Python基础、函数、模块、面向对象、网络和并发编程、数据库和缓存、 前端、django、Flask、tornado、api、git、爬虫、算法和数据结构、Linux、设计题、客观题、其他
第九章 Flask
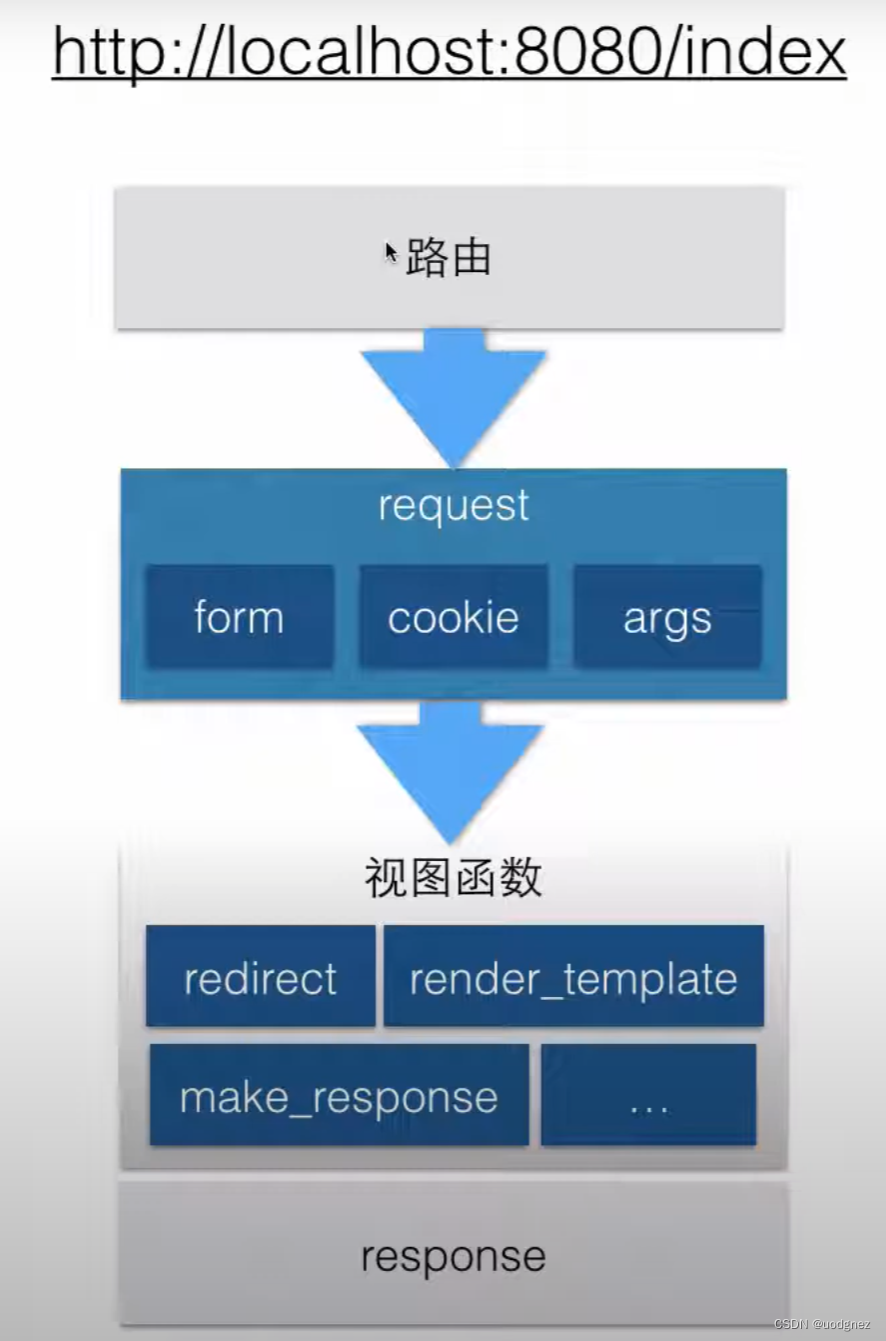
1. 请手写一个flask的 Hello World。
当你在 Flask 中创建一个简单的 "Hello World" 应用时,你需要遵循以下步骤。
首先,确保你已经安装 Flask。
如果没有安装,可以使用以下命令安装:
pip install flask
然后,创建一个新的文件(例如 `app.py`)并在其中编写以下代码:
from flask import Flask
# 创建一个 Flask 应用实例
app = Flask(__name__)
# 定义一个路由,当访问根路径时返回 "Hello, World!"
@app.route('/')
def hello_world():
return 'Hello, World!'
# 启动应用
if __name__ == '__main__':
app.run(debug=True)
保存文件后,在终端中切换到包含该文件的目录,然后运行:
python app.py
这将启动 Flask 开发服务器。你应该会在终端看到类似于以下的输出:
