pandas读取文件
pandas.DataFrame 设置索引
pandas.DataFrame 读取单行/列,多行多列
pandas.DataFrame 添加行/列
利用pandas处理表格类型数据,快捷方便,不常用但是有的时候又是必要技能,在这里记录一下一些常用函数和自己的踩坑经验
1、导入包
import pands as pd
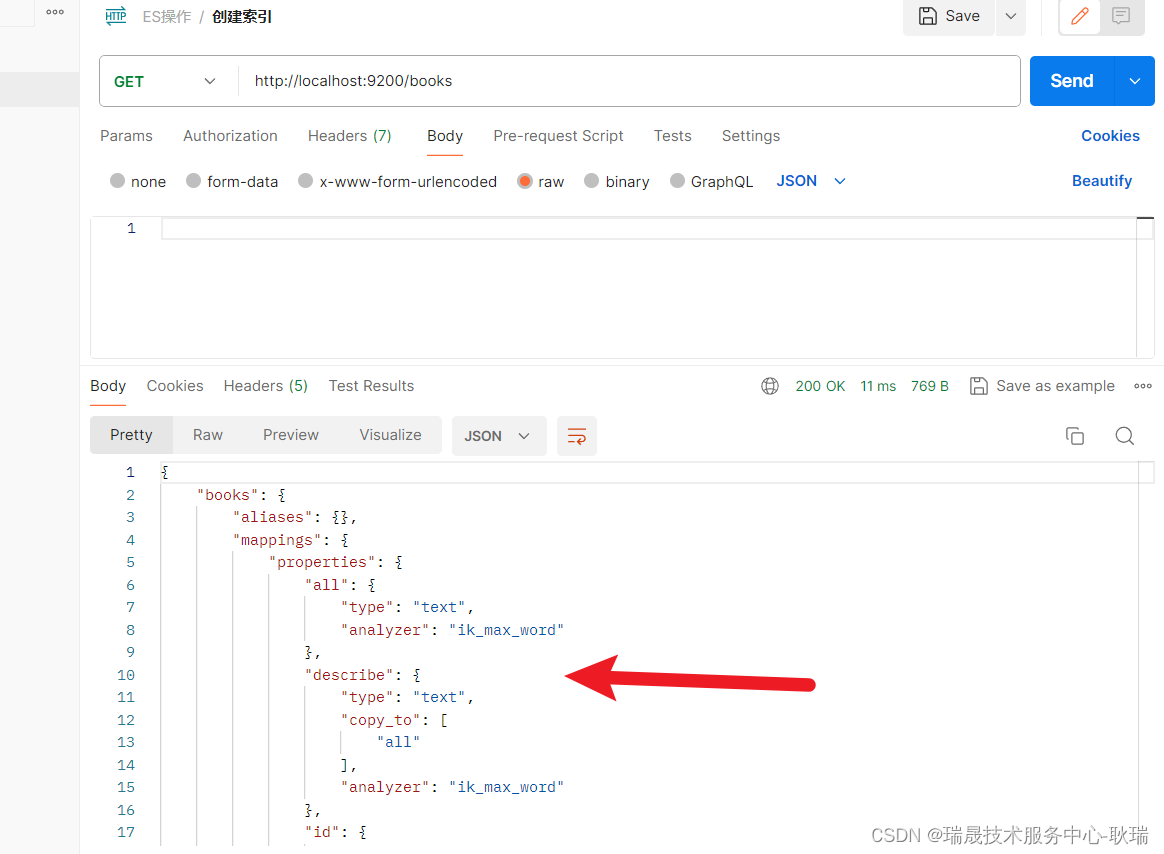
2、读取文件,并设置行、列索引,常用的存储表格数据为.csv 或 .excel格式
这里设置的文件格式为.csv
文件名及文件原始内容:pandas_test.csv ,

import pands as pd
file_path = r'pandas_test.csv'
df = pd.DataFrame(pd.read_csv(file_path)) # 简单读入,并将第一行作为表头
# df1 = pd.DataFrame(pd.read_csv(file_path, header=None)) # 简单读入,**不要将第一行作为表头**
# df2 = pd.DataFrame(pd.read_csv(file_path, index_col=3)) # 读入数据,并指定第3列作为行索引
print(df)
a b c d # 默认将第一行设置为表头
0 1 z x e
1 2 x h wd
2 3 f j x
3 4 k s j
print(df1)
0 1 2 3 # 设置不将第一行设置为表头
0 a b c d
1 1 z x e
2 2 x h wd
3 3 f j x
4 4 k s j
print(df2)
a b c # 读入数据,并指定第4列作为行索引
d
e 1 z x
wd 2 x h
x 3 f j
j 4 k s
3、完成读取后,若想再设置行列索引,或者更改
3.1 设置某一行为列索引【表头】
# 设置某一行为列索引【表头】
c_list = df.values.tolist()[1] # 得到想要设置为列索引【表头】的某一行提取出来
df.columns = c_list # 设置列索引【表头】
df.drop([1], inplace=True) # 将原来的那一行删掉。
# 这里的inplace=True,表示就在df这个数据表中进行修改,默认是False
print(df)
2 x h wd
0 1 z x e
2 3 f j x
3 4 k s j
# df_new = df.drop([1]) # 如果是默认的话,做出的修改就要将修改后的内容赋予新的变量才能呈现出和上面一样的效果
# print(df_new)
3.2 设置某一列为行索引
# 设置某一列为行索引
df.set_index('c', inplace=True) # 设置表头为"c"的那一列为行索引
print(df)
a b d
c # 这里看着这个c单独占一行很不爽,不过后面写入文件保存时会和表头对齐,就不纠结它了
x 1 z e
h 2 x wd
j 3 f x
s 4 k j
3.3 对列索引/表头重命名
# 对列索引【表头】重命名
df.rename(columns={"c": "c_new", "a": "a_x"}, inplace=True)
print(df)
a_x b c_new d
0 1 z x e
1 2 x h wd
2 3 f j x
3 4 k s j
4、行列索引
4.1 取某一列/行【单列,单行】
4.1.1 按数字索引
col = df.iloc[:, 1] # 按数字索引取第2列
row = df.loc[1, :] # 按数字索引取第2行
# 注意:这里取出来的内容还是pands中的数据格式,如果要取得具体的内容,需要加上.values
print(df)
a b c d
