Solr是基于ApacheLucene构建的流行、快速、开源的企业搜索平台
Solr具有高度可靠性、可扩展性和容错性,提供分布式索引、复制和负载平衡查询、自动故障切换和恢复、集中配置等功能。Solr为许多世界上最大的互联网站点提供搜索和导航功能
java8
solr8.11.2
笔者使用 centos7,已经安装Java环境,java 版本是 java8,solr 版本是8.11.2
1、solr 安装
1.1、linux solr 安装
1.1.1、下载 solr 安装包
solr官网:https://solr.apache.org/
solr下载地址:https://solr.apache.org/downloads.html
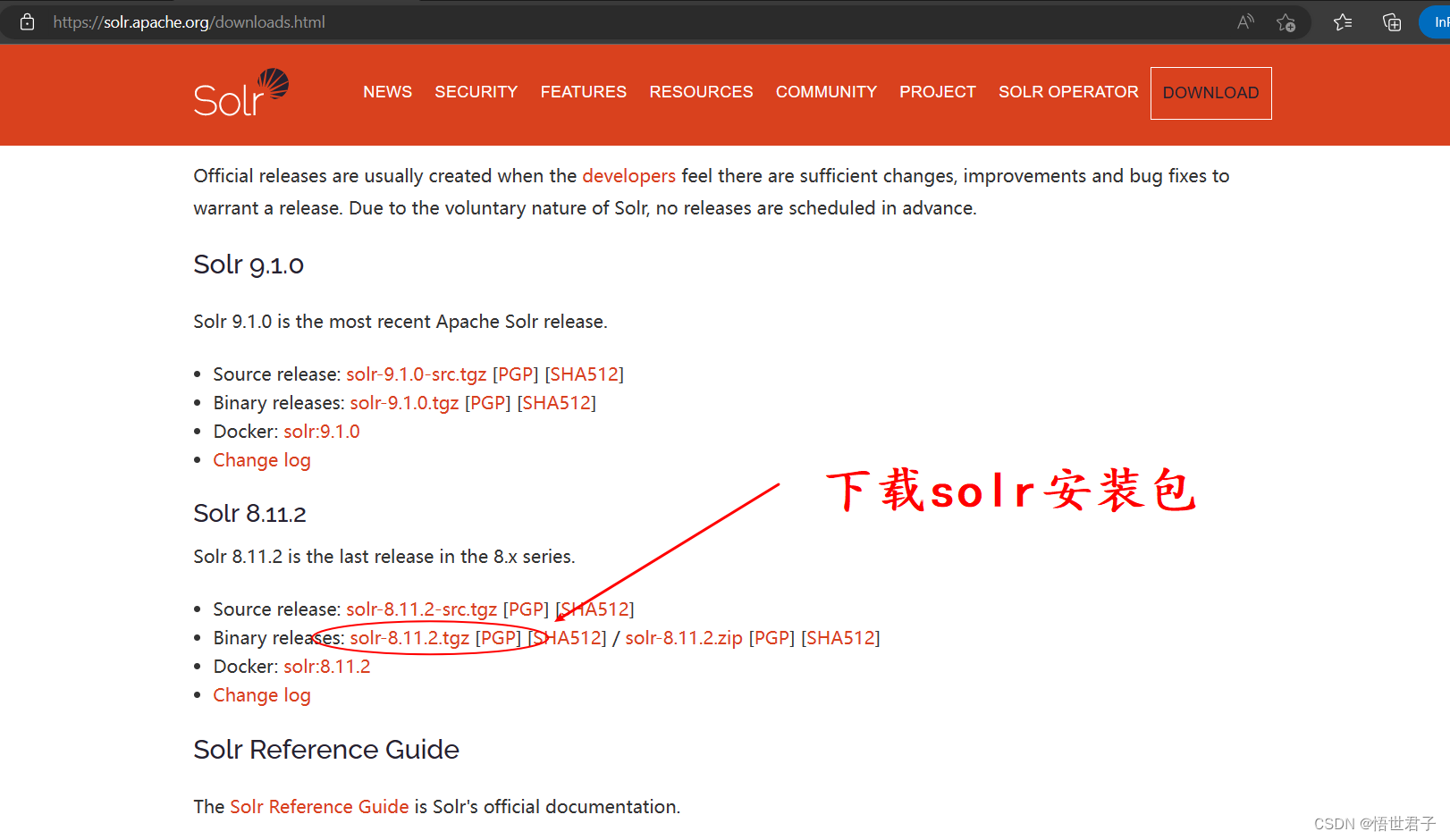
下载完成


mkdir -p /usr/local/solrtar -zxf solr-8.11.2.tgz -C /usr/local/solrcd /usr/local/solr/solr-8.11.2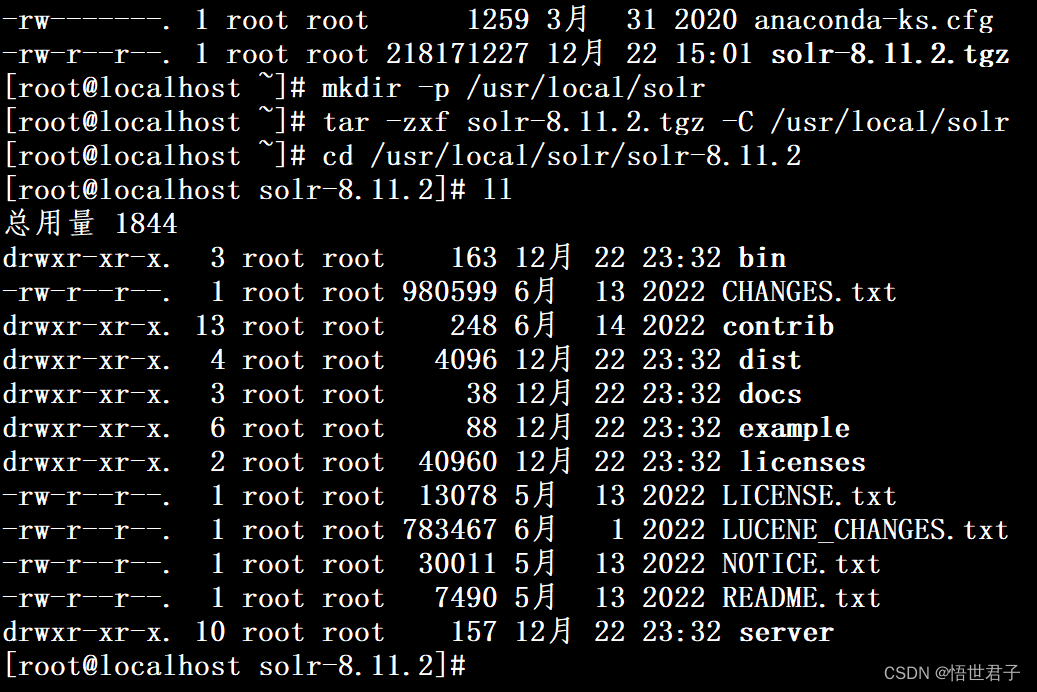
1.1.2、启动 solr
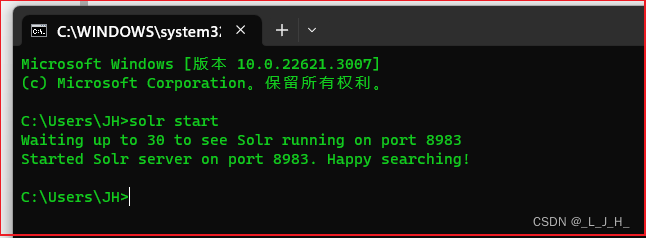
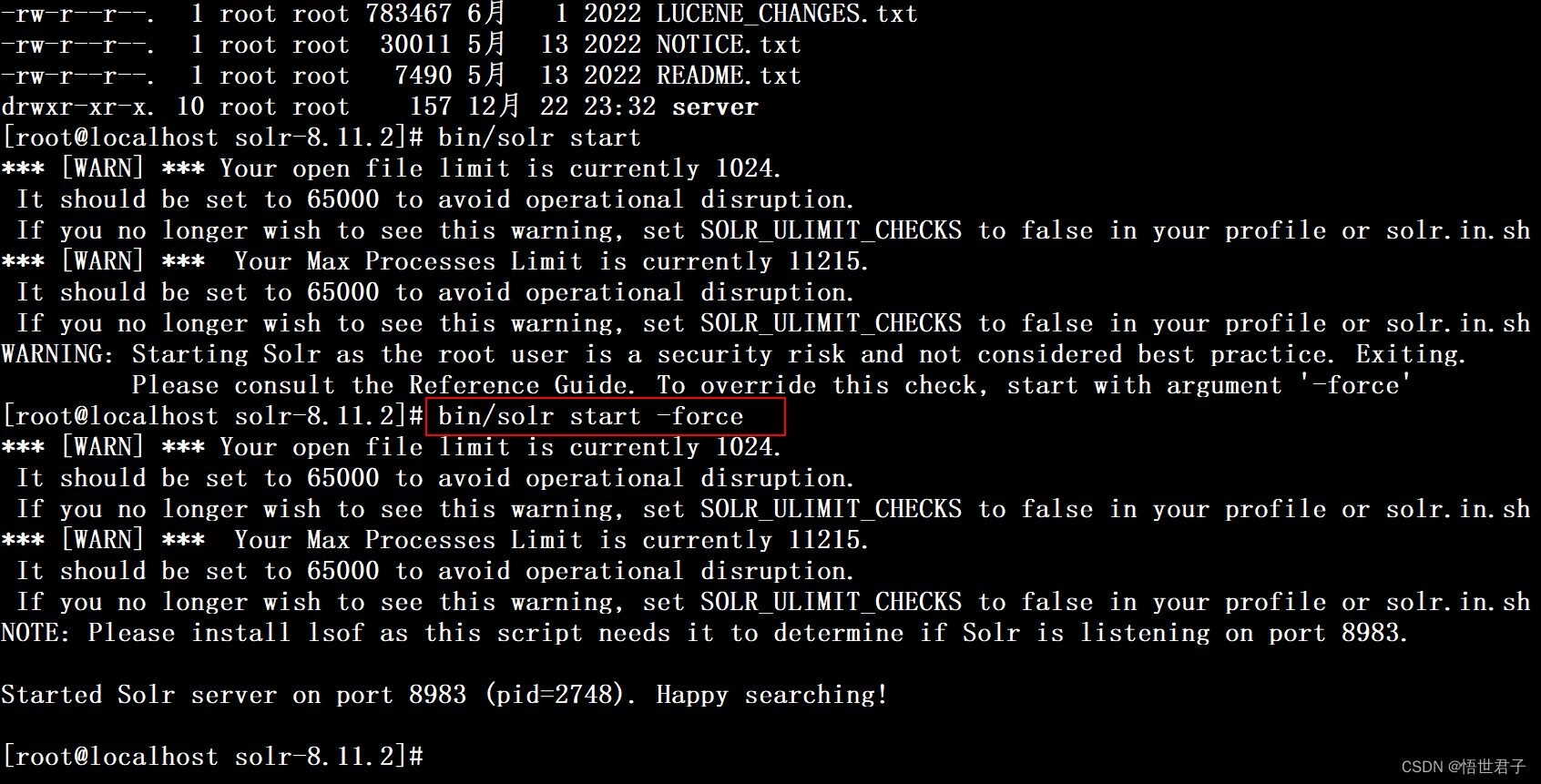
bin/solr start如果执行命令 bin/solr start 启动报错启动不起来,执行下面命令
bin/solr start -force笔者执行 bin/solr start –force 命令启动
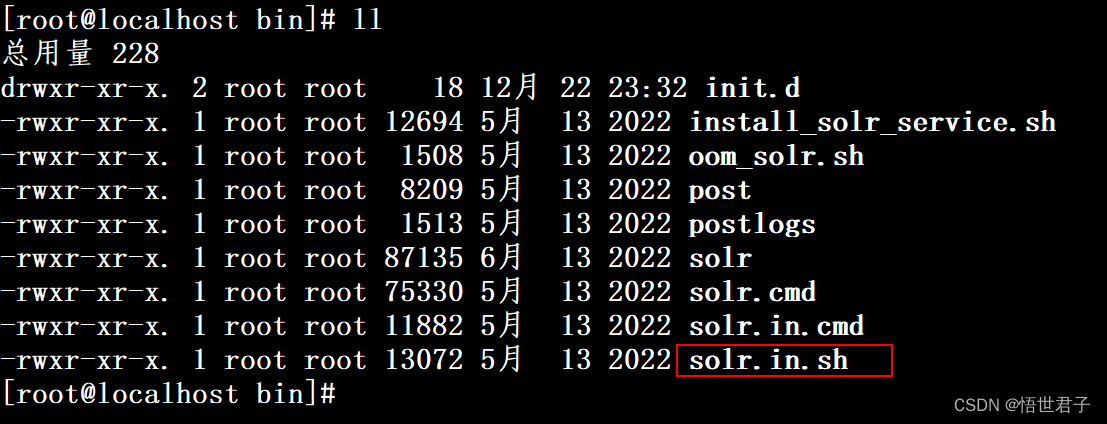
如果想要去除启动时的警告日志,可以将bin目录下 solr.in.sh 文件的 SOLR_ULIMIT_CHECKS 设置成 false
SOLR_ULIMIT_CHECKS=false 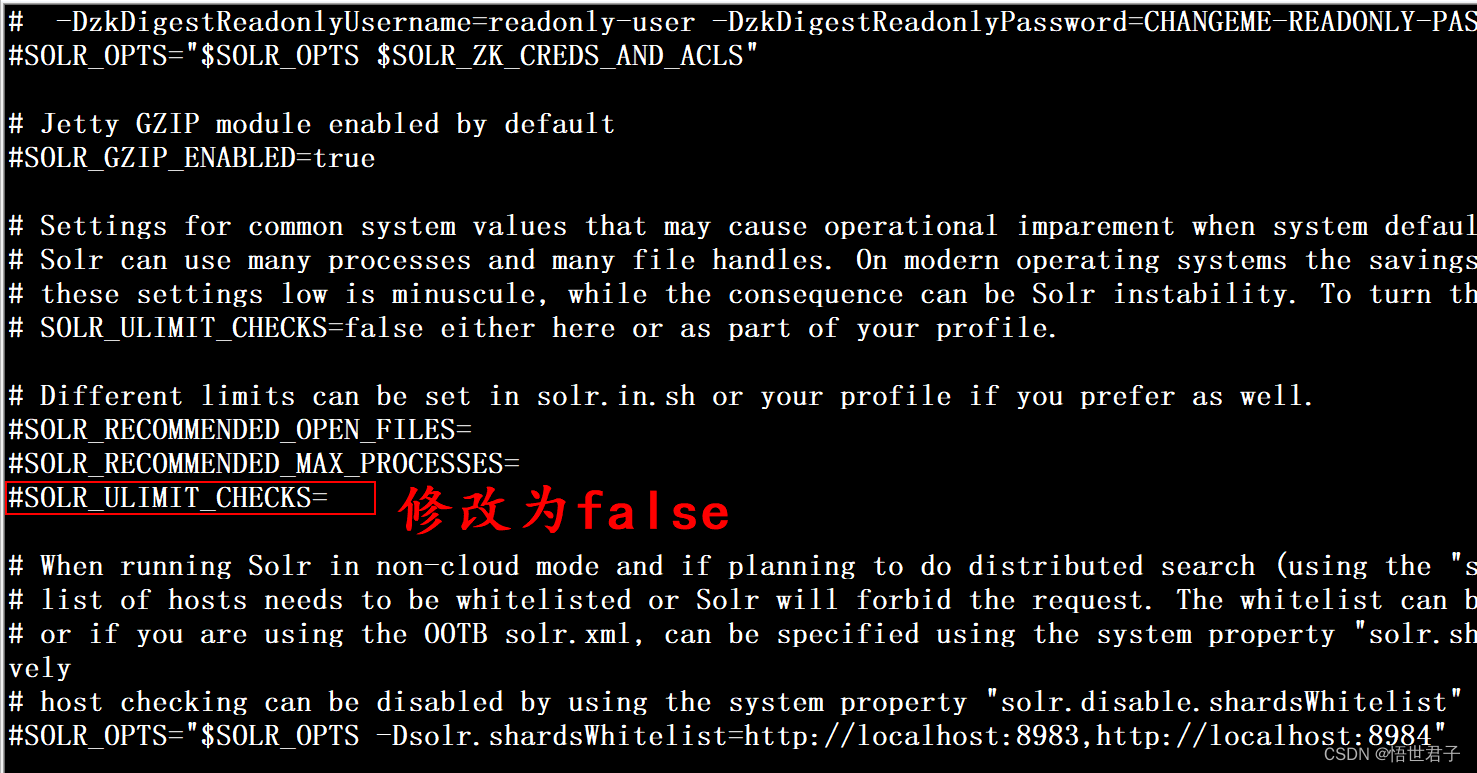

笔者这里没有修改 SOLR_ULIMIT_CHECKS 配置
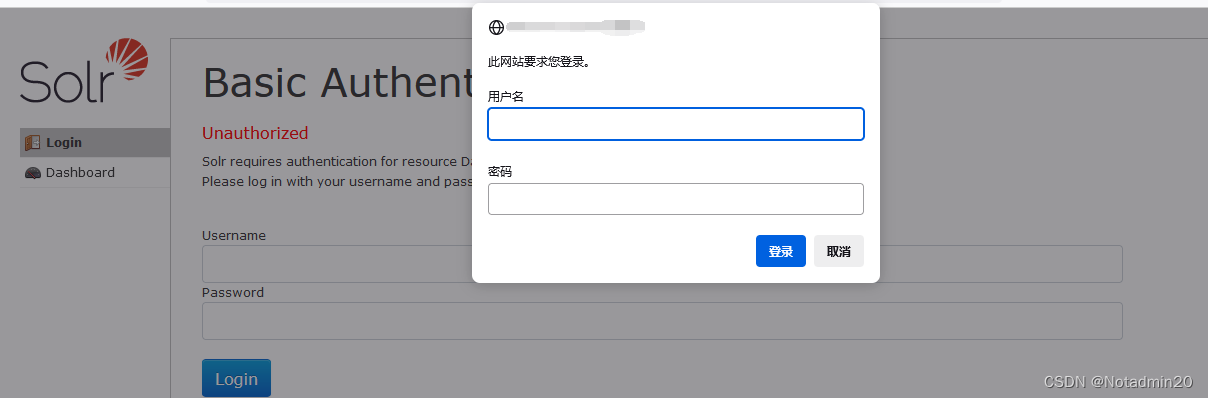
1.1.3、Admin Web管理页面
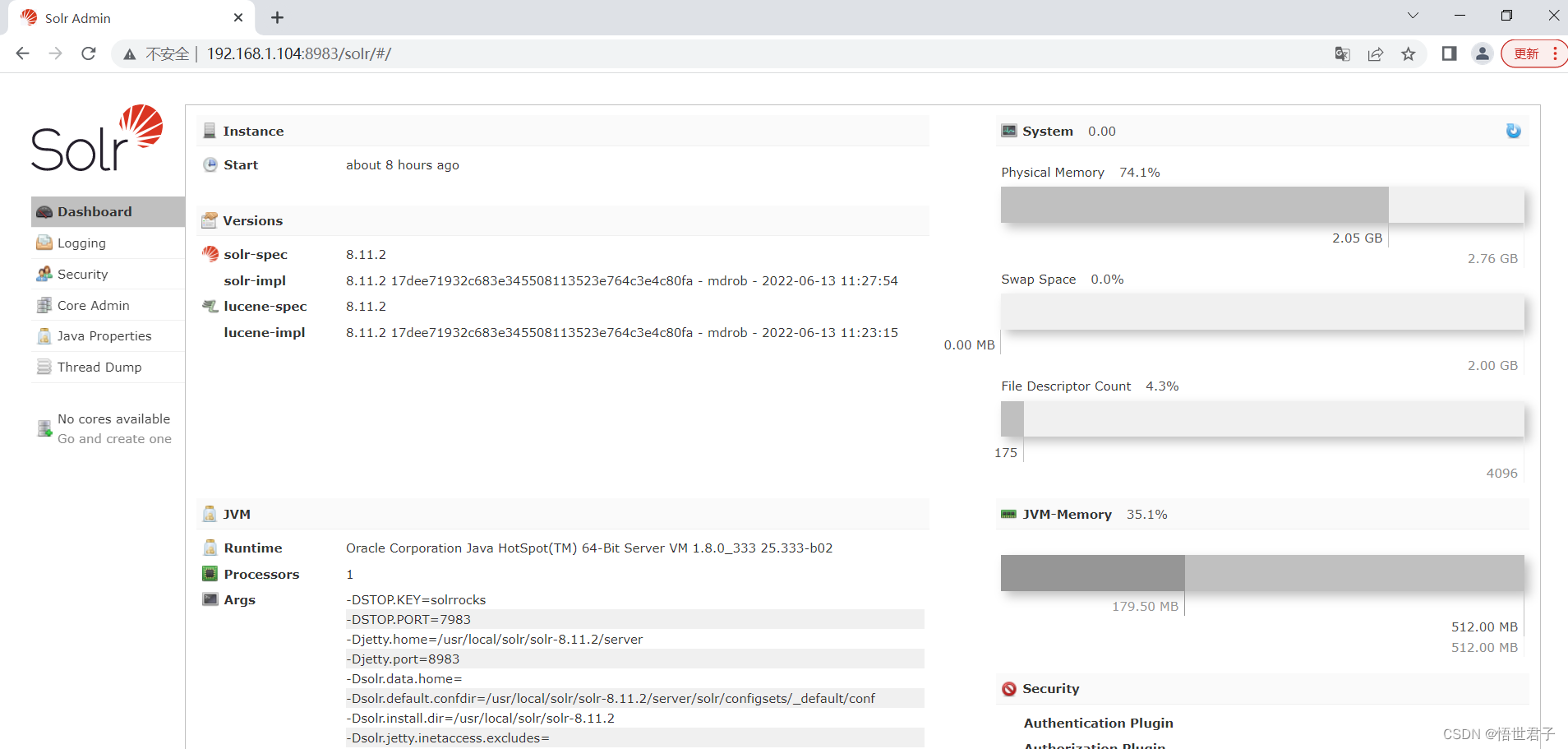
solr 启动后,浏览器访问Linux ip地址+端口号8983,访问 Admin Web管理页面
firewall-cmd --zone=public --add-port=8983/tcp --permanentfirewall-cmd --reload笔者ip地址是192.168.1.104,笔者访问地址 http://192.168.1.104:8983/solr
1.1.4、创建 solr 实例
bin/solr create -c solr_book如果上面命令创建不成功,执行命令 bin/solr create –c solr_book –force
bin/solr create -c solr_book -force
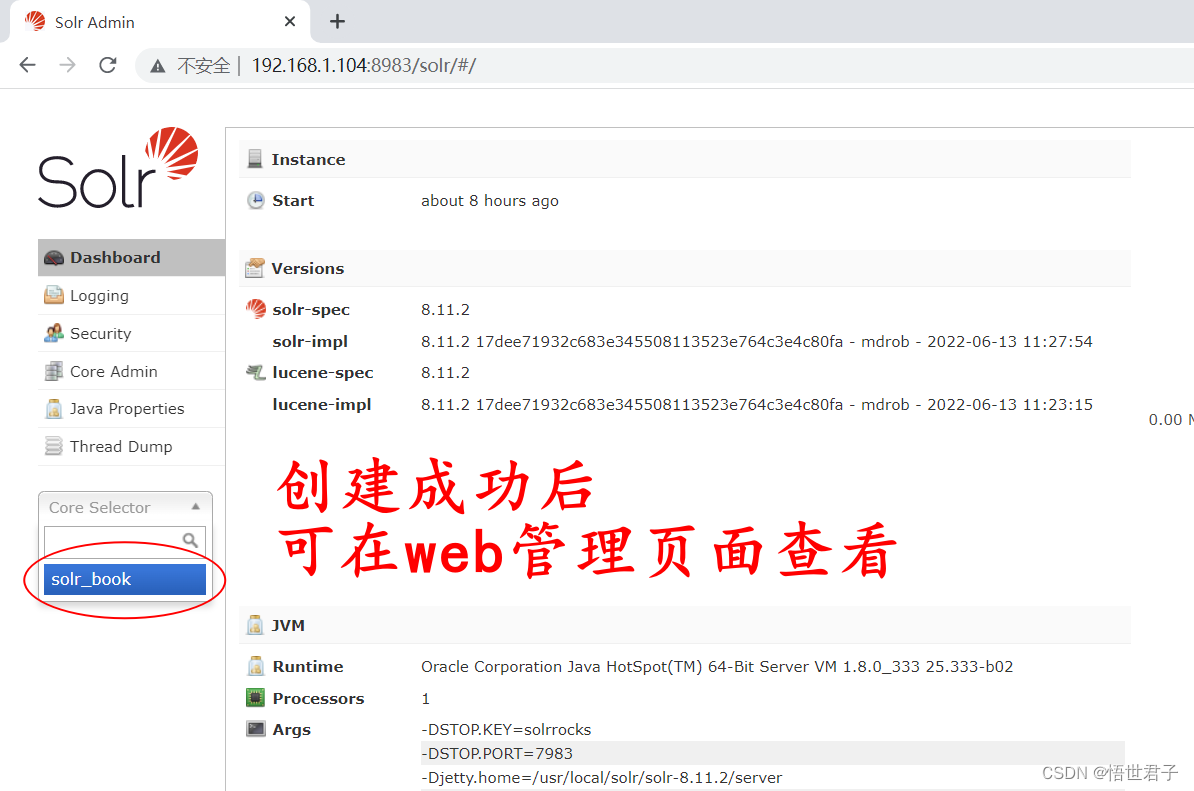
