1、JVM 基础知识
1.1 JVM 与操作系统的关系
JVM 能识别 class 后缀的文件,并且能够解析它的指令,最终调用操作系统上的函数,完成指定操作。操作系统并不认识这些 class 文件,是 JVM 将它们翻译成操作系统可识别的机器码,最终由操作系统执行这些机器码。
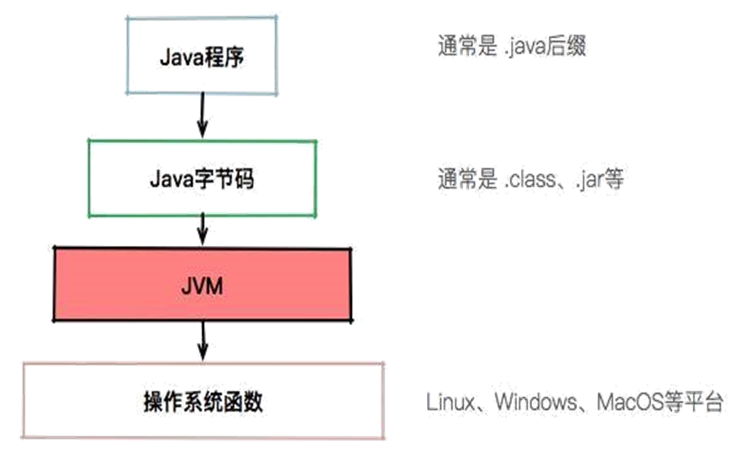
Java 具有跨平台、跨语言的特性,也是因为 JVM 可以把 Java 字节码、Kotlin 字节码、Groovy 字节码等翻译成可以被 Linux、Windows、Mac 系统识别的机器码。一个 JVM 可以识别不同语言的字节码,但是只能将它们翻译成某一种系统能识别的机器码,不同的系统需要使用不同的 JDK,对应的 JVM 只能在该种系统上运行。
1.2 Java SE 体系架构
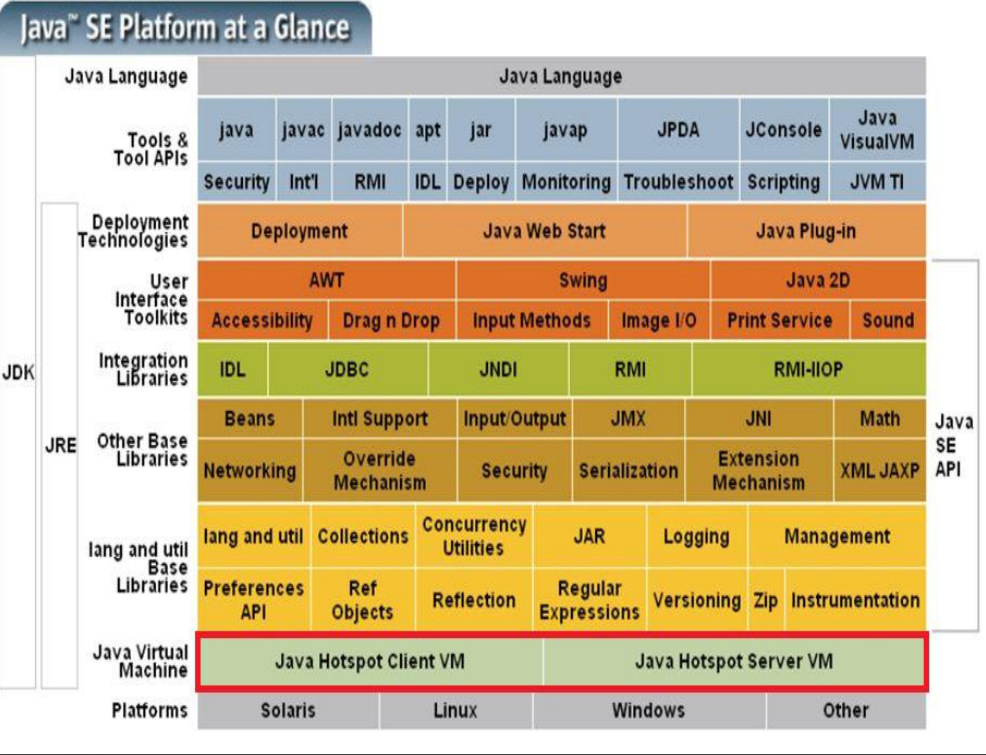
JVM 与 Java 提供的基础类库(如文件操作、网络连接和 IO 等)构成了 JRE,JRE、工具及其 API 和 Java 语言构成了 JDK。JDK 运行在 Linux、Windows 等平台之上。
注意 JVM 仅仅是一个“翻译”,Java 程序想要运行还需要基础类库 JRE,如需实现更多额外功能,还需要各种工具(由 JDK 提供,如 javac、javap、java 和 jar 等)。
1.3 JVM 整体
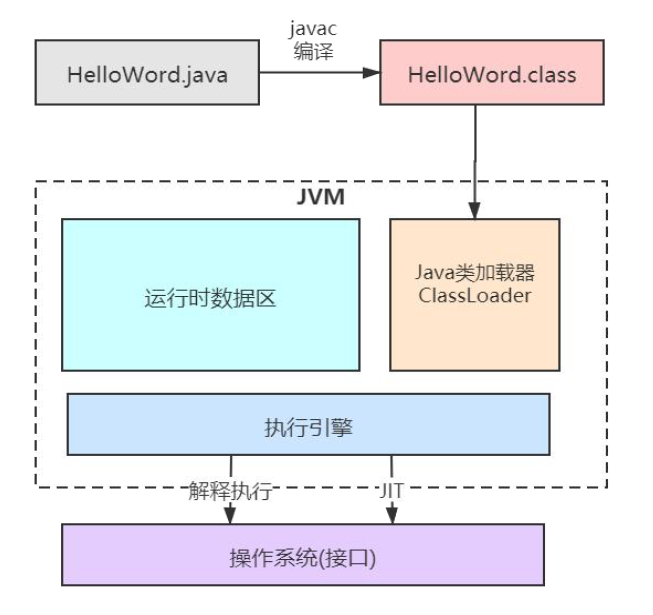
- 经过 javac 编译成为 class 字节码文件
- JVM 中的 ClassLoader 将 class 文件加载到运行时数据区(JVM 管理的内存)内的方法区中
