认识Redis
Redis是一种NoSQL数据库,以键值对形式存储数据,支持多种数据结构,包括字符串、哈希、列表、集合、有序集合等,使其适用于多种应用场景。由于所有数据都存储在内存中,Redis的读写性能非常高。同时,Redis可以通过快照和日志将内存中的数据保存到硬盘,以防数据丢失。此外,Redis还提供了键过期、发布订阅、事务等附加功能,像一把瑞士军刀,能在合适的场景下发挥巨大的作用。
Redis最初被设计为一个“消息中间件“,用于实现分布式系统下的生产者消费者模型。然而,现在直接将Redis用作消息中间件的情况较少,因为业界有许多更专业的消息中间件可以选择。
Redis的作用就像在内存中定义变量一样,用于存储数据。然而,Redis的真正优势在于分布式系统中才能充分发挥。对于单机程序来说,直接使用变量存储数据可能是更优的选择,因为它们可以避免网络通信带来的开销。
然而,在分布式系统中,由于进程间的隔离性,不同进程之间的数据无法直接共享。这时候,我们就需要通过网络进行进程间通信。Redis就是基于这种网络通信的,它可以使一个进程的内存中的变量被其他进程,甚至其他主机上的进程使用,从而在分布式系统中发挥重要作用。
MySQL的主要问题在于其访问速度相对较慢,这在很多高性能要求的互联网产品中可能成为瓶颈。另一方面,Redis作为基于内存的数据结构服务器,其访问速度明显快于MySQL,因此在需要高速数据处理的场景中,Redis是一个很好的选择。
然而,相比于MySQL,Redis的最大劣势在于其存储空间有限。尽管在性能要求较高的互联网产品中,这可能不是一个大问题,但对于许多对性能要求不那么高,而对存储空间有较大需求的互联网产品来说,这可能是一个问题。
因此,一个典型的解决方案是将Redis和MySQL结合使用,这是遵循了”二八原则“,即20%的热点数据可以满足80%的访问需求。这样可以有效地利用Redis的高速访问性能,同时利用MySQL的大存储空间。
然而,这种方案也将使系统的复杂程度大大提升。特别是当数据发生修改时,还需要解决Redis和MySQL之间的数据同步问题,这可能会带来额外的开发和维护成本。
Redis特性
Redis 之所以受到如此多公司的青睐,必然有之过人之处,下面是关于Redis的8个重要特性。
1.速度快
正常情况下,Redis执行命令的速度非常快,官方给出的数字是读写性能可以达到10万/秒,当然这也取决于机器的性能,但这里先不讨论机器性能上的差异,只分析一下是什么造就了Redis如此之快,可以大概归纳为以下四点:
几乎所有的编程语言都提供了类似字典的功能,例如C++里的map、Java里的map、Python里的dict等,类似于这种组织数据的方式叫做基于键值对的方式,与很多键值对数据库不同的是,Redis中的值不仅可以是字符串,而且还可以是具体的数据结构,这样不仅能便于在许多应用场景的开发,同时也能提高开发效率。Redis的全程是REmote Dictionary Server,它主要提供了5种数据结构:字符串(string)、哈希(hash)、列表(list)、集合(set)、有序集合(ordered set/zet),同时在字符串的基础之上演变出了位图(Bitmaps)和HyperLogLog两种神奇的”数据结构“,并且随着LBS (Location Based Service,基于位置服务)的不断发展,Redis 3.2.版本种加入有关GEO(地理信息定位)的功能,总之在这些数据结构的帮助下,开发者可以开发出各种“有意思”的应用。
3.丰富的功能
除了5种数据结构,Redis还提供了许多额外的功能:提供了键过期功能,可以用来实现缓存。
- 提供了发布订阅功能,可以用来实现消息系统。