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
现在,你可以在浏览器中访问 [http://127.0.0.1:5000/](http://127.0.0.1:5000/),
看到 "Hello, World!" 的消息。
这是一个最简单的 Flask 应用,它创建了一个根路由并返回 "Hello, World!"。
请注意,这只是一个入门示例,实际应用中通常需要更多的配置和路由。
2. Flask框架的优势?
Flask 是一个轻量级的 Python Web 框架,具有许多优势,使其成为许多开发人员和组织的首选。
以下是 Flask 框架的一些优势:
1. **轻量级和简单:**
Flask 是一个轻量级框架,它的设计理念是保持简单易用。
它提供了核心功能,但没有过多的抽象层,允许开发者根据自己的需求选择和集成其他库。
2. **灵活性:**
Flask 不强制使用特定的 ORM、模板引擎等工具,允许开发者选择他们喜欢的工具和库。
这种灵活性使得 Flask 适用于各种类型的应用。
3. **简单易学:**
Flask 的文档清晰简洁,API 直观易懂,使得新手能够迅速入门。
学习 Flask 不需要花费过多时间,因此适用于初学者和有经验的开发者。
4. **可扩展性:**
尽管 Flask 本身很轻巧,但它提供了许多可扩展的方式。
开发者可以根据需求选择并集成适合他们项目的扩展,这使得 Flask 能够适应各种规模和类型的应用。
5. **活跃的社区:**
Flask 拥有一个庞大且活跃的社区,这意味着你可以很容易地找到解决问题的资源,
获取支持和建议。社区驱动的开发也意味着 Flask 不断更新和改进。
6. **RESTful支持:**
Flask 对构建 RESTful Web 服务提供了良好的支持。
它提供了轻松创建 RESTful API 的功能,使得开发者能够构建现代的、基于 Web 的应用程序。
7. **Jinja2 模板引擎:**
Flask 使用 Jinja2 作为模板引擎,它强大而灵活,允许开发者在视图中轻松嵌入动态内容。
8. **Werkzeug 和 Jinja2 支持:**
Werkzeug 是一个 WSGI 工具集,而 Jinja2 是一个现代的模板引擎。
Flask 使用这两者来提供灵活且高效的 Web 开发工具。
总体而言,Flask 的优势在于其简单性、灵活性和可扩展性,
使得它成为构建各种规模和类型的 Web 应用的理想选择。
3. Flask框架依赖组件?
Flask 框架本身是一个轻量级的微框架,它提供了基本的功能,但不包含大量的内建依赖组件。
然而,在实际应用中,你通常会使用一些扩展来增加功能,这些扩展可能会引入一些额外的依赖。
以下是 Flask 框架及其常用扩展可能依赖的一些组件:
1. **Werkzeug:**
Werkzeug 是一个 WSGI 工具集,是 Flask 的基础之一。
它提供了 Flask 所需的路由、中间件等核心功能。Flask 应用通常会依赖 Werkzeug。
2. **Jinja2:**
Jinja2 是 Flask 默认的模板引擎,用于渲染 HTML 模板。
虽然它被视为 Flask 的一部分,但它本身是一个独立的项目。Flask 依赖 Jinja2 来处理模板。
3. **Werkzeug 中间件:**
一些 Flask 扩展可能依赖 Werkzeug 中间件,用于处理请求和响应。
例如,`flask-session` 扩展使用 Werkzeug 提供的 `SecureCookie` 中间件来处理会话。
4. **SQLAlchemy:**
如果你在 Flask 中使用 SQLAlchemy 进行数据库操作,那么你的应用会依赖 SQLAlchemy。
SQLAlchemy 是一个独立的数据库工具,不仅仅是 Flask 的一部分。
5. **WTForms:**
如果你使用 Flask-WTF 扩展来处理 Web 表单,那么你会依赖 WTForms。
WTForms 是一个用于处理表单的独立库。
6. **Flask-Login:**
如果你使用 Flask-Login 进行用户身份验证管理,那么你会依赖 Werkzeug
提供的 `session` 对象用于管理用户登录状态。
4. Flask蓝图的作用?
Flask 蓝图(Blueprint)是一种组织 Flask 应用的方式,它能帮助你更好地管理和组织大型应用的路由、模板、静态文件等。
以下是 Flask 蓝图的一些主要作用:
1. **模块化应用结构:**
蓝图允许你将应用拆分为一些小模块,每个模块对应一个蓝图。
这样可以使应用的结构更清晰,易于维护。每个蓝图可以包含自己的路由、模板、静态文件等。
2. **路由管理:**
蓝图允许你在应用中定义一组相关的路由,并将这些路由集中在一个地方进行管理。
这有助于避免在单个文件中定义大量的路由,使代码更有组织性。
3. **可重用性:**
蓝图提供了一种将应用逻辑打包成可重用组件的方式。
你可以定义一个蓝图,并在不同的应用中重复使用它,从而促进代码的可重用性。
4. **模板和静态文件的组织:**
蓝图允许你在每个蓝图中定义自己的模板和静态文件目录。
这有助于将模板和静态文件与特定的功能或模块相关联,使得项目结构更清晰。
5. **中间件的使用:**
蓝图允许你在应用和蓝图级别使用中间件。这使得在不同部分应用中应用不同的中间件变得更加灵活。
6. **应用工厂模式:** 蓝图通常与应用工厂模式一起使用,这使得在不同的配置下
创建应用实例变得更加容易。这对于测试、开发和生产环境的切换很有用。
以下是一个简单的 Flask 蓝图的示例:
from flask import Blueprint, render_template
# 创建蓝图
example_bp = Blueprint('example', __name__)
# 定义蓝图中的路由
@example_bp.route('/')
def index():
return render_template('example/index.html')
@example_bp.route('/about')
def about():
return render_template('example/about.html')
在这个例子中,`example_bp` 是一个蓝图,它定义了两个路由。这个蓝图可以在主应用中注册,
并将其路由集成到主应用的 URL 结构中。
5. 列举使用过的Flask第三方组件?
