手机连接 WiFi 开始,使用的是 802.11 (即 WLAN )协议;
手机自动获取网络配置,使用的是 DHCP 协议。
这时手机已经连入局域网了,可以访问局域网内的主机和资源,但还不能使用互联网应用,例如:微信、抖音等。想要访问互联网,还需要在手机的上联网络设备上进行配置,即在无线路由器上配置 NAT、 PPPOE 等功能,才能把局域网接入到互联网中,手机就可以上网玩微信、刷抖音了。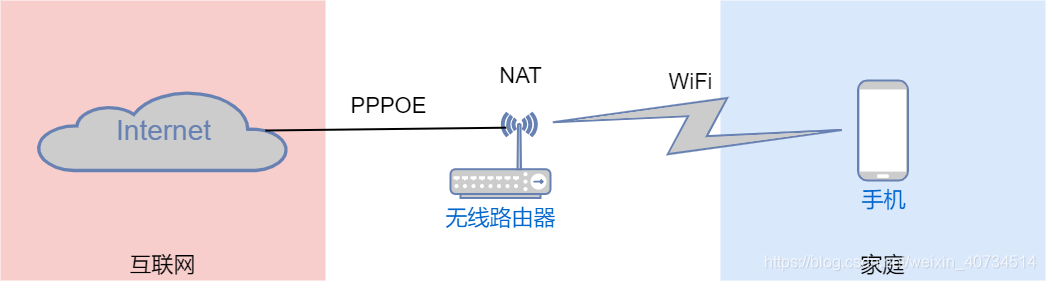
局域网 :小范围内的私有网络,一个家庭内的网络、一个公司内的网络、一个校园内的网络都属于局域网。
广域网:把不同地域的局域网互相连接起来的网络。运营商搭建连接远距离区域的广域网。
互联网:由世界各地的局域网和广域网连接起来的网络。互联网是一个开放、互联的网络,不属于任何个人和任何机构。
简单来说,就是手机、无线路由器等设备通过网络协议实现通信。网络协议又是谁规定的呢?ISO 制定了一个 OSI 参考模型,被用于网络协议的制定。
2.OSI 参考模型:
OSI 参考模型将网络协议提供的服务分成== 7 层==,并定义每一层的服务内容,实现每一层服务的是协议,协议的具体内容是规范。上下层之间通过接口进行交互,同一层之间通过协议进行交互。OSI 参考模型只对各层的服务做了粗略的界定,并没有对协议进行详细的定义。但是许多协议都对应了 7 个分层的某一层。所以要了解网络,首先要了解OSI 参考模型。

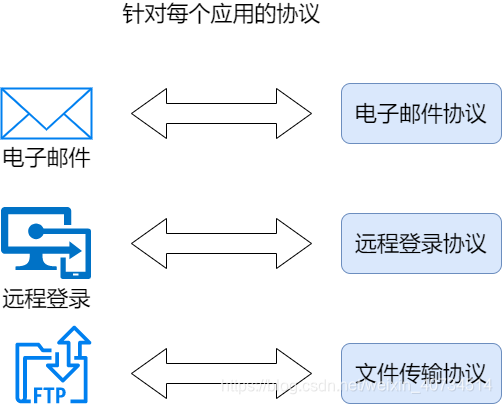
3.应用层:
OSI参考模型的第 7 层(最高层)。应用程序和网络之间的接口,直接向用户提供服务。应用层协议有电子邮件、远程登录等协议。
4.表示层:
OSI参考模型的第 6 层。负责数据格式的互相转换,如编码、数据格式转换和加密解密等。保证一个系统应用层发出的信息可被另一系统的应用层读出。
5.会话层:
OSI参考模型的第 5 层。主要是管理和协调不同主机上各种进程之间的通信(对话),即负责建立、管理和终止应用程序之间的会话。

6.传输层:
OSI参考模型的第 4 层。为上层协议提供通信主机间的可靠和透明的数据传输服务,包括处理差错控制和流量控制等问题。
7.网络层:
OSI参考模型的第 3 层。将数据传输到目的地址,主要负责寻址和路由选择。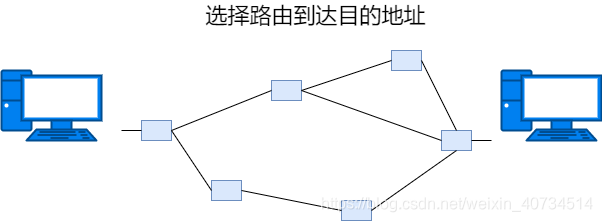
8.数据链路层:
OSI参考模型的第 2 层。负责两个相邻主机间的通信传输,即数据帧的生成与接收。
9.物理层:
OSI参考模型的第 1 层(最底层)。负责逻辑信号(比特流)与物理信号(电信号、光信号)之间的互相转换,利用传输介质为数据链路层提供物理连接。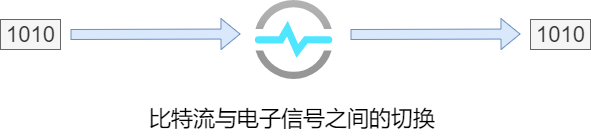
10.TCP/IP 参考模型:
由于 OSI 参考模型把服务划得过于琐碎,先定义参考模型再定义协议,有点理想化。TCP/IP 模型则正好相反,通过已有的协议归纳总结出来的模型,成为实际的主流网络协议标准。
先介绍下 TCP/IP 与 OSI 分层之间的对应关系,以及 TCP/IP 每层的主要协议。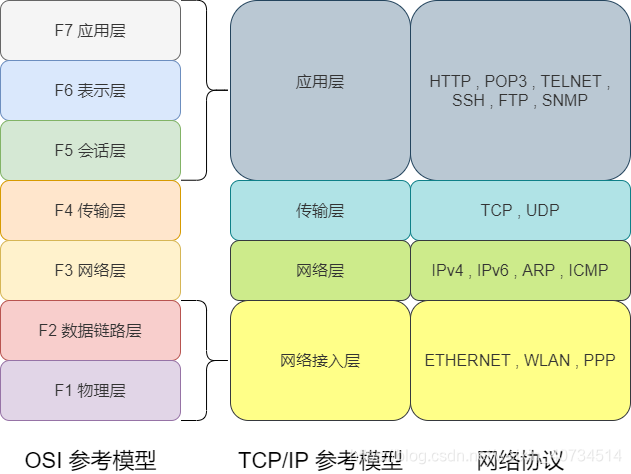
11.网络接入层:
在 TCP/IP 分层中,有把物理层和数据链路层合并称为网络接入层,有把物理层和数据链路层分别称为硬件、网络接口层。网络接入层是对网络介质的管理,定义如何使用网络来传送数据,但是对物理层和数据链路层在通信过程中起到了不一样的作用。所以 TCP/IP 分为四层或者五层都可以,只要能理解其中的原理就行。
12.网络层:
相当于 OSI 模型中的第 3 层网络层,使用的是IP协议,作用是将数据包从源地址发送到目的地址。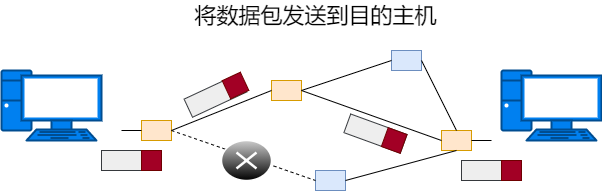
IP
IP 是跨越网络传送数据包, 使整个互联网都能收到数据的协议,它使用 IP 地址作为主机的标识。IP 协议独立于底层介质,
实现从源到目的的数据转发。
ICMP
用于在 IP 主机、路由器之间传递控制消息。被用来诊断网络的健康状况。
ARP
13.传输层:
相当于 OSI 模型中的第 4 层传输层,主要功能就是让应用程序之间互相通信,通过端口号识别应用程序,使用的协议有面向连接的 TCP 协议和面向无连接的 UDP 协议。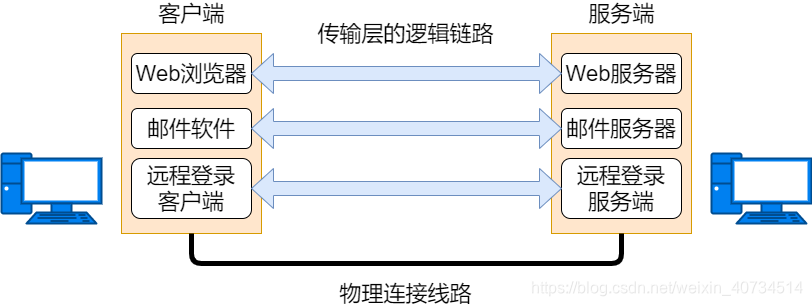
TCP
TCP 是一种面向有连接的传输层协议,能够对自己提供的连接实施控制。适用于要求可靠传输的应用,例如文件传输。
UDP
UDP 是一种面向无连接的传输层协议,不会对自己提供的连接实施控制。适用于实时应用,例如:IP电话、视频会议、直播等。
14.应用层:
相当于 OSI 模型中的第 5 – 7 层的集合,不仅要实现 OSI 模型应用层的功能,还要实现会话层和表示层的功能。HTTP 、 POP3 、 TELNET 、 SSH 、 FTP 、 SNMP都是应用层协议。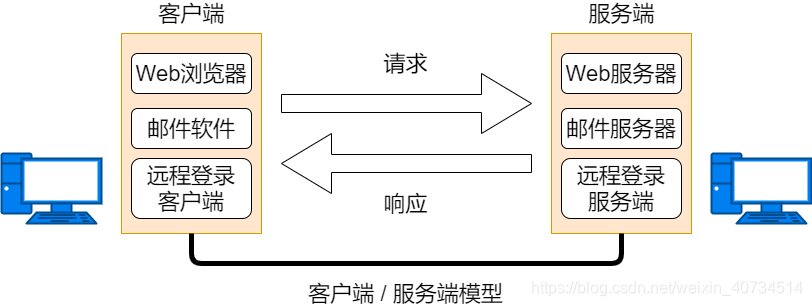
