数据归一化可以提升模型收敛速度,加快梯度下降求解速度,提升模型精度,消除量纲得影响,简化计算
常用的归一化方式有min_max标准化和Z-Score标准化
#生成dataframe格式数据
import numpy as np
import pandas as pd
data = pd.DataFrame(np.arange(12).reshape(3,4),columns = list('abcd'))
data
#数据结果:
a b c d
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
#最小最大归一化:min_max标准化
#对所有列进行归一化
min_max_norm1 = (data-data.min())/(data.max()-data.min())
min_max_norm2 = data.apply(lambda x:(x-np.min(x))/(np.max(x)-np.min(x)))
min_max_norm2
#结果:
a b c d
0 0.0 0.0 0.0 0.0
1 0.5 0.5 0.5 0.5
2 1.0 1.0 1.0 1.0
#对某一列进行归一化
data['min_max_norm_d'] = (data['d']-data['d'].min())/(data['d'].max()-data['d'].min())
data
#结果:
a b c d min_max_norm_d
0 0 1 2 3 0.0
1 4 5 6 7 0.5
2 8 9 10 11 1.0
#Z-Score 标准化 :将原来的数据转为符合均值为0,标准差为1的正态分布的新数据
z_score1 = (data-data.mean())/data.std()
z_score2 = data.apply(lambda x:(x-x.mean())/x.std())
z_score2
#结果:
a b c d min_max_norm_d
0 -1.0 -1.0 -1.0 -1.0 -1.0
1 0.0 0.0 0.0 0.0 0.0
2 1.0 1.0 1.0 1.0 1.0
#使用sklearn库中的StandardScaler()进行归一化
from sklearn import preprocessing
zscore = preprocessing.StandardScaler()
z_score = zscore.fit_transform(data)
z_score
#结果:
array([[-1.22474487, -1.22474487, -1.22474487, -1.22474487, -1.22474487],
[ 0. , 0. , 0. , 0. , 0. ],
[ 1.22474487, 1.22474487, 1.22474487, 1.22474487, 1.22474487]])
总结:
当数据本身就服从正态分布时,使用z-score;
当有离群值时,使用z-score;min-max比较容易受利群值得影响.
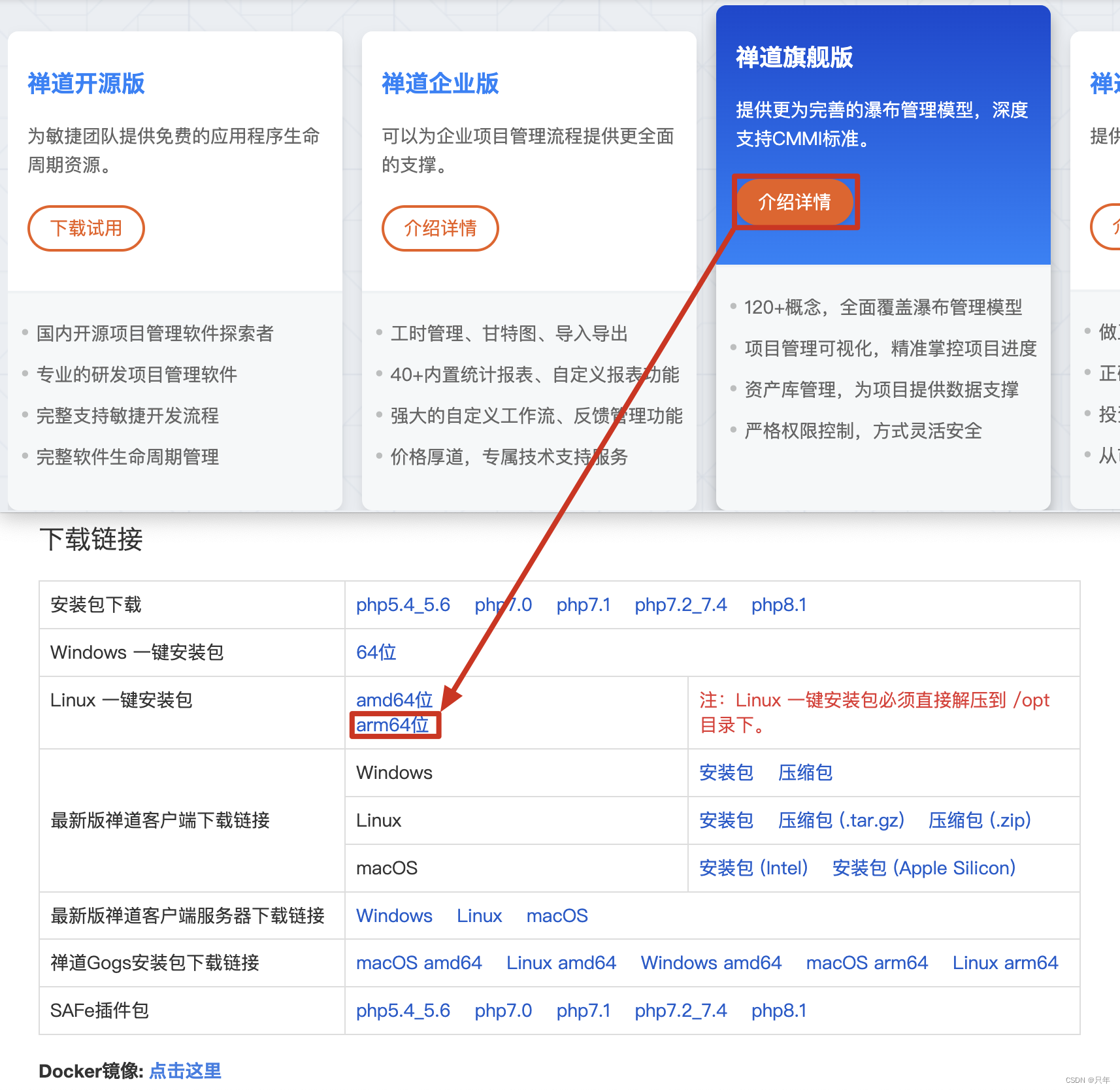
原文地址:https://blog.csdn.net/scp_6453/article/details/125589676
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_30120.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。