1. **Flask-WTF:** 提供与 WTForms 集成的功能,用于处理 Web 表单。
2. **Flask-SQLAlchemy:** 与 SQLAlchemy 集成,简化了对数据库的操作。
3. **Flask-Login:** 提供用户认证功能,用于管理用户登录状态。
4. **Flask-RESTful:** 用于构建 RESTful API 的扩展,简化了 API 的创建和管理。
5. **Flask-Mail:** 用于处理邮件的扩展,简化了发送电子邮件的过程。
6. **Flask-Caching:** 提供缓存功能,用于加速应用程序的性能。
7. **Flask-Bcrypt:** 提供对 Bcrypt 哈希密码的支持,用于安全地存储密码。
8. **Flask-Migrate:** 与 Flask-SQLAlchemy 集成,用于数据库迁移。
9. **Flask-RESTPlus:** 基于 Flask-RESTful 的扩展,提供了更多的功能和工具,用于构建 RESTful API。
10. **Flask-JWT-Extended:** 提供 JSON Web Token(JWT)的支持,用于实现身份验证机制。
11. **Flask-Principal:** 用于角色和权限管理的扩展。
12. **Flask-Admin:** 提供自动生成管理界面的工具,用于管理数据库内容。
13. **Flask-Moment:** 提供日期和时间处理的功能,用于在前端格式化日期和时间。
请注意,这只是其中的一小部分。Flask 生态系统非常丰富,有许多其他有用的扩展和组件可用。
在选择使用某个扩展时,最好查看相关文档,了解其功能、用法和维护状态。
6. 简述Flask上下文管理流程?
在 Flask 中,上下文管理是一种机制,用于在应用处理请求时传递数据,而无需显式地将数据传递给每个函数。
Flask 主要有两种上下文:
应用上下文(App Context)和请求上下文(Request Context)。
### 应用上下文(App Context):
1. **创建应用上下文:**
当应用启动时,Flask 会自动创建一个应用上下文,该上下文与整个应用的生命周期相关。
2. **推送应用上下文:**
在处理请求之前,应用上下文被推送到上下文栈。这允许应用程序全局访问应用配置和其他应用级别的数据。
3. **处理请求:**
当收到请求时,Flask 会自动创建一个请求上下文,并推送到上下文栈。请求上下文包含有关当前请求的信息,如请求对象、响应对象等。
4. **处理请求时访问应用上下文:**
在处理请求期间,可以访问应用上下文中的全局变量(如 `current_app`)。
5. **请求处理完成:**
处理请求完成后,请求上下文会被弹出,且可能会触发一些清理操作(如数据库会话的提交)。
### 请求上下文(Request Context):
1. **创建请求上下文:** 在每次请求到达时,Flask 会自动创建一个请求上下文。
2. **推送请求上下文:**
请求上下文被推送到上下文栈,允许访问请求相关的信息,如请求对象、会话对象等。
3. **处理请求:**
在请求上下文中,可以访问请求对象、全局变量(如 `g` 对象)等。这些变量对于处理当前请求非常有用。
4. **处理请求时访问应用上下文:**
请求上下文中可以访问应用上下文中的全局变量,如 `current_app`。
5. **请求处理完成:**
处理请求完成后,请求上下文被弹出。在这个阶段可能会触发一些清理操作(如数据库会话的回滚)。
### 上下文管理的实例:
from flask import Flask, g, current_app, request
app = Flask(__name__)
@app.route('/')
def index():
# 在请求上下文中访问请求对象和应用上下文中的全局变量
request_data = request.url
app_name = current_app.name
# 在应用上下文中存储和访问全局变量
g.user = 'John Doe'
user = g.user
return f"Hello, {user}! This is the {app_name} app. Request data: {request_data}"
if __name__ == '__main__':
app.run(debug=True)
在上述示例中,`request` 和 `current_app` 是在请求上下文中访问的对象,
而 `g` 对象则在应用上下文中存储和访问。这些上下文在处理请求时自动推送和弹出,
使得在应用中的不同地方能够方便地访问相关信息。
7. Flask中的g的作用?
在 Flask 中,`g` 是一个用于存储在请求处理期间全局共享数据的对象。
它是一个特殊的对象,与每个请求相关联,可用于在请求处理过程中传递数据,而无需将其显式传递给每个函数。
以下是 `g` 对象的主要作用:
1. **全局变量在请求中的传递:**
`g` 对象允许在同一请求处理期间共享全局变量,而无需在每个函数之间显式传递。
这对于存储一些请求相关的临时数据非常有用。
2. **避免全局变量的污染:**
使用 `g` 对象可以避免在全局范围内定义变量,从而减少全局变量的污染和冲突。
`g` 对象只在请求期间存在,不会跨越不同的请求。
3. **线程安全:**
`g` 对象是线程安全的,每个请求都有自己的 `g` 对象实例。
这确保了在多线程环境中,每个请求都可以安全地使用 `g` 对象来存储和访问数据。
下面是一个简单的示例,演示了如何在 Flask 中使用 `g` 对象:
from flask import Flask, g, request
app = Flask(__name__)
@app.before_request
def before_request():
# 在请求之前将数据存储到g对象中
g.user = 'John Doe'
@app.route('/')
def index():
# 在请求处理期间访问g对象中的数据
user = g.user
return f"Hello, {user}!"
if __name__ == '__main__':
app.run(debug=True)
在上述示例中,`before_request` 装饰器用于在每个请求之前调用的函数,
它将数据存储到 `g` 对象中。然后,`index` 路由函数中可以访问 `g` 对象中的数据,
而无需在函数之间显式传递。
8. 如何编写flask的离线脚本?
在 Flask 中,你可以使用 Flask 的应用上下文和请求上下文来编写离线脚本。
离线脚本是指在没有 HTTP 请求的情况下执行的脚本,通常用于执行一些后台任务、数据库迁移、定时任务等。
下面是一个简单的示例,演示了如何编写一个 Flask 离线脚本:
from flask import Flask
from flask.cli import FlaskGroup
app = Flask(__name__)
# 定义一个自定义的命令组
cli = FlaskGroup(app)
@app.cli.command("my_custom_command")
def my_custom_command():
"""
一个自定义的Flask命令
"""
with app.app_context():
# 在应用上下文中执行你的逻辑
print("Executing my custom command...")
