(一)MySQL服务的启动:
win+x选中选中计算机管理:选中MySQL让它的状态更改为启动,启动后的状态都是正在运行。
(二)MySQL的登录。
mysql -uroot -p123456
当出现一下提示进入成功:
当然这里是显示密码(123456)进行登录的,如果想隐藏密码登录,只需输入
mysql -uroot -p
当输入完成进行回车(enter)出现下面的图片进行输入密码即可进入:

(三)查看数据库databases:
show databases;
(四)使用数据库:
use 数据库名称;
(五)创建数据库:
create database 数据库名称;
例如create database test_wl;出现下面提示即创建成功

(六)查看表。
我们知道数据库最基本的单位是表,数据都是以表的形式展现出来,任何一张表都有行和列。行(row)被称为数据/记录,列(column)被称为字段,每一个字段下面的数据都是有数据类型的,不能填写规定类型之外的类型,没一个字段都有:字段名、数据类型、约束等。
输入指令:
show tables;
(七)数据库常用语句:
DQL:数据库查询语句(凡是带有select关键字的都是数据库查询语句)
DML:数据库操作语言:(凡是对数据库中表格的数据进行操作的语句都是数据库操作语句)
DDL;数据定义语言(凡是带有create、drop、alter关键字的都是DDL。其主要对表的结构进行操作,例如增删改某一记录(行)或者某一字段(列))。
另外还有一些其他语句:
select version();(查看MySQL版本号)
select database();(查看当前在使用那个数据库)
注意,在输入语句时,mysql不见分号不执行,必须由分号结束语句才会执行,当然也可以输入c来终止输入:

(八)导入sql文件
source 文件路径 //注意,这个指令不加分号
(九)表的查找:
(1)简单查询:
①查看某一表中数据:
select
*
from
表名;
desc 表名;
select
字段名
from
表名;
select
字段名1,字段名2
from
表名;
select
字段名 as 别名
from
表名;
注意的是数据库只是在显示时用这个别名,但是在数据库中还是原来的名字,select语句只是查询语句。而且别名中不能有空格,当你想加空格或者其中文名时应该给别名加单引号或者双引号,但是双引号在mysql中可以使用,Oracle中是无法使用的:
select
字段名 as '字段名'
from
表名;
⑥对某一字段的运算:
select
字段名*12
from
表名;
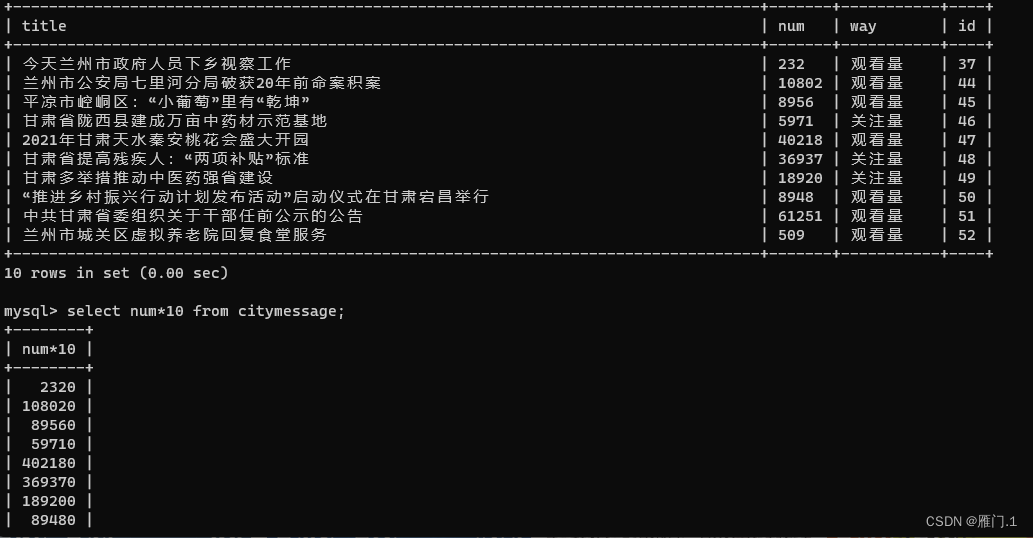
例如这样一个citymessage的表格,让它的num*10,但是一定要注意数据类型
select
num*10
from
citymessage:
(2)条件查询:
select
字段名
from
表名
where
条件;
(1)>
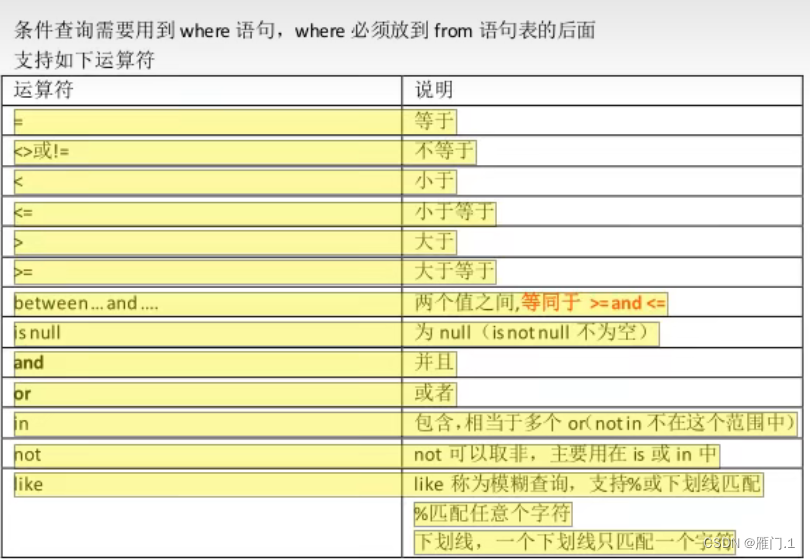
例如查询上面citymessage表中人数大于10000的名称和id
select
title,id
from
citymessage
where
num>10000:
(2)between and (相当于 >= and <=)