HTTP
是 WWW 浏览器和服务器之间的应用层通信协议。HTTP 定义高级命令或者方法供浏览器用来与Web服务器通信。
POP3
TELNET
SSH
安全外壳协议。通过使用SSH,可以把所有传输的数据进行加密。
SNMP
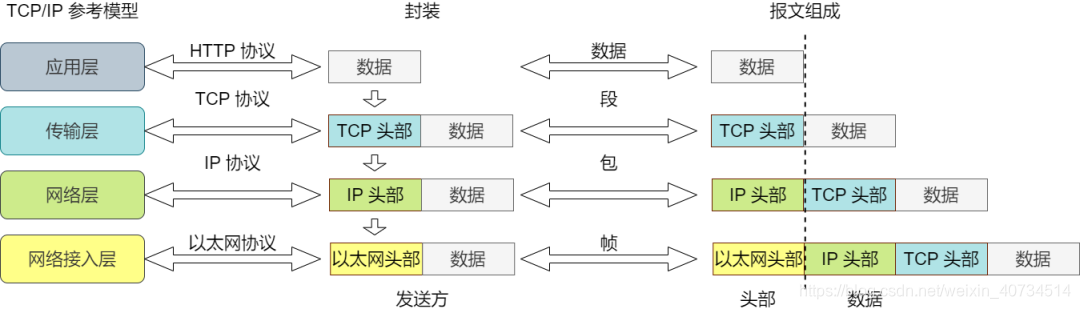
数据发送前,按照参考模型从上到下,在数据经过每一层时,添加协议头部信息,这个过程叫封装。
数据接收后,按照参考模型从下到上,在数据经过每一层时,去掉协议头部信息,这个过程叫解封装。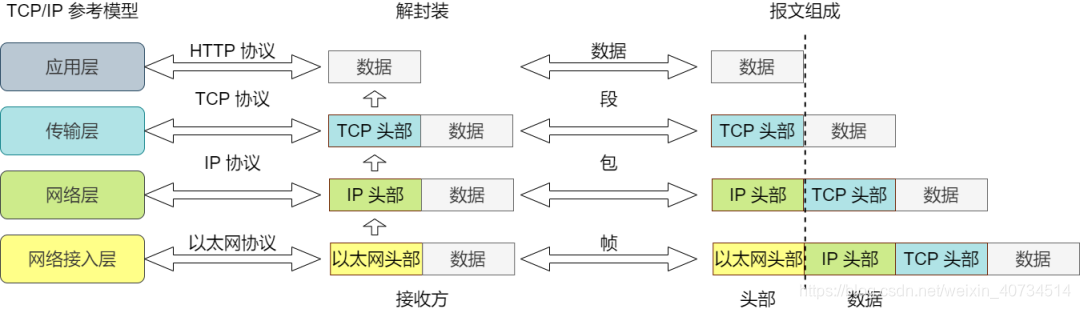
经过传输层协议封装后的数据称为段,经过网络层协议封装后的数据称为包,经过数据链路层协议封装后的数据称为帧,物理层传输的数据为比特。
16.实际数据传输举例:
实际生活中,互联网是使用的 TCP/IP 协议进行网络连接的。我们以访问网站为例,看看网络是如何进行通信的。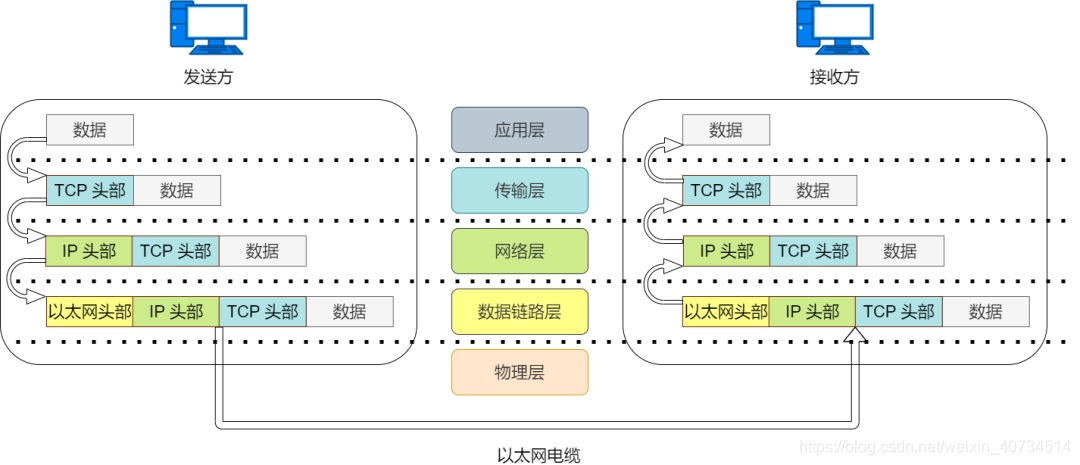
发送数据包
访问 HTTP 网站页面时,打开浏览器,输入网址,敲下回车键就开始进行 TCP/IP 通信了。
应用程序处理
首先,应用程序中会进行 HTML 格式编码处理,相当于 OSI 的表示层功能。编码转化后,不一定会马上发送出去,相当于会话层的功能。在请求发送的那一刻,建立 TCP 连接,然后在 TCP 连接上发送数据。接下来就是将数据发送给下一层的 TCP 进行处理。
TCP 模块处理
TCP 会将应用层发来的数据顺利的发送至目的地,实现可靠传输的功能,需要给数据封装 TCP 头部信息。TCP 头部信息包括源端口号和目的端口号(识别主机上应用)、序号(确认哪部分是数据)以及校验和(判断数据是否被损坏)。随后封装了 TCP 头部信息的段再发送给 IP 。
IP 模块处理
IP 将 TCP 传过来的数据段当做自己的数据,并封装 IP 头部信息。IP 头部信息中包含目的 IP 地址和源 IP 地址,以及上层协议类型信息。
网络接口处理
网络接口对传过来的 IP 包封装上以太网头部信息并进行发送处理。以太网头部信息包含目的 MAC 地址、源 MAC 地址,以及上层协议类型信息。然后将以太网数据帧通过物理层传输给接收端。
网络接口处理
