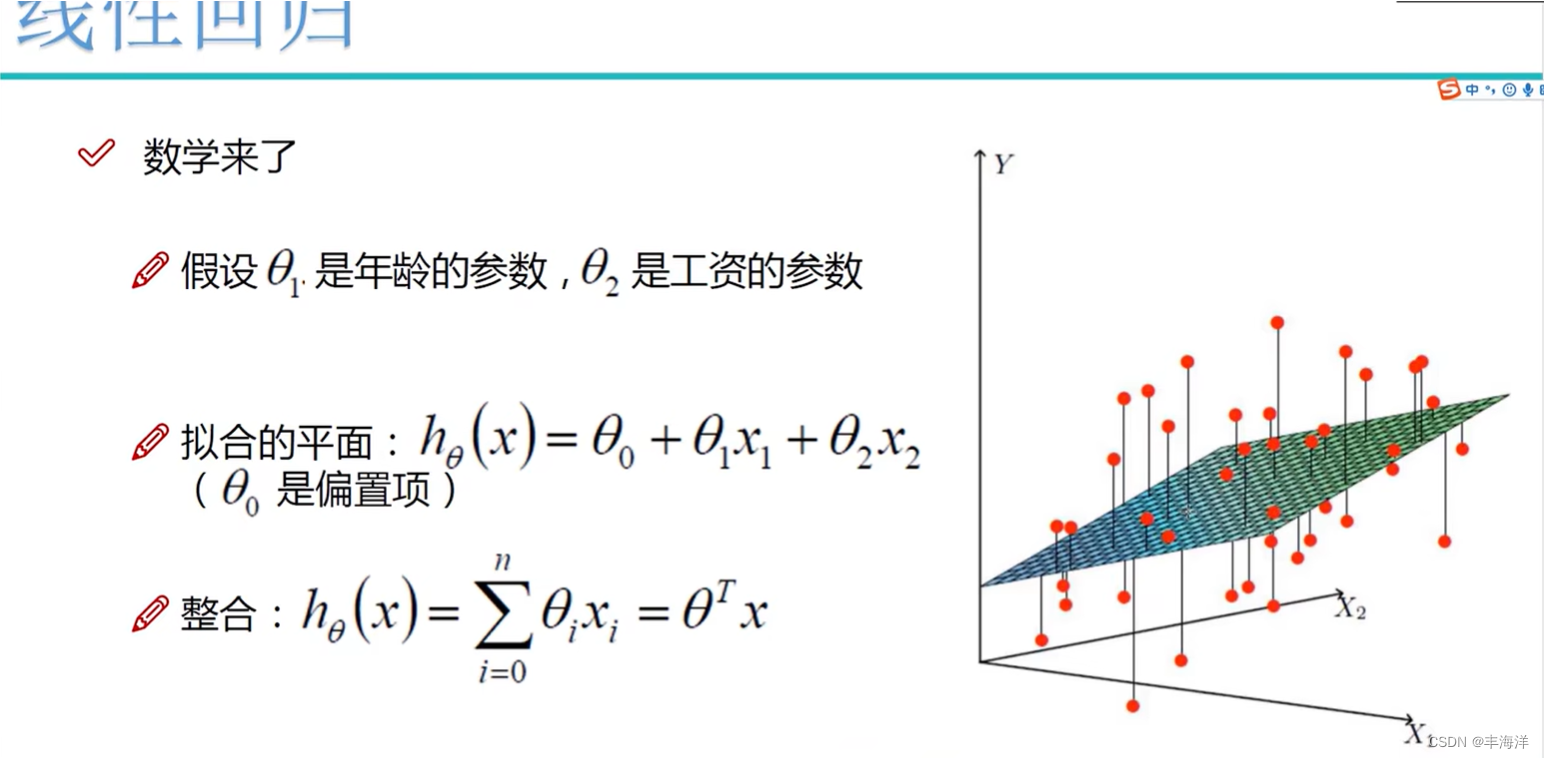
训练一个分类器是小问题

上难度

训练数据和测试数据不一致,比如训练数据是黑白的,测试时彩色的,结果准确率非常低。
训练数据和测试数据有点差距的时候,能不能效果也能好呢?这就用到了领域自使用domain adptation