0 1 z x e
1 2 x h wd
2 3 f j x
3 4 k s j
==========================================================
print(type(col))
<class 'pandas.core.series.Series'>
print(col)
0 z
1 x
2 f
3 k
Name: b, dtype: object
print(col.values)
['z' 'x' 'f' 'k']
==========================================================
print(row)
a 2
b x
c h
d wd
Name: 1, dtype: object
print(row.values)
[2 'x' 'h' 'wd']
4.1.2 按指定索引(非数值型索引)
col = df["b"] # 取出列索引为"c"的列
row = df.loc["x"] # 取出行索引为"x"的行
print(col)
c
x z
h x
j f
s k
Name: b, dtype: object
print(row)
a 1
b z
d e
Name: x, dtype: object
4.1.2 通过切片索引
row1 = df[0:1] # 通过切片索引,取得第1行
print(row1)
a b c d
0 1 z x e
4.2 取多行多列
4.2.1 仅取多行
# 取多行
# 1、直接取
此用法需要注意,[]里面一般为列名,表示取某一列,若列名以列表的形式放入[],则可以去多列;单选列结果为Series,多选列结果为Dataframe。选取列名不能超出源数据列名,不然报错
若为数值时,默认取行,且只能进行切片操作,不能单独选择,输出结果为Dataframe,即便只选择一行。df[]不能通过索引标签名来选择行(df['x'])
rows = df[0:2] # 取第1~2行
print(rows)
a b c d
0 1 z x e
1 2 x h wd
# 2、用 .loc 取
.loc[]用法是根据标签名来定位,默认用法是df.loc[行标签(多个用列表),列标签(多个用列表)],如果只提取列,则行标签位置用:代替
rows1 = df.loc[0:2] # 取第1~3行
print(rows1)
a b c d
0 1 z x e
1 2 x h wd
2 3 f j x
4.2.2 仅取多列
# 1、直接取
cols = df[["a","b"]] # 注意,取多列时记得把列名以列表格式放入
print(cols)
a b
c
x 1 z
h 2 x
j 3 f
s 4 k
==========================================================
# 2、.loc
cols1 = df.loc[:, ["a","b"]] # 想取出**指定**的多列时用这个
print(cols1) # 取"a","b"两列
a b
c
x 1 z
h 2 x
j 3 f
s 4 k
cols2 = df.loc[:, "a":"b"] # 通过切片取出多列时用这个
# 注意,通过这样切片时,"a":"b"是左右包含的
print(cols2)
a b
c
x 1 z
h 2 x
j 3 f
s 4 k
==========================================================
# 3、.iloc
# 与.loc[]用法的区别是,该方法通过行列的位置*(数字)*来定位,从0开始计,左闭右开。
cols3 = df.iloc[:, 0:2] # 取前两列
print(cols3)
a b
c
x 1 z
h 2 x
j 3 f
s 4 k