1.1.5、关闭 solr
bin/solr stop -all
1.1.6、添加中文分词
solr 默认没有中文分词,中文分词需要手动添加,这里使用 ik–analyzer-8.5.0.jar
ik–analyzer GitHub 地址:https://github.com/magese/ik-analyzer-solr
将 ik–analyzer-8.5.0.jar 上传到 Linux

将 ik–analyzer-8.5.0.jar 移动到 /usr/local/solr/solr-8.11.2/server/solr-webapp/webapp/WEB-INF/lib 目录
mv /root/ik-analyzer-8.5.0.jar /usr/local/solr/solr-8.11.2/server/solr-webapp/webapp/WEB-INF/lib进入 /usr/local/solr/solr-8.11.2/server/solr-webapp/webapp/WEB-INF/lib 目录
cd /usr/local/solr/solr-8.11.2/server/solr-webapp/webapp/WEB-INF/lib查看 ik–analyzer-8.5.0.jar 是否移动成功
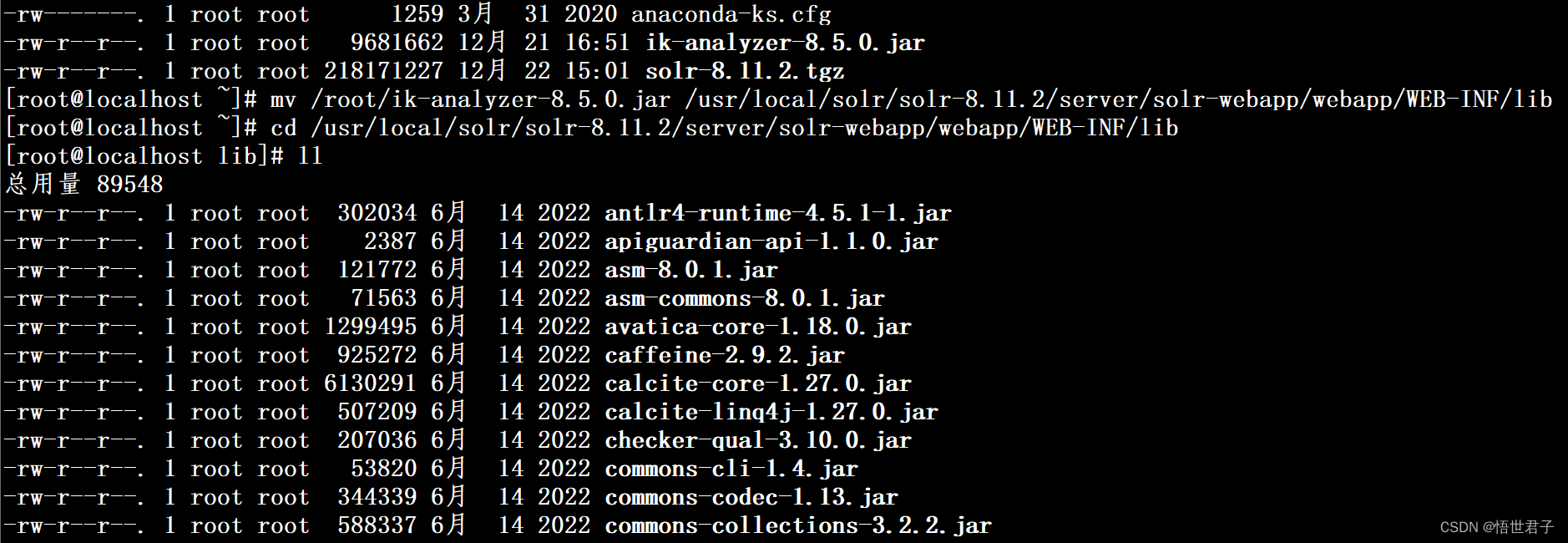

移动成功
cd /usr/local/solr/solr-8.11.2/server/solr
cd solr_book/conf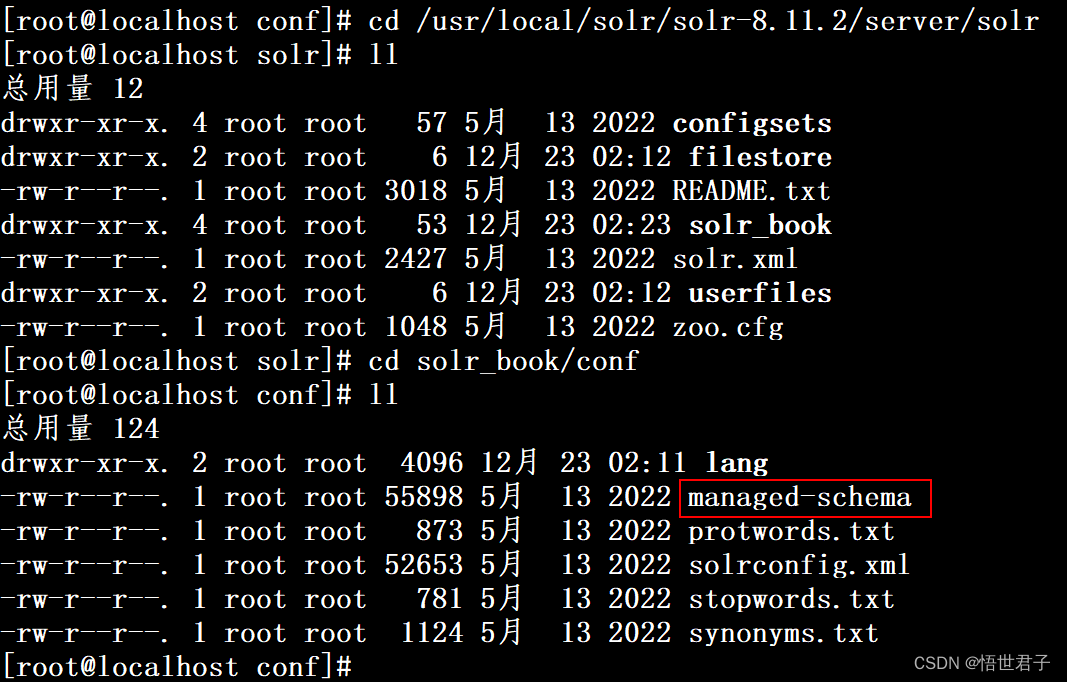
编辑 managed-schema ,或者将 managed-schema 下载下来添加配置再上传回去
vi managed-schema<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>笔者是将 managed-schema下载下来后编辑,再上传上去
SFTP下载命令
get /usr/local/solr/solr-8.11.2/server/solr/solr_book/conf/managed-schema
将修改后的 managed-schema 移动到原来目录的位置
mv /root/managed-schema /usr/local/solr/solr-8.11.2/server/solr/solr_book/conf/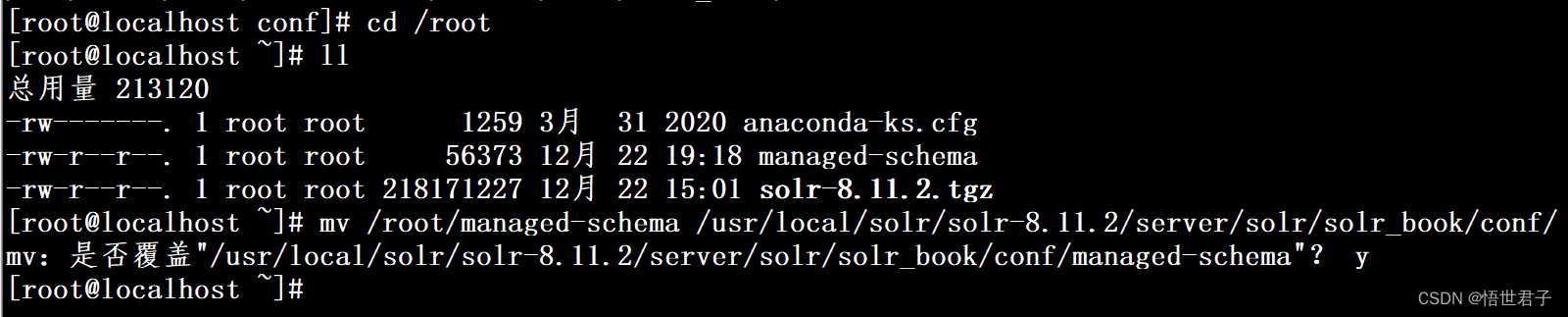

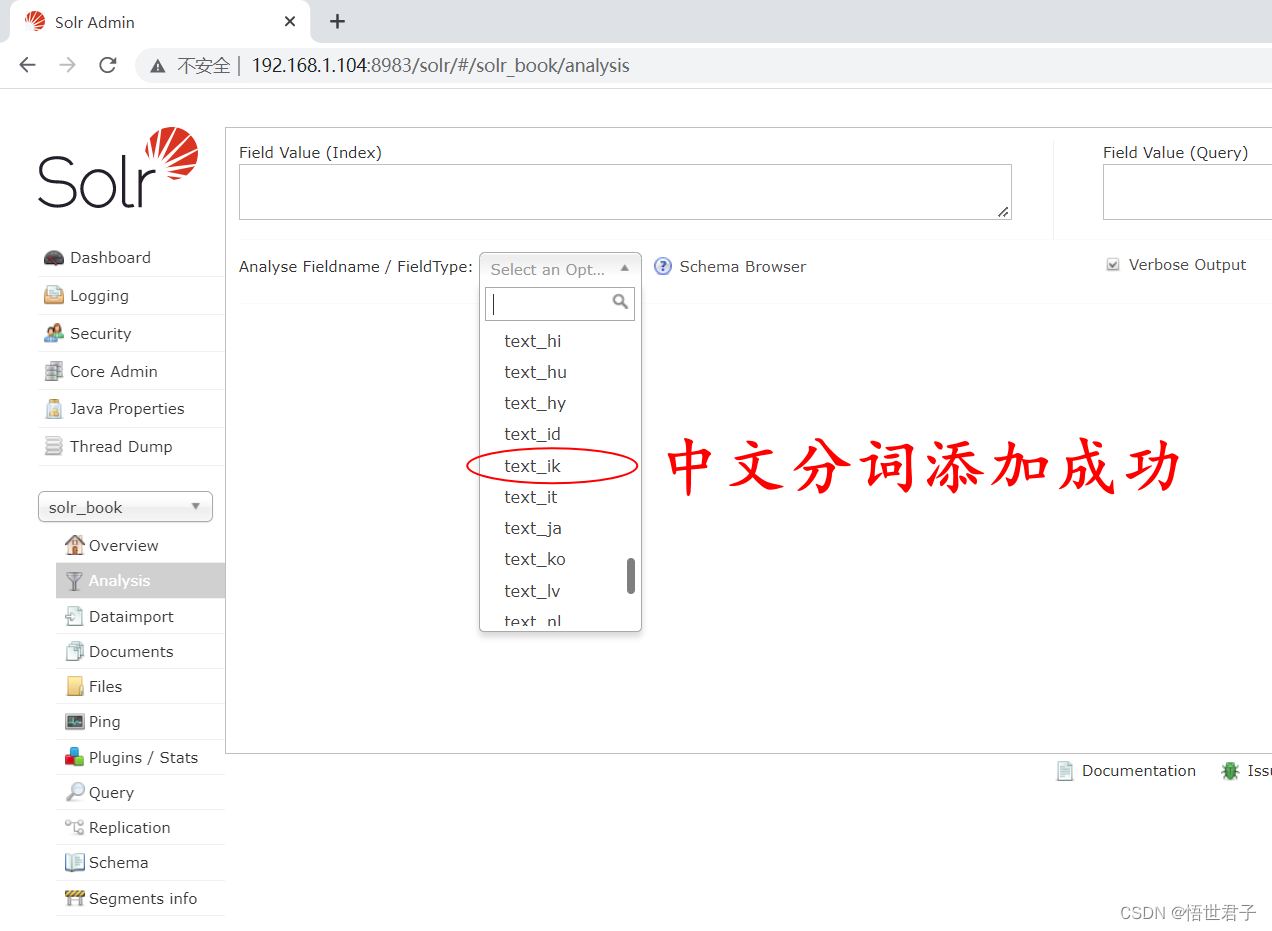
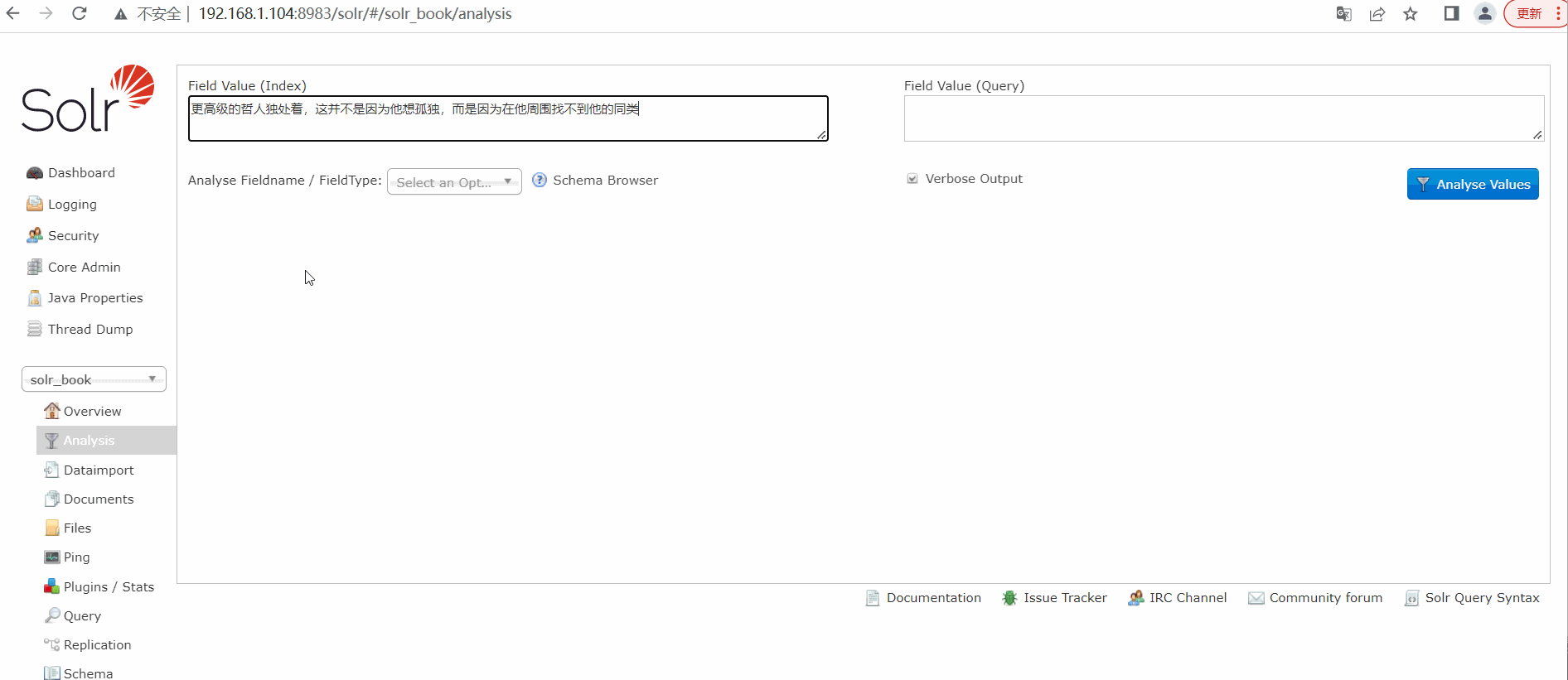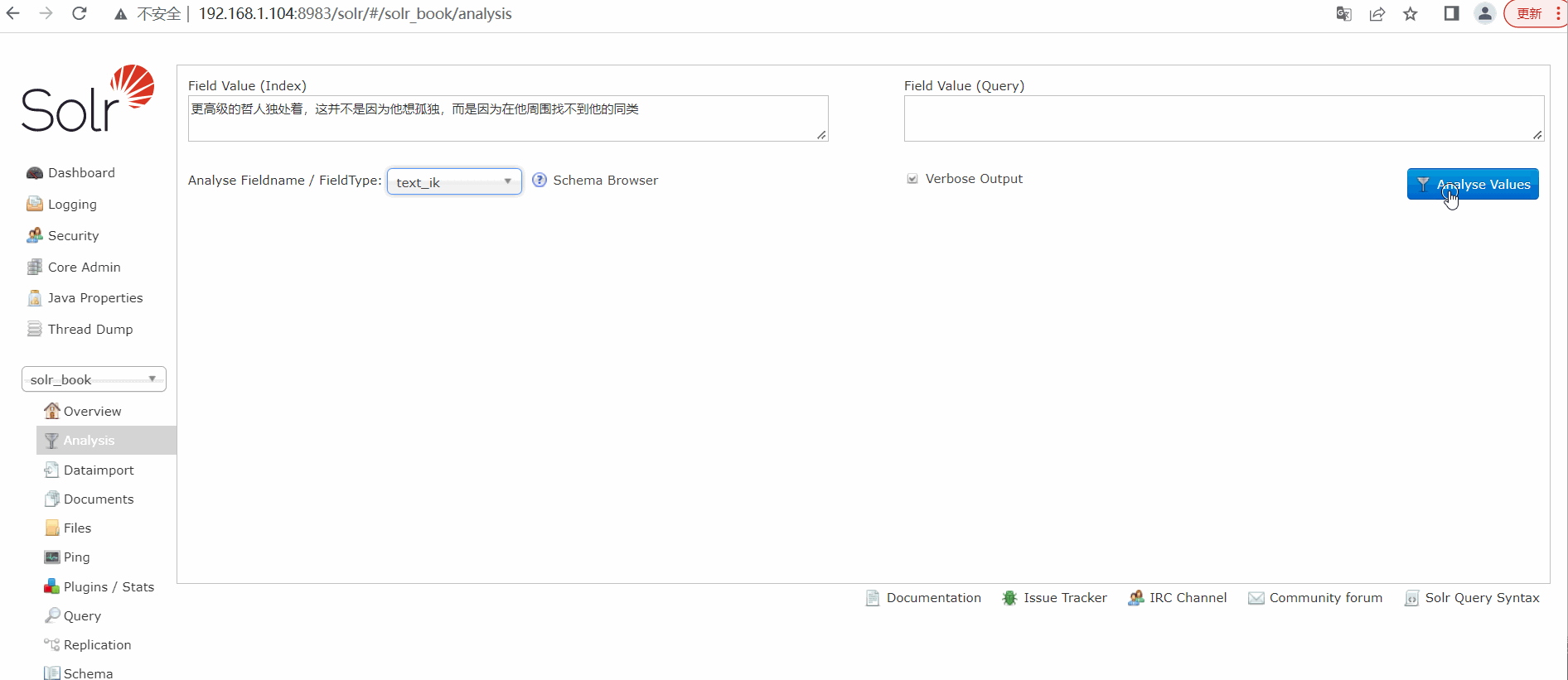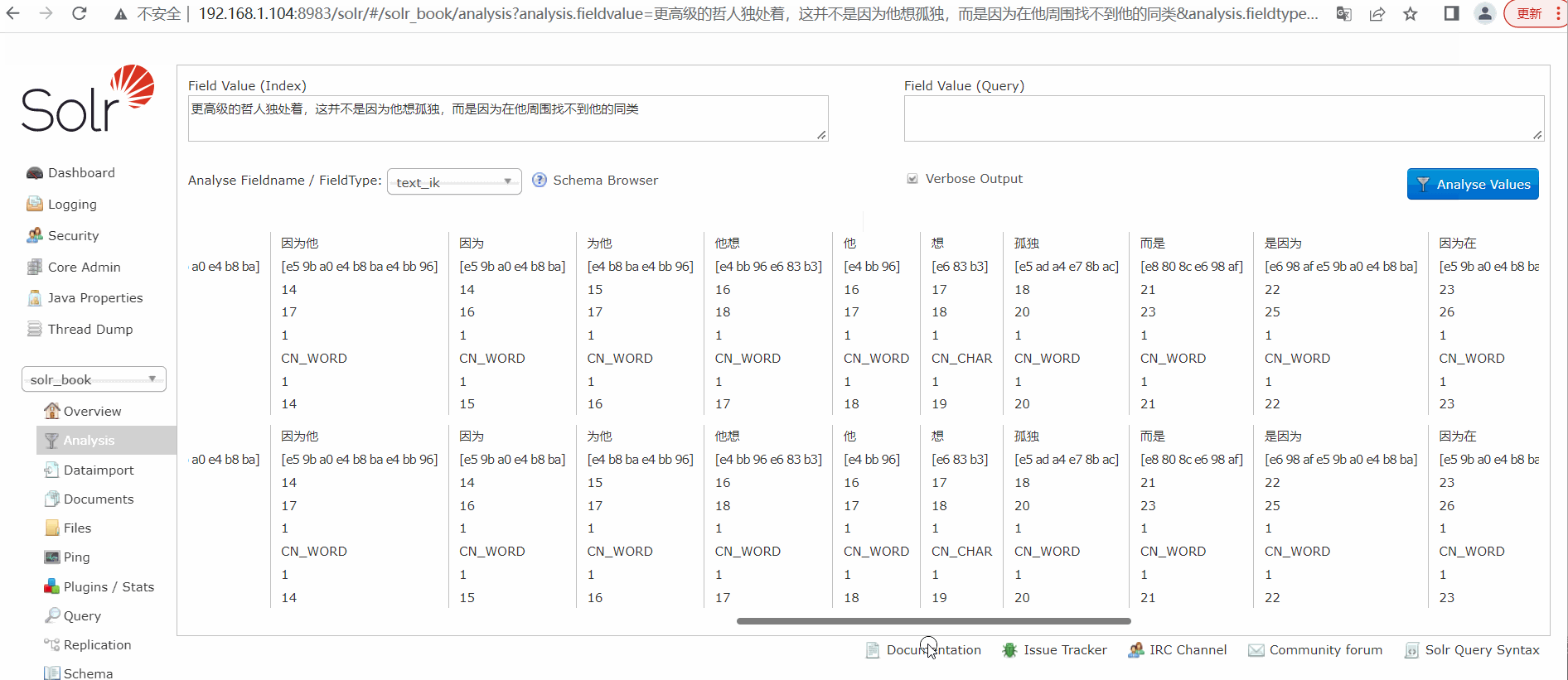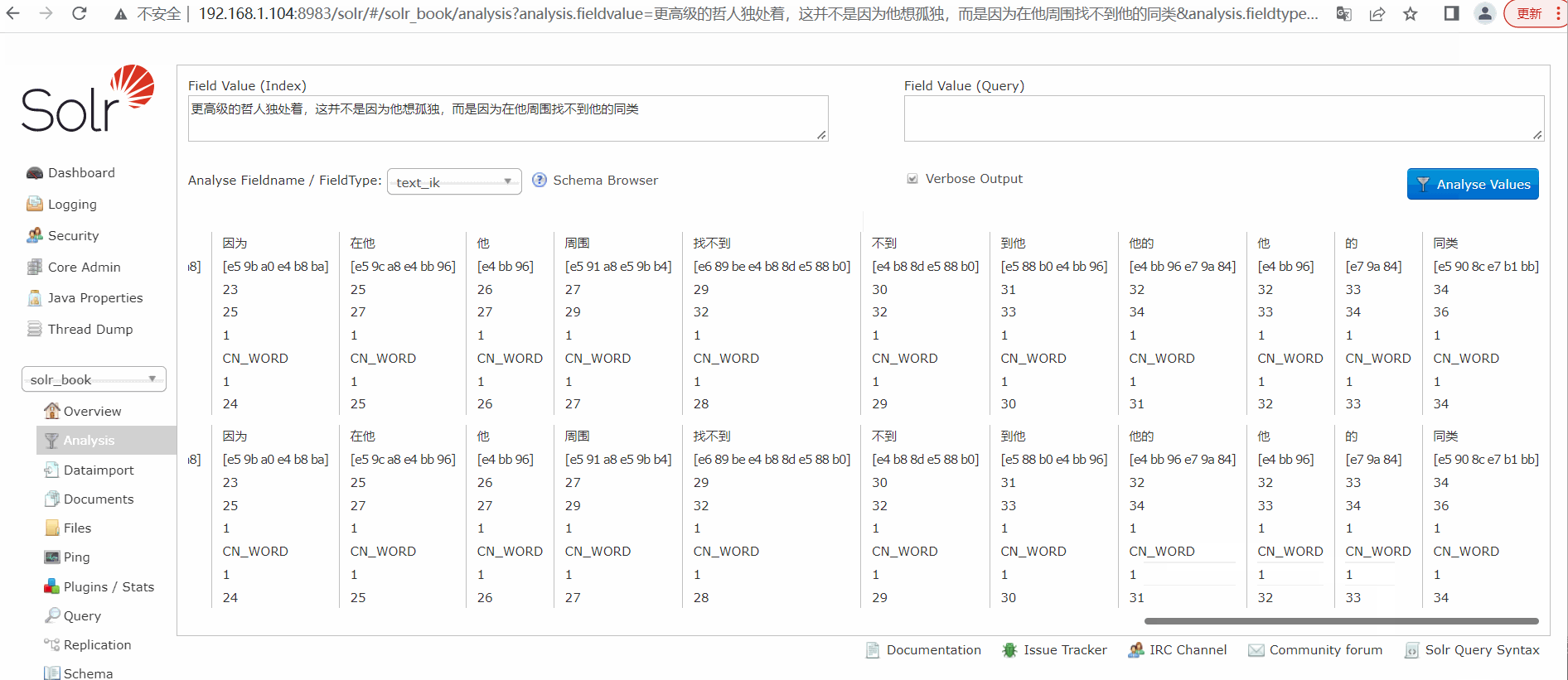
中文分词测试
1.2、docke solr 安装
1.2.1、docker 安装 solr