- 支持Lua脚本功能,可以利用Lua创造出新的Redis命令。·提供了简单的事务功能,能在一定程度上保证事务特性。
- 提供了流水线(Pipeline)功能,这样客户端能将一批命令一次性传到Redis,减少了网络的开销。
4.简单稳定
Redis的简单主要表现在三个方面。首先,Redis的源码很少,早期版本的代码只有2万行左右,3.0版本以后由于添加了集群特性,代码增至5万行左右,相对于很多NoSQL数据库来说代码量相对要少很多,也就意味着普通的开发和运维人员完全可以“吃透”它。其次,Redis使用单线程模型,这样不仅使得Redis服务端处理模型变得简单,而且也使得客户端开发变得简单。最后,Redis 不需要依赖于操作系统中的类库(例如Memcache需要依赖libevent这样的系统类库) ,Redis自己实现了事件处理的相关功能。
但与简单相对的是Redis具备相当的稳定性,在大量使用过程中,很少出现因为Redis自身BUG而导致宕掉的情况。
Redis提供了简单的TCP通信协议,很多编程语言可以很方便地接入到Redis,并且由于Redis受到社区和各大公司的广泛认可,所以支持 Redis的客户端语言也非常多,几乎涵盖了主流的编程语言,例如C、C++、Java、PHP、Python、NodeJS等,后续我们会对Redis的客户端使用做详细说明。
通常看,将数据放在内存中是不安全的,一旦发生断电或者机器故障,重要的数据可能就会丢失,因此Redis提供了两种持久化方式:RDB和AOF,即可以用两种策略将内存的数据保存到硬盘中,这样就保证了数据的可持久性,后续我们将对Redis的持久化进行详细说明。
Redis提供了复制功能,实现了多个相同数据的Redis副本(Replica),复制功能是分布式Redis的基础。
8.高可用(High Availability)和分布式(Distributed)
Redis提供了高可用实现的Redis哨兵(Redis Sentinel),能够保证Redis结点的故障发现和故障自动转移。也提供了Redis集群(Redis Cluster),是真正的分布式实现,提供了高可用、读写和容量的扩展性。
Redis使用场景
Redis可以做什么?
缓存机制几乎在所有大型网站都有使用,合理地使用缓存不仅可以加速数据的访问速度,而且能够有效地降低后端数据源的压力。Redis提供了键值过期时间设置,并且也提供了灵活控制最大内存和内存溢出后的淘汰策略。可以这么说,一个合理的缓存设计能够为一个网站的稳定保驾护航。
排行榜系统几乎存在于所有的网站,例如按照热度排名的排行榜,按照发布时间的排行榜,按照各种复杂维度计算出的排行榜,Redis 提供了列表和有序集合的结构,合理地使用这些数据结构可以很方便地构建各种排行榜系统。
3.计数器应用
计数器在网站中的作用至关重要,例如视频网站有播放数、电商网站有浏览数,为了保证数据的实时性,每一次播放和浏览都要做加1的操作,如果并发量很大对于传统关系型数据的性能是一种挑战。Redis天然支持计数功能而且计数的性能也非常好,可以说是计数器系统的重要选择。
4.社交网络
赞、踩、粉丝、共同好友/喜好、推送、下拉刷新等是社交网站的必备功能,由于社交网站访问量通常比较大,而且传统的关系型数据不太合适保存这种类型的数据,Redis 提供的数据结构可以相对比较容易地实现这些功能。
5.消息队列系统
消息队列系统可以说是一个大型网站的必备基础组件,因为其具有业务解耦、非实时业务削峰等特性。Redis 提供了发布订阅功能和阻塞队列的功能,虽然和专业的消息队列比还不够足够强大,但是对于一般的消息队列功能基本可以满足。
Redis 不可以做什么?
