cyclictest 主要是用于测试系统延时,进而判断系统的实时性
使用版本
rt–tests-2.6.tar.gz
numactl v2.0.16
问题
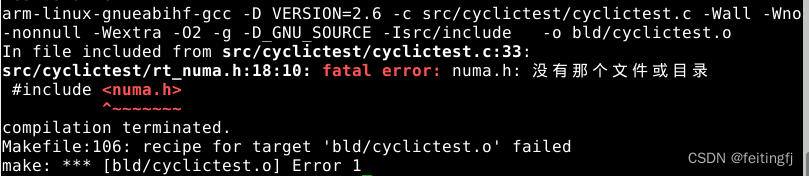
arm-linux-gnueabihf-gcc -D VERSION=2.6 -c src/cyclictest/cyclictest.c -Wall -Wno-nonnull -Wextra -O2 -g -D_GNU_SOURCE -Isrc/include -o bld/cyclictest.o
In file included from src/cyclictest/cyclictest.c:33:
src/cyclictest/rt_numa.h:18:10: fatal error: numa.h: 没有那个文件或目录
#include <numa.h>
^~~~~~~~
compilation terminated.
Makefile:106: recipe for target 'bld/cyclictest.o' failed
make: *** [bld/cyclictest.o] Error 1
编译 numactl
文件下载 https://github.com/numactl/numactl/tree/v2.0.16
./autogen.sh
./configure CC=arm-linux-gnueabihf-gcc --host=arm prefix=~/git/numactl-2.0.16/build
make install
这是主要用到编译生成的 lib 及 include 里的文件
编译 cyclictest
https://git.kernel.org/pub/scm/utils/rt-tests/rt-tests.git/
在 RTTESTLIB 后面加上 -L/home/XXX/git/numactl-2.0.16/build/lib
在 CPPFLAGS 后面加上 -I/home/XXX/git/numactl-2.0.16/build/include
RTTESTLIB = -lrttest -L$(OBJDIR) -L/home/XXX/git/numactl-2.0.16/build/lib
CPPFLAGS += -D_GNU_SOURCE -Isrc/include -I/home/XXX/git/numactl-2.0.16/build/include
make CROSS_COMPILE=arm-linux-gnueabihf- LDFLAGS=-static
使用
cyclictest V 2.60
Usage:
cyclictest <options>
-a [CPUSET] --affinity Run thread #N on processor #N, if possible, or if CPUSET
given, pin threads to that set of processors in round-
robin order. E.g. -a 2 pins all threads to CPU 2,
but -a 3-5,0 -t 5 will run the first and fifth
threads on CPU (0),thread #2 on CPU 3, thread #3
on CPU 4, and thread #5 on CPU 5.
-A USEC --aligned=USEC align thread wakeups to a specific offset
-b USEC --breaktrace=USEC send break trace command when latency > USEC
-c CLOCK --clock=CLOCK select clock
0 = CLOCK_MONOTONIC (default)
1 = CLOCK_REALTIME
--default-system Don't attempt to tune the system from cyclictest.
Power management is not suppressed.
This might give poorer results, but will allow you
to discover if you need to tune the system
-d DIST --distance=DIST distance of thread intervals in us, default=500
-D --duration=TIME specify a length for the test run.
Append 'm', 'h', or 'd' to specify minutes, hours or days.
-F --fifo=<path> create a named pipe at path and write stats to it
-h --histogram=US dump a latency histogram to stdout after the run
US is the max latency time to be tracked in microseconds
This option runs all threads at the same priority.
-H --histofall=US same as -h except with an additional summary column
--histfile=<path> dump the latency histogram to <path> instead of stdout
-i INTV --interval=INTV base interval of thread in us default=1000
--json=FILENAME write final results into FILENAME, JSON formatted
--laptop Save battery when running cyclictest
This will give you poorer realtime results
but will not drain your battery so quickly
--latency=PM_QOS power management latency target value
This value is written to /dev/cpu_dma_latency
and affects c-states. The default is 0
-l LOOPS --loops=LOOPS number of loops: default=0(endless)
--mainaffinity=CPUSET
Run the main thread on CPU #N. This only affects
the main thread and not the measurement threads
-m --mlockall lock current and future memory allocations
-M --refresh_on_max delay updating the screen until a new max
latency is hit. Useful for low bandwidth.