docker pull solr:8.11.2docker run --name solr_demo -d -p 8983:8983 solr:8.11.2 
开启容器后,浏览器访问宿主机器ip+8983端口,访问 Admin Web管理页面

1.2.2、创建实例
创建实例 shop_solr
docker exec -it solr_demo solr create_core -c shop_solr

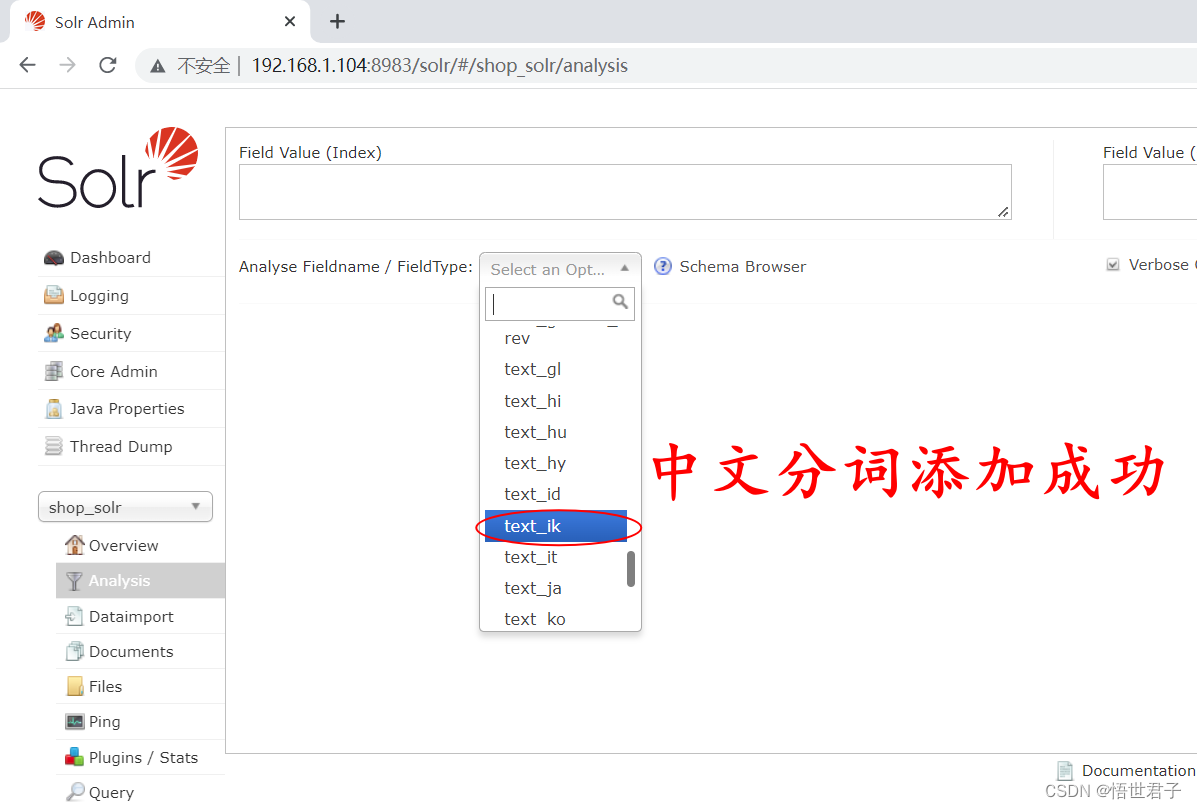
1.2.3、添加中文分词
步骤和 linux 安装 solr 添加中文分词一样,先添加 ik-analyzer-8.5.0.jar 包,然后在 managed-schema 中添加配置
docker cp ik-analyzer-8.5.0.jar solr_demo:/opt/solr-8.11.2/server/solr-webapp/webapp/WEB-INF/lib
将 docker 容器中的 managed-schema 文件复制出来进行修改
docker cp solr_demo:/var/solr/data/shop_solr/conf/managed-schema /root
添加下面配置
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>在managed-schema 文件中添加配置和上面Linux安装solr添加中文分词处理一样,可以编辑managed-schema 文件或下载下来再处理,这里不再赘述
修改后,将 managed-schema 文件复制到 docker 容器
docker cp /root/managed-schema solr_demo:/var/solr/data/shop_solr/conf/docker restart solr_demo
2、Java API
2.1、项目搭建
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.7</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.wsjz</groupId>
<artifactId>solr-learn</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>solr-learn</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-solr</artifactId>
<version>2.4.13</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
SolrConfig 配置类
package com.wsjz.config;
import org.apache.solr.client.solrj.SolrClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.solr.core.SolrTemplate;
@Configuration
public class SolrConfig {
@Autowired