实际上和任何一门技术一样,每个技术都有自己的应用场景和边界,也就是说Redis并不是万金油,有很多合适它解决的问题,但是也有很多不合适它解决的问题。我们可以站在数据规模和数据冷热的角度来进行分析。
站在数据规模的角度看,数据可以分为大规模数据和小规模数据,我们知道Redis的数据是存放在内存中的,虽然现在内存已经足够便宜,但是如果数据量非常大,例如每天有几亿的用户行为数据,使用Redis来存储的话,基本上是个无底洞,经济成本相当高。
站在数据冷热的角度,数据分为热数据和冷数据,热数据通常是指需要频繁操作的数据,反之为冷数据,例如对于视频网站来说,视频基本信息基本上在各个业务线都是经常要操作的数据,而用户的观看记录不一定是经常需要访问的数据,这里暂且不讨论两者数据规模的差异,单纯站在数据冷热的角度上看,视频信息属于热数据,用户观看记录属于冷数据。如果将这些冷数据放在Redis上,基本上是对于内存的一种浪费,但是对于一些热数据可以放在Redis中加速读写,也可以减轻后端存储的负载,可以说是事半功倍。
分布式
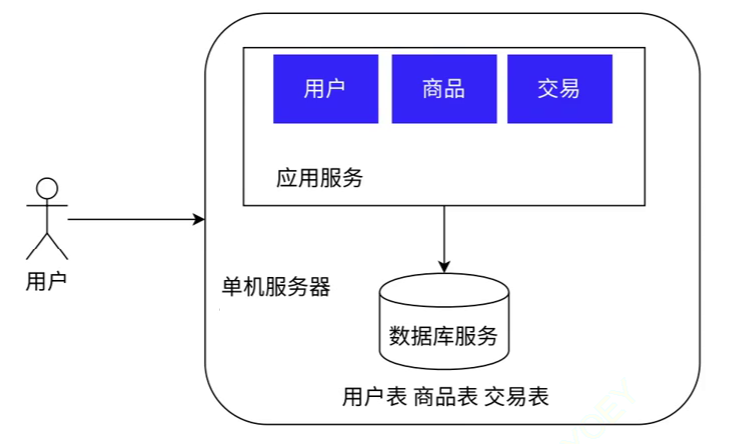
单机架构
单机架构, 如其名字所示,是一种在一台服务器上运行所有应用程序和服务的架构。在这种架构中,应用程序、数据库、前端和后端服务等都运行在同一台机器上,不涉及分布式系统或者服务之间的网络通信。
以下是单机架构的一些主要特点:
-
简单:由于所有的服务和应用程序都运行在同一台机器上,开发和维护都相对简单。不需要考虑分布式系统中的数据一致性,网络延迟,分布式事务等复杂问题。
-
扩展性:单机架构的扩展性较差,当应用程序的负载增加时,可能需要通过增加机器的硬件资源(CPU、内存等)来提升性能,而这种方式的扩展性有限。
单机架构常用于一些小型应用程序或者系统,例如个人网站,小型企业应用等。当应用的访问量和数据量不大,或者初期开发和测试阶段,单机架构是一个简单有效的选择。
引入分布式
在单机架构中,理论上是可以让应用服务器既处理业务逻辑,又负责数据存储的。然而,这在实际操作中可能会相对复杂,因为这就意味着我们需要在一个服务器上处理所有的任务。
实际上,单机架构是被广大企业广泛采用的。随着现代计算机硬件的飞速发展,即便是一台服务器,其处理能力也足够强大,可以支持高并发和大数据量的存储。
但是,当业务进一步增长,用户量和数据量激增时,一台服务器可能难以应对。这时,我们需要增加更多的服务器,加入更多的硬件资源。因为一台服务器的硬件资源总是有上限,每次处理请求都会消耗一定的资源。
如果在同一时间处理的请求过多,可能会导致某些硬件资源不足,这可能会延长服务器处理请求的时间,甚至导致处理出错。遇到这种情况,我们可以选择增加硬件资源,这是一种直接而有效的方法。另一种方法是进行性能优化,找出瓶颈并进行针对性的改进。但这需要相当高的技术水平。
然而,单台服务器的硬件资源增加总是有限的,受主板扩展能力的限制。当一台服务器已经扩展到极限,但仍无法满足需求时,就需要引入多台服务器,此时,我们需要在软件层面进行相应的调整和适配。
一旦引入多台服务器,我们的系统就进入了”分布式系统“的领域。分布式系统的引入会大大提高系统的复杂性,增加bug出现的概率,因此需要我们更加细心和专业的技术来处理。
