看过电视剧《开端》的都知道,处在循环中是多么让人崩溃的事情,循环可以制造问题,但循环同样可以解决问题。现在我们要讲的这个案例就是利用循环来实现的。
案例说明:有一个excel文档,一列记录的是文件名,另一列记录的是文件中要填充的文件内容。需要读取对应的文件内容,存入对应的表名中。
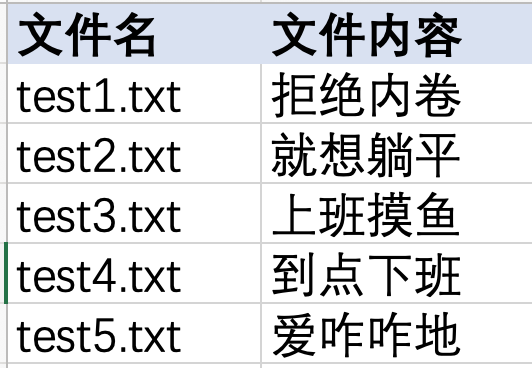

想要实现最后的结果,首先是需要循环读取文件内容,然后是把读取到的内容循环存入文件。要强调的是这里涉及到的循环并不是嵌套循环,而是两轮独立的循环。
下面是用pandas实现过程
import pandas as pd
excel_file='/Users/airc/Desktop/TEST.xlsx'
target_path='/Users/airc/Desktop/目标文件夹/'
read_excel=pd.read_excel(excel_file,sheet_name='输出文件内容')
print(read_excel)print结果

错误示范
新手往往会这么去遍历和储存,这么单看好像并没有问题,因为确实’a‘的值就是遍历出来所有文件名,file存储的时候,也并没有报错,但是最后一看结果就炸了。
table_name=read_excel['文件名']
table_content=read_excel['文件内容']
for a in table_name:
print(a)
for b in table_content:
file=open(target_path+a,'w+')
file.write(b)
file.close()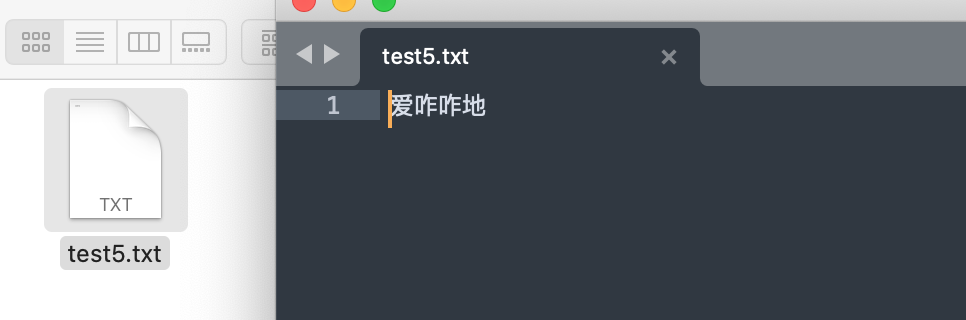
咱先看一下存储文件时发生了什么,把断点放在file.open这里的时候,可以看到文件内容的循环‘b’在遍历循环的同时,存储文件名的‘a’的结果始终都是test5.txt

而究竟a的结果为什么只有test5.txt的内容呢?咱再看下第一个for 循环最后给a传的值究竟是什么,当把断点放在print(a)的位置,当一个for 循环遍历完毕时看到最后打印出是‘test5.txt’。
这也就说通了,第一个循环遍历结束时,并不是把所有table_name传给了a,而只是把遍历最后的结果传给了a,所以最后也就只有test5.txt储存了。

正确思路
首先取出来的两列serise类型转换成list,方便下一步进行遍历操作。
table_name=read_excel['文件名'].to_list()
table_content=read_excel['文件内容'].to_list()这是比较关键的一步,进行table_name遍历操作时,同时把table_name的索引取出来,并且需要把遍历出来a的值追加到定义的空列表里,这样name的结果里装的就是所有table_name的值。
name=[]#定义空列表
for index1,a in enumerate(table_name):#enumerate:遍历列表时带上索引,
#index1即索引,a即是values
name.append(a)#把每一次遍历的a的值追加到name列表里这个时候再debug就会发现 :列表name里装的是所有需要储存的文件名。