当然也可以查询citymessage表中人数介于8000和20000的名称和id、way,当然这里要注意的是使用between…and…时,必须注意左小右大的规范:
select * from citymessage where num between 8000 and 20000;
select * from citymessage where num>=8000 and num <= 20000;

(3)null
在对null进行查询时要注意使用is null 不能使用‘=’符号:
select 字段名 from 表名 where is null;
(4)and和or同时出现
那当我们要查询id为47,48然后人数大于2000的数据,是不是可以这样写:
select * from citymessage where num>2000 and id=47 or id=48;
这样其实是错的,因为and优先级比or高,所以这里就应该加上括号:
select * from citymessage where num>2000 and (id=47 or id=48);`
(5)in与not in
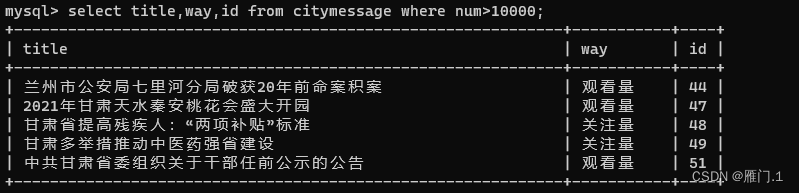
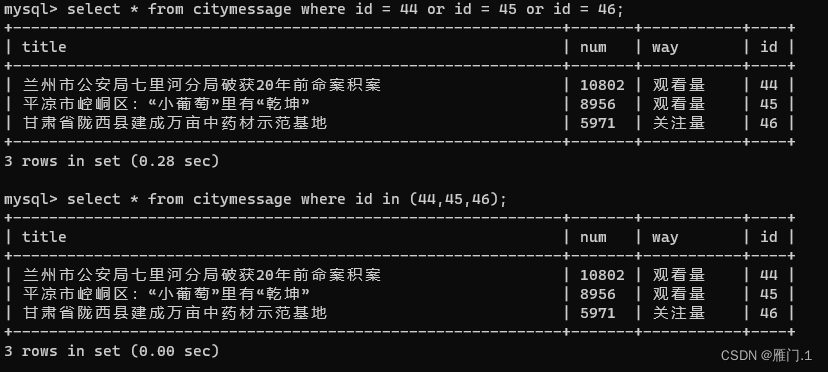
in其实相当于多个or,例如当我们想查询id为44,45,46的数据可以这样写:
select * from citymessage where id = 44 or id = 45 or id = 46;
select * from citymessage where id in (44,45,46);
下面是两个结果对比:
not in 便表示不在in的几个数据的其他数据。
select * from citymessage where id not in (44,45,46);
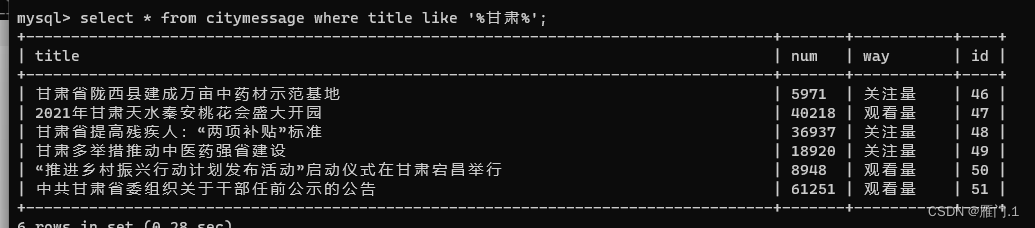
(6)模糊查询:like(配合%和_)
select * from citymessage where title like '%甘肃%';
select * from citymessage where title like '_肃%';

这里还注意当你想找到字符里面有下划线(_)的,一定要先转义再查询:
select * from 表名 where 字段名 like '%_%';
(十)排序 (order by)
(1)默认排序(升序)
select * from 表名 order by 字段名;
例如这里以id作为排序:select * from citymessage order by id;

(2)指定降序:
select * from 表名 order by 字段名 desc;
id降序:select * from citymessage order by id desc;当然将desc改为asc为指定升序。
(3)多段排序
select * from citymessage order by id asc,num asc;
这里指的是先把id按照升序进行排列,当id一样的情况下,在对num进行升序排列。
(4)综合应用:
在表citymessage中找出num在2000和8000之间,且id按照降序排列的数据:
select
*
from
citymessage
where
num between 2000 and 8000