数据库分离
应用服务和数据库服务分离
在设计系统架构时,将应用服务和数据库服务进行分离是一种常见且高效的方法。这种设计方式主要基于两个服务的特性和需求。
应用服务器,其主要职责是处理业务逻辑,这往往会消耗大量的CPU和内存资源。而数据库服务器的主要职责是进行数据存储和访问,因此需要更大的硬盘空间以及更快的数据读写速度。
通过将这两个服务分离,我们可以根据各自的需求来优化和配置服务器。例如,对于数据库服务器,我们可以选择配置更大的硬盘空间,甚至可以使用SSD硬盘以提高数据访问速度。
这样的设计不仅可以让各个服务更加专注于其主要职责,提高系统的整体性能,同时也可以提高投入资源的性价比。因此,应用服务和数据库服务的分离是一种值得推广的系统架构设计方法。

负载均衡
负载均衡是一种核心技术,用于高流量、大规模系统的管理和优化。其主要目标是优化系统的性能,防止任何单点故障,并保证系统的高可用性。
你可以将负载均衡器理解为一个团队的领导,负责将任务合理分配给各个成员,以保证整个团队的工作效率。在我们的场景中,这些成员就是应用服务器节点。
应用服务器往往会消耗大量的CPU和内存资源,因此当流量过大或者业务请求过重时,单个应用服务器可能会不堪重负。为了解决这个问题,我们可以引入更多的应用服务器节点。
用户的请求首先达到负载均衡器或网关服务器(这通常是一个单独的服务器)。假设有一万个用户请求,有两个应用服务器。此时,负载均衡器就会以某种策略(如轮询、最少连接等)将这些请求平均分配给这两个应用服务器,如此,每个应用服务器就只需要处理五千个请求,从而有效地分散了单个服务器的压力,提高了系统的处理能力。
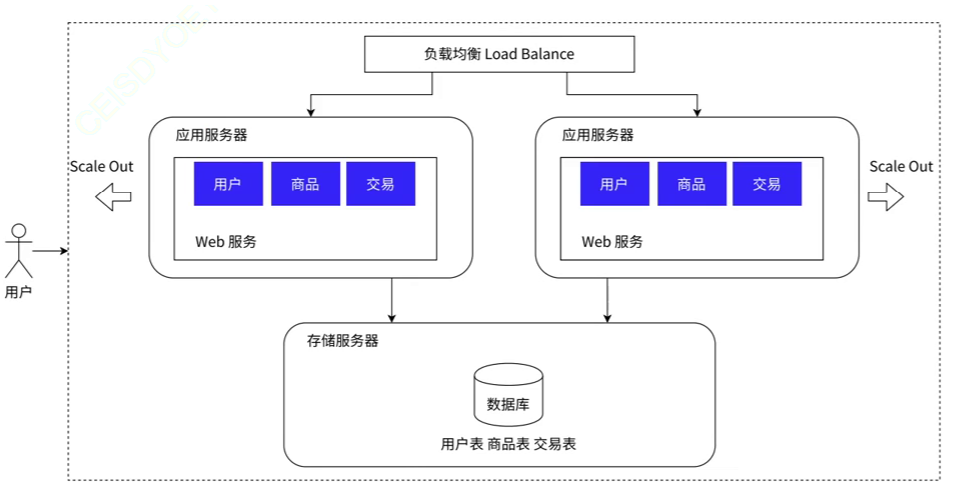
负载均衡器,看起来不是承担了所有的请求嘛?这个东西能顶住嘛??
负载均衡器的主要角色是接收并分配用户请求到各个应用服务器,因此,它确实需要处理大量的请求。然而,负载均衡器的设计和优化使其具有远超应用服务器的请求处理能力。你可以将其视为团队的领导,主导着工作的分配,而应用服务器则是执行任务的组员。
然而,即使负载均衡器的处理能力很强,也并非无懈可击。在极端情况下,如请求量过大,负载均衡器也可能会出现无法承受的情况。对于这种情况,我们可以采取的策略是引入更多的负载均衡器,甚至在多个机房部署负载均衡器,以增强系统的处理能力和容错性。
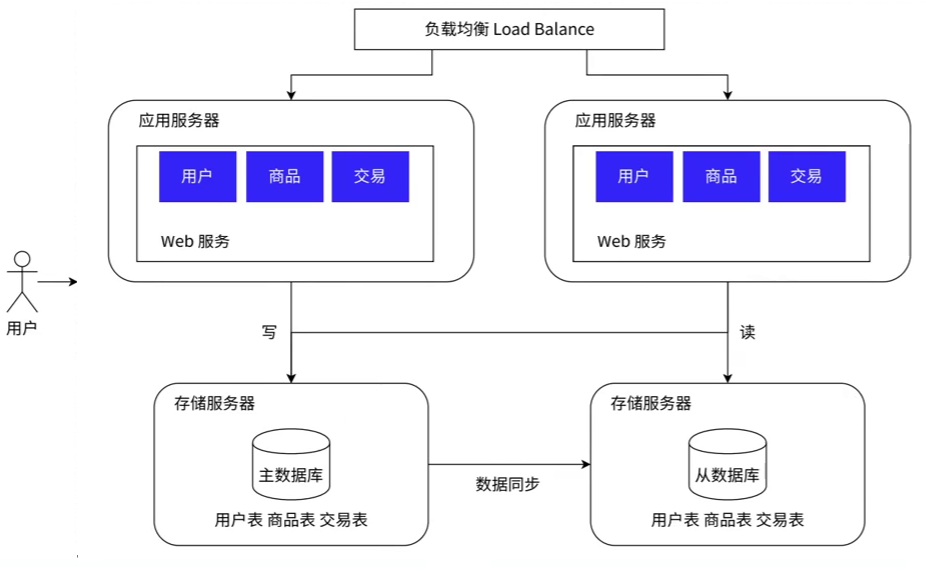
数据库读写分离
增加应用服务器,确实能够处理更高的请求量。但是随之存储服务器,要承担的请求量也就更多了!如何解决呢?开源+节流的方式门槛太高,也更复杂。使用数据库读写分离。
数据库读写分离是一种常用的数据库优化策略,主要用于处理大量的并发读写请求。具体来说,它将数据库的读操作和写操作分离到不同的服务器上进行,进而提高了数据库系统的性能和并发处理能力。
读写分离的主要思想是:将对数据库的读和写操作分别处理,读操作在读库(Slave)上进行,写操作在写库(Master)上进行。读库一般会有多个,写库通常只有一个。写库会定期将数据同步到读库,来保证数据的一致性。在实际的应用场景中,读的频率要比写的要高出许多!