收到以太网帧后,首先查看头部信息的目的 MAC 地址是否是发给自己的帧。如果不是发送给自己的帧就丢弃。如果是发送给自己的帧,查看上层协议类型是 IP 包,以太网帧解封装成 IP 包,传给 IP 模块进行处理。
IP 模块处理
收到 IP 包后,进行类似处理。根据头部信息的目的 IP 地址判断是否是发送给自己包,如果是发送给自己的包,则查看上一层的协议类型,并把 IP 包解封装发送给 TCP 协议处理。
TCP 模块处理
收到 TCP 段后,首先查看校验和,判断数据是否被破坏。然后检查是否按照序号接收数据。最后检查端口号,确定具体的应用程序。
数据接收完毕后,发送一个 “ 确认回执 ” 给发送端。
数据被完整接收后,会把 TCP 段解封装发送给由端口号识别的应用程序。
应用程序处理
应用程序收到数据后,通过解析数据知道了发送端请求的网页内容,然后按照 HTTP 协议进行后续数据交互。
17.网络构成:
搭建一套网络涉及各种线缆和网络设备。下面介绍一些常见的硬件设备。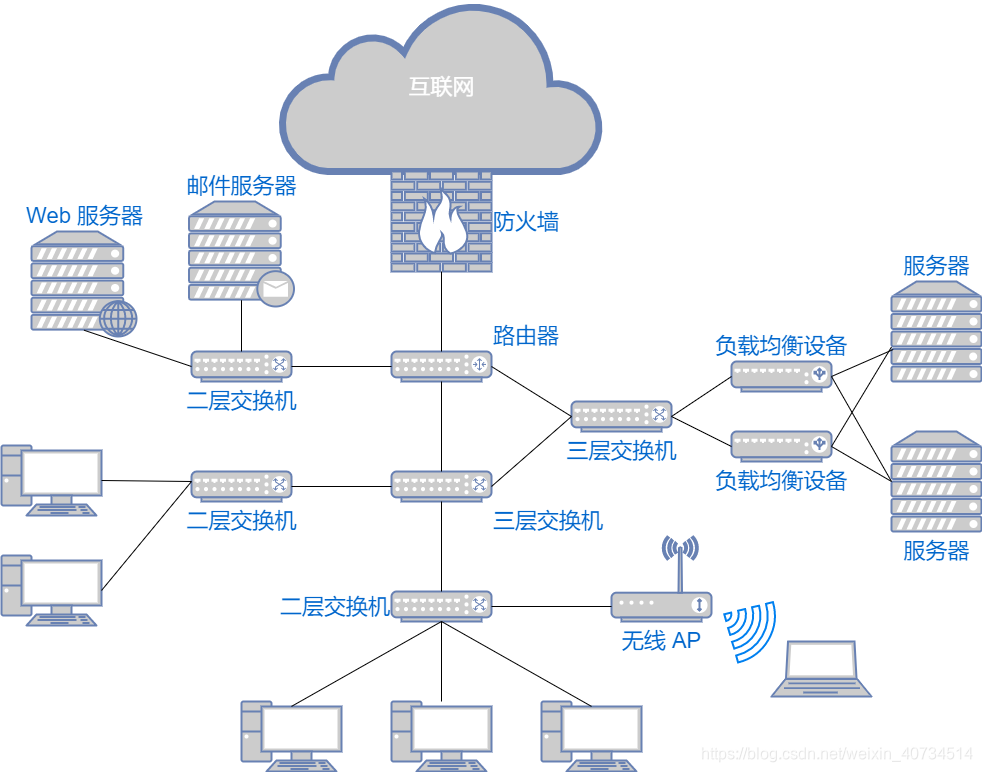
通信介质
主机可以通过有线线缆进行连接。有线线缆有双绞线、光纤、串口线等。根据网络接口选择对应的线缆。传输介质还可以被分为电波、微波等不同类型的电磁波。
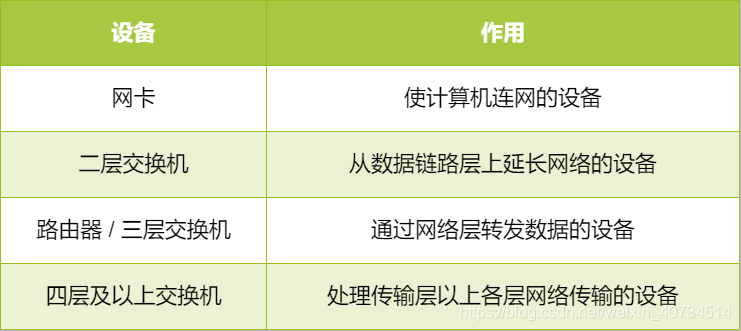
主机连接网络时,必须要使用网卡。可以是有线网卡,用来连接有线网络,也可以是无线网卡连接 WiFi 网络。每块网卡都有一个唯一的 MAC 地址,也叫做硬件地址或物理地址。
二层交换机: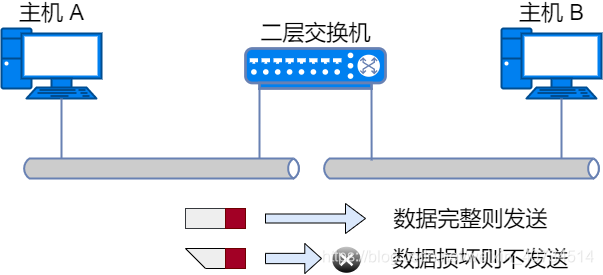
二层交换机位于 OSI 模型的第 2 层(数据链路层)。它能够识别数据链路层中的数据帧,并将帧转发给相连的另一个端口。
数据帧中有一个数据位叫做 FCS ,用以校验数据是否正确送达目的地。二层交换机通过检查这个值,将损坏的数据丢弃。
二层交换机根据 MAC 地址自学机制判断是否需要转发数据帧。这类功能也是数据链路层所具有的功能。
路由器 / 三层交换机: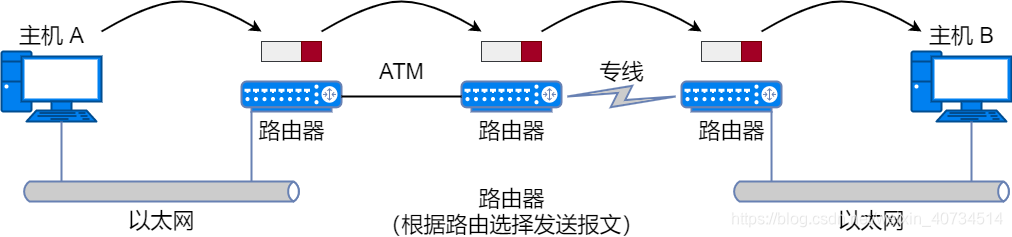
路由器是在 OSI 模型的第 3 层(网络层)上连接两个网络、并对报文进行转发的设备。二层交换机是根据 MAC 地址进行处理,而路由器 / 三层交换机则是根据 IP 地址进行处理的。因此 TCP/IP 中网络层的地址就成为了 IP 地址。