order by
id desc;
(十一)数据处理函数(单行处理函数与多行处理函数)
单行处理函数的特点的是一个输入对应一个输出,多行处理函数的特点是多个输入对应一个输出。
(1)单行处理函数:
①substr 取子串:
substr(被截取的字符串的字段名,起始下标,截取长度));//这里注意起始下标从1开始,不能从0开始
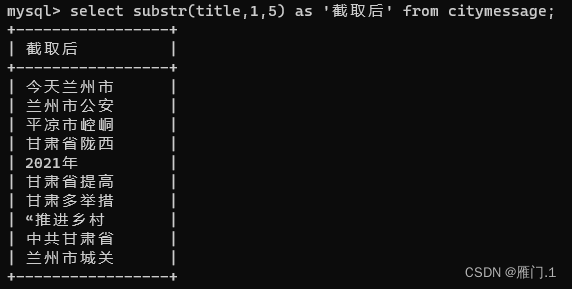
select
substr(title,1,5) as '截取后'
from
citymessage;
能看到被截取1-5个字符后,字段名title下的字符串都只剩下五个字符。
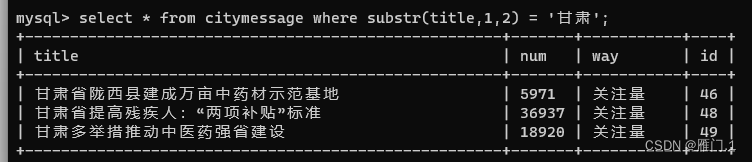
当然还可以与模糊查询一起用,比如现在要查询前两个字是甘肃的title:
select * from citymessage where title like '甘肃%';
select * from citymessage where substr(title,1,2) = '甘肃';
②concat:拼接字符串
select concat(title,num) from citymessage;
③length:取长度
select length(title) from citymessage;
④lower、upper(转换小写、转换大写)
select lower/upper (字段名) from 表名;
select lower(title) from citymessage;
select upper(title) from citymessage;
concat、length、substr、supper几者合用:比如当我们希望某一字段的所有字符串首字母大写(upper):
select
concat(upper(substr(title,1,1)),substr(title,2,length(title)-1))
from
citymessage;
⑤trim:去空格
select
*
from
citymessage
where
id = trim(45);
⑥round:四舍五入
select
round(title,0)
from
citymessage;
这里除了0以外,正数便是保留几位小数,0即保留到整数。负数便是保留到几分位,如-1是十分位,-2是百分位。保留规则均是四舍五入。
⑦rand:生成随机数(<1的随机数)
select
rand()
from
citymessage;
select
round(rand()*100)
from
citymessage;
⑧infull
专门处理null的数据,可以将null转换为具体数值。会将null当做具体的0,否则在数据库中的运算但凡有null参与,结果都为null。
select
ifnull(id,0)
from
citymessage;
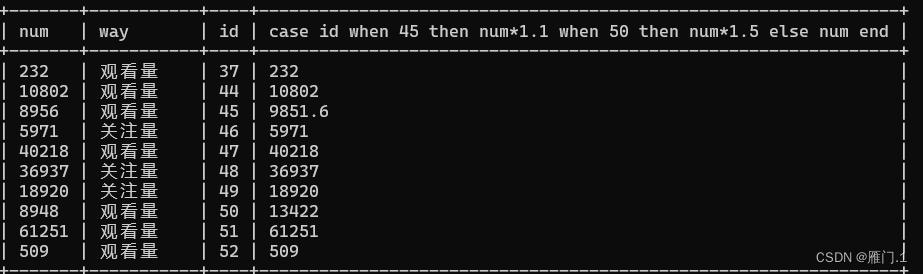
⑨case… when … then… when…then… else … end;
例如当id为45时num上涨10%,当id为50时num上涨50%,其他num正常。
select
*,case id when 45 then num*1.1 when 50 then num*1.5 else num end
from