- 执行引擎执行这些 class 文件,将其翻译成操作系统相关的函数。这里有两种执行方式:解释执行(解释一行,执行一行)或 JIT 执行(将热点代码,即执行次数较多的代码或方法直接编译为本地代码以提高执行速度)
Java 之所以能跨平台,就是由于 JVM 的存在。Java 的字节码,是沟通 Java 语言与 JVM 的桥梁,也是沟通 JVM 与操作系统的桥梁。
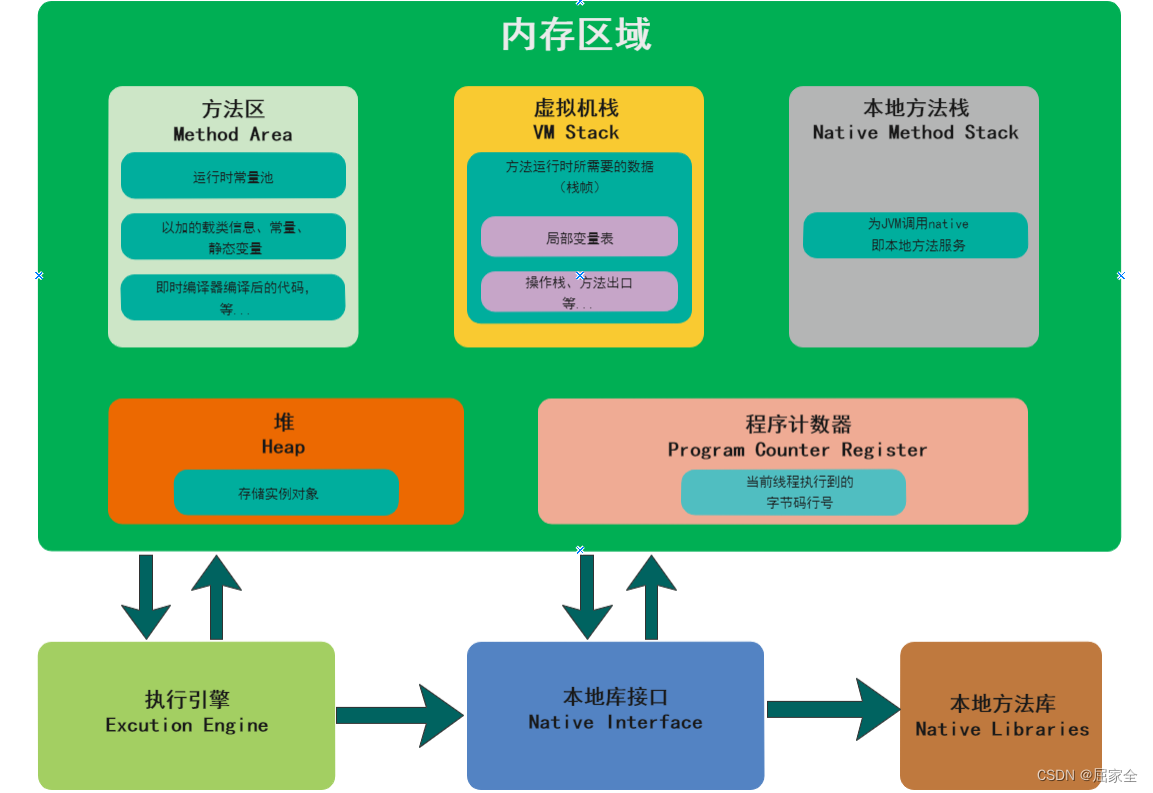
2、 运行时数据区
Java 引以为豪的就是它的自动内存管理机制。相比于 C++ 的手动内存管理、复杂难以理解的指针等,Java 程序写起来就方便的多。
在 Java 中,运行时数据区(即 JVM 内存)主要分为堆、程序计数器、方法区(运行时常量池)、虚拟机栈和本地方法栈:
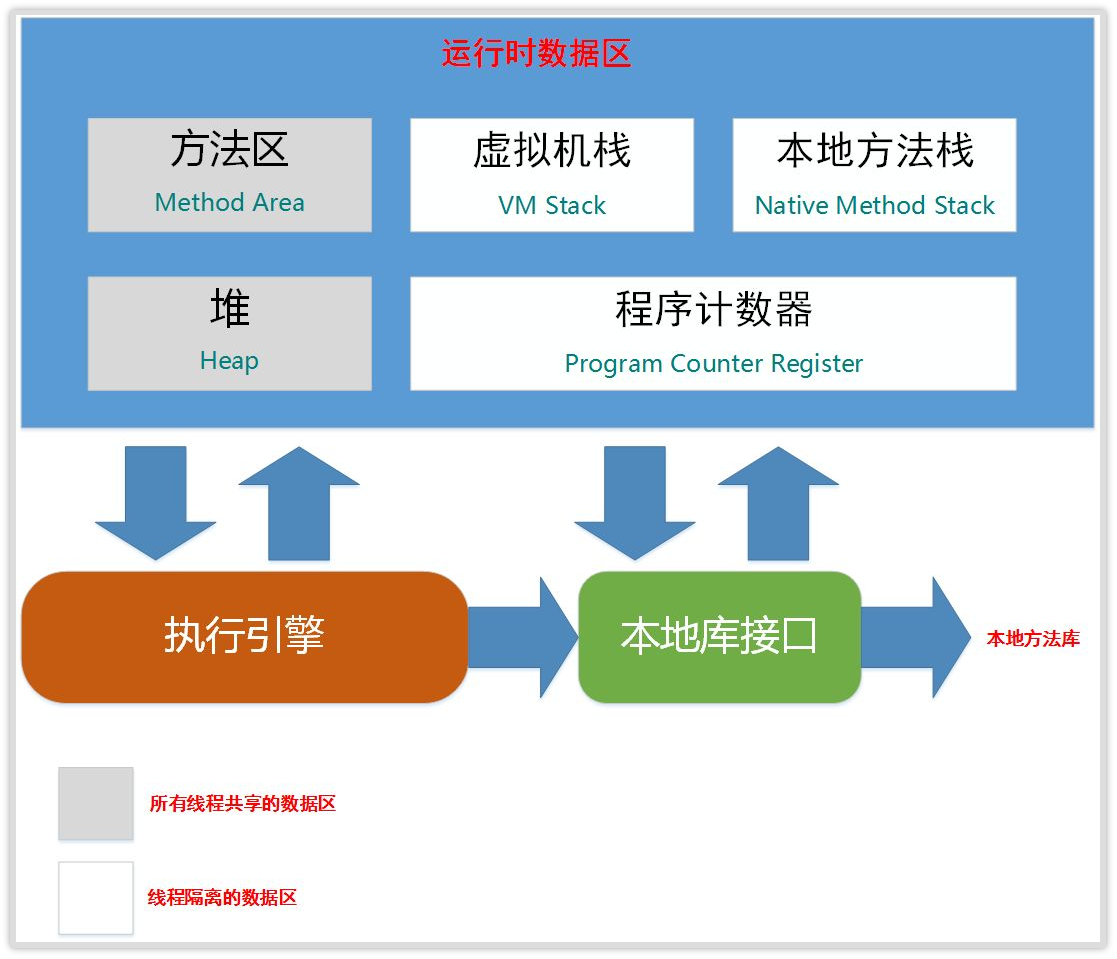
其中虚拟机栈、本地方法栈和程序计数器是线程私有的,而方法区和堆是线程公有的。这 5 个区域是 Java 虚拟机规范中定义的区域,所有自定义的虚拟机都要遵循这个规范。
2.1 程序计数器
程序计数器用来记录当前线程执行的字节码的地址,分支、循环、跳转、异常、线程恢复等都依赖于它。以线程恢复为例,在多线程环境下,当线程数量超过 CPU 核心数时,线程之间会根据时间片轮询争夺 CPU 资源,如果一个线程的时间片用完了,或者是其他原因导致这个线程的 CPU 资源被提前抢夺,那么这个退出的线程就需要一个单独的程序计数器,记录下一条运行的指令,以便下一次运行时继续执行剩余任务。
比如说使用 javap 命令反汇编一个 class 文件得到字节码文件:
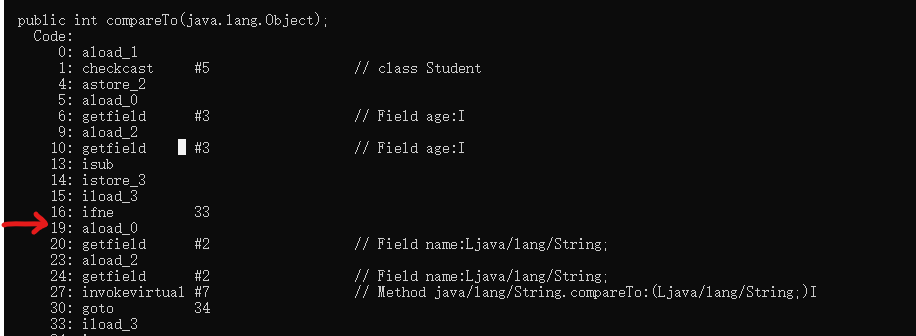
程序计数器记录的是指令的地址。比如执行完偏移量是 16 的指令 ifne 33 后,时间片用完了,当前线程不能再继续执行了,那么计数器就会记录下偏移量 19 的指令 aload_0 的地址,便于下次该线程获得时间片后从正确的位置继续执行。
在执行 native 方法时,程序计数器的值为 undefined。
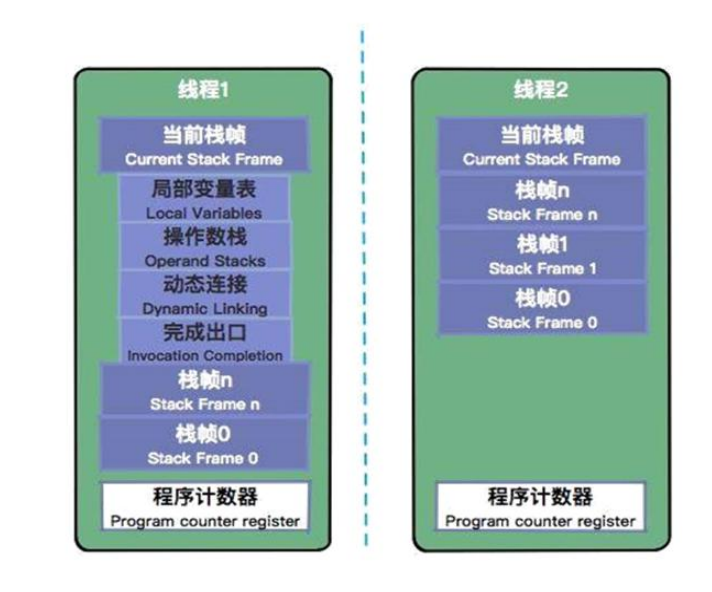
2.2 虚拟机栈
虚拟机栈后进先出,保存在当前线程中运行的方法所需的数据,栈里的每条数据,就是一个栈帧。每个 Java 方法被调用的时候,都会创建一个栈帧,并入栈(一个方法对应一个栈帧),方法完成调用后出栈。由于虚拟机栈是基于线程的,栈的生命周期和线程是一样的,当所有的栈帧都出栈后,线程也就结束了。
每个栈帧,都包含四个区域,分别是局部变量表、操作数栈、动态连接、返回地址。栈的大小默认为 1M(各个平台不同,可参考 -Xsssize),可用参数 –Xss 调整大小,例如 -Xss256k。四个区域的简介如下:
- 局部变量表:顾名思义就是局部变量的表,用于存放我们的局部变量的。它的长度是 32 位,主要存放我们的 Java 的八大基础数据类型,一般 32 位就可以存放下,如果是 64 位的就使用高低位占用两个也可以存放下,如果是局部的一些对象,比如 Object 对象,我们只需要存放它的引用地址即可。
- 操作数栈:存放我们方法执行的操作数,它就是一个栈,先进后出的栈结构,操作数栈,就是用来操作的,操作的的元素可以是任意的 Java 数据类型,所以我们知道一个方法刚刚开始的时候,这个方法的操作数栈就是空的,操作数栈运行方法就是 JVM 一直运行入栈/出栈的操作。
