1.下拉框操作
(1)按普通元素定位
安装普通元素的定位方式来定位下拉框,使用元素的操作方法element.click()方法来操作下拉框内容的选择
(2)使用Select()类
Select()封装了3种可以查找下拉框选项的方法,实现对下拉框选项的选择,不用在进行点击动作,找到就直接选中了
定位到下拉框元素 driver.find_element_by_xxx(‘XXX’)
实例化下拉框选项类 select= Select(element)
select.select_by_index(‘选项下标‘)
select_by_visible_text(‘选项的文本内容‘)
2.滚动条操作
Selenium没有对于滚动条的相关处理类或者方法,但是Selenium提供了其他脚本语言的执行方法,所以我们可以使用其他脚本语言来实现对滚动条的操作,再使用Selenium的execute_Script()方法调用这个实现语句,执行对滚动条的操作。
# 导包
from time import sleep
from selenium import webdriver
# 实例化浏览器对象
driver = webdriver.Chrome()
# 打开浏览器
driver.get('https://www.baidu.com')
# 展示效果
sleep(1)
# 浏览器窗口最大化
driver.maximize_window()
# 隐式等待
driver.implicitly_wait(10)
sleep(2)
driver.find_element_by_id('kw').send_keys('Test')
driver.find_element_by_id('su').click()
sleep(2)
# 设置JS脚本控制滚动条(左边距,上边距),将JS代码作为字符串,传参给excuse_sctipt()方法
js1 = "window.scrollTo(0,2000)"
js2 = "window.scrollTo(0,0)"
# 执行JS脚本,利用selenium提供的执行脚本方法excuse_script()
driver.execute_script(js1)
sleep(2)
driver.execute_script(js2)
sleep(2)
# 关闭浏览器
driver.quit()3.弹窗处理
(1)为什么要进行弹窗处理
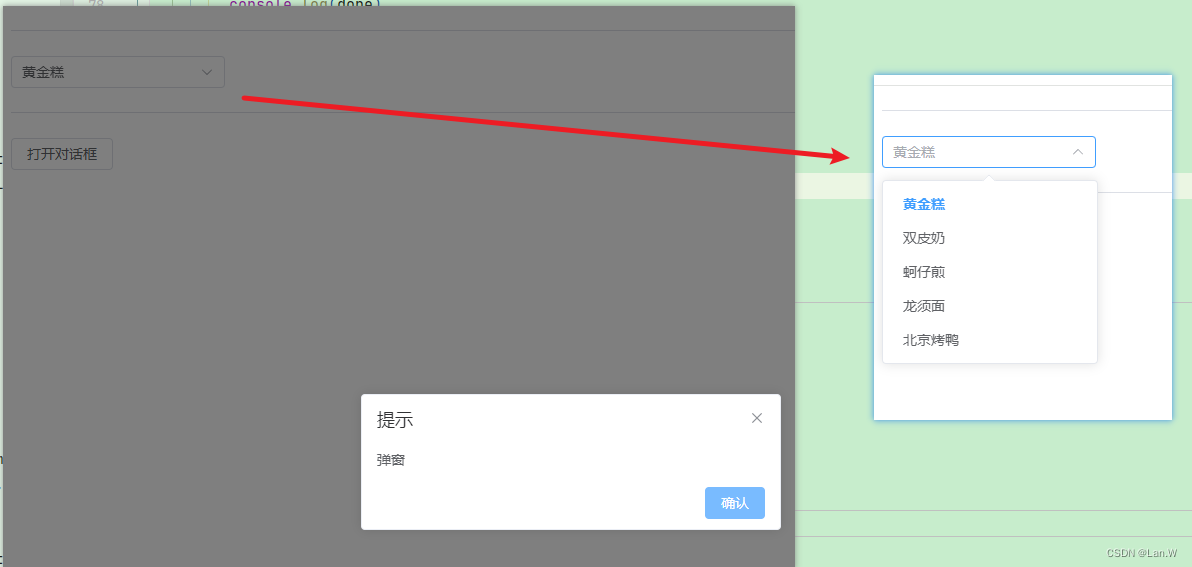
在项目中有些特殊页面,需要在用户进行了错误操作或遗漏了某些操作时,进行弹窗提示。例如:博客写完没保存,用户就想离开页面会关闭浏览器。
这里说的弹窗是通过页面右键没有“检查“选项的那种浏览器弹窗,如下图。不是指前端写的具备风格的、可以定位到的那种。

当这种弹窗弹出的时候,如果不对它进行处理,是不可以再继续进行页面操作的,不管是选择确认还是选择取消,都要处理。
(2)弹窗有哪几种
警告类:alert,只是警告用户遗漏了操作,用户可以选择继续操作或取消操作留在当前页面
确认类:confirm,用户进行了有风险的操作,或者浏览器想要进行某种操作需要用户允许。
业务流程类:需要用户输入内容来判断页面给出哪种操作,例如,输入密码才能显示某些内容。
(3)怎样处理弹窗