# 在这里可以访问 Flask 中的全局变量和执行任何你需要的任务
if __name__ == "__main__":
cli()
在这个例子中,我们定义了一个自定义的 Flask 命令 `my_custom_command`。
在这个命令的实现中,我们使用 `with app.app_context():`
来创建应用上下文,这样可以确保在执行任务时 Flask 应用上下文处于活动状态。
要执行这个离线脚本,你可以通过命令行运行:
python your_script_name.py my_custom_command
这样,你就可以在没有 HTTP 请求的情况下执行 Flask 中的逻辑。
在 `my_custom_command` 中,你可以访问 Flask 中的全局变量、数据库等,并执行你需要的任务。
请注意,`FlaskGroup` 是一个用于创建自定义命令组的辅助类,它提供了一种简单的方式来定义和
管理自定义命令。
9. Flask中上下文管理主要涉及到了那些相关的类?并描述类主要作用?
在 Flask 中,上下文管理主要涉及到以下几个相关的类:
1. **`Flask` 类:**
- **作用:** `Flask` 类是 Flask 应用的主类,它代表整个 Web 应用程序。
在应用中,通过实例化一个 `Flask` 对象来创建应用。
- **上下文管理:**
Flask类本身并没有直接处理上下文,但是它会协调和管理应用上下文和请求上下文的创建、推送和弹出。
2. **`AppContext` 类:**
- **作用:** `AppContext` 类表示应用上下文,用于存储应用级别的全局变量和配置。
每个请求到达时,都会创建一个新的应用上下文。
- **上下文管理:**
AppContext类的实例是通过Flask类的app_context()方法创建的,用于推送和弹出应用上下文。
3. **`RequestContext` 类:**
- **作用:** `RequestContext` 类表示请求上下文,用于存储请求相关的信息,
如请求对象、响应对象等。每个请求到达时,都会创建一个新的请求上下文。
- **上下文管理:**
RequestContext类的实例是通过Flask类的request_context()方法创建的,用于推送和弹出请求上下文。
4. **`g` 对象:**
- **作用:** `g` 对象是一个轻量级的上下文全局对象,用于在同一请求处理期间共享数据。
它允许存储和访问在请求处理过程中全局共享的变量。
- **上下文管理:** `g` 对象是在每个请求的生命周期中自动创建和销毁的,
可以通过 `app.app_context()` 和 `app.test_request_context()方法来访问 g对象。
总体而言,这些类和对象在 Flask 中共同协作,以确保在处理请求时可以轻松地存储和访问全局变量,
而无需手动传递它们。这种上下文管理机制使得在 Flask 中编写 Web 应用变得更加方便和灵活。
10. 为什么要Flask把Local对象中的的值stack 维护成一个列表?
在 Flask 中,`Local` 对象中的 `stack` 维护成一个列表的设计主要是为了处理多线程的情况。
`Local` 对象用于实现线程安全的上下文存储,确保每个线程都有自己独立的上下文,防止上下文之间的相互干扰。
在多线程的环境中,不同的线程可能会同时处理多个请求。为了确保每个请求都有独立的上下文,
并且不会与其他线程的上下文发生冲突,`Local` 使用了一个栈结构。每个线程拥有自己的
`Local` 实例,而栈结构允许在处理请求时将多个上下文推送到栈中,而不会干扰其他线程的上下文。
在 Flask 中,应用上下文和请求上下文是通过 `AppContext` 和 `RequestContext` 类的
实例表示的。当请求到达时,会创建一个新的 `AppContext` 和 `RequestContext` 对象,
并将它们推送到 `Local` 对象的栈中。这确保了每个请求都在独立的上下文中运行。
使用栈的方式也使得在处理嵌套请求时更容易管理上下文。
例如,在处理一个请求的过程中可能会触发另一个请求(如子请求或内部请求),
而栈的结构允许将新的上下文推送到栈上,而不会影响原始请求的上下文。
总的来说,使用栈的设计是为了确保 Flask 在多线程环境中能够提供安全、独立的上下文管理。
11. Flask中多app应用如何编写?
在 Flask 中,可以通过创建多个 `Flask` 应用实例来构建多个应用。每个应用可以独立运行,
拥有自己的路由、配置和上下文。
以下是一个简单的示例,演示如何在一个项目中创建多个 Flask 应用。
# app1.py
from flask import Flask
app1 = Flask(__name__)
@app1.route('/')
def hello_app1():
return 'Hello from App 1!'
# app2.py
from flask import Flask
app2 = Flask(__name__)
@app2.route('/')
def hello_app2():
return 'Hello from App 2!'
# main.py
from flask import Flask
from app1 import app1
from app2 import app2
app = Flask(__name__)
# 注册子应用
app.register_blueprint(app1, url_prefix='/app1')
app.register_blueprint(app2, url_prefix='/app2')
if __name__ == '__main__':
app.run(debug=True)
在这个示例中,我们创建了两个独立的 Flask 应用(`app1` 和 `app2`)
。然后,我们在主应用(`main.py`)中通过 `register_blueprint` 方法注册了这两个应用,
并为它们指定了 URL 前缀。这样,访问 `http://127.0.0.1:5000/app1/` 就会调用
`app1` 应用中的路由,访问 `http://127.0.0.1:5000/app2/` 则会调用 `app2` 应用中的路由。
这种方式可以用于构建多个相对独立的子应用,每个子应用可以有自己的配置、路由和视图函数。
这对于组织大型应用、将功能划分为模块或构建微服务等场景都很有用。
12. 在Flask中实现WebSocket需要什么组件?