private SolrClient solrClient;
@Bean
public SolrTemplate solrTemplate() {
return new SolrTemplate(solrClient);
}
}
package com.wsjz.bean;
import org.apache.solr.client.solrj.beans.Field;
import org.springframework.data.annotation.Id;
import org.springframework.data.solr.core.mapping.SolrDocument;
import lombok.Data;
@Data
@SolrDocument(collection = "solr_book")
public class Book {
@Id
@Field
private String id;
/**
* 书名
*/
@Field
private String name;
/**
* 作者
*/
@Field
private String author;
/**
* 介绍
*/
@Field
private String introduce;
}
package com.wsjz.bean;
import java.util.List;
import org.springframework.data.solr.core.query.result.HighlightEntry;
import lombok.Data;
@Data
public class HighlightBook extends Book {
/**
* 存储高亮字段
*/
private List<HighlightEntry.Highlight> highlight;
@Override
public String toString() {
String snipplets = "";
for (HighlightEntry.Highlight h : highlight) {
snipplets += h.getSnipplets().toString();
}
return "HighlightBook [highlight=" + snipplets + "]" + super.toString();
}
}
BookController
package com.wsjz.controller;
import java.util.List;
import java.util.stream.Collectors;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Sort;
import org.springframework.data.solr.core.SolrTemplate;
import org.springframework.data.solr.core.query.Criteria;
import org.springframework.data.solr.core.query.HighlightOptions;