此策略的主要优点是可以显著提高数据库系统的处理能力,因为读操作和写操作通常有不同的性能特点和资源需求。读操作通常可以缓存并高效地并行处理,而写操作则需要更多的磁盘I/O和数据一致性保证。
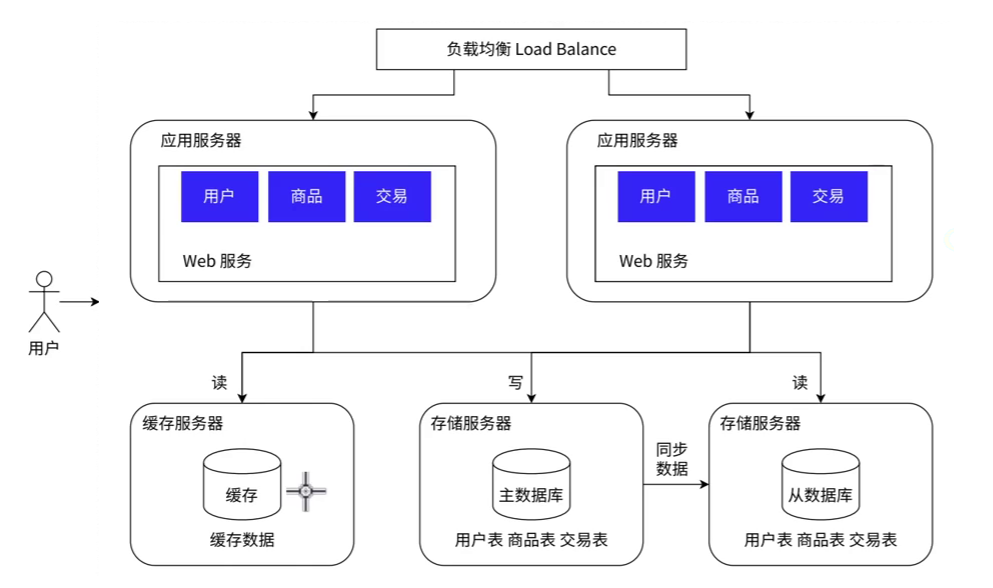
引入缓存
数据库天然有个问题,响应速度是很慢的!把数据区分”冷热”,热点数据放到缓存中,缓存的访问速度往往比数据库要快很多了!
