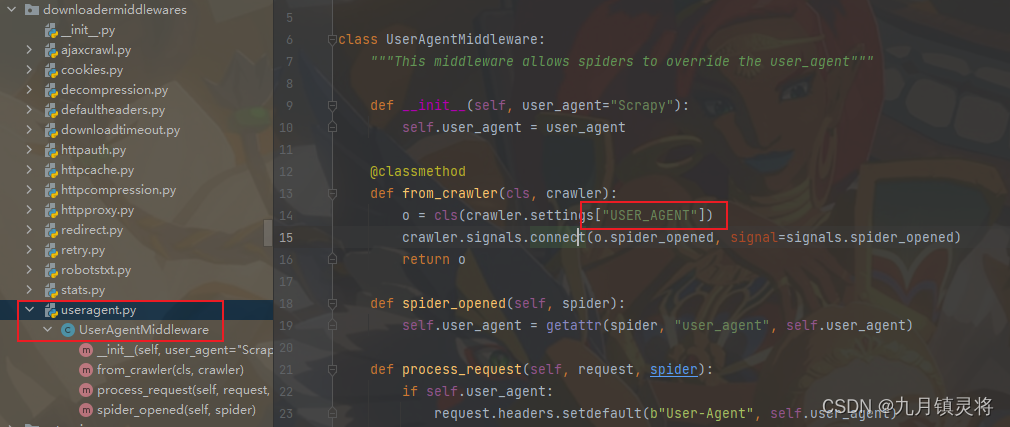
本文介绍: 先看一个内置的中间件:UserAgentMiddlewareinit: 在这里进行中间件的初始化,可以使用 settings 对象获取配置信息from_crawler:在这里通过 crawler 对象创建中间件的实例,可以获取全局配置信息spider_opened(可选): 在这里执行爬虫启动时的初始化操作,例如打开文件、连接数据库等process_request(可选): 在这里对请求进行预处理,例如修改请求头、添加代理等那么同理process_response(可选)
一、关于中间件
之前文章说过,scrapy有两种中间件:爬虫中间件和下载中间件,他们的作用时间和位置都不一样,具体区别如下:
作用: 爬虫中间件主要负责处理从引擎发送到爬虫的请求和从爬虫返回到引擎的响应。这些中间件在请求发送给爬虫之前或响应返回给引擎之前可以对它们进行处理。
作用: 下载中间件主要负责处理引擎发送到下载器的请求和从下载器返回到引擎的响应。这些中间件在请求发送给下载器之前或响应返回给引擎之前可以对它们进行处理。
只需要记住,级别越小的越接近scrapy的引擎,结合scrapy的数据流,就能记住每个中间件的作用时机。
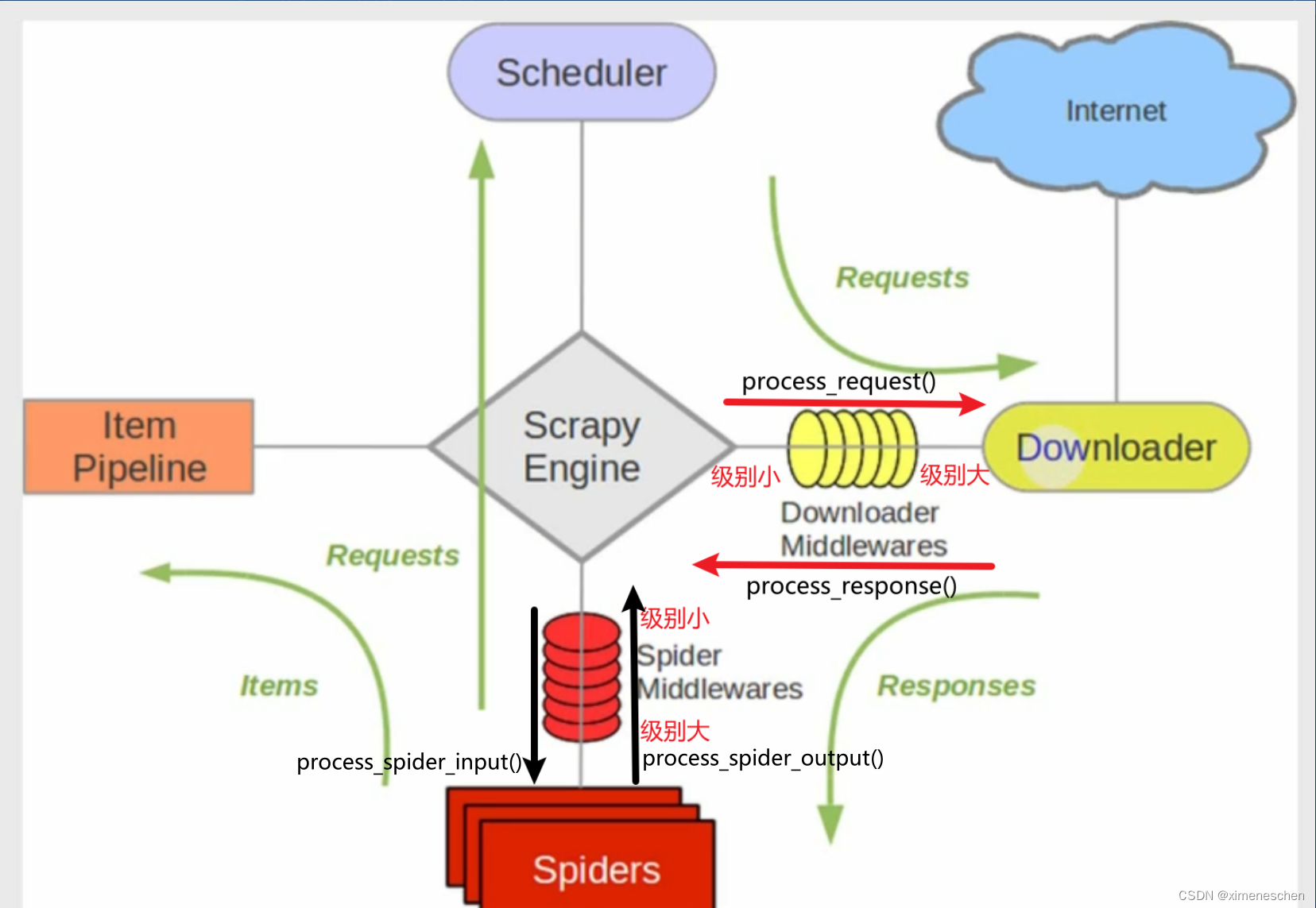
结合图可知:
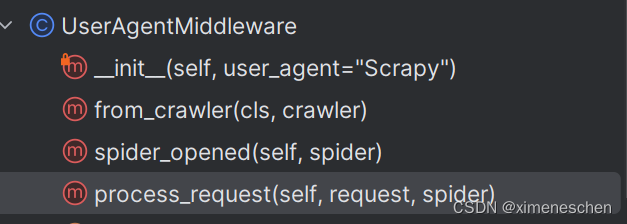
那么哪来的这些方法?
二、定义中间件的通用模板
三、位置

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。