import org.springframework.data.solr.core.query.SimpleHighlightQuery;
import org.springframework.data.solr.core.query.SimpleQuery;
import org.springframework.data.solr.core.query.result.HighlightEntry;
import org.springframework.data.solr.core.query.result.HighlightPage;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import com.wsjz.bean.Book;
import com.wsjz.bean.HighlightBook;
@RestController
public class BookController {
@Autowired
private SolrTemplate solrTemplate;
/**
* solr实例名称
*/
private static final String collection = "solr_book";
/**
* 添加
*
* @return
*/
@RequestMapping("/add")
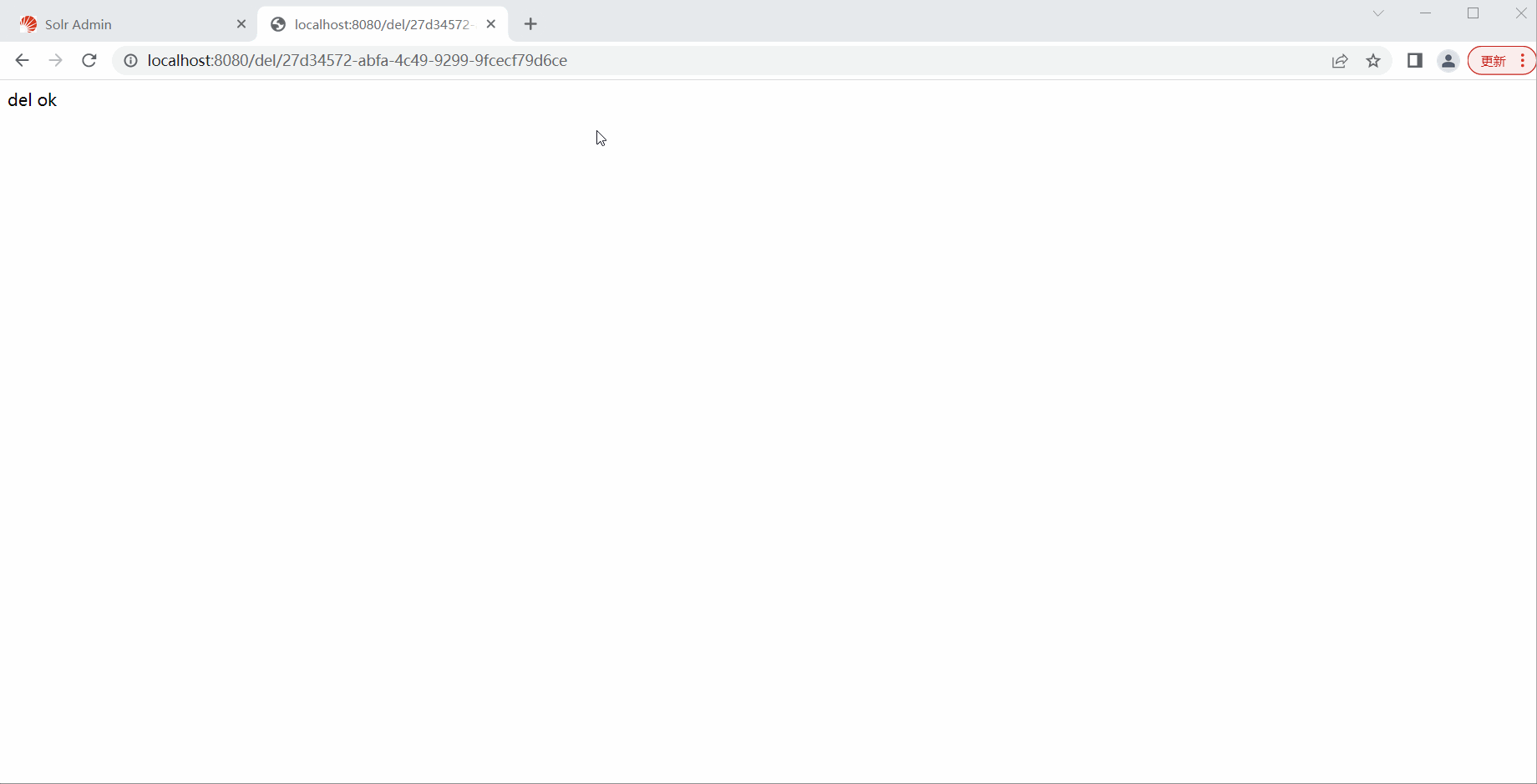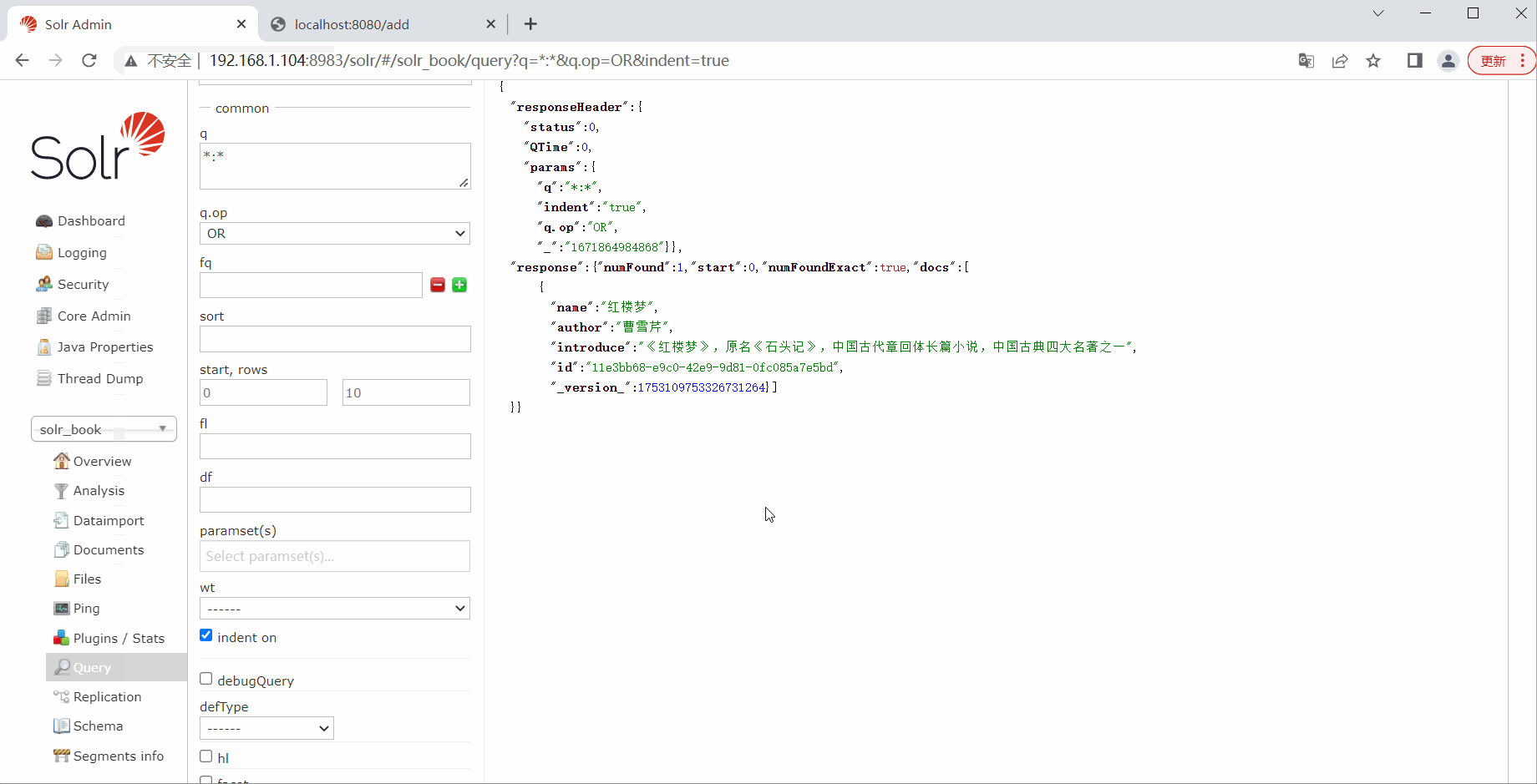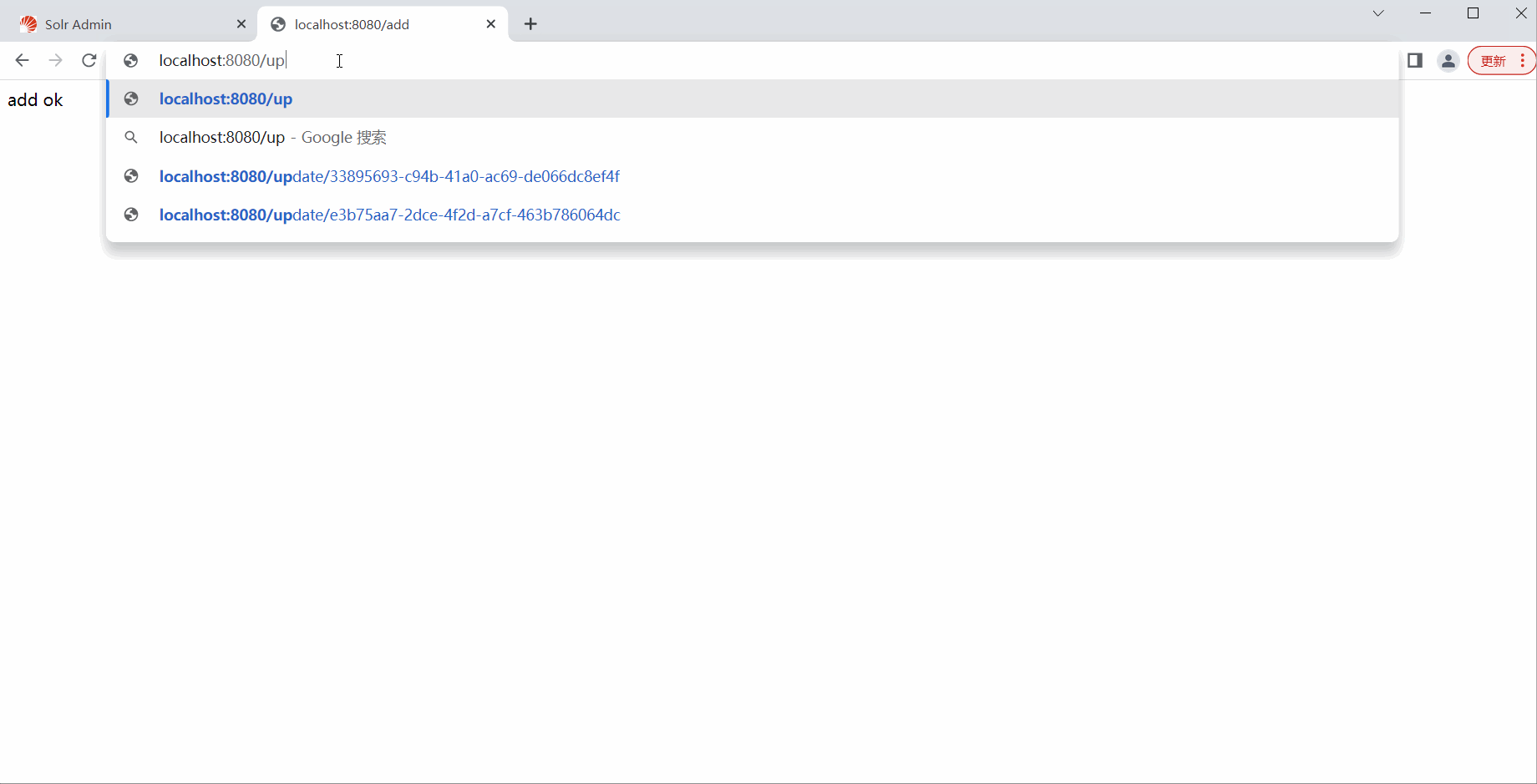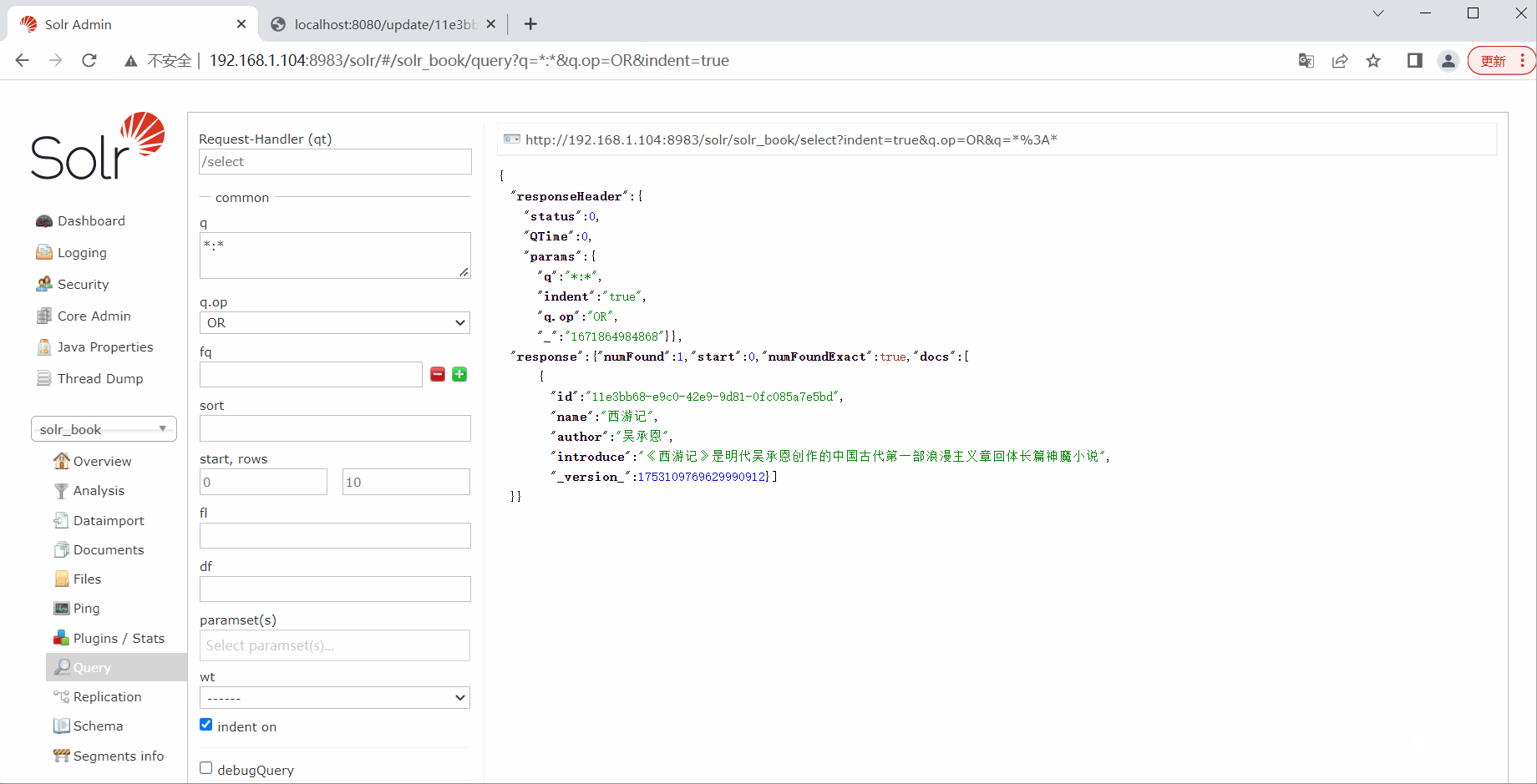
public String add() {
Book book = new Book();
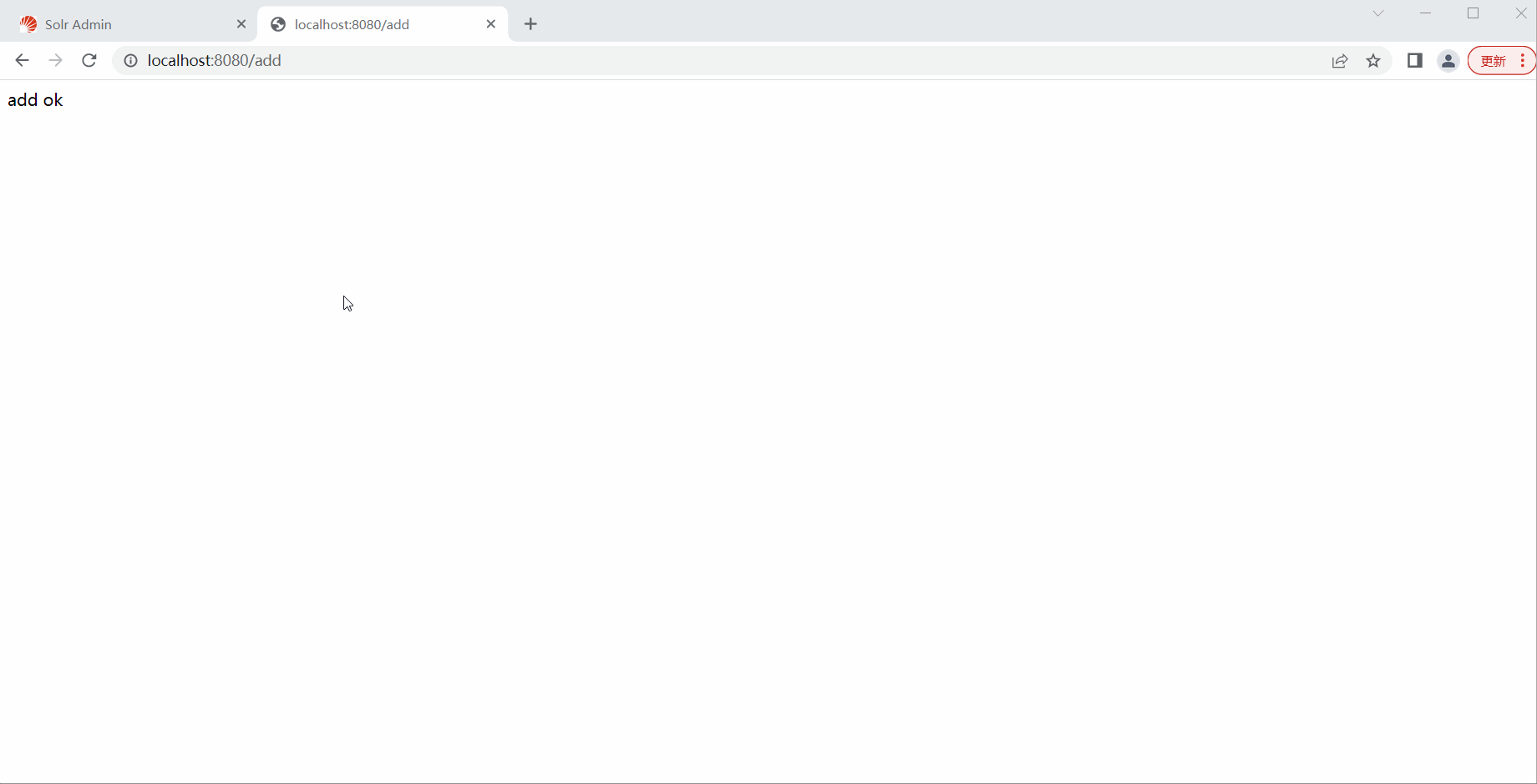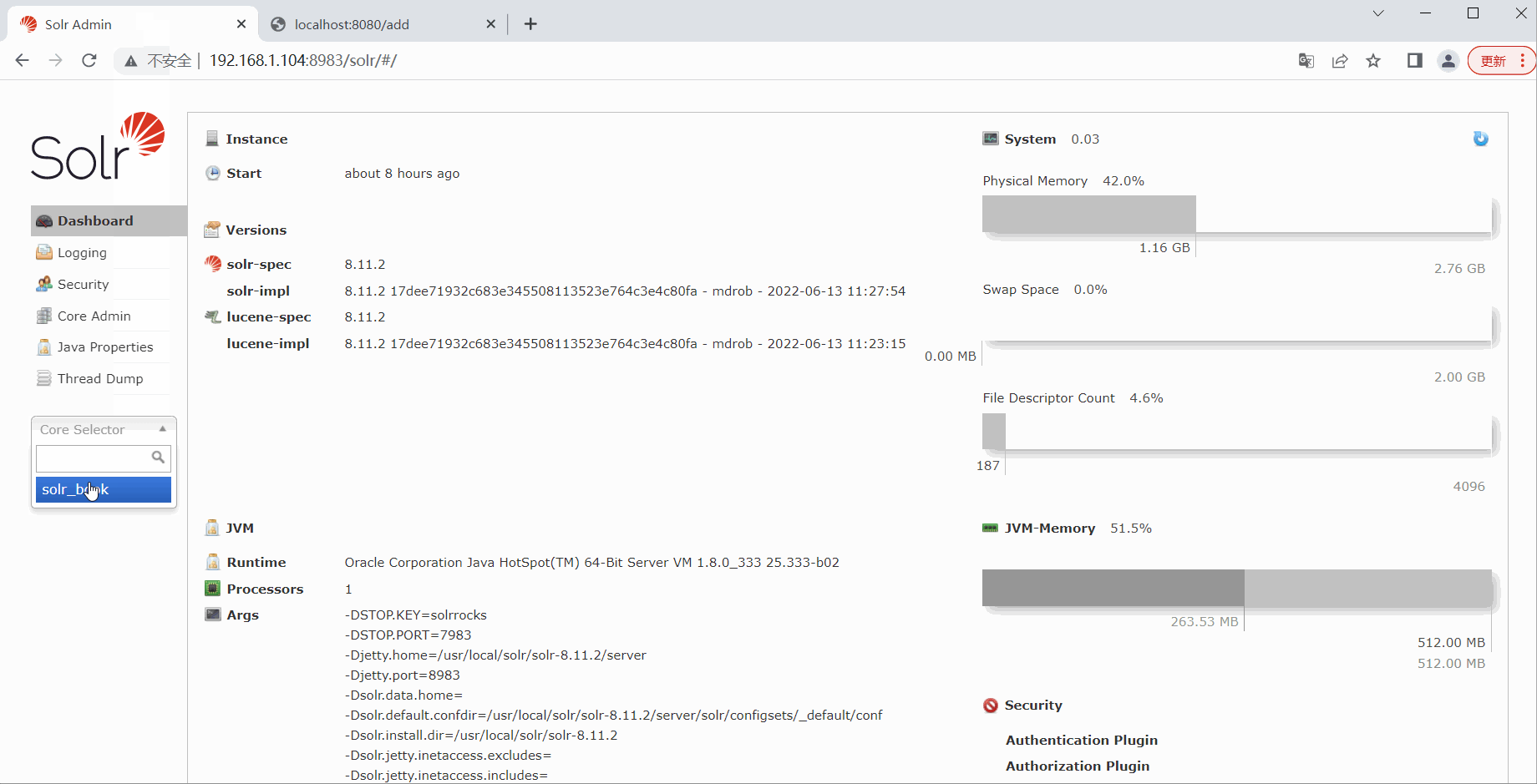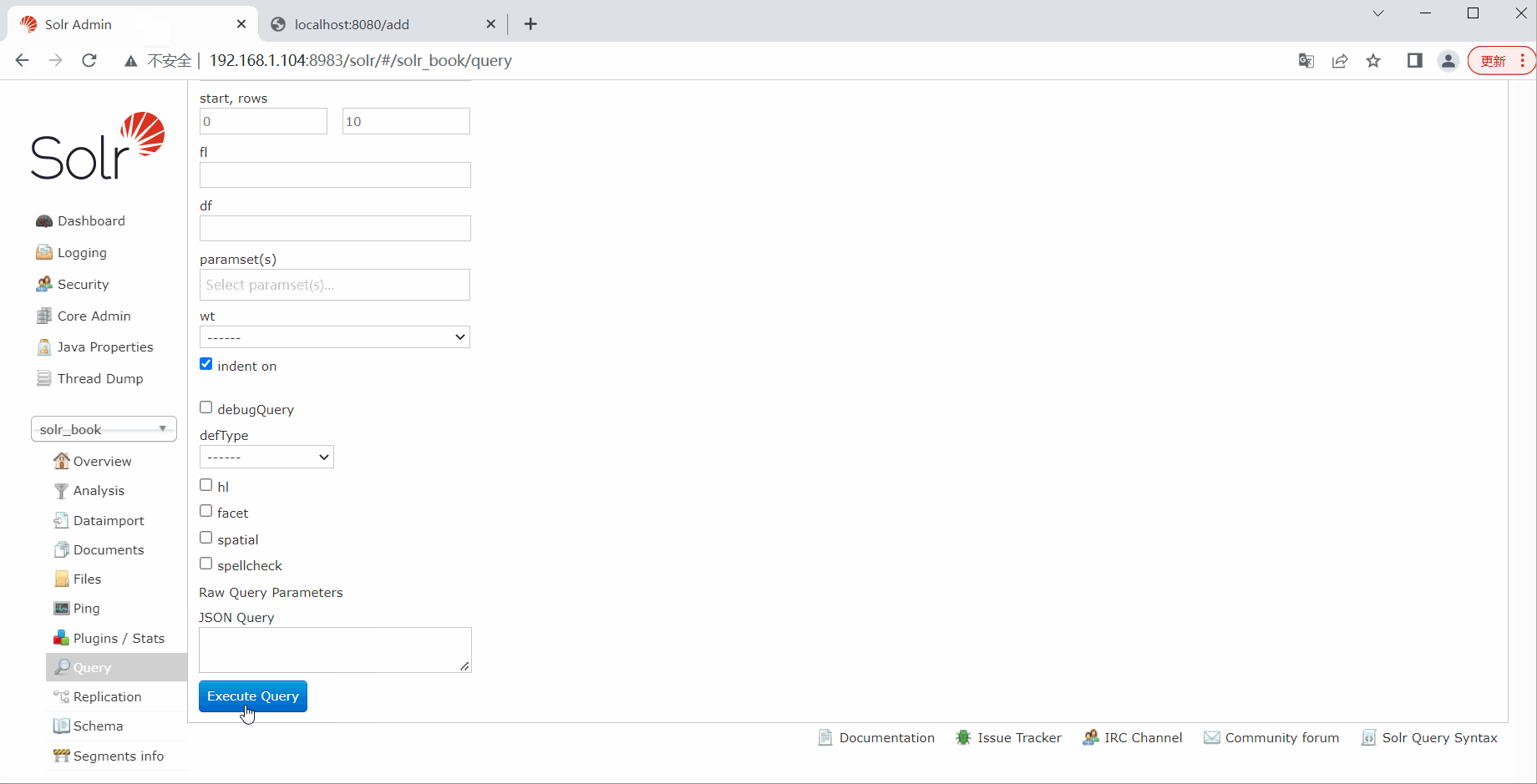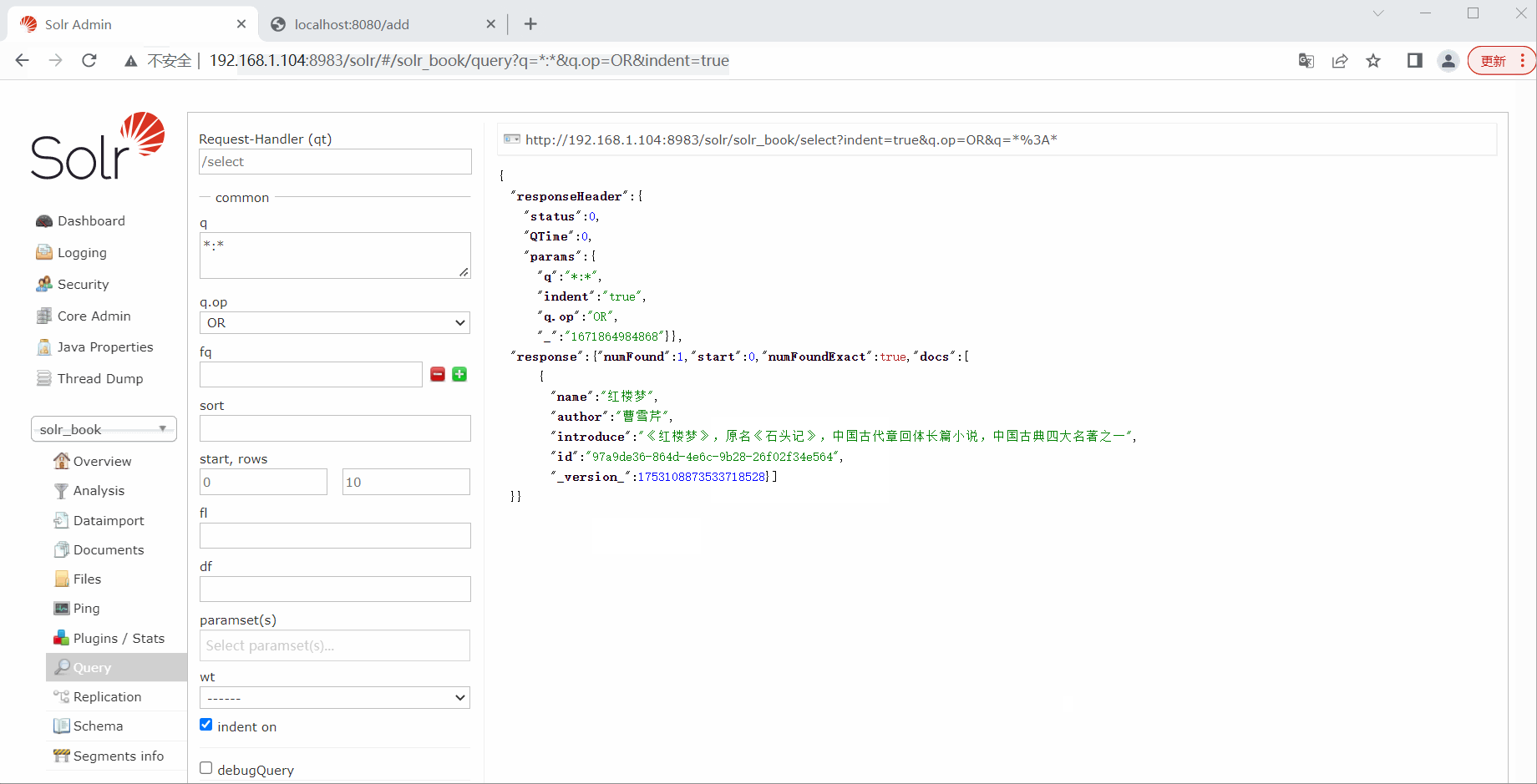
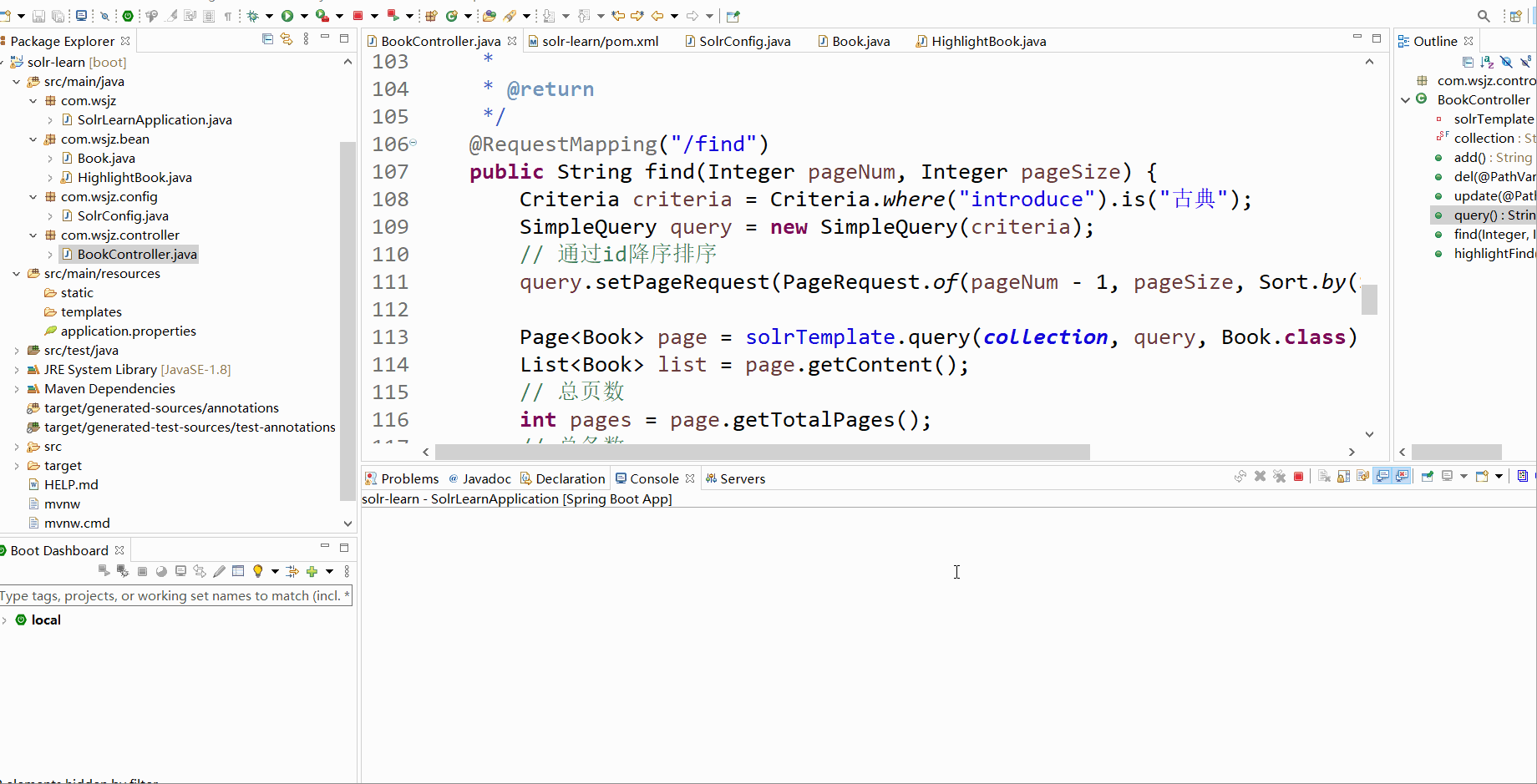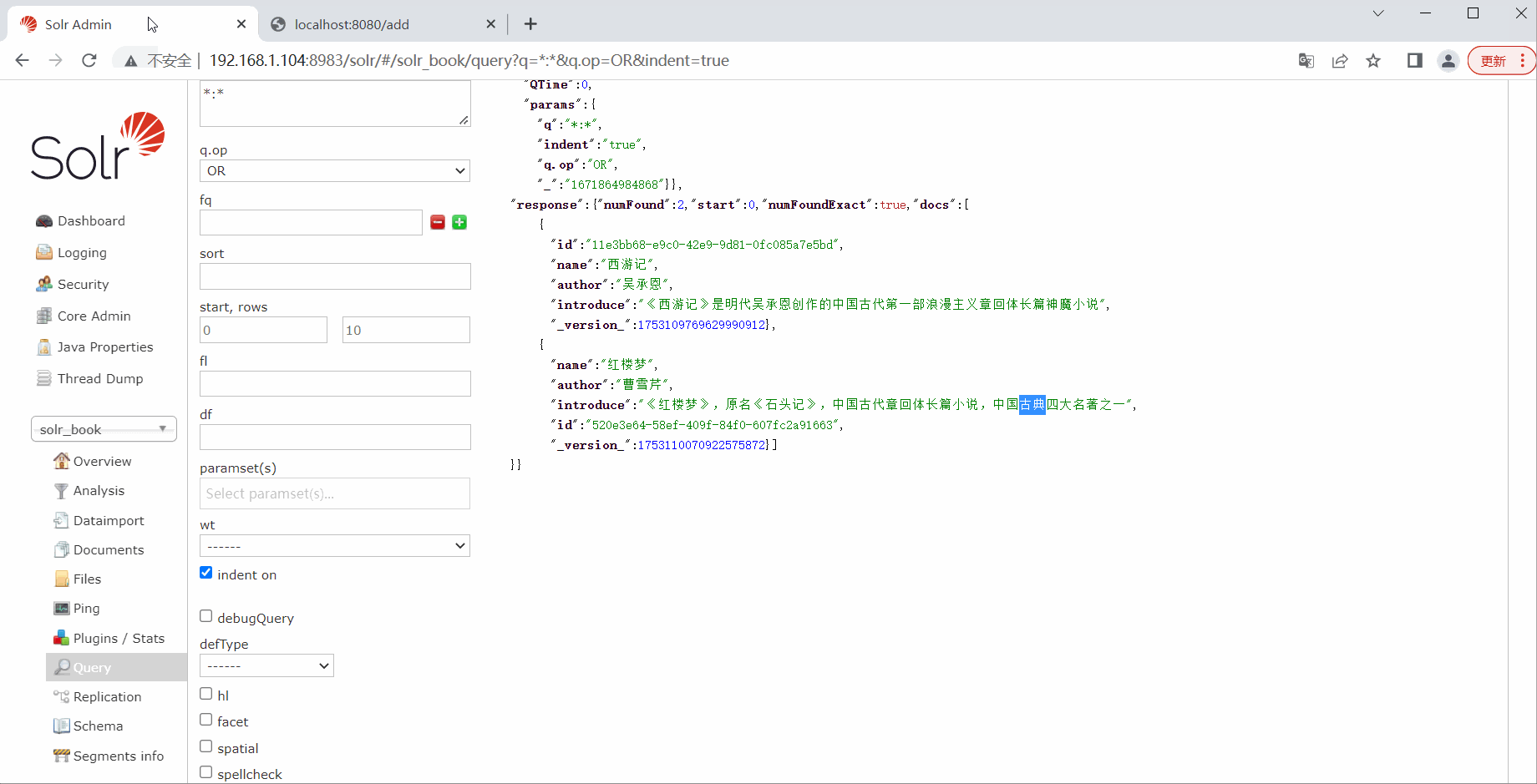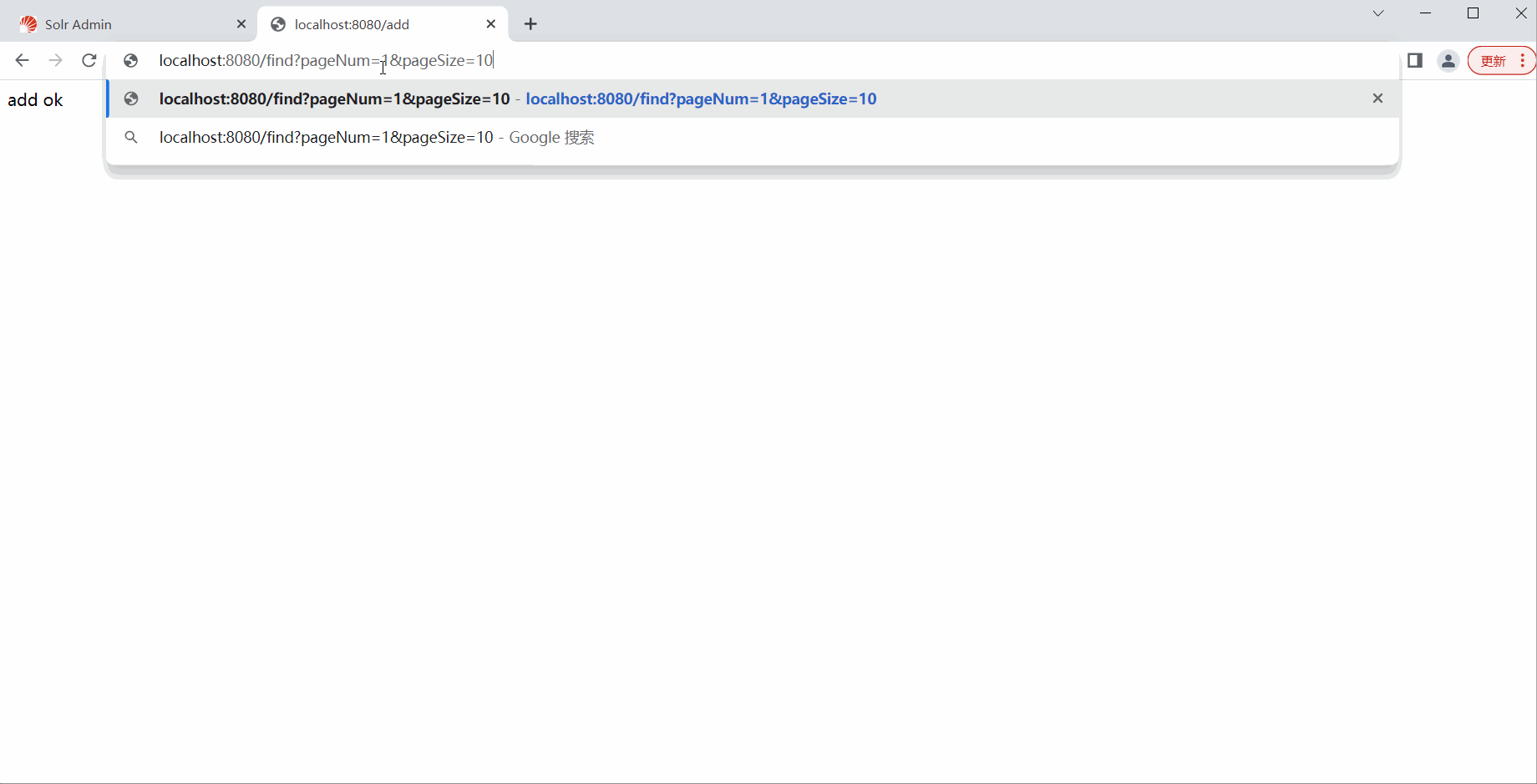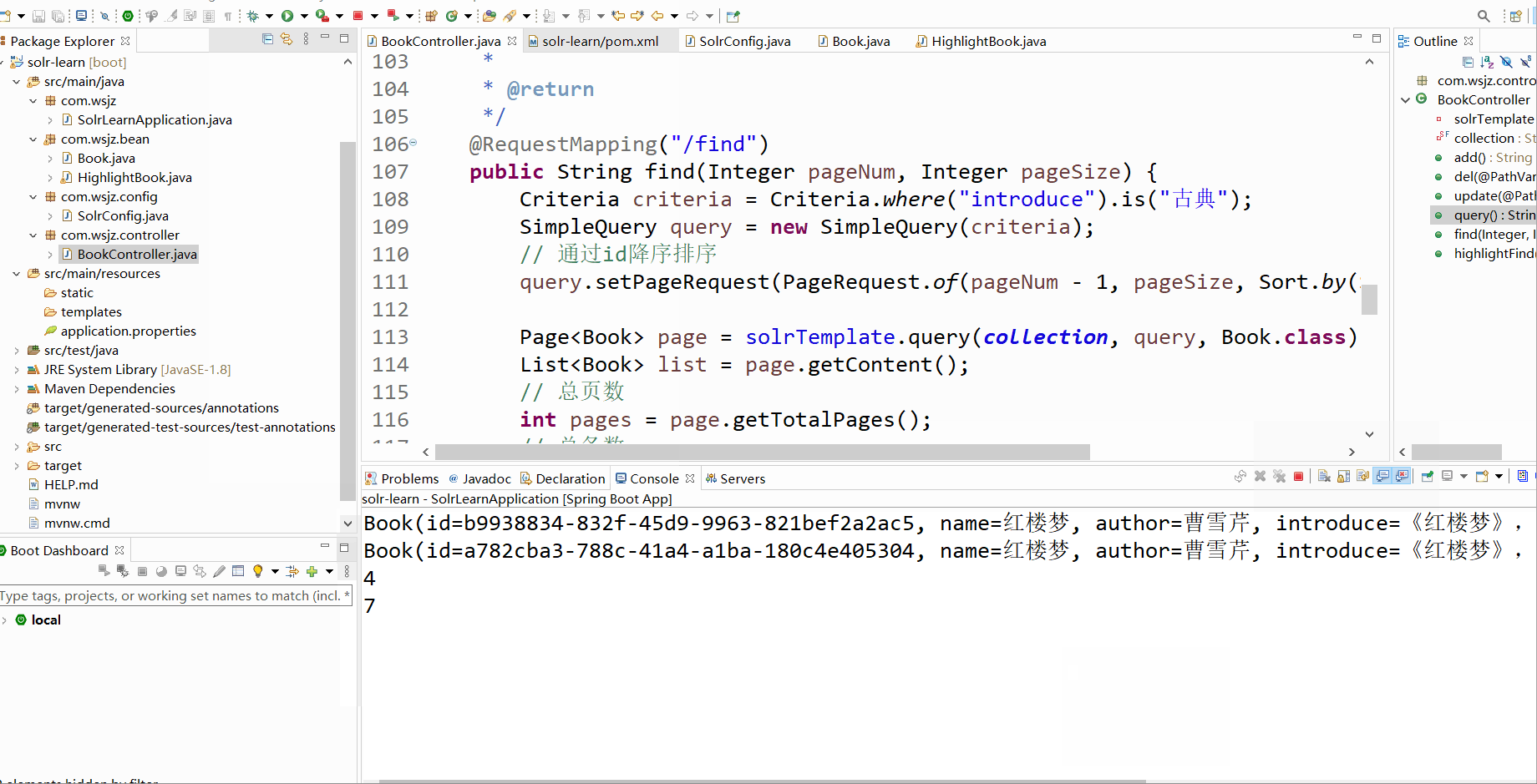
book.setName("红楼梦");
book.setAuthor("曹雪芹");
book.setIntroduce("《红楼梦》,原名《石头记》,中国古代章回体长篇小说,中国古典四大名著之一");
solrTemplate.saveBean(collection, book);
solrTemplate.commit(collection);
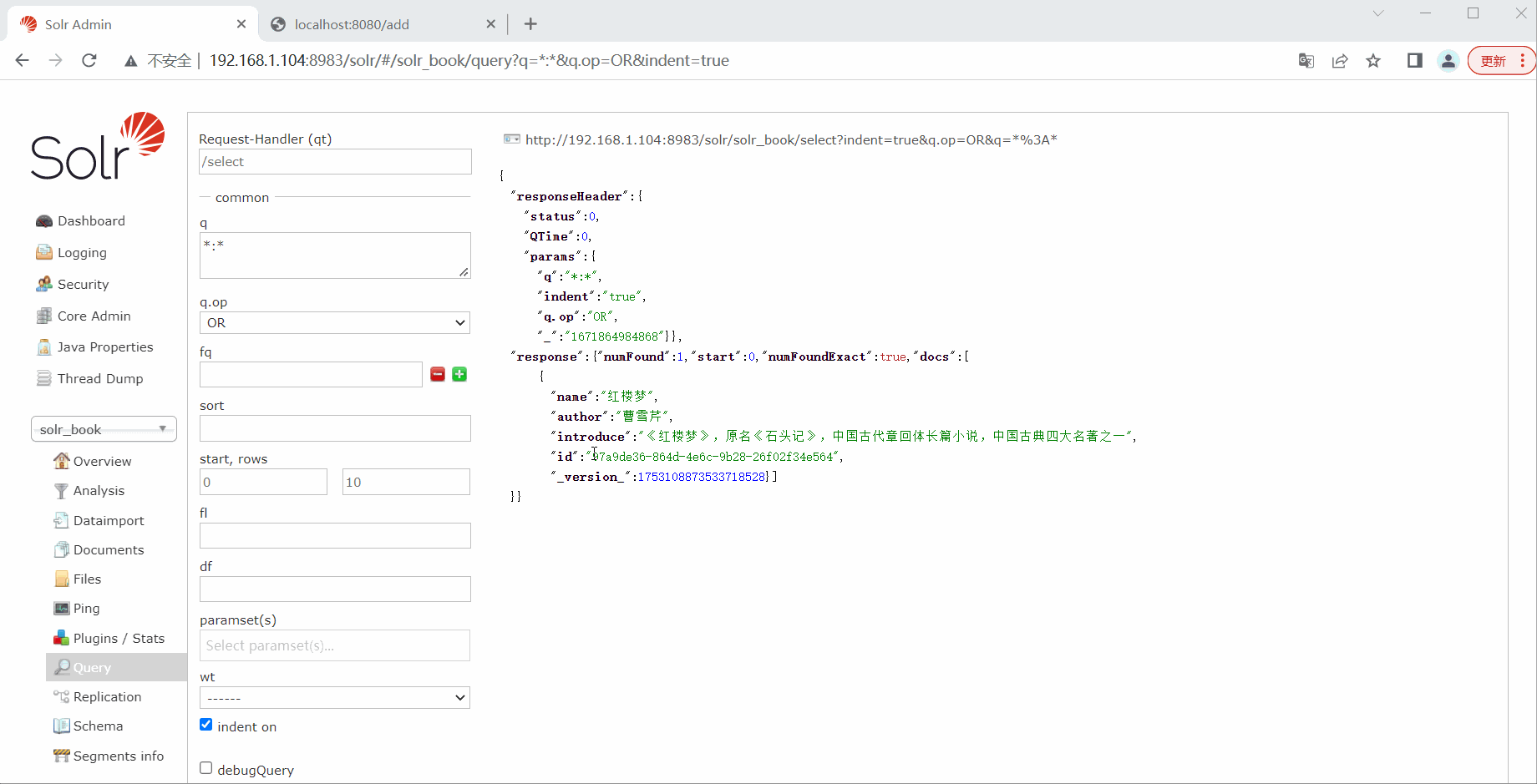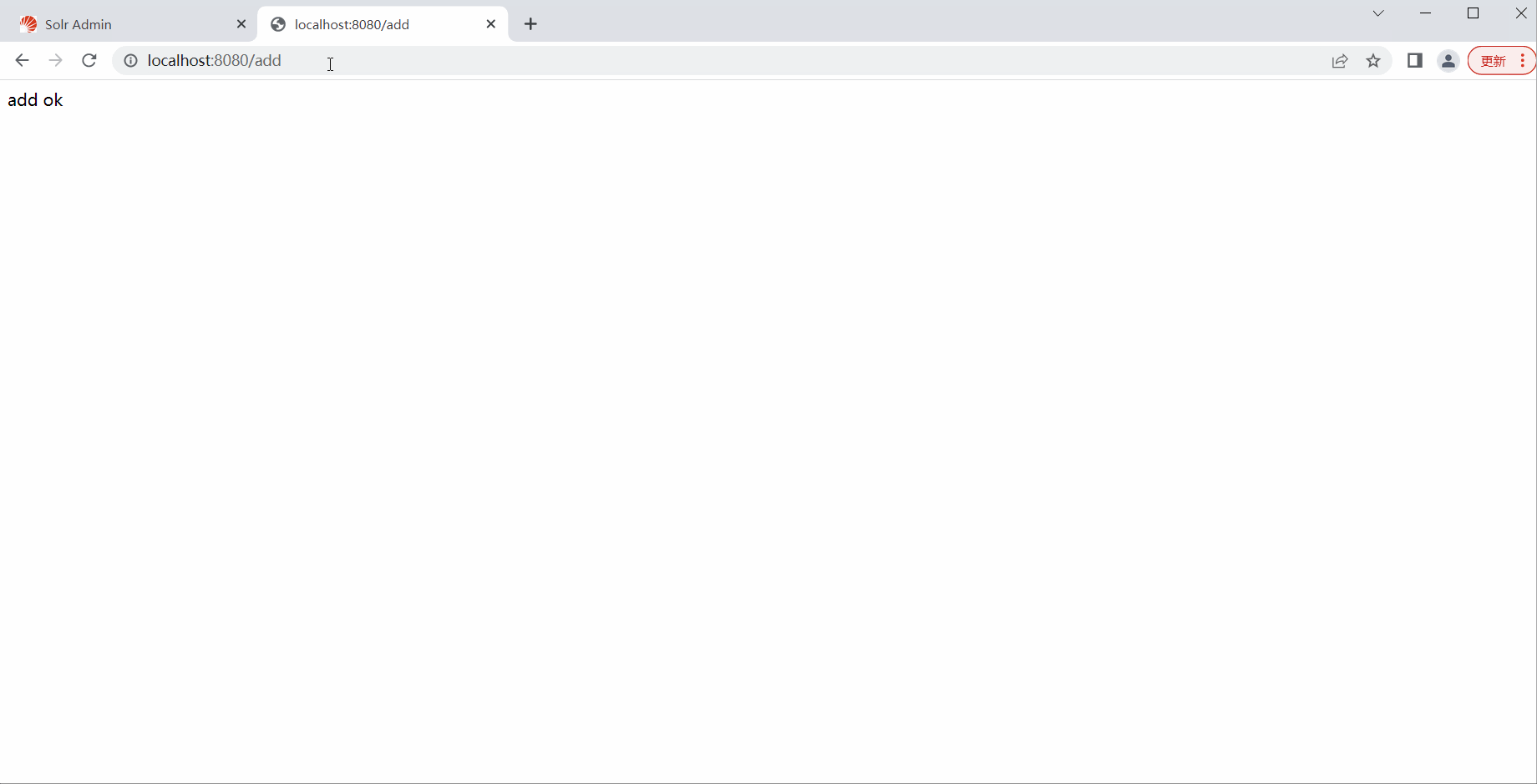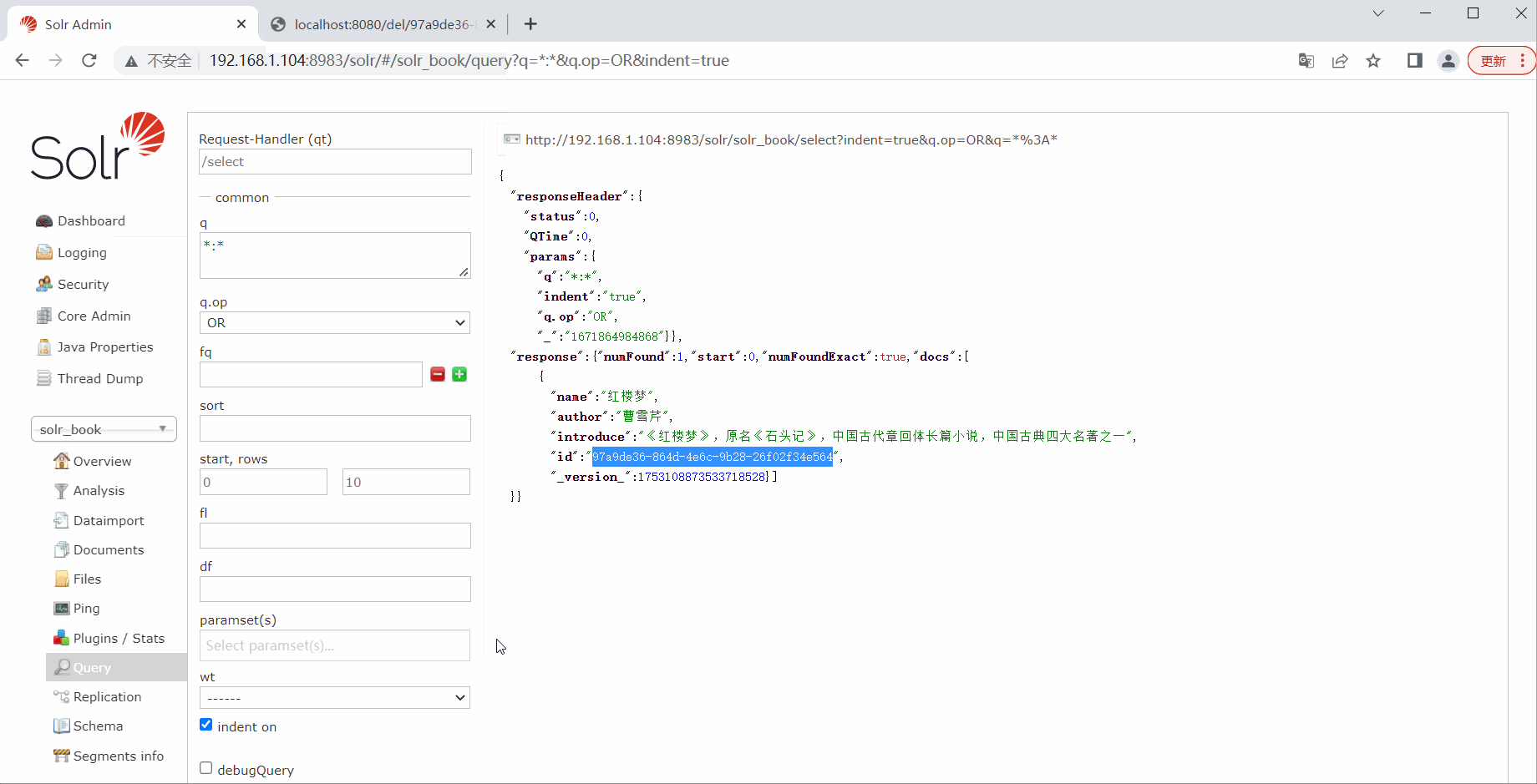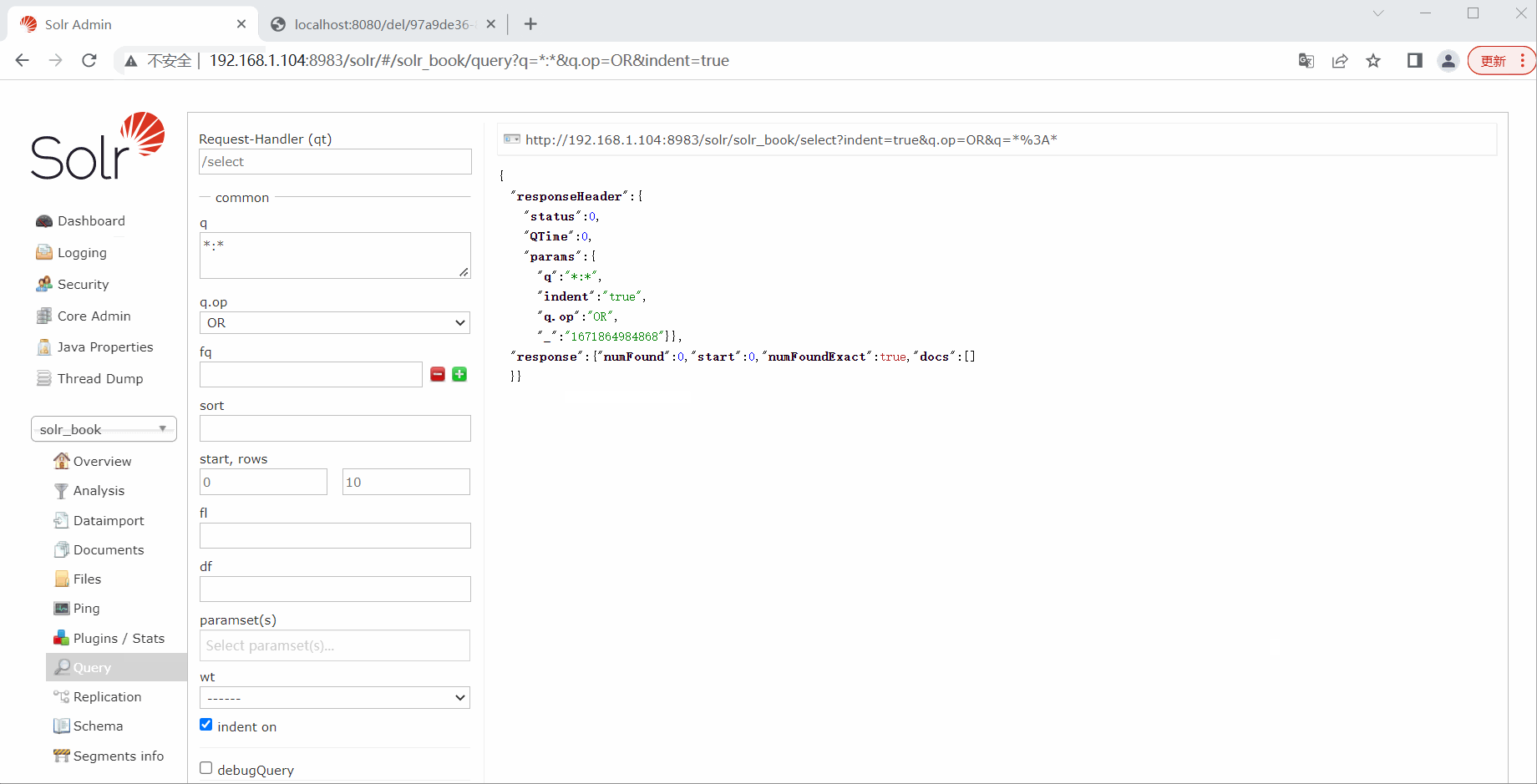