用一个领域学到的知识,用到另外一个领域。
Domain Shift

- 分布频次不一样
- 标签不一致

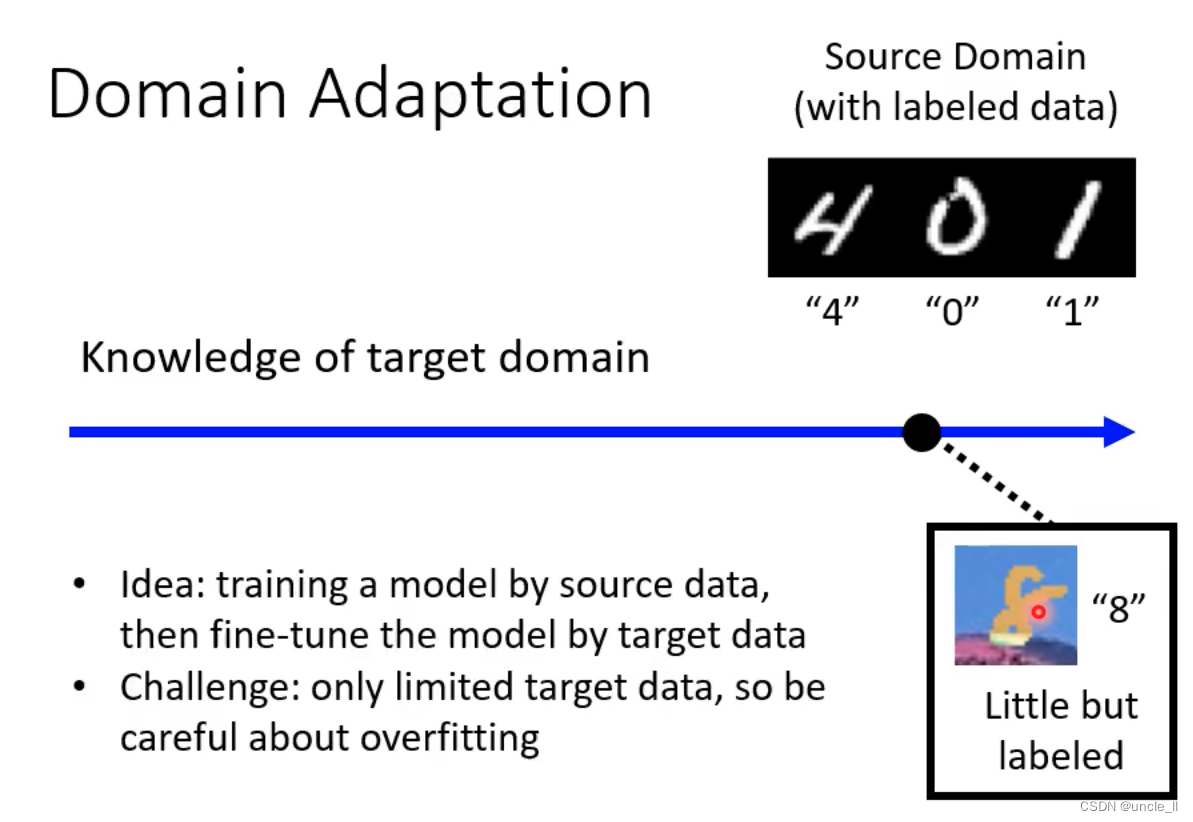