路由器可以连接不同的数据链路。比如连接两个以太网,或者连接一个以太网与一个无线网。家庭里面常见的无线路由器也是路由器的一种。
四层及以上交换机: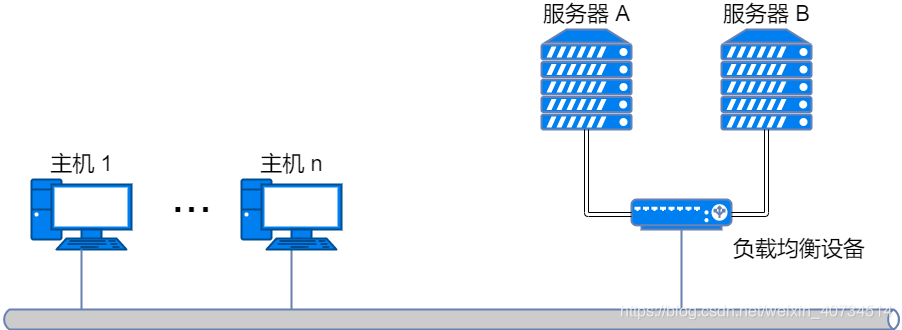
四层及以上交换机负责处理OSI模型中从传输层至应用层的数据。例如,下载和视频网站的服务器会用到的负载均衡设备,就是四层及以上交换机的一种。还有广域网加速器、防火墙等。
1.网络协议:
我们用手机连接上网的时候,会用到许多网络协议。从手机连接 WiFi 开始,使用的是 802.11 (即 WLAN )协议;
手机自动获取网络配置,使用的是 DHCP 协议。
这时手机已经连入局域网了,可以访问局域网内的主机和资源,但还不能使用互联网应用,例如:微信、抖音等。想要访问互联网,还需要在手机的上联网络设备上进行配置,即在无线路由器上配置 NAT、 PPPOE 等功能,才能把局域网接入到互联网中,手机就可以上网玩微信、刷抖音了。
局域网 :小范围内的私有网络,一个家庭内的网络、一个公司内的网络、一个校园内的网络都属于局域网。
广域网:把不同地域的局域网互相连接起来的网络。运营商搭建连接远距离区域的广域网。
互联网:由世界各地的局域网和广域网连接起来的网络。互联网是一个开放、互联的网络,不属于任何个人和任何机构。
简单来说,就是手机、无线路由器等设备通过网络协议实现通信。网络协议又是谁规定的呢?ISO 制定了一个 OSI 参考模型,被用于网络协议的制定。
2.OSI 参考模型:
OSI 参考模型将网络协议提供的服务分成== 7 层==,并定义每一层的服务内容,实现每一层服务的是协议,协议的具体内容是规范。上下层之间通过接口进行交互,同一层之间通过协议进行交互。OSI 参考模型只对各层的服务做了粗略的界定,并没有对协议进行详细的定义。但是许多协议都对应了 7 个分层的某一层。所以要了解网络,首先要了解OSI 参考模型。
3.应用层:
OSI参考模型的第 7 层(最高层)。应用程序和网络之间的接口,直接向用户提供服务。应用层协议有电子邮件、远程登录等协议。
4.表示层:
OSI参考模型的第 6 层。负责数据格式的互相转换,如编码、数据格式转换和加密解密等。保证一个系统应用层发出的信息可被另一系统的应用层读出。
5.会话层:
OSI参考模型的第 5 层。主要是管理和协调不同主机上各种进程之间的通信(对话),即负责建立、管理和终止应用程序之间的会话。
6.传输层:
OSI参考模型的第 4 层。为上层协议提供通信主机间的可靠和透明的数据传输服务,包括处理差错控制和流量控制等问题。