在 Flask 中实现 WebSocket 需要使用额外的库或扩展,因为 Flask 本身并没有内置对
WebSocket 的原生支持。一个常用的库是 `Flask-SocketIO`,
它提供了在 Flask 中集成 WebSocket 的功能。
以下是在 Flask 中实现 WebSocket 的步骤:
1. **安装 Flask-SocketIO:** 使用以下命令安装 `Flask-SocketIO`:
pip install flask-socketio
2. **导入和初始化 SocketIO:** 在 Flask 应用中导入 `SocketIO` 类并初始化:
from flask import Flask, render_template
from flask_socketio import SocketIO
app = Flask(__name__)
socketio = SocketIO(app)
3. **定义 WebSocket 事件处理器:**
使用@socketio.on装饰器定义WebSocket事件处理器,例如connect和message:
@socketio.on('connect')
def handle_connect():
print('Client connected')
@socketio.on('message')
def handle_message(msg):
print(f'Received message: {msg}')
socketio.emit('message', msg) # 发送消息给所有连接的客户端
5. **在路由中集成 SocketIO:** 在路由中集成 SocketIO,以便在路由中使用 WebSocket:
@app.route('/')
def index():
return render_template('index.html')
6. **创建 WebSocket 客户端页面:** 创建一个 HTML 页面,用于测试 WebSocket 客户端:
<!-- templates/index.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>WebSocket Example</title>
</head>
<body>
<script src="https://cdnjs.cloudflare.com/ajax/libs/socket.io/3.0.3/socket.io.js"></script>
<script>
var socket = io.connect('http://' + document.domain + ':' + location.port);
socket.on('connect', function() {
console.log('Connected to the server');
});
socket.on('message', function(msg) {
console.log('Received message:', msg);
});
function sendMessage() {
var input = document.getElementById('messageInput');
var message = input.value;
socket.emit('message', message);
input.value = '';
}
</script>
<input type="text" id="messageInput" placeholder="Type a message">
<button onclick="sendMessage()">Send Message</button>
</body>
</html>
7. **运行应用:** 在应用中运行 SocketIO 服务器:
if __name__ == '__main__':
socketio.run(app, debug=True)
现在,你的 Flask 应用就支持 WebSocket 了。在浏览器中打开 `http://127.0.0.1:5000/`,
你将能够与服务器建立 WebSocket 连接,并在页面上通过输入框发送和接收消息。
请注意,上述代码只是一个简单的示例,实际中你可能需要更多的逻辑和安全性措施。
13. wtforms组件的作用?
`WTForms` 是一个在 Flask 中常用的表单处理库,用于简化 Web 表单的创建、验证和渲染。
它提供了一种声明性的方式来定义表单,使得开发者能够更轻松地处理用户提交的数据。
以下是 `WTForms` 的主要作用:
1. **表单定义:**
`WTForms` 允许开发者使用 Python 类来定义表单,类中的字段对应于表单中的输入项。
每个字段都可以附加验证器、过滤器等属性,以定义输入的规则。
2. **表单验证:**
`WTForms` 提供了强大的验证器,用于验证用户提交的数据是否符合预期的格式和规则。
这包括字符串长度、邮箱格式、整数范围等。验证器可用于确保用户输入的数据是有效和安全的。
3. **表单渲染:**
`WTForms` 可以根据表单定义生成 HTML 表单,从而简化前端页面的开发。
开发者可以通过在模板中使用表单对象的属性和方法,轻松生成表单元素、标签和错误信息。
4. **CSRF 保护:**
`WTForms` 集成了 CSRF 保护机制,以防止跨站请求伪造攻击。
它会自动在表单中生成 CSRF 令牌,并在处理表单时验证令牌的有效性。
5. **数据预处理:**
`WTForms` 允许在接收用户输入之前对数据进行预处理。
这包括去除首尾空白、将输入转换为小写等操作,以确保输入的一致性。
6. **国际化支持:**
`WTForms` 提供了对表单标签、验证错误消息等的国际化支持,使得应用能够轻松地适应不同的语言环境。
以下是一个简单的示例,展示了如何使用 `WTForms` 创建一个简单的登录表单:
from flask_wtf import FlaskForm
from wtforms import StringField, PasswordField, SubmitField
from wtforms.validators import DataRequired, Email
class LoginForm(FlaskForm):
username = StringField('Username', validators=[DataRequired()])
password = PasswordField('Password', validators=[DataRequired()])
submit = SubmitField('Log In')
在这个示例中,`LoginForm` 类继承自 `FlaskForm`,并定义了三个字段:
`username`、`password` 和 `submit`。
每个字段都附加了一个或多个验证器,以确保用户输入的数据符合要求。
在实际应用中,你可以通过在路由中实例化这个表单类,然后在模板中使用它来生成 HTML 表单。
14. Flask框架默认session处理机制?
Flask 使用基于签名的会话(session)处理机制来管理用户的会话数据。
具体来说,Flask 使用了称为 SecureCookie 的机制,通过对会话数据进行签名和序列化,
确保数据的完整性和安全性。
以下是 Flask 框架默认的会话处理机制的主要特点:
1. **Session 数据存储:**
会话数据存储在客户端的 cookie 中,通过浏览器与服务器之间的传输来传递。
这样的设计使得 Flask 的会话处理是无状态的,服务器不需要在后端存储每个用户的会话信息。
2. **数据签名:**
会话数据在存储到客户端之前会被签名,以确保数据的完整性。
签名是通过 Flask 使用的 Werkzeug 库中的 `itsdangerous` 模块实现的。
签名包括会话数据的内容和一个密钥,用于验证数据是否被篡改。
3. **安全传输:**
由于会话数据存储在客户端的 cookie 中,Flask 使用了安全的 cookie 选项,
确保会话数据只在使用 HTTPS 连接时传输。
4. **序列化:**
会话数据在存储到客户端之前会被序列化。
Flask 使用 JSON 格式对会话数据进行序列化,以便在客户端和服务器之间进行传输。
5. **密钥管理:**
为了签名和验证会话数据,Flask 使用一个密钥(secret key)。
这个密钥是在创建 Flask 应用时配置的,必须是一个足够长且随机的字符串。
密钥的安全性对于保护会话数据的完整性至关重要。
6. **过期时间:**
Flask 的会话数据可以设置过期时间,这意味着会话数据在一定时间后会自动失效。
默认情况下,会话数据在用户关闭浏览器时过期。
下面是一个简单的示例,展示了如何在 Flask 中使用默认的会话处理机制:
from flask import Flask, session
app = Flask(__name__)
app.secret_key = 'your_secret_key' # 设置密钥,用于签名会话数据
@app.route('/')
def index():
session['username'] = 'example_user' # 设置会话数据
return 'Session data set.'
@app.route('/get_session')
def get_session():
username = session.get('username') # 获取会话数据
return f'Session data: {username}'
if __name__ == '__main__':
app.run(debug=True)
在这个示例中,`session` 对象被用于存储和获取会话数据。
密钥(`secret_key`)的设置是必要的,因为它用于签名会话数据以确保安全性。
密钥应该被保持安全,不应该被泄露。在实际应用中,密钥通常会被配置为环境变量或者其他更安全的方式。
15. 解释Flask框架中的Local对象和threadinglocal对象的区别?
在 Flask 框架中,`Local` 对象和 Python 标准库中的 `threading.local` ]对象都是用于处理线程局部变量的工具,但它们有一些关键的区别。
1. **Flask 的 Local 对象:**
- `werkzeug.local.Local` 是 Werkzeug 库中的一个组件,Flask 使用它来实现上下文感知的变量。
- `Local` 对象是一种实现线程局部存储的机制,但它同时也支持在同一线程中的不同上下文中存储不同的值。
- 在 Flask 中,`Local` 对象用于存储应用上下文(`AppContext`)和
请求上下文(`RequestContext`)中的全局变量,以确保在同一线程中的不同请求和应用上下文之间隔离。
2. **Python 的 threading.local 对象:**
- `threading.local` 是 Python 标准库中的一个模块,提供了一个轻量级的线程局部存储实现。
- `threading.local` 对象是基于线程的,每个线程都有自己独立的存储空间。
它不具备 Flask 的 Local 对象的上下文感知特性,只提供了线程局部的隔离。
- 在多线程环境中,每个线程可以在 `threading.local` 对象中存储自己的数据,
而这些数据在不同线程之间是相互独立的。
总的来说,主要区别在于:
- `Local` 对象是 Werkzeug 库中的一个特殊实现,用于 Flask 中的上下文感知变量,
并且支持在同一线程中的不同上下文中存储不同的值。
- `threading.local` 对象是 Python 标准库提供的线程局部存储工具,
每个线程都有独立的存储空间,但它不具备上下文感知的特性,不能区分不同的上下文。
在 Flask 中,`Local` 对象用于实现上下文感知的全局变量,确保在不同的上下文中隔离数据。
这对于处理 Web 请求和应用上下文非常有用。
16. SQLAlchemy中的 session和scoped_session 的区别?
在 SQLAlchemy 中,`session` 和 `scoped_session` 都是用于处理数据库会话的工具,
但它们在作用范围和使用方式上有一些区别。
1. **`session`:**
- `session` 是 SQLAlchemy 中的标准会话对象。
在使用 `session` 时,你需要手动管理会话的生命周期,包括会话的创建、提交、回滚等。
- `session` 通常用于简单的脚本或非 Web 环境下,需要手动控制数据库会话的生命周期的情况。
from sqlalchemy import create_engine, Column, Integer, String, Sequence
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
engine = create_engine('sqlite:///:memory:')
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer, Sequence('user_id_seq'), primary_key=True)
name = Column(String(50))
Base.metadata.create_all(engine)
Session = sessionmaker(bind=engine)
session = Session()
user = User(name='John Doe')
session.add(user)
session.commit()
2. **`scoped_session`:**
- `scoped_session` 是 SQLAlchemy 提供的一个工具,用于在 Web 环境中处理会话的
生命周期。它通过将会话与线程相关联,自动管理会话的创建和销毁。
- `scoped_session` 可以确保在同一线程中的多个请求之间共享相同的会话实例,
而不需要手动传递会话对象。
from sqlalchemy import create_engine, Column, Integer, String, Sequence
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import scoped_session, sessionmaker
engine = create_engine('sqlite:///:memory:')
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer, Sequence('user_id_seq'), primary_key=True)
name = Column(String(50))
Base.metadata.create_all(engine)
Session = scoped_session(sessionmaker(bind=engine))
session = Session()
user = User(name='John Doe')
session.add(user)
session.commit()