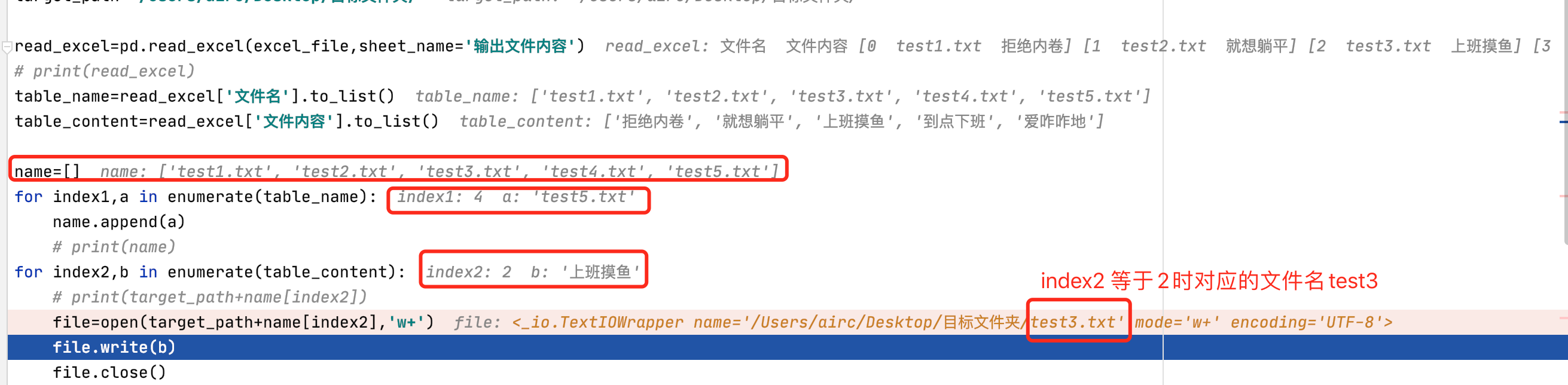
经过上一步把所有的文件名进行了列表存储之后,接着咱就到了咱的最终目的,把文件内容存到对应的文件名中 ,如下所示

for index2,b in enumerate(table_content):#同理enumerate:index2即索引,b即是values
file=open(target_path+name[index2],'w+')
file.write(b)
file.close()此时的name是个列表,此时的index2是table_content的索引,当遍历存储的时候,name的取值是索引对应的文件名。
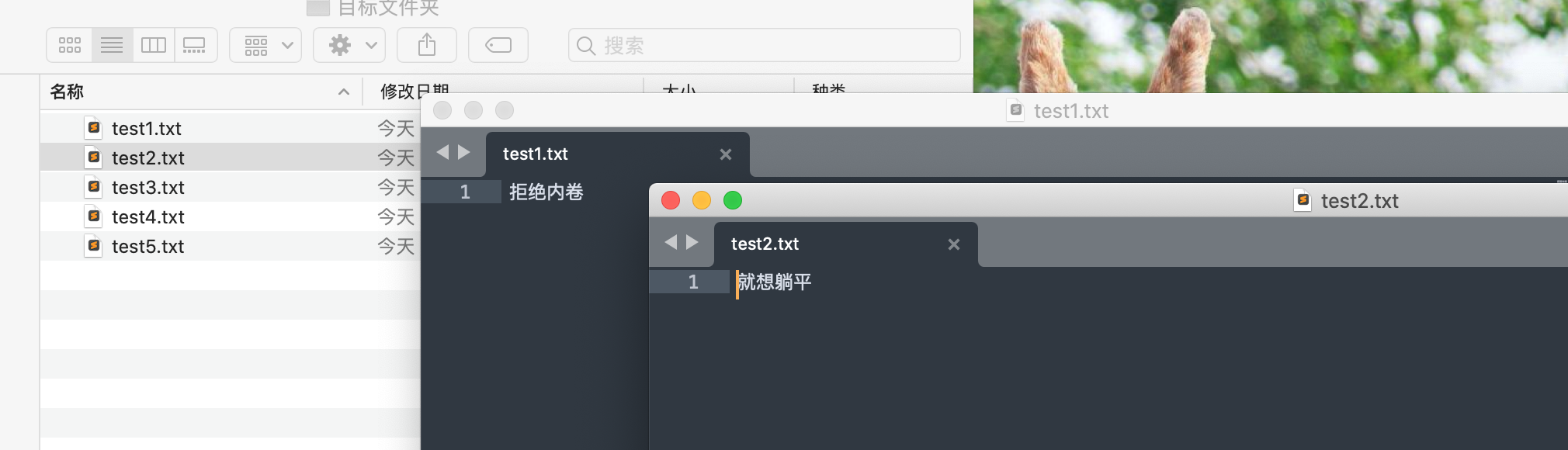
这是最终想要达到的效果。
总结一下:python在进行双层独立的循环的时候,是先走完第一层循环,遍历的结果是元素的最后一个值,如果第二层循环是接收不到第一层循环所有的值的,只有把第一层循环的值进行列表追加,第二层循环在用的时候再按索引的顺序取值,才能接受到所有第一层循环的值。
原文地址:https://blog.csdn.net/weixin_45357195/article/details/128779252
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_34646.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!