7.网络层:
OSI参考模型的第 3 层。将数据传输到目的地址,主要负责寻址和路由选择。
8.数据链路层:
OSI参考模型的第 2 层。负责两个相邻主机间的通信传输,即数据帧的生成与接收。
9.物理层:
OSI参考模型的第 1 层(最底层)。负责逻辑信号(比特流)与物理信号(电信号、光信号)之间的互相转换,利用传输介质为数据链路层提供物理连接。
10.TCP/IP 参考模型:
由于 OSI 参考模型把服务划得过于琐碎,先定义参考模型再定义协议,有点理想化。TCP/IP 模型则正好相反,通过已有的协议归纳总结出来的模型,成为实际的主流网络协议标准。
先介绍下 TCP/IP 与 OSI 分层之间的对应关系,以及 TCP/IP 每层的主要协议。
11.网络接入层:
在 TCP/IP 分层中,有把物理层和数据链路层合并称为网络接入层,有把物理层和数据链路层分别称为硬件、网络接口层。网络接入层是对网络介质的管理,定义如何使用网络来传送数据,但是对物理层和数据链路层在通信过程中起到了不一样的作用。所以 TCP/IP 分为四层或者五层都可以,只要能理解其中的原理就行。
12.网络层:
相当于 OSI 模型中的第 3 层网络层,使用的是IP协议,作用是将数据包从源地址发送到目的地址。
IP
IP 是跨越网络传送数据包, 使整个互联网都能收到数据的协议,它使用 IP 地址作为主机的标识。IP 协议独立于底层介质,
实现从源到目的的数据转发。
ICMP
用于在 IP 主机、路由器之间传递控制消息。被用来诊断网络的健康状况。
ARP
从数据包的 IP 地址中解析出 MAC 地址的一种协议。
13.传输层:
相当于 OSI 模型中的第 4 层传输层,主要功能就是让应用程序之间互相通信,通过端口号识别应用程序,使用的协议有面向连接的 TCP 协议和面向无连接的 UDP 协议。
TCP
TCP 是一种面向有连接的传输层协议,能够对自己提供的连接实施控制。适用于要求可靠传输的应用,例如文件传输。
UDP
UDP 是一种面向无连接的传输层协议,不会对自己提供的连接实施控制。适用于实时应用,例如:IP电话、视频会议、直播等。
14.应用层:
相当于 OSI 模型中的第 5 – 7 层的集合,不仅要实现 OSI 模型应用层的功能,还要实现会话层和表示层的功能。HTTP 、 POP3 、 TELNET 、 SSH 、 FTP 、 SNMP都是应用层协议。
HTTP