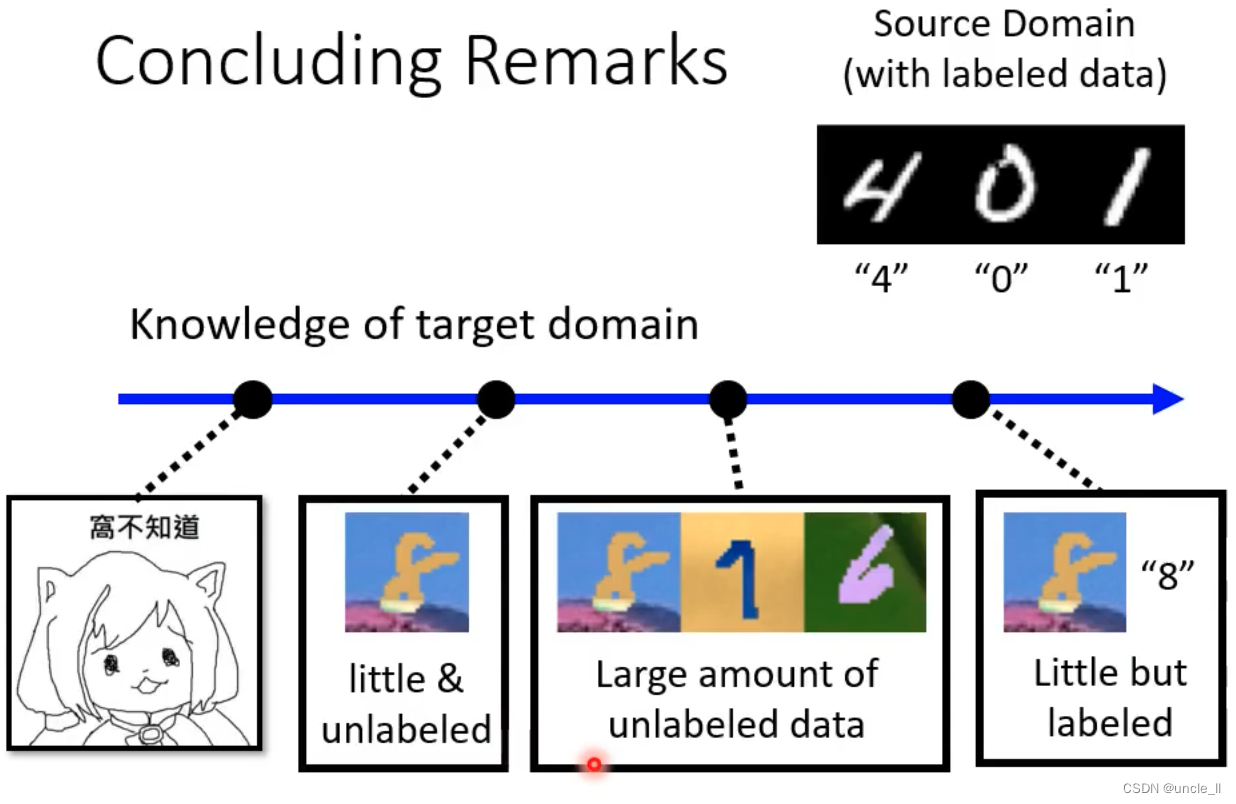
现在问题是有大量的图像,但是没有标注,怎么用这些没有标注的数据用来训练模型。
