1.描述性统计
Series与 DataFrame支持大量计算描述性统计的方法与操作。这些方法大部分都是 sum()、mean()、quantile()等聚合函数,其输出结果比原始数据集小;此外,还有输出结果与原始数据集同样大小的 cumsum()、 cumprod()等函数。这些方法都基本上都接受 axis 参数,如, ndarray.{sum,std,…},但这里的 axis 可以用名称或整数指定:
1.1 常用描述性统计
| 函数 | 描述 |
|---|---|
count |
统计非空值数量 |
sum |
汇总值 |
mean |
平均值 |
mad |
平均绝对偏差 |
median |
算数中位数 |
min |
最小值 |
max |
最大值 |
mode |
众数 |
abs |
绝对值 |
prod |
乘积 |
std |
贝塞尔校正的样本标准偏差 |
var |
无偏方差 |
sem |
平均值的标准误差 |
skew |
样本偏度 (第三阶) |
kurt |
样本峰度 (第四阶) |
quantile |
样本分位数 (不同 % 的值) |
cumsum |
累加 |
cumprod |
累乘 |
cummax |
累积最大值 |
cummin |
累积最小值 |
示例如下:
import pandas as pd
import numpy as np
d = {
"name":pd.Series(['小明','小黑','小红']),
'age':pd.Series([12,16,14]),
'score':pd.Series([98,90,77])
}
df = pd.DataFrame(d)
#sum求和函数,按照轴进行求和,默认是按照列轴,axis = 0
df.sum()
#设置按行求和,axis =1
df.sum(1)
# 求平均
df.mean()
# 求标准差
df.std()
# 求列最小值
df.min()
# 求列最大值
df.max()
# 求age和score列的绝对值
df[['age','score']].abs()输出结果:
name age score
0 小明 12 98
1 小黑 16 90
2 小红 14 77
#sum求和函数,按照轴进行求和,默认是按照列轴,axis = 0
name 小明小黑小红
age 42
score 265
dtype: object
#设置按行求和,axis =1
0 110
1 106
2 91
dtype: int64
# 求平均
age 14.000000
score 88.333333
dtype: float64
# 求标准差
age 2.000000
score 10.598742
dtype: float64
# 求最小值
name 小明
age 12
score 77
dtype: object
# 求最大值
name 小黑
age 16
score 98
dtype: object
# 求age和score列的绝对值
age score
0 12 98
1 16 90
2 14 771.2 数据总结:describe()
describe()函数计算Series 与 DataFrame 数据列的各种数据统计量,注意,这里排除了空值。
# 数据描述
df.describe()
# 使用include/exclude指定或排除描述的参数类型,如object,number,all等类型
df.describe(include="object")
df.describe(include="number")
df.describe(include="all")输出结果:




2. 函数的应用
不管是为 Pandas 对象应用自定义函数,还是应用第三方函数,都离不开以下三种方法。用哪种方法取决于操作的对象是 DataFrame,还是 Series ;是行、列,还是元素。
-
聚合 API: agg()与 transform()
-
元素级函数应用:applymap()
2.1 pipe()表级函数的应用
在pipe(fn,args)函数中,会将dataframe作为函数fn传入的第一个参数,args等后续参数作为函数传入的后续参数。例如下面案例中,将以df内的数据为add()传入的ele1,将2作为ele2。
示例:
# 需要将df中所有元素的内容加2
import pandas as pd
import numpy as np
def add(ele1,ele2):
return ele1+ele2
df = pd.DataFrame(np.random.randn(5,3),columns=['col1','col2','col3'])
print(df)
# pipe()
df.pipe(add,2)
print(df)原始df:


2.2 apply()行列级函数应用
apply()方法沿着 DataFrame 的轴应用函数,比如,描述性统计方法,该方法支持 axis 参数。
默认情况下,apply()方法调用的函数返回的类型会影响 DataFrame.apply 输出结果的类型。
apply(fn,axis)df.apply(np.std,axis=1) #根据水平计算输出结果:

2.3 agg();transform()聚合 API
agg()与transform()函数的用法基本相同,但transform()方法返回的结果与原始数据索引相同,大小相同。下面以agg()方法为例进行使用。
agg()应用单个函数时,该操作与apply()等效,这里也可以用字符串表示聚合函数名。例如:
df.apply(np.std)
==
df.agg(np.std)2. 多聚和模式
还可以用列表形式传递多个聚合函数。每个函数在输出结果 DataFrame 里以行的形式显示,行名是每个聚合函数的函数名。
df.agg(['sum',np.std])输出结果:

df.agg({'col1': 'mean', 'col2': 'sum','col3':'std'}) 
2.4 applymap()元素级函数应用
并非所有函数都能矢量化,即接受 NumPy 数组,返回另一个数组或值,DataFrame 的 applymap()及 Series 的 map(),支持任何接收单个值并返回单个值的 Python 函数。
例如使用applymap()对每一个元素进行乘以100的操作:
#applymap每一个元素进行操作
df.applymap(lambda x:x*100)
3. 重建索引
reindex()是 Pandas 里实现数据对齐的基本方法,该方法执行几乎所有功能都要用到的标签对齐功能。 reindex 指的是沿着指定轴,让数据与给定的一组标签进行匹配。该功能完成以下几项操作:
示例:
3.1 重建索引
reindex(index,columns,axis)其中:
index为索引值(行);
columns为列值;
import pandas as pd
import numpy as np
df = pd.DataFrame({
"a":pd.date_range(start='2020-01-01',periods=5,freq="D"),
'b':[1,2,3,4,5],
'c':[0.1,0.2,0.3,0.4,0.5]
})
df
#重建索引reIndex
df.reindex(index=[0,2,4],columns=['a','b','d'])
df初始dataframe:

重建索引后dataframe:

3.2 重置索引,填充空值
| 方法 | 动作 |
|---|---|
| pad / ffill | 先前填充 |
| bfill / backfill | 向后填充 |
| nearest | 从最近的索引值填充 |
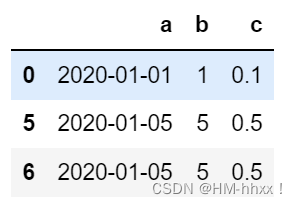
#向前填充
df.reindex(index=[0,5,6],columns=['a','b','c'],method="ffill")
3.3 重置索引,并与其它对象对齐
提取一个对象,并用另一个具有相同标签的对象 reindex 该对象的轴。这种操作的语法虽然简单,但未免有些啰嗦。这时,最好用reindex_like()方法,这是一种既有效,又简单的方式:
df1 = pd.DataFrame({
"g":pd.date_range(start='2020-01-01',periods=5,freq="D"),
'b':[1,2,3,4,5],
'c':[0.1,0.2,0.3,0.4,0.5]
})
#填充加注
df.reindex_like(df1) 
3.4 重命名索引
rename()方法支持按不同的轴基于映射(字典或 Series)调整标签。
基本语法:
df.rename(columns={'one': 'foo', 'two': 'bar'},index={'a': 'apple', 'b': 'banana'})示例:
#重命名
df1.rename(columns={'g':"ggg",'b':'hello','c':"tom"})输出结果:

4.迭代
Pandas 对象基于类型进行迭代操作。Series 迭代时被视为数组,基础迭代生成值。DataFrame 则遵循字典式习语,用对象的 key 实现迭代操作。
4.1 基础迭代for in循环
- Series :值
- DataFrame:列标签
示例:
import pandas as pd
import numpy as np
df = pd.DataFrame({
'date':pd.date_range(start='2020-01-01',periods=7,freq="D"),
'a':np.linspace(0,6,7),
'b':np.random.rand(7),
'c':np.random.choice(['Low','Medium','High'],7).tolist(),
'd':np.random.normal(100,10,size=(7)).tolist()
})
df输出结果:

#for in 循环,循环的是列
for col in df:
print(col)
print("-----------")
print(df[col])输出结果:
date
-----------
0 2020-01-01
1 2020-01-02
2 2020-01-03
3 2020-01-04
4 2020-01-05
5 2020-01-06
6 2020-01-07
Name: date, dtype: datetime64[ns]
a
-----------
0 0.0
1 1.0
2 2.0
3 3.0
4 4.0
5 5.0
6 6.0
Name: a, dtype: float64
b
-----------
0 0.528330
1 0.690732
2 0.505649
3 0.572986
4 0.543452
5 0.092484
6 0.665942
Name: b, dtype: float64
c
-----------
0 High
1 Medium
2 Medium
3 Medium
4 High
5 High
6 High
Name: c, dtype: object
d
-----------
0 94.385040
1 87.748938
2 114.945423
3 107.408004
4 91.328902
5 105.160663
6 92.128187
Name: d, dtype: float644.2 字典式item()迭代
用下列方法可以迭代 DataFrame 里的行:
-
iterrows():把 DataFrame 里的行当作 (index, Series)对进行迭代。该操作把行转为 Series,同时改变数据类型,并对性能有影响。
-
itertuples()把 DataFrame 的行当作值的命名元组进行迭代。该操作比 iterrows()快的多,建议尽量用这种方法迭代 DataFrame 的值。
4.2.1 iteritem()
示例:
#iteritem
for key,value in df.iteritems():
print(key)
print(value)
print("----------")输出结果:
date
0 2020-01-01
1 2020-01-02
2 2020-01-03
3 2020-01-04
4 2020-01-05
5 2020-01-06
6 2020-01-07
Name: date, dtype: datetime64[ns]
----------
a
0 0.0
1 1.0
2 2.0
3 3.0
4 4.0
5 5.0
6 6.0
Name: a, dtype: float64
----------
b
0 0.528330
1 0.690732
2 0.505649
3 0.572986
4 0.543452
5 0.092484
6 0.665942
Name: b, dtype: float64
----------
c
0 High
1 Medium
2 Medium
3 Medium
4 High
5 High
6 High
Name: c, dtype: object
----------
d
0 94.385040
1 87.748938
2 114.945423
3 107.408004
4 91.328902
5 105.160663
6 92.128187
Name: d, dtype: float64
----------# 取行值
for key,value in df.iterrows():
print(key)
print(value)输出结果:
0
date 2020-01-01 00:00:00
a 0
b 0.325726
c Low
d 79.9946
Name: 0, dtype: object
1
date 2020-01-02 00:00:00
a 1
b 0.507182
c Low
d 92.1191
Name: 1, dtype: object
2
date 2020-01-03 00:00:00
a 2
b 0.219389
c Medium
d 100.214
Name: 2, dtype: object
3
date 2020-01-04 00:00:00
a 3
b 0.466743
c High
d 114.725
Name: 3, dtype: object
4
date 2020-01-05 00:00:00
a 4
b 0.268522
c Medium
d 102.523
Name: 4, dtype: object
5
date 2020-01-06 00:00:00
a 5
b 0.0869462
c High
d 91.1989
Name: 5, dtype: object
6
date 2020-01-07 00:00:00
a 6
b 0.599297
c Low
d 112.741
Name: 6, dtype: object4.2.3 itertuples()
# 取行内容
for row in df.itertuples():
print(row)输出结果:

原文地址:https://blog.csdn.net/damadashen/article/details/126897040
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_32336.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!