4.2.3 同时取多行多列
# 1、 .loc
df1 = df.loc[["x", "h"], ['a', 'd']] # 用列表指定行列
print(df1)
a d
c
x 1 e
h 2 wd
df2 = df.loc["x": "h", 'a': 'd'] # 通过切片取
print(df2)
a b d
c
x 1 z e
h 2 x wd
========================================================
# 2、 .iloc
df3 = df.iloc[1:3, 0:2]
print(df3)
a b
c
h 2 x
j 3 f
5、加入行/列
print(df)
a b d
c
x 1 z e
h 2 x wd
j 3 f x
s 4 k j
==========================================================
# 加入列
col = df.iloc[:, 1] # 先按数字索引取第2列,作为添加的内容
# 1、在最后一列后面加入一列
df["e"] = col # 直接通过[]添加一列,并将第2列作为新的一列加入原来的数据中;
# 这里注意新的列名和之前原有的不要重复,否则会修改原有的那一列内容,而不是添加新的一列
print(df)
a b d e
c
x 1 z e z
h 2 x wd x
j 3 f x f
s 4 k j k
--------------------------------------------------------
# 2、在指定位置加入一列
# df.insert(添加列位置索引序号,添加列名,数值,是否允许列名重复)
df.insert(1, "i", col, allow_duplicates=True)
print(df)
a i b d e
c
x 1 z z e z
h 2 x x wd x
j 3 f f x f
s 4 k k j k
======================================================================
# 加入行
row_add = df.loc["x"] # 取出行索引为"x"的一行作为新加入的内容
# 1、.loc
df.loc["w"] = row_add # 在最后一行后加入一行索引为"w"的内容
print(df)
a i b d e
c
x 1 z z e z
h 2 x x wd x
j 3 f f x f
s 4 k k j k
w 1 z z e z
--------------------------------------------------------
# 2、.append
df4 = df.append(row_add) # 把上面取出的一行直接加入到最后一行后面
print(df4)
a i b d e
c
x 1 z z e z
h 2 x x wd x
j 3 f f x f
s 4 k k j k
x 1 z z e z
df4 = df.append(row_add, ignore_index=True) # 如果不想要原来的行索引,可以加入这个参数
print(df4)
a i b d e
0 1 z z e z
1 2 x x wd x
2 3 f f x f
3 4 k k j k
4 1 z z e z
原文地址:https://blog.csdn.net/Admiral_x/article/details/126415277
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_34642.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。