return "add ok";
}
/**
* 删除
*
* @param id
* @return
*/
@RequestMapping("/del/{id}")
public String del(@PathVariable("id") String id) {
solrTemplate.deleteByIds(collection, id);
solrTemplate.commit(collection);
return "del ok";
}
/**
* 修改
*
* @param id
* @return
*/
@RequestMapping("/update/{id}")
public String update(@PathVariable("id") String id) {
Book book = new Book();
book.setId(id);
book.setName("西游记");
book.setAuthor("吴承恩");
book.setIntroduce("《西游记》是明代吴承恩创作的中国古代第一部浪漫主义章回体长篇神魔小说");
// 有id进行修改操作
solrTemplate.saveBean(collection, book);
solrTemplate.commit(collection);
return "update ok";
}
/**
* 查询
*
* @return
*/
@RequestMapping("/query")
public String query() {
Criteria criteria = Criteria.where("introduce").is("古典");
SimpleQuery query = new SimpleQuery(criteria);
Page<Book> page = solrTemplate.query(collection, query, Book.class);
List<Book> list = page.getContent();
list.forEach(System.out::println);
return "query ok";
}
/**
* 分页查询
*
* @return
*/
@RequestMapping("/find")
public String find(Integer pageNum, Integer pageSize) {
Criteria criteria = Criteria.where("introduce").is("古典");
SimpleQuery query = new SimpleQuery(criteria);
// 通过id降序排序
query.setPageRequest(PageRequest.of(pageNum - 1, pageSize, Sort.by(Sort.Direction.DESC, "id")));
Page<Book> page = solrTemplate.query(collection, query, Book.class);