以上提到的弹窗,在Selenium中统一被称为alert类,处理思路如下:
alert = driver.switch_to.alert 提示:没有括号
②对弹窗进行操作
4.切换Frame
(1)为什么要切换frame
有些项目,页面部署分为多个模块,每个模块实现不同的功能区,通常会把这些模块写成不同的frame。或者在接收到用户的特定操作后,弹出一个处理弹窗,这个弹窗通常也会写成一个单独的frame。
例如CSDN的登录功能,当没有登录的用户在首页点击登录时,弹出一个登录窗。在这个登录窗口上右键“检查“,沿层级向上查找,我们就可以看到,这个窗口全部封装在一个叫做 iframe的模块标签里。
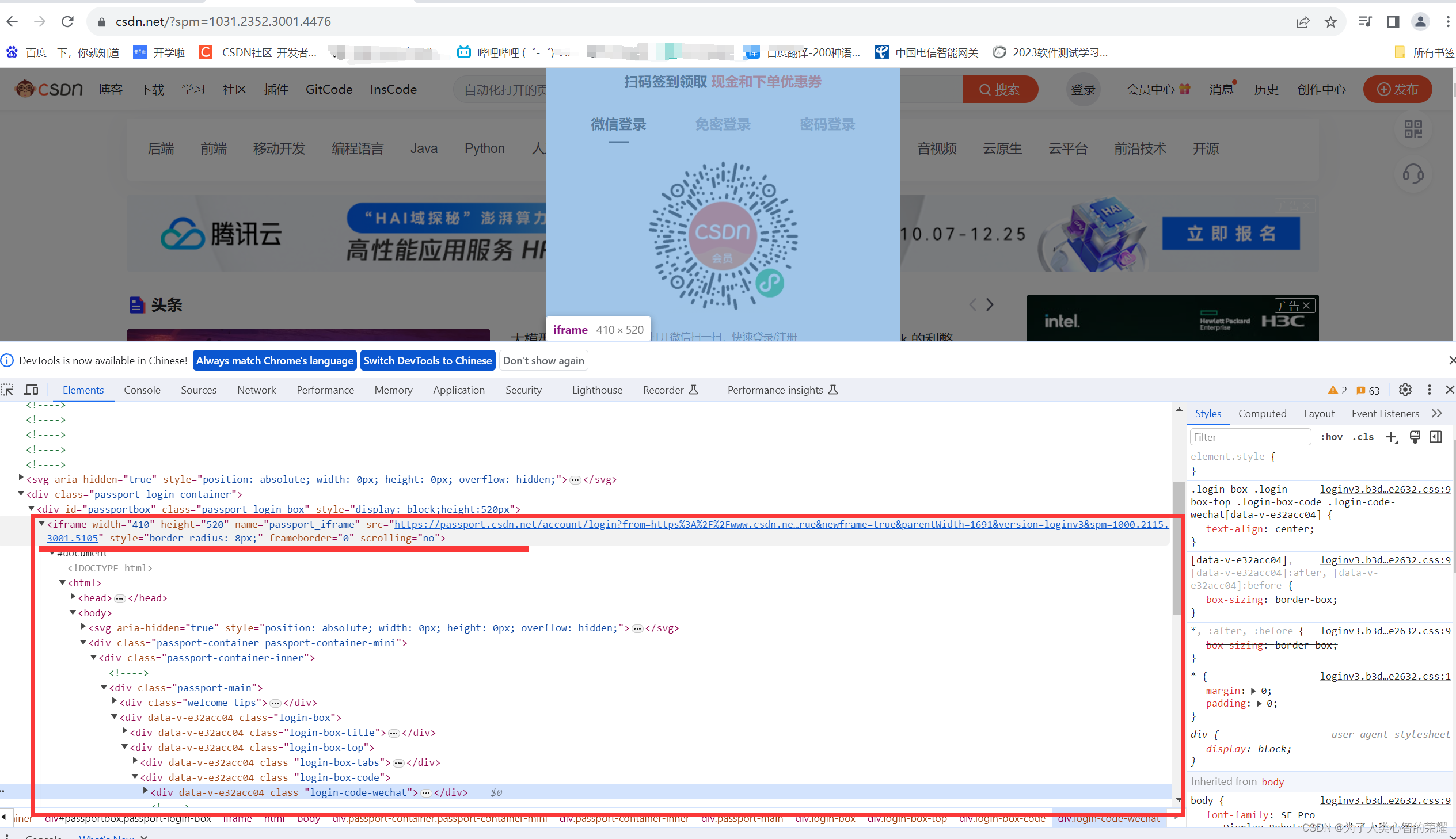
当遇到这类页面时,采用普通定位方法去定位元素时,我们就会发现,写的代码绝对没有问题,但是就是找不到报错。就是因为我们在进入页面时,操作对象在这个页面的默认frame里,不同的frame是存在隔绝的,如果页面出现了除了默认frame之外的frame,我们在默认frame里是看不到里面的内容的。
(2)怎样实现frame切换
①定位iframe,找到frame的属性(id,name,xpath或CSS)
②driver.swicth_to.frame(id/name/element) 参数值可以是唯一标识frame的id值、name值、也可以是一个元素对象driver.find_element_by_XXX(XXX)
用一个实例理解一下:一个页面好比是一栋房子,多个frame就像这个房子的多个房间,每个房间之间有墙隔开,只能通过门相互进出。我们使用get方法打开这个页面,就像进入一个房子的时候会默认进客厅(一个公共区域),在客厅里我们没办法拿到卧室的东西,也看不到卧室有什么。想要进卧室拿东西就要打开卧室门进去,driver.swicth_to.frame()就是开门进入卧室这个动作。那么我们进入卧室拿到了想要的东西以后还想进厨房怎么办呢?就要先从卧室出来,回到公共区域,在从公共区域打开厨房门进入厨房。
所以当页面有多个frame,想要实现两个frame之间的切换,就要先从frame回到默认模块driver.switch_to.default_content() 再从默认模块进入另一个frame。
# 进入frame1,以下三种写法都可以
driver.switch_to.frame('frame1_id')
driver.switch_to.frame('frame1_name')
driver.switch_to.frame(driver.find_element_by_xpath('//*[@frame1_key="value"]'))
# 回到公共区域模块
driver.switch_to.default_content()
# 再进入frame2,写法与进入frame1相同,都有三种
driver.switch_to.frame('frame2_id')
5.切换窗口
(1)为什么要切换窗口
真实的业务流程:用户进行了某些操作,打开了一个新的标签页,接下来的功能要在这个新的标签页中进行。