citymessage;
(2)多行处理函数
多行函数在使用时:
①必须先进行分组在进行计算。没有分组则计算整张表。
②分组函数自动处理null,不需提前对null进行处理。
③count(字段名)统计的是改字段下所有不为null的字符串个数,count(*)统计该表总行数。
①count:计数
select count(id) from citymessage;
select count(*) from citymessage;
②max:最大值
select max(id) from citymessage;
③min:最小值
select min(id) from citymessage;
④avg:平均值
select avg(id) from citymessage;
⑤sum:求和
select sum(id) from citymessage;
(3)分组查询
分组查询一定要先对表进行分组,再进行查询,所以分组函数也不能直接使用在where后面。
查询指令编写顺序:
①group by
比如我查询一下,每种工作的工资和,并且找到其中最高的工资:但是这里需要注意的是,在分组后,select后面只能加上分组字段和数据操作函数,不能添加其他字段,否则mysql中可能会输出一个错误的结果,但是Oracle中会直接报错。
select
job,sum(salary);//不能再添加其他字段
from
表名
group by
job
order by
asc;
当需要查询某个部门某个工作岗位的最高工资时,你会发现这里需要分组两次,其实这里可以直接将两个查询直接放在一起:
select
部门,岗位,max(工资)
from
表名
group by
部门,岗位;
②having(必须与group by连用)
select
部门,max(工资)
from
表名
where
工资>5000
group by
部门;
select
部门,max(工资)
from
表名
group by
部门
having
max(工资)>5000;
③去除重复记录
这里要注意的是当有个字段命出现时,去除重复记录时属于联合去除,也就是将两个字段的数据结合起来,去除其中都在各自字段属于重复的数据。
select
distinct 字段名,字段名...
from
表名;
比如我要统计这里工作岗位的种类的数量,那么就要先行去除在进行计数:
select
count(distinct 岗位)
from
表名;
(4)连接查询
表的连接方式:
(1)内连接:
等值连接
非等值连接
自连接
(2)外连接:
左外连接
右外连接
全连接
*笛卡尔积现象:
当两张表连接时没有任何条件限制会发生笛卡尔积现象,即两个不同表中的不同字段数据会进行一对一匹配,最终生成字段1×字段2数量的数据。
select 字段名,字段名 from 表名,表名;
为了避免笛卡尔积现象,连接时必须加条件:
select
字段名,字段名
from
表1,表2
where
表1.字段 = 表2.字段;
例如这两张表:
原文地址:https://blog.csdn.net/hahahammp/article/details/129412120
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_34802.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!