List<Book> list = page.getContent();
// 总页数
int pages = page.getTotalPages();
// 总条数
long total = page.getTotalElements();
list.forEach(System.out::println);
System.out.println(pages);
System.out.println(total);
return "find ok";
}
/**
* 高亮查询
*
* @param pageNum
* @param pageSize
* @return
*/
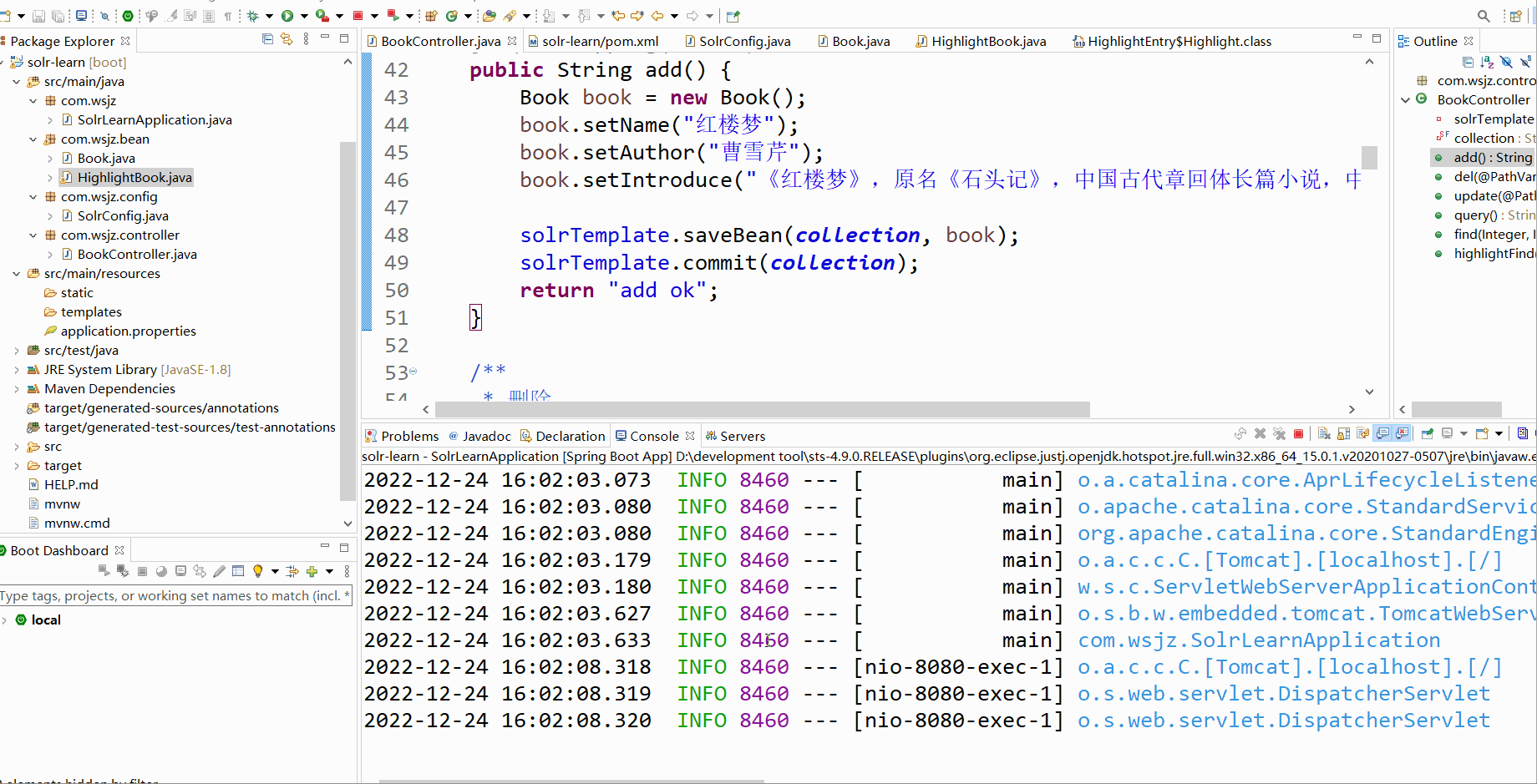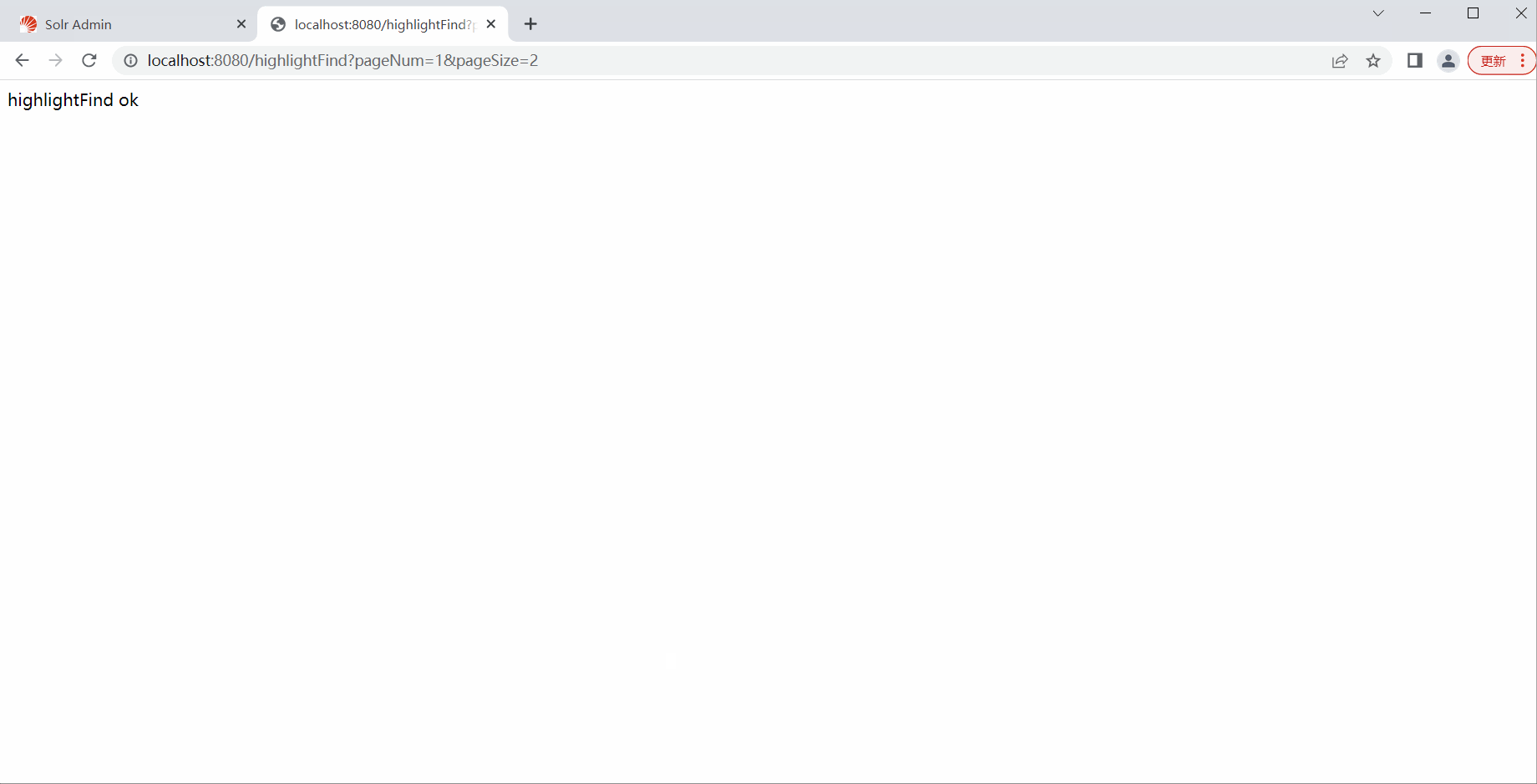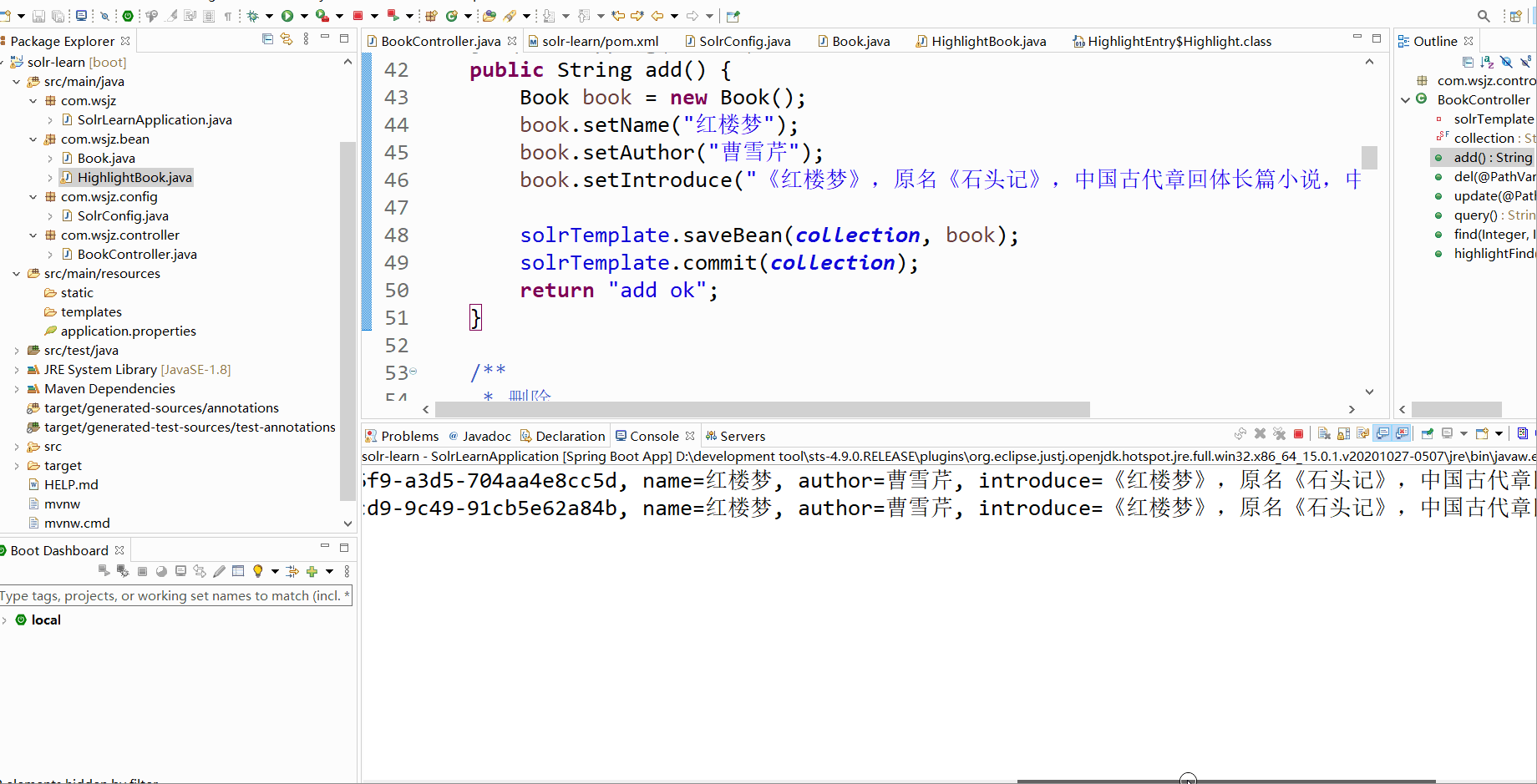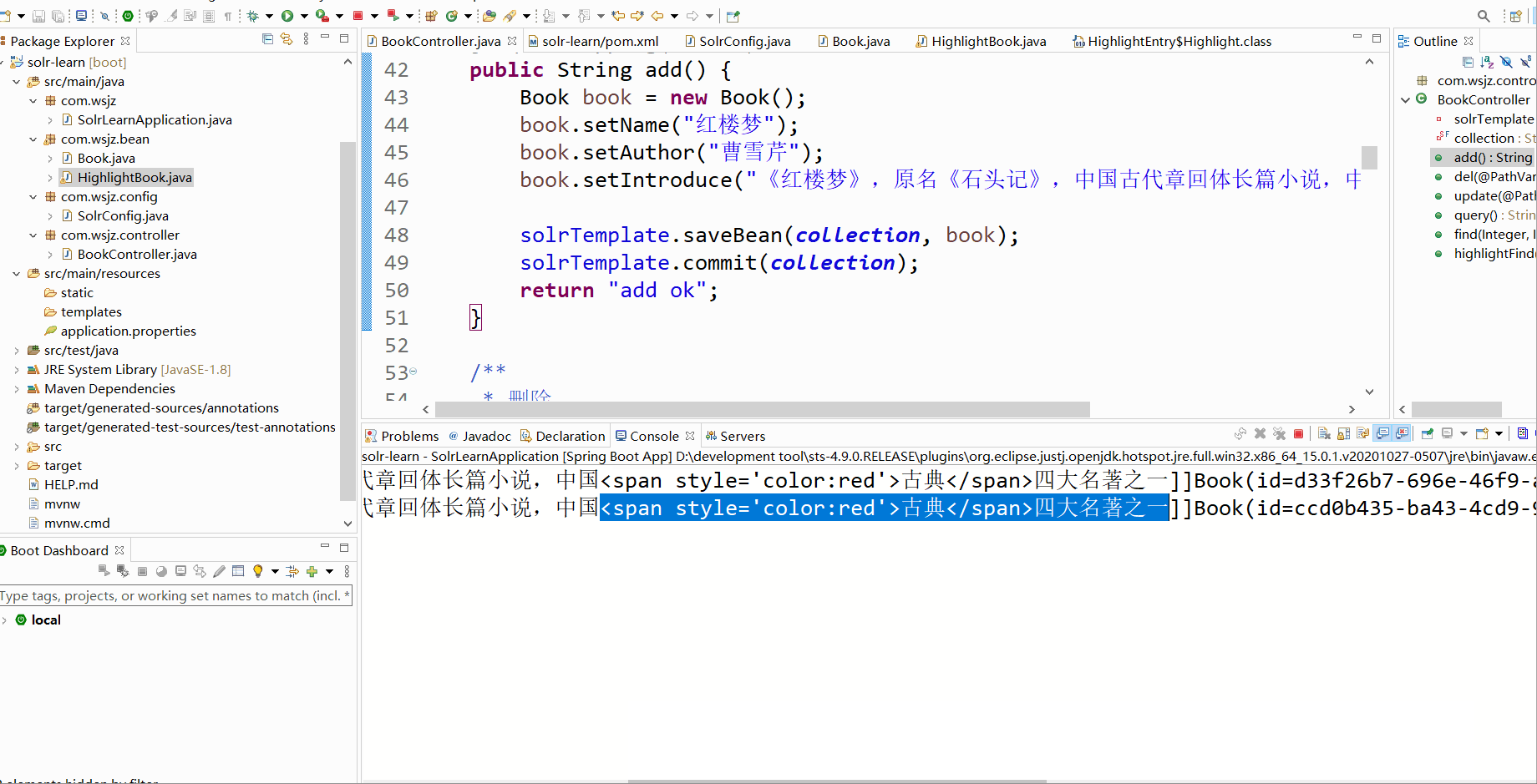
@RequestMapping("/highlightFind")
public String highlightFind(Integer pageNum, Integer pageSize) {
Criteria criteria = Criteria.where("introduce").is("古典");
// 高亮查询
SimpleHighlightQuery query = new SimpleHighlightQuery(criteria);
// 通过id降序排序
query.setPageRequest(PageRequest.of(pageNum - 1, pageSize, Sort.by(Sort.Direction.DESC, "id")));
HighlightOptions highlightOptions = new HighlightOptions();
highlightOptions.addField("introduce");
highlightOptions.setSimplePrefix("<span style='color:red'>");
highlightOptions.setSimplePostfix("</span>");
query.setHighlightOptions(highlightOptions);
HighlightPage<Book> page = solrTemplate.queryForHighlightPage(collection, query, Book.class);
List<Book> content = page.getContent();
List<HighlightBook> list = content.stream().map(book -> {
HighlightBook highlightBook = new HighlightBook();
BeanUtils.copyProperties(book, highlightBook);
List<HighlightEntry.Highlight> highlights = page.getHighlights(book);