总的来说,`scoped_session` 更适合在 Web 应用中使用,特别是在使用多线程或多进程的情况下,
它可以确保在同一线程或进程中共享相同的会话实例。在非 Web 环境中,直接使用 `session`
是更直观和简单的选择。
17. SQLAlchemy如何执行原生SQL?
SQLAlchemy提供了多种执行原生SQL语句的方法,其中最常用的方法之一是使用 `execute` 方法。
这个方法可以在 `Engine` 对象上调用,该对象代表了数据库连接。
以下是一个简单的示例,演示了如何使用 `execute` 方法执行原生SQL语句:
from sqlalchemy import create_engine
# 创建数据库连接引擎
engine = create_engine('sqlite:///example.db')
# 获取数据库连接
connection = engine.connect()
# 执行原生SQL查询
result = connection.execute('SELECT * FROM users')
# 获取查询结果
for row in result:
print(row)
# 关闭数据库连接
connection.close()
在这个例子中,`engine` 是通过 `create_engine` 函数创建的,表示与数据库的连接。
然后,通过 `engine.connect()` 获取数据库连接。接下来,使用 `execute` 方法执行
原生SQL查询,并迭代结果集以获取数据。最后,使用 `close` 方法关闭数据库连接。
另一种执行原生SQL的方法是通过 `text` 函数创建一个 `text` 对象,然后调用 `execute` 方法。这种方法更常用于包含参数的SQL语句。以下是一个示例:
from sqlalchemy import create_engine, text
# 创建数据库连接引擎
engine = create_engine('sqlite:///example.db')
# 获取数据库连接
connection = engine.connect()
# 执行带参数的原生SQL查询
sql_query = text('SELECT * FROM users WHERE id = :user_id')
result = connection.execute(sql_query, user_id=1)
# 获取查询结果
for row in result:
print(row)
# 关闭数据库连接
connection.close()
在这个例子中,`text` 函数用于创建一个 `text` 对象,该对象包含原生SQL查询。
然后,调用 `execute` 方法执行查询,并通过关键字参数传递参数值。
18. ORM的实现原理?
ORM(对象关系映射)的实现原理涉及到数据库和编程语言对象之间的映射,
使得开发者可以使用面向对象的方式来操作数据库,而不必直接编写SQL语句。
以下是ORM的基本实现原理:
1. **对象模型与数据库表的映射:**
- ORM通过定义模型类,将程序中的对象与数据库中的表进行映射。
每个模型类对应数据库中的一张表,类的属性对应表的列。
- 模型类通常通过继承基类,基类提供了对数据库的访问方法,包括增、删、改、查等操作。
2. **类属性与表列的映射:**
- 类的属性通常对应数据库表中的列。ORM需要能够识别类属性与数据库列的映射关系,
包括属性的数据类型、长度、是否唯一等信息。
- 数据库表结构的信息可以通过模型类的元类或其他方式进行收集和定义。
3. **SQL生成与执行:**
- 当使用模型类进行查询时,ORM会根据查询的需求生成相应的SQL语句。
这包括查询条件、排序、分组等。
- ORM负责将生成的SQL语句传递给数据库执行引擎,并获取执行结果。
4. **结果集与对象实例的映射:**
- 当数据库引擎返回查询结果时,ORM会将结果集映射为模型类的实例,
使得开发者可以直接操作对象而不必处理原始的数据库记录。
- 映射的过程包括实例化对象、将结果集中的数据赋值给对象属性等。
5. **事务管理:**
- ORM通常提供了事务管理的机制,确保对数据库的操作要么全部成功,要么全部失败。
事务管理包括事务的开始、提交、回滚等操作。
6. **关联关系的处理:**
- ORM支持处理数据库中表之间的关联关系,包括一对一、一对多、多对多等关系。
通过在模型类中定义关联关系,ORM可以自动生成相应的查询语句。
7. **性能优化:**
- 为了提高性能,ORM通常提供了缓存机制、延迟加载(Lazy Loading)等特性。
缓存可以存储已经查询过的对象,避免重复查询。延迟加载可以在需要时才加载关联对象的数据。
具体的ORM实现方式和细节因不同的ORM库而异,但基本原理是类似的。
常见的Python中的ORM库包括 SQLAlchemy、Django ORM 等。
19. DBUtils模块的作用?
`DBUtils` 是一个用于管理数据库连接池的Python模块。它提供了一组工具和接口,
用于创建和管理数据库连接,以便在多线程或多进程的环境中更有效地使用数据库连接。
主要作用包括:
1. **连接池管理:**
`DBUtils` 允许你创建和管理数据库连接池,以避免在每次数据库操作时都重新建立连接。
连接池维护一组数据库连接,并在需要时提供给应用程序。
2. **连接的重用:**
连接池可以重复使用已经建立的数据库连接,避免了反复连接和断开的开销,提高了数据库操作的效率。
3. **连接的回收:**
连接池可以监测并回收不再使用的连接,防止长时间未使用的连接占用数据库资源。
4. **线程和进程安全:**
`DBUtils` 提供了线程安全和进程安全的连接池实现,确保在多线程或多进程环境中正确地共享数据库连接。
5. **不同数据库的支持:**
`DBUtils` 可以与不同的数据库后端一起使用,例如 MySQL、PostgreSQL、SQLite 等。
使用 `DBUtils` 的一般步骤如下:
1. **创建连接池:**
使用DBUtils提供的连接池类(例如PooledDB)创建连接池,并指定连接参数(如数据库地址、用户名、密码等)。
2. **从连接池获取连接:** 当需要执行数据库操作时,从连接池中获取一个数据库连接。
3. **执行数据库操作:** 使用获取的数据库连接执行数据库操作(查询、插入、更新等)。
4. **释放连接:** 在完成数据库操作后,将连接释放回连接池,以便其他地方可以重用。
示例代码:
from DBUtils.PooledDB import PooledDB
import pymysql
# 创建连接池
pool = PooledDB(pymysql, 5, host='localhost', user='user', passwd='password', db='database', port=3306)
# 从连接池获取连接
conn = pool.connection()
# 执行数据库操作
cursor = conn.cursor()
cursor.execute('SELECT * FROM table')
result = cursor.fetchall()
# 释放连接
cursor.close()
conn.close()
在这个示例中,`PooledDB` 创建了一个连接池,`pool.connection()` 获取了一个连接,
然后可以使用这个连接执行数据库操作。在完成操作后,通过 `close()` 方法将连接释放回连接池。
20. 以下SQLAlchemy的字段是否正确?如果不正确请更正.