-N --nsecs print results in ns instead of us (default us)
-o RED --oscope=RED oscilloscope mode, reduce verbose output by RED
-p PRIO --priority=PRIO priority of highest prio thread
--policy=NAME policy of measurement thread, where NAME may be one
of: other, normal, batch, idle, fifo or rr.
--priospread spread priority levels starting at specified value
-q --quiet print a summary only on exit
-r --relative use relative timer instead of absolute
-R --resolution check clock resolution, calling clock_gettime() many
times. List of clock_gettime() values will be
reported with -X
--secaligned [USEC] align thread wakeups to the next full second
and apply the optional offset
-s --system use sys_nanosleep and sys_setitimer
-S --smp Standard SMP testing: options -a -t and same priority
of all threads
--spike=<trigger> record all spikes > trigger
--spike-nodes=[num of nodes]
These are the maximum number of spikes we can record.
The default is 1024 if not specified
-t --threads one thread per available processor
-t [NUM] --threads=NUM number of threads:
without NUM, threads = max_cpus
without -t default = 1
--tracemark write a trace mark when -b latency is exceeded
-u --unbuffered force unbuffered output for live processing
-v --verbose output values on stdout for statistics
format: n:c:v n=tasknum c=count v=value in us
--dbg_cyclictest print info useful for debugging cyclictest
-x --posix_timers use POSIX timers instead of clock_nanosleep.
使用命令
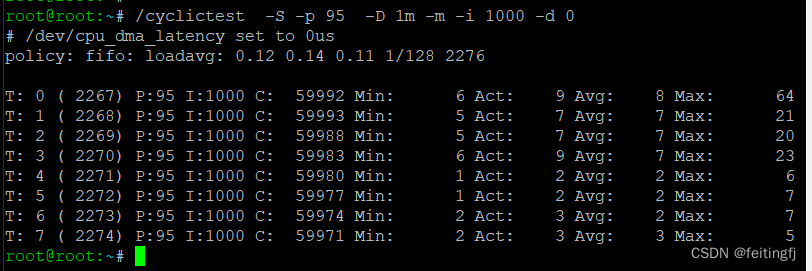
./cyclictest -S -p 95 -D 1m -m -i 1000 -d 0
./cyclictest -p 95 -D 1m -m -i 1000 -d 0 -t 10 -a 5-7
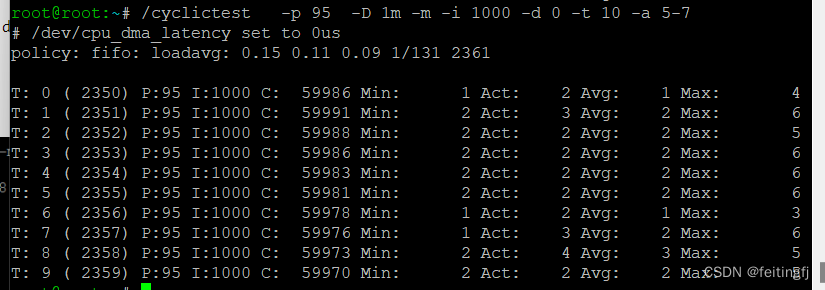
T: 线程序号
P: 线程优先级
C: 线程执行次数
I: 线程运行间隔(us)
Min: 最小延时(us)
Act: 最近一次的延时(us)
Avg:平均延时(us)
Max:最大延时(us)
参考
https://github.com/CJTSAJ/jailhouse-learning/blob/master/%E4%BA%A4%E5%8F%89%E7%BC%96%E8%AF%91cyclictest.md
https://zhuanlan.zhihu.com/p/336381111
原文地址:https://blog.csdn.net/feitingfj/article/details/134664221
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_29632.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。