highlightBook.setHighlight(highlights);
return highlightBook;
}).collect(Collectors.toList());
// 总页数
int pages = page.getTotalPages();
// 总条数
long total = page.getTotalElements();
list.forEach(System.out::println);
System.out.println(pages);
System.out.println(total);
return "highlightFind ok";
}
}
2.2、solr中定义域名和域的类型
solr中域名和域的类型,等同于mysql中表字段和表字段类型
上面有Book实体类,有字段name、author、introduce;需要在solr中定义对应的域,以及对应的分词器
这里笔者对introduce字段进行中文分词,使用上面配置的中文分词器 text_ik
需要在solr_book实例下面的managed-schema文件中添加域的配置
<field name="name" type="string" indexed="true" stored="true" multiValued="false" />
<field name="author" type="string" indexed="true" stored="true" multiValued="false" />
<field name="introduce" type="text_ik" indexed="true" stored="true" multiValued="false" />编辑 managed-schema 文件
vi /usr/local/solr/solr-8.11.2/server/solr/solr_book/conf/managed-schema在managed-schema文件末尾添加域的配置
配置后重启 solr
bin/solr restart -force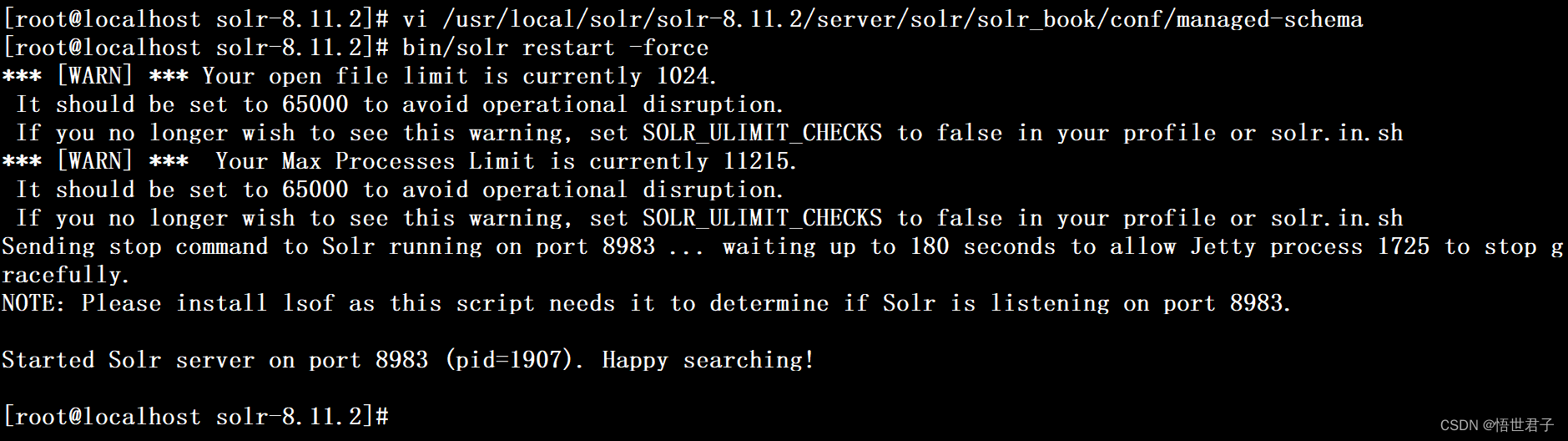
2.3、Java API 测试
测试添加
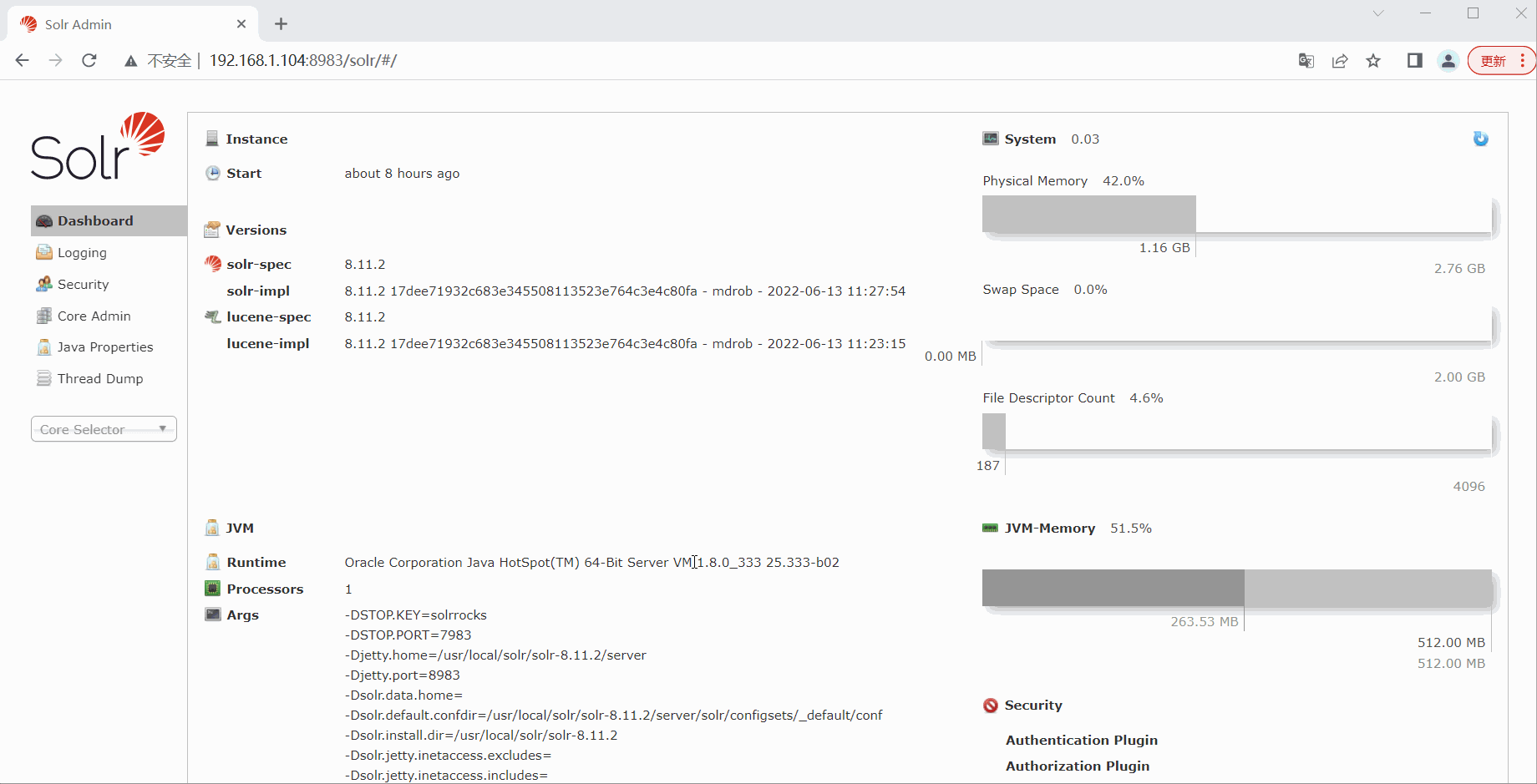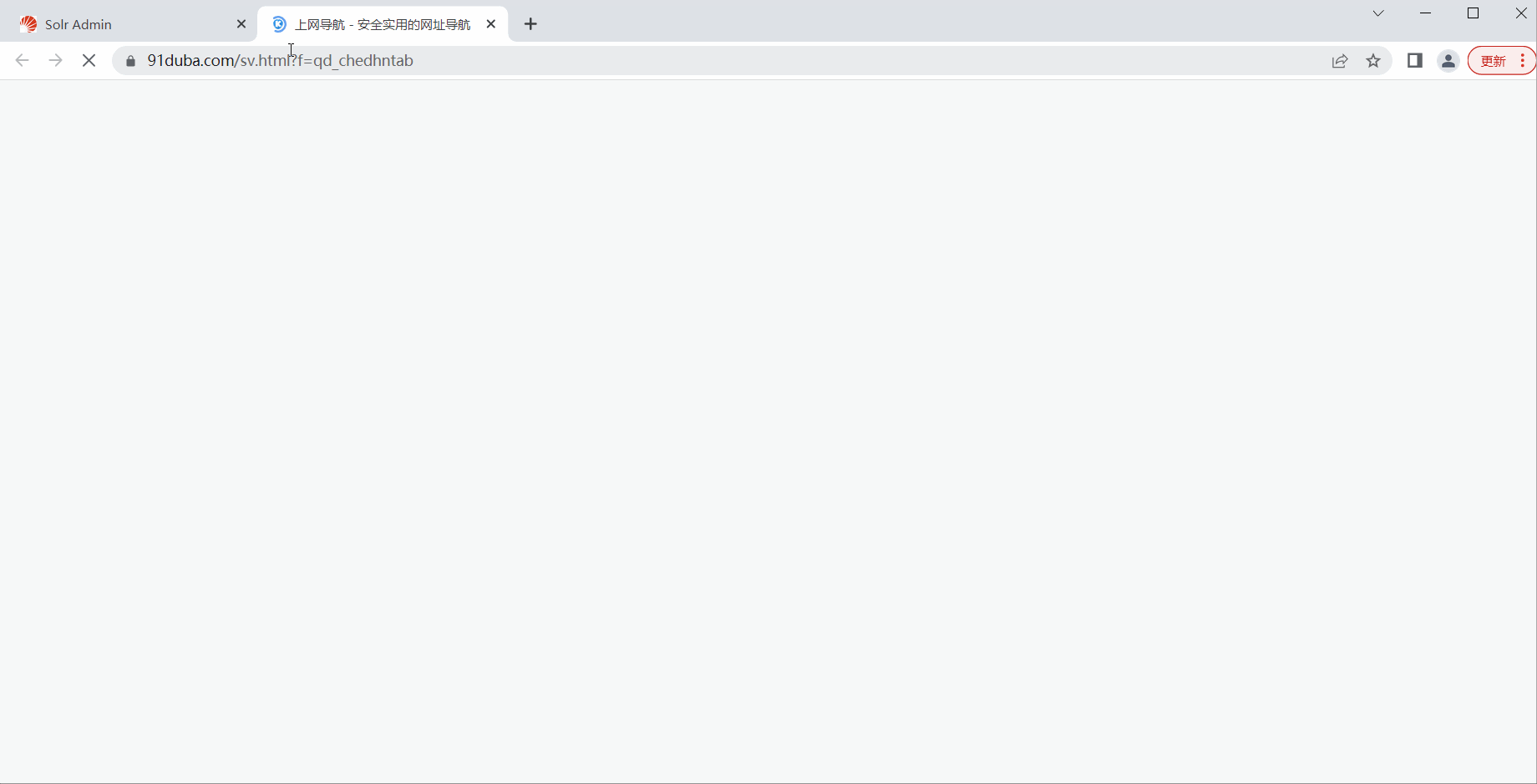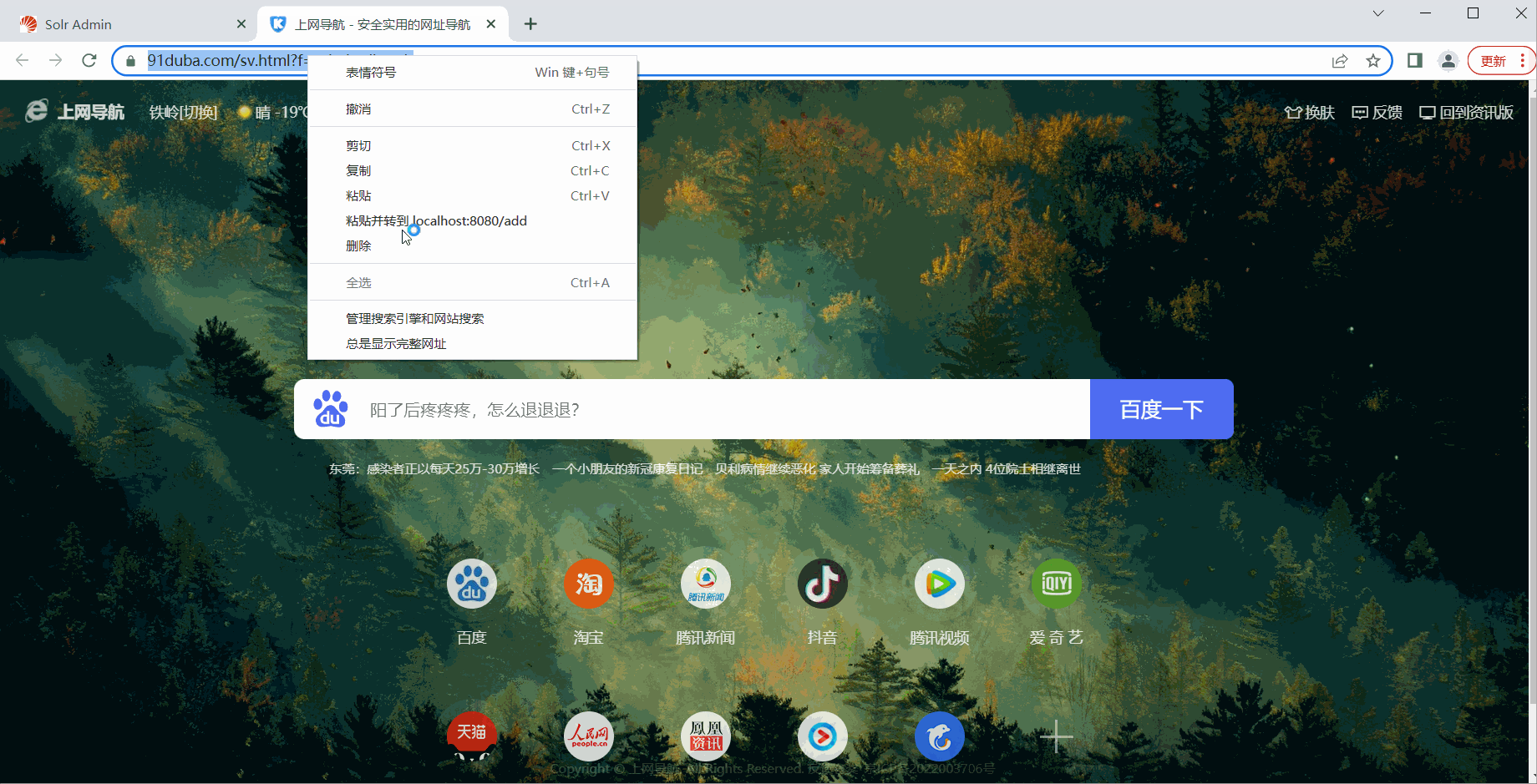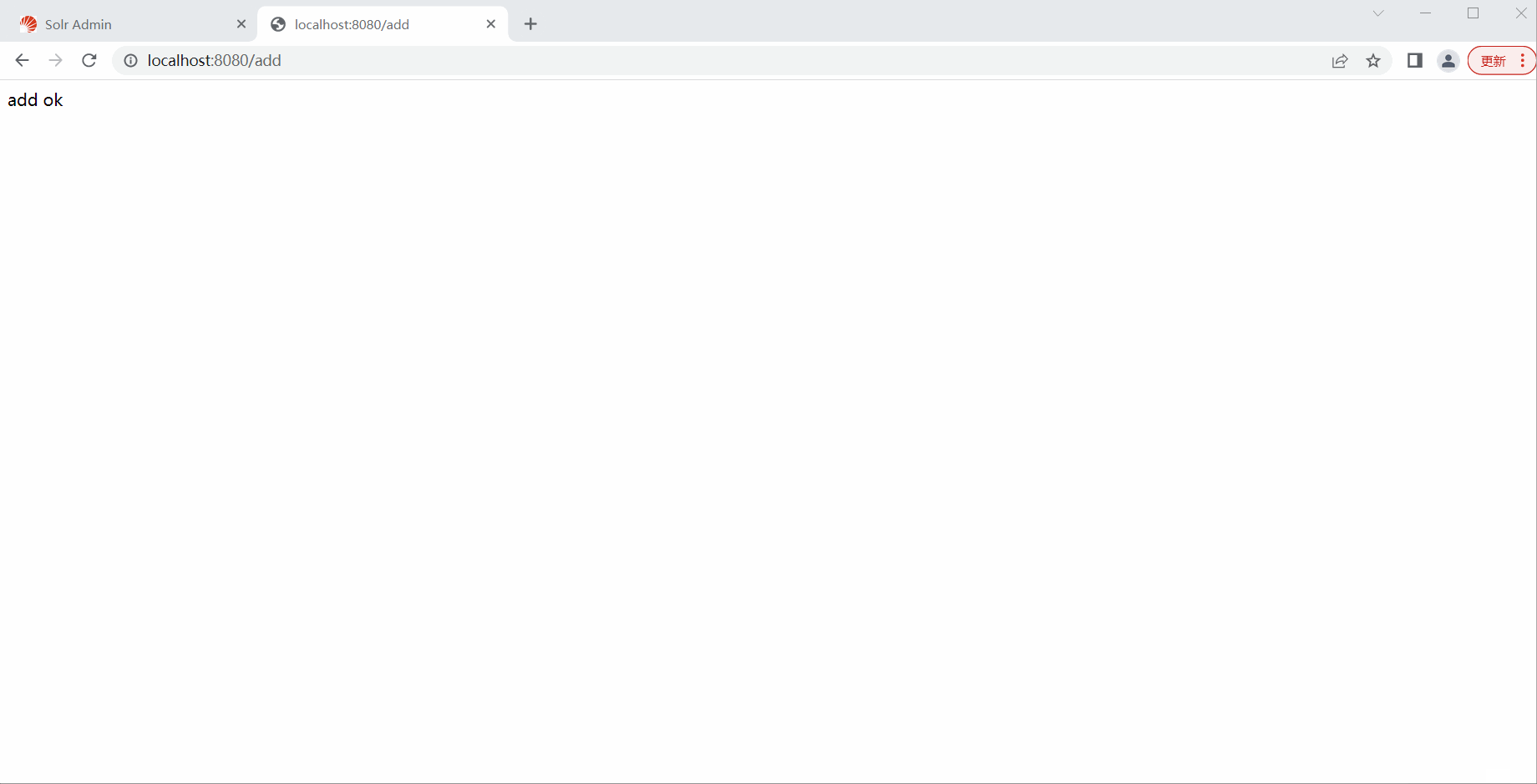
测试删除
测试修改
修改前先添加一条
测试查询

测试分页查询
测试高亮查询
至此完
原文地址:https://blog.csdn.net/wsjzzcbq/article/details/128413086
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_29050.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!