是 WWW 浏览器和服务器之间的应用层通信协议。HTTP 定义高级命令或者方法供浏览器用来与Web服务器通信。
POP3
TELNET
远程终端协议,用于远程管理网络设备。
SSH
安全外壳协议。通过使用SSH,可以把所有传输的数据进行加密。
SNMP
15.封装与解封装:
数据发送前,按照参考模型从上到下,在数据经过每一层时,添加协议头部信息,这个过程叫封装。
数据接收后,按照参考模型从下到上,在数据经过每一层时,去掉协议头部信息,这个过程叫解封装。
经过传输层协议封装后的数据称为段,经过网络层协议封装后的数据称为包,经过数据链路层协议封装后的数据称为帧,物理层传输的数据为比特。
16.实际数据传输举例:
实际生活中,互联网是使用的 TCP/IP 协议进行网络连接的。我们以访问网站为例,看看网络是如何进行通信的。
发送数据包
访问 HTTP 网站页面时,打开浏览器,输入网址,敲下回车键就开始进行 TCP/IP 通信了。
应用程序处理
首先,应用程序中会进行 HTML 格式编码处理,相当于 OSI 的表示层功能。编码转化后,不一定会马上发送出去,相当于会话层的功能。在请求发送的那一刻,建立 TCP 连接,然后在 TCP 连接上发送数据。接下来就是将数据发送给下一层的 TCP 进行处理。
TCP 模块处理
TCP 会将应用层发来的数据顺利的发送至目的地,实现可靠传输的功能,需要给数据封装 TCP 头部信息。TCP 头部信息包括源端口号和目的端口号(识别主机上应用)、序号(确认哪部分是数据)以及校验和(判断数据是否被损坏)。随后封装了 TCP 头部信息的段再发送给 IP 。
IP 模块处理
IP 将 TCP 传过来的数据段当做自己的数据,并封装 IP 头部信息。IP 头部信息中包含目的 IP 地址和源 IP 地址,以及上层协议类型信息。
网络接口处理
网络接口对传过来的 IP 包封装上以太网头部信息并进行发送处理。以太网头部信息包含目的 MAC 地址、源 MAC 地址,以及上层协议类型信息。然后将以太网数据帧通过物理层传输给接收端。
接收数据包
网络接口处理
收到以太网帧后,首先查看头部信息的目的 MAC 地址是否是发给自己的帧。如果不是发送给自己的帧就丢弃。如果是发送给自己的帧,查看上层协议类型是 IP 包,以太网帧解封装成 IP 包,传给 IP 模块进行处理。
IP 模块处理
收到 IP 包后,进行类似处理。根据头部信息的目的 IP 地址判断是否是发送给自己包,如果是发送给自己的包,则查看上一层的协议类型,并把 IP 包解封装发送给 TCP 协议处理。