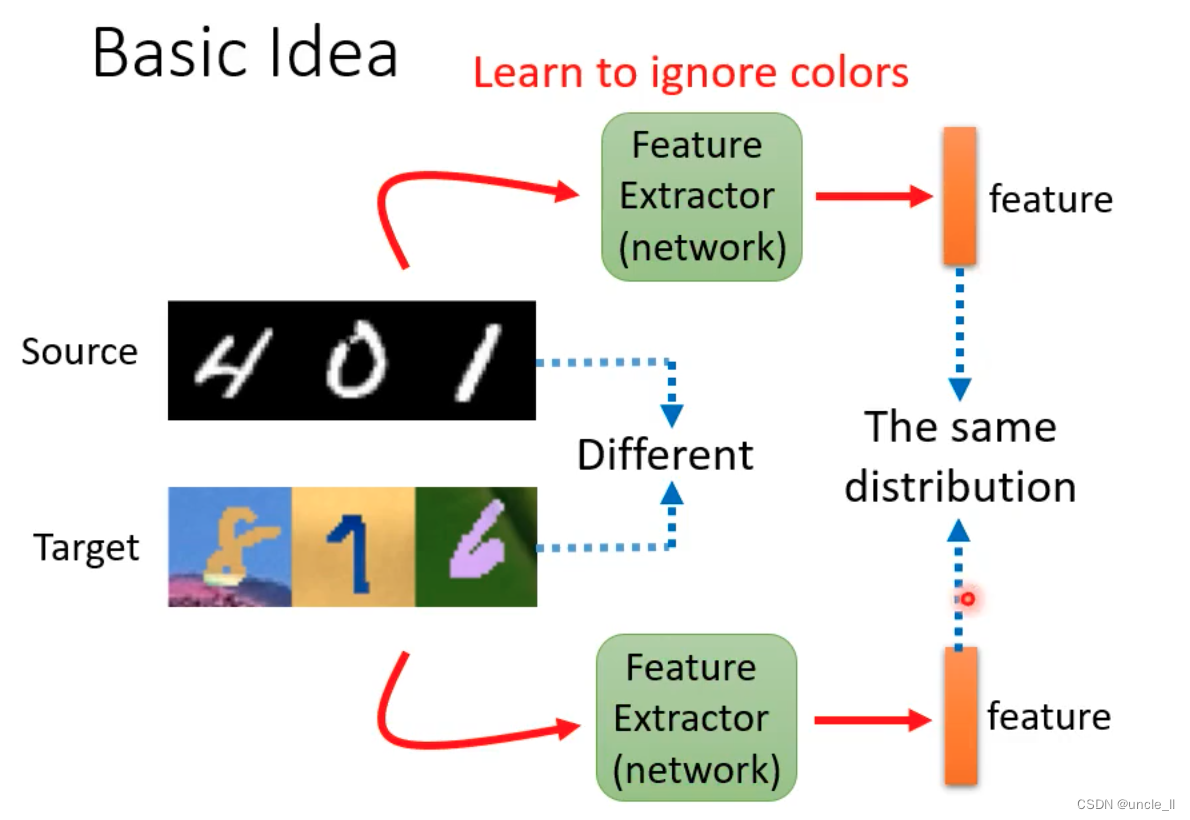
把颜色去掉,这样就能一样训练了。
Domain Adversarial Training