- 动态连接:Java 语言特性多态(需要类运行时才能确定具体的方法)。
- 返回地址:也称为完成出口,方法正常执行完毕,就用调用程序计数器中的地址作为返回;方法过程中如果发生异常,就通过异常处理器表来确定。注意这个异常处理表并不是栈帧的组成部分。
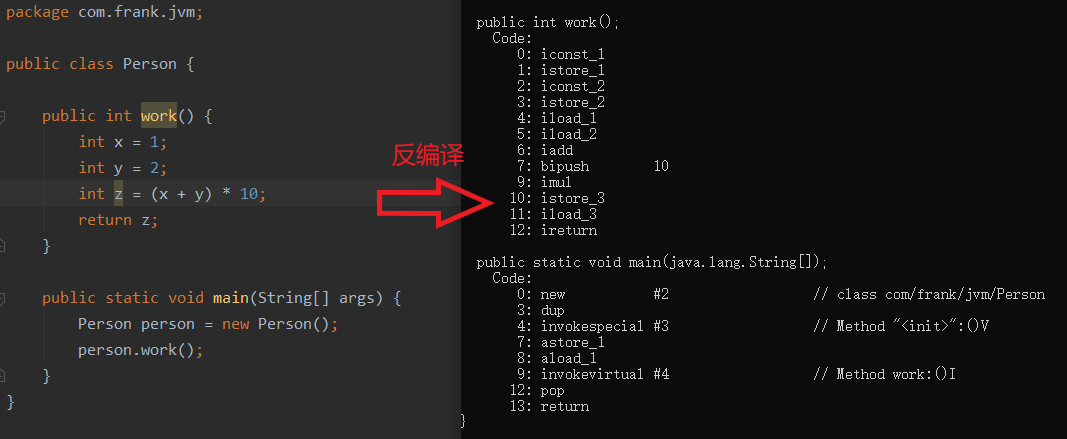
将左侧源代码编译的 class 文件通过 javap –c 命令反编译成右侧的字节码,注意观察 work() 内的指令。对指令陌生的可以参考 java虚拟机 JVM字节码 指令集 bytecode 操作码 指令分类用法 助记符。
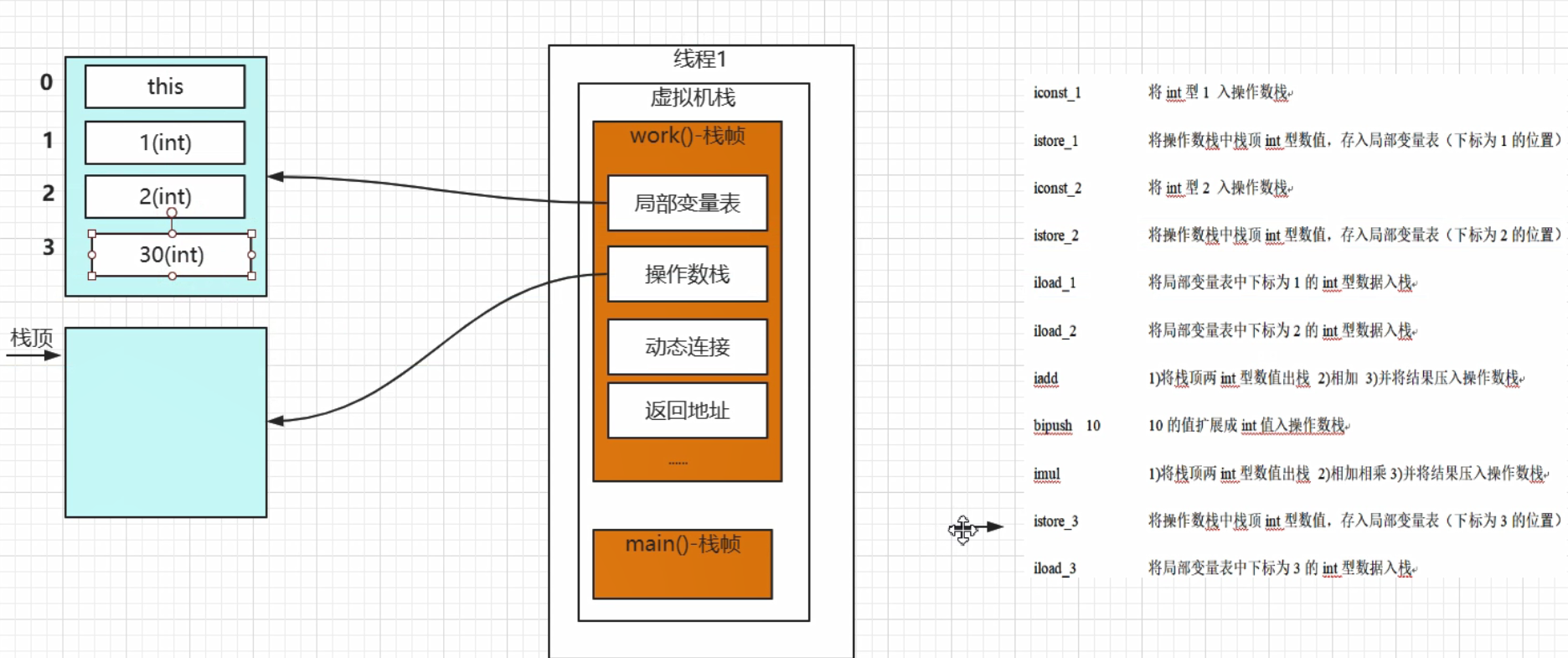
图片右侧是 work() 执行操作数栈的指令以及指令的含义,图片左侧是局部变量表和操作数栈执行到 istore_3 指令时的状态。有一个需要注意的地方是,如果方法是一个对象方法,那么该方法局部变量表的 0 号地址存放的是一个 this,如果方法是静态的则没有 this。
Java 方法执行是基于栈(操作数栈),兼容性好,但效率偏低一点;而 C/C++ 是基于寄存器(偏硬件),运算快但移植性差(需要 make install)。
还有栈帧区域中的动态连接,是跟 Java 语言的多态特性相关的,具体术语叫做动态分派和静态分派。假设有如下代码:
public class People {
public void wc() {
System.out.println("People");
}