这些标签页在当前的大多数的浏览器中都看起来是在一个窗口打开的,其实这是浏览器提供的显示功能,实际上这些标签页每一个都是一个新的窗口,只是浏览器为了提升用户体验,将它整合显示在了一个窗口内。
用户在真人体验的时候,浏览器会自动把新的窗口打开在最上层供用户操作。但是在自动化代码执行时,如果我们没有进行窗口切换动作,代码的操作对象永远都只能停留在初始页面,新打开的窗口内容我们永远无法进行操作。
(2)怎样实现窗口切换
在这里引入一个句柄的概念:句柄是浏览器窗口的唯一标识,叫做handle。
既然句柄能唯一标识一个窗口,那么我们进行窗口切换的时候,就可以使用句柄作为切换的依据。
①获取当前页面句柄: driver.current_window_handle ,返回值是当前页面的句柄值
②获取全部页面的句柄: driver.window_handles ,返回值是一个列表,列表内容为当前打开的全部页面的句柄值,顺序与页面打开顺序相同。
③因为我们只打开了两个页面,不是当前页,就是我们要切换的窗口。遍历handles列表,判断是否为当前页句柄,如果不是,则执行切换窗口动作.driver.switch_to.window(handle)
④如果想要切回之前那个页面怎么办呢?把现在这个页面当做当前页,再执行以上3个步骤就可以了。
(3)多个窗口之间互相切换,要怎样实现
上面我们说的是两个窗口切换,如果我们打开了N个页面怎么办呢?
我们知道,driver.window_handles的返回值是一个列表,列表就可以使用下标来获取列表中的值。
利用列表的特性,我们就可以知道driver.switch_to.window(handle_list[-1]),打开的永远是最新的那个页面,driver.switch_to.window(handle_list[0])打开的永远是第一个页面,依次类推,想要跳转切换到哪一个页面就找到它打开的顺序,使用列表定位到它的handle传参给driver.switch_to.window()就可以打开指定页面啦。
代码示例
# 获取当前页面handle并打印出来
print(driver.current_window_handle)
# 获取所有打开窗口的句柄并打印
print(driver.window_handles)
# 切换到最新窗口
driver.switch_to.window(driver.window_handles[-1])
# 切换到第一个窗口
driver.switch_to.window(driver.window_handles[0])
# 切换到第四个窗口
driver.switch_to.window(driver.window_handles[3]) # 列表下标从0开始扩展
如果我们切换到最新页面,完成应有的操作之后,关闭当前页面,再操作其他页面,可以直接操作吗?
我们可以用以下代码试一下:
# 导包
from time import sleep
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.support.wait import WebDriverWait
# 实例化浏览器对象
driver = webdriver.Chrome()
# 打开浏览器
driver.get('https://www.baidu.com')
