QKT)V
其中
dk表示查询和键的维度。在CoAtNet中,我们可以使用卷积操作将
V
V
V转换为
Q
Q
Q、
K
K
K和
V
V
V。
对注意力机制的输出进行处理,包括残差连接(residual connection)、层归一化(layer normalization)和前馈神经网络(feed–forward neural network)等操作。这些操作有助于提高模型的表示能力和稳定性。
3. CSV数据样例
filename,label
image_001.jpg,0
image_002.jpg,1
image_003.jpg,0
image_004.jpg,1
image_005.jpg,0
4. 数据加载与预处理
首先,我们需要加载CSV文件中的数据,并对图像进行预处理。我们将使用pandas库读取CSV文件,并使用PIL库和torchvision.transforms对图像进行预处理。
import pandas as pd
from PIL import Image
from torchvision.transforms import Compose, Resize, ToTensor, Normalize
# 读取CSV文件
data = pd.read_csv("books.csv")
# 定义图像预处理操作
transform = Compose([
Resize((224, 224)),
ToTensor(),
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# 加载图像数据
images = []
labels = []
for index, row in data.iterrows():
filename, label = row["filename"], row["label"]
image = Image.open(filename)
image = transform(image)
images.append(image)
labels.append(label)
images = torch.stack(images)
labels = torch.tensor(labels, dtype=torch.long)
5. 利用PyTorch框架实现CoAtNet模型
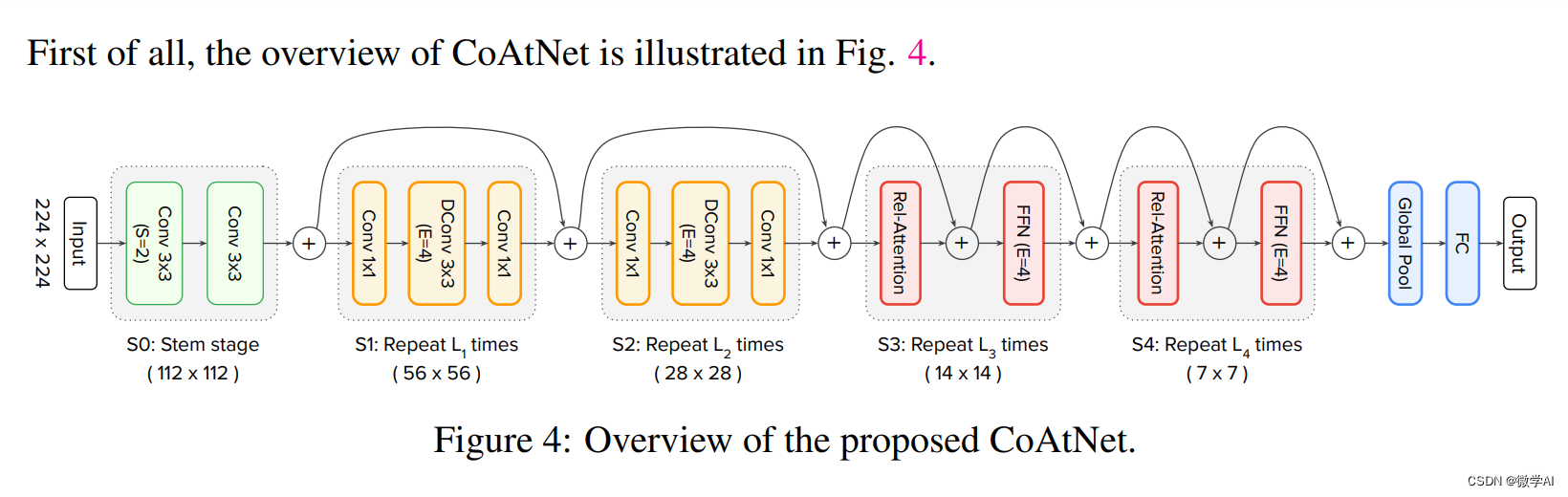
接下来,我们将使用PyTorch框架实现CoAtNet模型。首先,我们需要定义模型的基本组成部分,包括卷积层、自注意力机制和协作注意力模块。然后,我们将这些组件组合在一起,构建CoAtNet模型。
import torch
import torch.nn as nn
import torch.nn.functional as F
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding):
super(ConvBlock, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
class SelfAttention(nn.Module):
def __init__(self, in_channels, out_channels):
super(SelfAttention, self).__init__()
self.query = nn.Conv2d(in_channels, out_channels, 1)
self.key = nn.Conv2d(in_channels, out_channels, 1)
self.value = nn.Conv2d(in_channels, out_channels, 1)
def forward(self, x):
q = self.query(x)
k = self.key(x)
v = self.value(x)
q = q.view(q.size(0), q.size(1), -1)
k = k.view(k.size(0), k.size(1), -1)
v = v.view(v.size(0), v.size(1), -1)
attention = F.softmax(torch.bmm(q.transpose(1, 2), k), dim=-1)
y = torch.bmm(v, attention)
y = y.view(x.size(0), x.size(1), x.size(2), x.size(3))
return y
class CollaborativeAttentionModule(nn.Module):
def __init__(self, in_channels, out_channels):
super(CollaborativeAttentionModule, self).__init__()
self.conv_block = ConvBlock(in_channels, out_channels, 3, 1, 1)
self.self_attention = SelfAttention(out_channels, out_channels)
def forward(self, x):
x = self.conv_block(x)
x = x + self.self_attention(x)
return x
class CoAtNet(nn.Module):