static class Man extends People {
@Override
public void wc() {
System.out.println("Man");
}
}
static class Woman extends People {
@Override
public void wc() {
System.out.println("Woman");
}
}
public static void main(String[] args) {
People people = new Man();
people.wc();
people = new Woman();
people.wc();
}
}
在编译阶段,无法确定 people 调用的 wc() 应该是 Man 中的还是 Woman 中的,它是在执行阶段,由动态连接决定的。
2.3 本地方法栈
本地方法栈跟 Java 虚拟机栈的功能类似,Java 虚拟机栈用于管理 Java 方法的调用,而本地方法栈则用于管理本地方法的调用。native 方法由 C 语言实现,当一个 JVM 创建的线程调用 native 方法后,JVM 不会为该方法在虚拟机栈中创建栈帧,只是简单地动态链接并直接调用该方法。
虚拟机规范对本地方法栈无强制规定,各版本虚拟机可以自由实现。比如说 HotSpot 直接把本地方法栈和虚拟机栈合二为一。
线程私有的三个区域到这里就介绍完毕了,下面开始介绍线程公有的方法区和 Java 堆。
2.4 方法区
方法区主要是用来存放已被虚拟机加载的类相关信息,包括类信息、静态变量、常量、运行时常量池、字符串常量池。
JVM 在执行某个类的时候,必须先加载。在加载类(加载、验证、准备、解析、初始化)的时候,JVM 会先加载 class 文件,而在 class 文件中除了有类的版本、字段、方法和接口等描述信息外,还有一项信息是常量池 (Constant Pool Table),用于存放编译期间生成的各种字面量和符号引用:
- 字面量包括字符串(String a=“b”)、基本类型的常量(final 修饰的变量)
- 符号引用包括类和方法的全限定名(例如 String 的全限定名是 Java/lang/String)、字段的名称和描述符以及方法的名称和描述符。
而当类加载到内存中后,JVM 就会将 class 文件常量池中的内容存放到运行时的常量池中;在解析阶段,JVM 会把符号引用替换为直接引用(对象的索引值)。
例如,类中的一个字符串常量在 class 文件中时,存放在 class 文件常量池中的;在 JVM 加载完类之后,JVM 会将这个字符串常量放到运行时常量池中,并在解析阶段,指定该字符串对象的索引值。运行时常量池是全局共享的,多个类共用一个运行时常量池,class 文件中常量池多个相同的字符串在运行时常量池只会存在一份。
方法区与堆空间类似,也是一个共享内存区,所以方法区是线程共享的。假如两个线程都试图访问方法区中的同一个类信息,而这个类还没有装入 JVM,那么此时就只允许一个线程去加载它,另一个线程必须等待。在 HotSpot 虚拟机、Java7 版本中已经将永久代的静态变量和运行时常量池转移到了堆中,其余部分则存储在 JVM 的非堆内存中,而 Java8 版本已经将方法区中实现的永久代去掉了,并用元空间(class metadata)代替了之前的永久代,并且元空间的存储位置是本地。
方法区和堆区都是线程共享的,为什么要分成两个区域呢?