TCP 模块处理
收到 TCP 段后,首先查看校验和,判断数据是否被破坏。然后检查是否按照序号接收数据。最后检查端口号,确定具体的应用程序。
数据接收完毕后,发送一个 “ 确认回执 ” 给发送端。
数据被完整接收后,会把 TCP 段解封装发送给由端口号识别的应用程序。
应用程序处理
应用程序收到数据后,通过解析数据知道了发送端请求的网页内容,然后按照 HTTP 协议进行后续数据交互。
17.网络构成:
搭建一套网络涉及各种线缆和网络设备。下面介绍一些常见的硬件设备。
通信介质
主机可以通过有线线缆进行连接。有线线缆有双绞线、光纤、串口线等。根据网络接口选择对应的线缆。传输介质还可以被分为电波、微波等不同类型的电磁波。
网卡
主机连接网络时,必须要使用网卡。可以是有线网卡,用来连接有线网络,也可以是无线网卡连接 WiFi 网络。每块网卡都有一个唯一的 MAC 地址,也叫做硬件地址或物理地址。
二层交换机:
二层交换机位于 OSI 模型的第 2 层(数据链路层)。它能够识别数据链路层中的数据帧,并将帧转发给相连的另一个端口。
数据帧中有一个数据位叫做 FCS ,用以校验数据是否正确送达目的地。二层交换机通过检查这个值,将损坏的数据丢弃。
二层交换机根据 MAC 地址自学机制判断是否需要转发数据帧。这类功能也是数据链路层所具有的功能。
路由器 / 三层交换机:
路由器是在 OSI 模型的第 3 层(网络层)上连接两个网络、并对报文进行转发的设备。二层交换机是根据 MAC 地址进行处理,而路由器 / 三层交换机则是根据 IP 地址进行处理的。因此 TCP/IP 中网络层的地址就成为了 IP 地址。
路由器可以连接不同的数据链路。比如连接两个以太网,或者连接一个以太网与一个无线网。家庭里面常见的无线路由器也是路由器的一种。
四层及以上交换机:
四层及以上交换机负责处理OSI模型中从传输层至应用层的数据。例如,下载和视频网站的服务器会用到的负载均衡设备,就是四层及以上交换机的一种。还有广域网加速器、防火墙等。
原文地址:https://blog.csdn.net/m0_59073956/article/details/128857967
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_24730.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!