在这里插入代码片
21. SQLAchemy中如何为表设置引擎和字符编码?
在 SQLAlchemy 中,你可以使用 `create_engine` 函数的参数来为表设置引擎和字符编码。
具体来说,你可以使用 `create_engine` 的 `connect_args` 参数来传递一些特定于数据库的
参数,其中包括设置引擎和字符编码的选项。
以下是一个示例,演示了如何在创建 SQLAlchemy 引擎时设置 MySQL 数据库的引擎和字符编码:
from sqlalchemy import create_engine, Column, Integer, String, MetaData
from sqlalchemy.ext.declarative import declarative_base
# 定义模型类
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String(255))
# 设置 MySQL 数据库的引擎和字符编码
engine = create_engine(
'mysql+mysqlconnector://username:password@localhost/dbname',
connect_args={'charset': 'utf8mb4'},
echo=True # 如果你想打印SQL语句,可以设置为True
)
# 创建表
Base.metadata.create_all(engine)
在上述示例中:
- `connect_args={'charset': 'utf8mb4'}` 将字符编码设置为 `utf8mb4`,
这是一种支持更广泛字符集的 MySQL 字符编码。
- `mysql+mysqlconnector://username:password@localhost/dbname` 是连接字符串,
其中包含用户名、密码、主机和数据库名等信息。
请注意,具体的引擎和字符编码的设置可能会因数据库类型而异。
上述示例是针对 MySQL 数据库的设置,如果使用不同的数据库类型,你需要适当调整连接字符串和参数。
22. SQLAchemy中如何设置联合唯一索引?
在 SQLAlchemy 中,你可以使用 `UniqueConstraint` 类或 `Index` 类来设置联合唯一索引。
下面是使用这两个方法的示例:
### 使用 `UniqueConstraint`:
from sqlalchemy import create_engine, Column, Integer, String, UniqueConstraint
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String(255), nullable=False)
email = Column(String(255), nullable=False)
# 设置联合唯一索引
__table_args__ = (
UniqueConstraint('name', 'email', name='uix_name_email'),
)
# 创建引擎和表
engine = create_engine('sqlite:///:memory:')
Base.metadata.create_all(engine)
# 创建一个用户对象并插入到数据库中
Session = sessionmaker(bind=engine)
session = Session()
user = User(name='John Doe', email='john.doe@example.com')
session.add(user)
session.commit()
在这个示例中,`UniqueConstraint` 用于定义一个联合唯一索引,它包含了表中的 `name`
和 `email` 两列。索引的名字是 `uix_name_email`。
### 使用 `Index`:
from sqlalchemy import create_engine, Column, Integer, String, Index
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String(255), nullable=False)
email = Column(String(255), nullable=False)
# 创建引擎和表
engine = create_engine('sqlite:///:memory:')
Base.metadata.create_all(engine)
# 创建一个联合唯一索引
Index('uix_name_email', User.name, User.email, unique=True)
# 创建一个用户对象并插入到数据库中
Session = sessionmaker(bind=engine)
session = Session()
user = User(name='John Doe', email='john.doe@example.com')
session.add(user)
session.commit()
在这个示例中,`Index` 用于创建一个联合唯一索引,也包含了 `name` 和 `email` 两列。
索引的名字是 `uix_name_email`,并且通过 `unique=True` 设置为唯一索引。
你可以根据自己的需求选择使用其中的一种方法。
无论使用哪种方法,都要确保定义索引的列不允许为空,以保证索引的唯一性。
23. 简述tornado框架特点及应用场景。
Tornado 是一个Python的异步Web框架和异步网络库,具有以下特点:
1. **异步非阻塞:**
Tornado 使用了非阻塞的异步I/O模型,基于事件循环(Event Loop)实现,
允许高并发的处理请求。这使得 Tornado 在处理大量连接时表现出色。
2. **轻量级:**
Tornado 是一个相对轻量级的框架,专注于处理Web请求和构建异步网络应用。
它的核心功能集中,没有过多的依赖,使其易于学习和使用。
3. **Web框架和网络库一体化:**
Tornado 不仅仅是一个Web框架,同时也是一个强大的异步网络库。
这使得它在构建WebSocket应用、长连接等方面非常有优势。
4. **支持协程:**
Tornado 支持协程(coroutines),使得异步编程更加方便。
通过 `gen.coroutine` 装饰器,可以使用协程写出看起来同步的代码,而实际上是异步执行的。
5. **安全性:**
Tornado 对安全性有良好的支持,包括对跨站脚本攻击(XSS)和请求伪造(CSRF)的防护。
6. **长轮询和WebSocket支持:**
Tornado 提供了对长轮询(long polling)和WebSocket的原生支持,使得构建实时应用变得简单。
7. **扩展性:**
Tornado 支持中间件机制,可以通过插入中间件来扩展其功能。
它还可以与其他异步库(如异步数据库驱动)结合使用。
8. **应用场景:**
Tornado 适用于构建高性能、高并发的Web应用和实时应用,
特别在需要处理大量连接的场景下表现出色,如实时通信、推送服务、在线聊天等。
总的来说,Tornado适用于那些需要高性能异步处理的应用场景,
特别是在需要保持高并发连接的实时Web应用中,例如在线游戏、聊天应用、实时消息推送等。
原文地址:https://blog.csdn.net/weixin_44145338/article/details/134676867
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_32706.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。