堆中保存的对象和数组都是需要频繁回收的,而方法区中保存的类信息、常量、静态变量和即时编译期编译后的代码,它们要被回收的难度是非常大的。把二者区分开体现了一种动静分离的思想,偏静态的数据放到方法区,而频繁创建回收的对象放到堆中,便于高效的回收。
永久代与元空间
关于方法区,有两个易混淆的概念就是永久代(PermGen)和元空间(MetaSpace)。方法区是虚拟机中规范的一部分,而永久代和元空间都是实现这种规范的方式,只不过永久代仅存在于 Hotspot 虚拟机中,而其他的虚拟机如 JRocket(Oracle)、J9(IBM)并没有永久代。并且在 Oracle 收购 Hotspot 和 JRocket 两家公司之后,为了推出 JDK 1.8 需要将两个虚拟机融合,将永久代去掉了转而使用元空间,即从 JDK 1.8 开始没有永久代了(其实从 1.7 开始就着手清除永久代了)。两者最大的区别就是:元空间并不在虚拟机中,而是使用本地内存。
除此之外,还有以下区别:
- JDK ≤ 1.7 时代,GC 除了要回收堆内存之外,还要回收永久代中保存的类信息、常量、静态变量等,回收效率很低;而当 JDK ≥ 1.8 后,元空间完全替代了永久代。它使用的是机器内存,默认情况下,其空间大小不受限制(永久代的空间大小受制于堆的大小,而元空间只受制于机器,它可以使用直接内存,也称堆外内存)。
- 永久代在动态生成类时容易发生内存溢出,即”java.lang.OutOfMemoryError: PermGen space“;而元空间方便拓展,但是会挤压堆空间。比如说一个机器内存为 16G,元空间占用了其中的 12G,那么使用 -Xmx 指令为堆区内存可分配的最大上限的值,理论最大值只能为 4G。
Java8 为什么使用元空间替代永久代,这样做有什么好处呢?
官方给出的解释是:
移除永久代是为了融合 HotSpot JVM 与 JRockit VM 而做出的努力,因为 JRockit 没有永久代,所以不需要配置永久代。
永久代内存经常不够用或发生内存溢出,抛出异常 java.lang.OutOfMemoryError: PermGen。这是因为在 JDK1.7 版本中,指定的 PermGen 区大小为 8M,由于 PermGen 中类的元数据信息在每次 FullGC 的时候都可能被收集,回收率都偏低,成绩很难令人满意;还有,为 PermGen 分配多大的空间很难确定,PermSize 的大小依赖于很多因素,比如,JVM 加载的 class 总数、常量池的大小和方法的大小等。
关于永久代和元空间更详细的内容可以参考以下:
Java8内存模型—永久代(PermGen)和元空间(Metaspace)
元空间和永久代的区别
别再说不知道元空间和永久代的区别了
元空间和永久代的区别
2.5 堆
堆是 JVM 上最大的内存区域,我们申请的几乎所有的对象,都是在这里存储的。我们常说的垃圾回收,操作的对象就是堆。
随着对象的频繁创建,堆空间占用的越来越多,就需要不定期的对不再使用的对象进行回收。这个在 Java 中,就叫作 GC(Garbage Collection)。
那一个对象创建的时候,到底是在堆上分配,还是在栈上分配呢?这和两个方面有关:对象的类型和在 Java 类中存在的位置。Java 的对象可以分为基本数据类型和普通对象:
- 对于普通对象来说,JVM 会首先在堆上创建对象,然后在其他地方使用的其实是它的引用。比如,把这个引用保存在虚拟机栈的局部变量表中。