把前5层当作feature extractor,后5层当作label predictor。
想要有标注的数据和无标注的数据抽取后的特征在分布上没有什么差别。


Limitation



- 考虑外包围

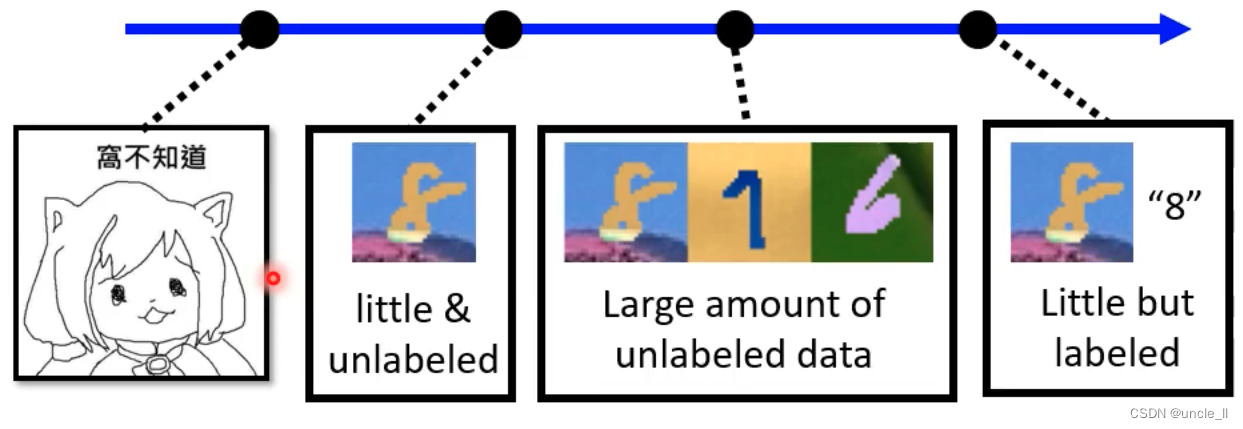
更坏的情况:
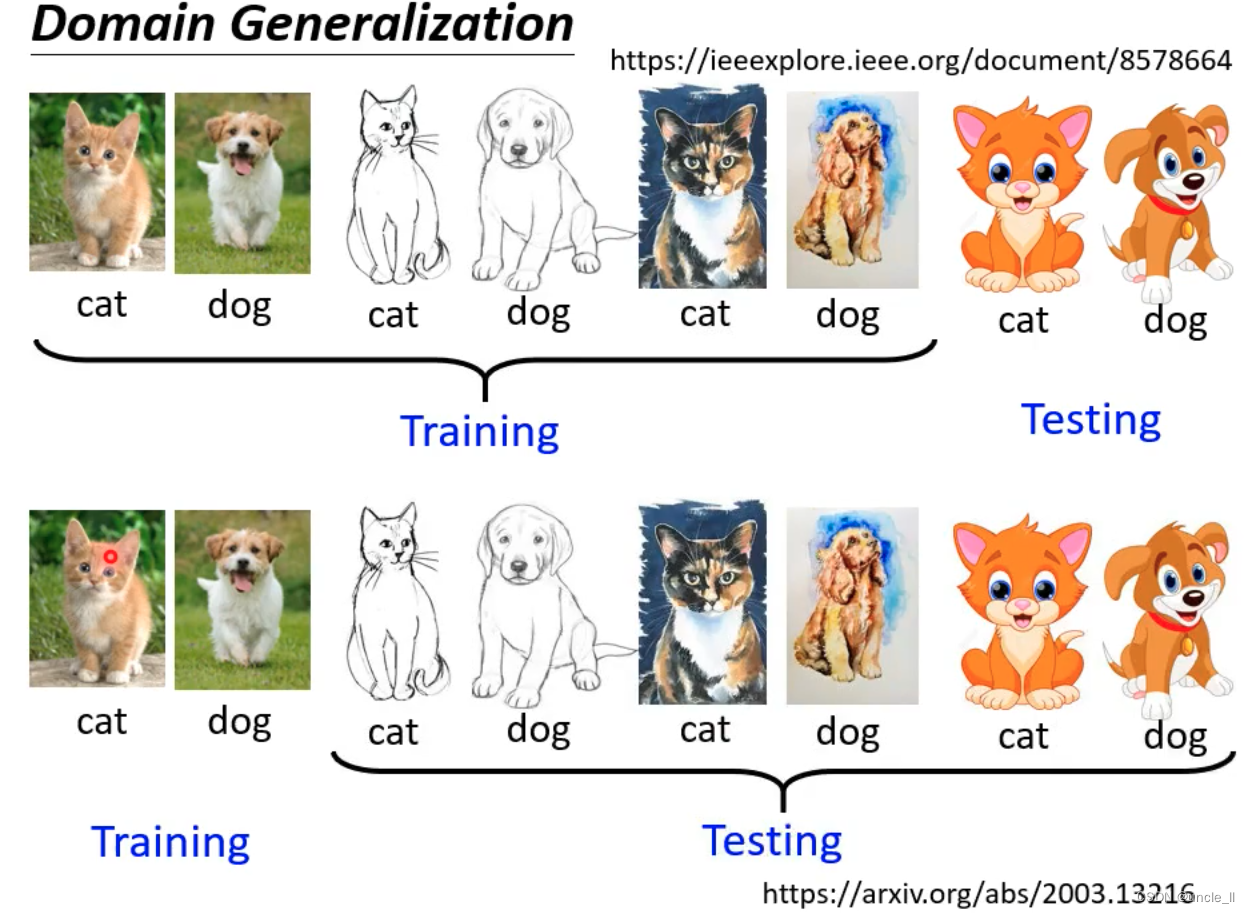
一张都不知道的话就不叫domain adaptation而是domain generalization
data aug 进行数据增强
原文地址:https://blog.csdn.net/uncle_ll/article/details/134700443
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_31104.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。