数据的”冷热”区分是一种常见的策略。我们将频繁访问的”热点“数据放入缓存中,如Redis,这样可以大大提高数据访问的速度。这种策略的效果往往非常显著,根据二八原则,即使只缓存了20%的数据,也能够支持80%的访问量。在一些极端情况下,缓存的比例甚至可以达到一九。
而传统的数据库服务器,如MySQL,仍然存储全量的完整数据。缓存并不是用来替代数据库的,而是用来辅助数据库,以减轻其负担并提高整体性能。
然而,这种优化策略也是有代价的。为了保持高速的访问性能,缓存的大小通常会受到限制,也就是说,我们不能将所有数据都存储在缓存中。因此,我们需要有一套有效的策略,来确定哪些数据应该被缓存,以及如何更新和管理这些缓存数据。这是实施缓存策略时需要考虑的关键问题。
数据库分库分表
随着数据量的增长和并发请求的提高,单台服务器可能无法满足需求,这时候就需要引入分布式系统。
分布式系统不仅能处理更高的并发请求,也可以应对更大的数据量。有时候,数据量可能大到一台服务器存不下,即使一个服务器的存储量可以达到几十个TB,对于像短视频这种大数据量的应用来说,也可能会出现存储不足的情况。
这就需要采取分库分表的策略。原本一个数据库服务器上有多个逻辑数据库,现在可以引入多个数据库服务器,每个数据库服务器存储一个或者一部分数据库。如果某个表的数据量特别大,大到一台主机存不下,那么我们也可以针对表进行拆分。
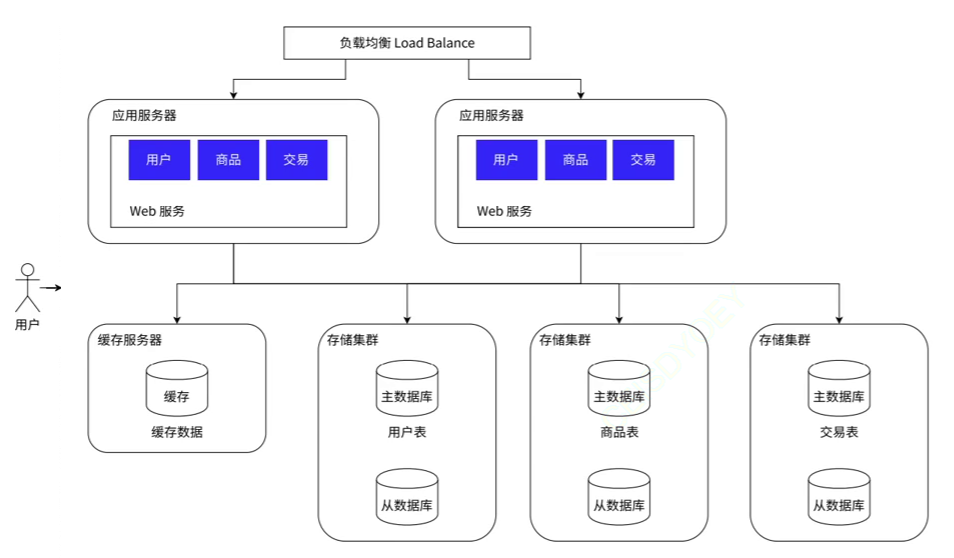
微服务
随着业务逻辑的增长,单个应用服务器的代码可能会变得越来越复杂,这不仅会带来维护和更新的困难,也可能降低系统的稳定性和可扩展性。
为了解决这些问题,我们可以采用微服务架构,将一个复杂的服务器拆分成多个功能更为单一、更小的服务器。这样,每个微服务都可以独立开发、部署和扩展,使得系统的复杂性得以管理,同时也能提高系统的可扩展性和稳定性。
值得注意的是,微服务架构的引入,本质上是为了解决”人”的问题。在小公司,由于开发团队人数较少,可能不需要采用微服务架构。但是在大公司,由于开发人员多,业务复杂,如果不进行合理的组织和分工,可能会导致管理和协调的困难。
此时,微服务架构可以作为一种有效的组织和管理工具。我们可以根据业务功能,将系统拆分成多个微服务,每个微服务由一个小团队负责。这样,每个团队可以专注于自己负责的微服务,降低了协调的复杂性,提高了开发效率。
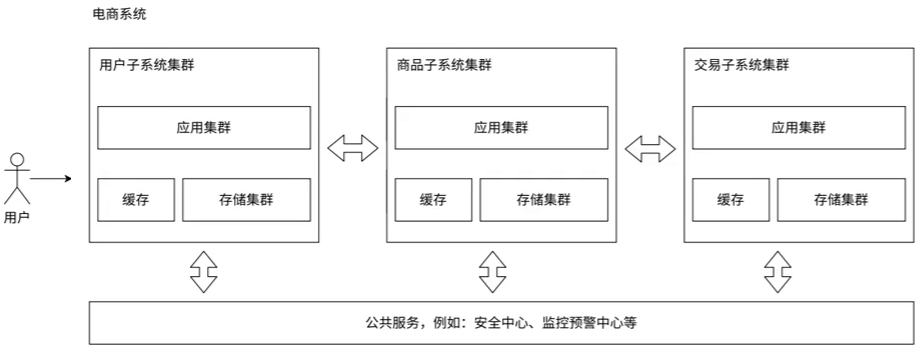
虽然微服务架构能够带来许多优势,如解决大型团队的协调问题,提高系统的可扩展性,但是同时,它也带来了一些挑战和代价:
- 系统性能下降:由于微服务涉及到更多的网络通信,这可能会导致系统的性能下降。网络通信的速度通常低于硬盘读写的速度,这就要求我们需要投入更多的硬件资源来保证性能不下降太多,比如使用速度更快的万兆网卡。然而,这会增加系统运行成本。
- 系统复杂度增加:微服务架构使得系统的复杂度提高。原本单一的系统被拆分为多个独立的服务,这意味着需要进行更多的协调和管理。此外,因为服务器数量增多,错误和故障的概率也会相应增大。
- 可用性受影响:微服务架构可能会对系统的可用性造成影响。由于服务器数量增多,一个服务的故障可能会影响到整个系统。为了保证系统的可用性,我们需要采用更丰富的监控和报警手段,同时需要配备专业的运维人员进行维护。
环境搭建
Ubuntu
1.更新系统包索引
首先,打开一个终端窗口并运行以下命令,以确保Ubuntu系统的包索引是最新的:
sudo apt update
sudo apt install build-essential tcl
3.下载Redis源码
接下来,前往Redis官网(https://redis.io/download)查找最新版本的Redis源码包,使用wget或curl命令下载。例如:
wget http://download.redis.io/releases/redis-7.0.0.tar.gz
tar xzf redis-7.0.0.tar.gz
cd redis-7.0.0
5.编译Redis
在Redis源代码目录中,编译Redis:
make
sudo make install
7.配置Redis
Redis的源码包中包含了一个默认的配置文件。你可以将这个配置文件复制到合适的位置,并根据需要对其进行调整:
sudo mkdir /etc/redis