# 浏览器窗口最大化
driver.maximize_window()
# 隐式等待:通常设置10s
driver.implicitly_wait(10)
sleep(2)
# 在百度首页打开新闻页
driver.find_element_by_link_text('新闻').click()
sleep(5)
# 切换到新闻页
driver.switch_to.window(driver.window_handles[-1])
# 关闭新闻页
driver.close() # 此时百度首页就成了最新的页面,我们试一下能不能操作
# 在百度首页,搜索框输入“test”
driver.find_element_by_id('kw').send_keys('test')
sleep(2)
# 关闭浏览器
driver.quit()执行代码以后我们可以看到,代码报错no such window: target window already closed
也就是说,我们的操作对象还是新闻页,没有自动切换到百度首页,在新闻页查找百度搜索框,但是页面已经被关闭了,所以报错

所以,即使关闭了当前页,再去其他页面进行操作的时候依然要切换。
# 导包
from time import sleep
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.support.wait import WebDriverWait
# 实例化浏览器对象
driver = webdriver.Chrome()
# 打开浏览器
driver.get('https://www.baidu.com')
# 浏览器窗口最大化
driver.maximize_window()
# 隐式等待:通常设置10s
driver.implicitly_wait(10)
sleep(2)
# 在百度首页打开新闻页
driver.find_element_by_link_text('新闻').click()
sleep(5)
# 切换到新闻页
driver.switch_to.window(driver.window_handles[-1])
# 关闭新闻页
driver.close()
# 切回百度首页
driver.switch_to.window(driver.window_handles[-1])
"""
因为我并没有使用变量接收driver.window_handles的结果,
每次使用driver.window_handles,都会重新获取handle_list,跟页面打开与关闭都无关
不管之前关闭了多少页面或打开多少新页面,driver.window_handles获取的都是在执行这一语句时,打开页面的全部句柄
"""
# 因为关闭了新闻页,所以百度首页就是当前最新的页面,所以使用driver.window_handles[-1]可以获取它的句柄
# 因为我们只打开了两个页面,百度首页此时既是最新页又是第一个页面。所以driver.window_handles[0]也可以获取它的句柄
# 在百度首页,搜索框输入“test”
driver.find_element_by_id('kw').send_keys('test')
sleep(2)
# 关闭浏览器
driver.quit()