def __init__(self, num_classes):
super(CoAtNet, self).__init__()
self.stem = ConvBlock(3, 64, 7, 2, 3)
self.pool = nn.MaxPool2d(3, 2, 1)
self.cam1 = CollaborativeAttentionModule(64, 128)
self.cam2 = CollaborativeAttentionModule(128, 256)
self.cam3 = CollaborativeAttentionModule(256, 512)
self.cam4 = CollaborativeAttentionModule(512, 1024)
self.avg_pool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(1024, num_classes)
def forward(self, x):
x = self.stem(x)
x = self.pool(x)
x = self.cam1(x)
x = self.cam2(x)
x = self.cam3(x)
x = self.cam4(x)
x = self.avg_pool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
6. 模型训练
在定义了CoAtNet模型之后,我们需要对模型进行训练。首先,我们将定义损失函数和优化器,然后使用训练数据对模型进行训练。
from torch.optim import Adam
from torch.utils.data import DataLoader, TensorDataset
# 划分训练集和验证集
train_size = int(0.8 * len(images))
val_size = len(images) - train_size
train_images, val_images = torch.split(images, [train_size, val_size])
train_labels, val_labels = torch.split(labels, [train_size, val_size])
# 创建DataLoader
train_dataset = TensorDataset(train_images, train_labels)
val_dataset = TensorDataset(val_images, val_labels)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)
# 初始化模型、损失函数和优化器
model = CoAtNet(num_classes=2)
criterion = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=1e-4)
# 训练模型
num_epochs = 10
for epoch in range(num_epochs):
model.train()
train_loss = 0.0
train_correct = 0
for images, labels in train_loader:
# 将数据移到GPU上(如果可用)
images = images.to(device)
labels = labels.to(device)
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 计算训练集的损失和准确率
train_loss += loss.item() * images.size(0)
_, predicted = torch.max(outputs.data, 1)
train_correct += (predicted == labels).sum().item()
# 计算平均训练损失和准确率
train_loss = train_loss / len(train_dataset)
train_acc = train_correct / len(train_dataset)
# 打印每个epoch的损失和准确率
print('Epoch [{}/{}], Train Loss: {:.4f}, Train Accuracy: {:.2f}%'.format(epoch+1, num_epochs, train_loss, train_acc*100))
7.总结
CoAtNet模型结合了卷积操作和自注意力机制,以实现高效和准确的特征提取。该模型的主要步骤包括:
3.对注意力加权的特征表示进行处理,包括残差连接、层归一化和前馈神经网络等操作。
CoAtNet模型通过将卷积和注意力机制相结合,利用卷积操作提取局部特征,利用自注意力机制捕捉全局关系,从而获得更丰富的特征表示。这种结合使得CoAtNet在图像分类等任务中具有高效性和准确性。
原文地址:https://blog.csdn.net/weixin_42878111/article/details/134753295
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_31150.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!