sudo cp redis.conf /etc/redis
sudo nano /etc/redis/redis.conf
bind 0.0.0.0
protected-mode no
daemonize yes
8.创建Redis systemd单元文件
为了让Redis作为服务运行,需要创建一个systemd单元文件。在/etc/systemd/system/目录下创建一个名为redis.service的文件:
sudo nano /etc/systemd/system/redis.service
[Unit]
Description=Redis In-Memory Data Store
After=network.target
[Service]
User=redis
Group=redis
ExecStart=/usr/local/bin/redis-server /etc/redis/redis.conf
ExecStop=/usr/local/bin/redis-cli shutdown
Restart=always
[Install]
WantedBy=multi-user.target
sudo systemctl enable redis
sudo systemctl start redis
10.验证Redis服务状态
检查Redis服务的状态以确保它正在运行:
sudo systemctl status redis
redis-cli
Centos 7
1.更新系统包索引
sudo yum update
2.安装编译工具
为了从源代码编译Redis,需要安装编译工具(如果还没有安装的话):
sudo yum install -y gcc tcl
3.下载Redis源代码
需要从Redis官网下载最新稳定版的源代码。
wget http://download.redis.io/releases/redis-7.0.0.tar.gz
tar xzf redis-7.0.0.tar.gz
然后进入解压后的目录:
cd redis-7.0.0
5.编译Redis
编译Redis源代码:
make
sudo make install
7.创建Redis用户和配置文件
为Redis创建一个非root用户:
sudo useradd -r -s /sbin/nologin redis
sudo mkdir /etc/redis
sudo mkdir /var/lib/redis
sudo chown redis:redis /var/lib/redis
sudo chmod 770 /var/lib/redis
sudo cp redis.conf /etc/redis
sudo nano /etc/redis/redis.conf
- 设置IP地址
bind 0.0.0.0
protected-mode no
daemonize yes
8.创建Redis服务文件
为了使Redis作为服务运行,创建一个systemd服务文件:
sudo nano /etc/systemd/system/redis.service
[Unit]
Description=Redis In-Memory Data Store
After=network.target
[Service]
User=redis
Group=redis
ExecStart=/usr/local/bin/redis-server /etc/redis/redis.conf
ExecStop=/usr/local/bin/redis-cli shutdown
Restart=always
[Install]
WantedBy=multi-user.target
9.启动Redis服务
使Redis服务启动,并设置开机自启:
sudo systemctl start redis
sudo systemctl enable redis
sudo systemctl status redis
redis-cli
原文地址:https://blog.csdn.net/ikun66666/article/details/134696879
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_25874.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!