6.验证码处理
(1)直接规避
验证码这个功能,本身就是防自动化爬虫的,所以自动化测试可以说没啥必要正验证码。一般在测试环境中最简单直接的处理方式就是把这个功能干掉,发布之前再加上。
(2)使用万能验证码
如果项目已经上线了,不能屏蔽掉验证码功能,可以设置的一个万能码。
请开发配合,将万能码写在项目验证码的判断逻辑里,不管明面上显示的是什么验证码,只要输入提前约定的万能码,验证都可以通过。
这个方法需要注意的一点就是保证万能码保密,不要流出,否则会造成巨大损失。
(3)使用python插件
python有一个测试图片验证码的框架Python_tesseract,但是这个图像识别技术并不是100%成功。
(4)使用cookie绕过验证码
客户端登录账号后将登录状态相关的cookie信息,发送给服务器保存, 再次发送请求,携带的cookie信息,如果和登录状态一致,服务器默认登录成功
提前手动登录,获取cookie值,然后使用这个cookie值绕过登录,直接进行功能测试。
如何查看cookie值:F12(开发者工具)-Application–cookie
cookie的值具体包含在页面的哪一个字段,需要向开发询问,或者自行手动登录一下,对比登录前后多了哪一个字段。百度的cookie在BDUSS字段。
注意:使用cookie时要保证有一个浏览器处于登录项目的状态,不能退出,一旦退出则cookie失效。任何一个浏览器都可以,不一定是我们用来测试的这个,只要打开登录着就行。
代码示例:
# 实例化浏览器对象
driver = webdriver.Chrome()
# 打开浏览器
driver.get('https://www.baidu.com')
# 展示效果
sleep(1)
# 浏览器窗口最大化
driver.maximize_window()
# 隐式等待
driver.implicitly_wait(10)
sleep(2)
# 实现需求
cookie_value = {'name': 'BDUSS',
'value': 'ZaaVlTRUZ0ZWZaOXBBQ0JZLXV-NDhFQkRhTnhzfmQ1MDFmcWktR3RMeVA0SVpsRVFBQUFBJCQAAAAAAAAAAAEAAAA1c09WwfjD98LlAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAI9TX2WPU19lak'}
driver.add_cookie(cookie_value)
driver.refresh()
sleep(2)
# 关闭浏览器
driver.quit()好啦,关于Web自动化相关的基础知识,到这里我们就学习结束啦。后边就是学习测试框架的内容啦。再接再厉哟~~~。
发帖的全部内容是博主自学后整理的笔记,如果有错漏,希望各位小伙伴指正!!!
原文地址:https://blog.csdn.net/Chrisliuluo/article/details/134676234
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_34498.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!