- 对于基本数据类型来说(byte、short、int、long、float、double、char),有两种情况。当你在方法体内声明了基本数据类型的对象,它就会在栈上直接分配。其他情况,都是在堆上分配。
堆大小参数设置:
-Xmx:堆区内存可被分配的最大上限。
-Xms:堆区内存初始内存分配的大小。
-Xmn:新生代的大小;
-XX:NewSize:新生代最小值;
-XX:MaxNewSize:新生代最大值;
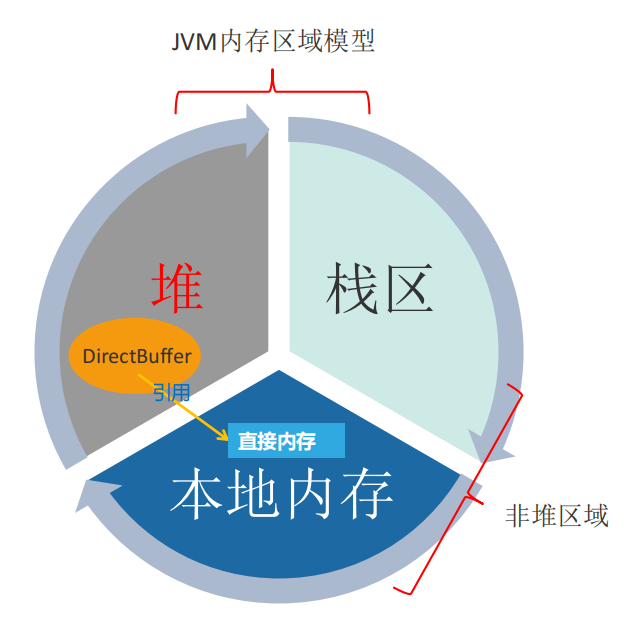
2.6 直接内存
也称堆外内存,不是虚拟机运行时数据区的一部分,也不是 Java 虚拟机规范中定义的内存区域。
如果使用了 NIO,这块区域会被频繁使用,在 Java 堆内可以用 directByteBuffer 对象直接引用并操作。
这块内存不受 Java 堆大小限制,但受本机总内存的限制,可以通过 -XX:MaxDirectMemorySize 来设置(默认与堆内存最大值一样),所以也会出现 OOM 异常。
3、从底层深入理解运行时数据区
/**
* 设置虚拟机参数:-Xms30m -Xmx30m -XX:+UseConcMarkSweepGC -XX:-UseCompressedOops
* 参数含义依次为:堆的初始大小为30M,堆的最大值为30M,使用垃圾回收器,关闭内存压缩
*/
public class JVMObject {
public final static String MAN_TYPE = "man"; // 常量
public static String WOMAN_TYPE = "woman"; // 静态变量
public static void main(String[] args) throws InterruptedException {
Teacher t1 = new Teacher(); // t1对象本身是局部变量,在堆中;t1引用在虚拟机栈->main栈帧->局部变量表中。
t1.setName("Teacher1");
t1.setSexType(MAN_TYPE);
t1.setAge(30);
for (int i = 0; i < 15; i++) {
System.gc();
}
Teacher t2 = new Teacher();
t2.setName("Teacher2");
t2.setSexType(MAN_TYPE);
t2.setAge(35);
Thread.sleep(Integer.MAX_VALUE);
}
}
class Teacher {
String name;
String sexType;
int age;
// setters...
}
我们要使用工具来观察这段代码执行时 JVM 和底层数据的一些现象。
开始执行程序,步骤是:
- 首先要申请堆、栈、方法区的内存。
- 然后使用 ClassLoader 将 Teacher 和 JVMObject 两个类的 class 加载进方法区。
- 接下来对类进行分析,将类中的常量(MAN_TYPE)和静态变量(WOMAN_TYPE)加载进方法区。
- 开始执行 main 方法,表示该方法的栈帧进入虚拟机栈。
- 执行 main 方法内容,对象 t1 在堆的年轻代中创建,而 t1 的引用则要放在该方法栈帧的局部变量表中。执行过 15 次垃圾回收后,t1 会被放入堆的老年代中,随后 t2 在堆的年轻代中创建,t2 的引用放入栈帧的局部变量表。
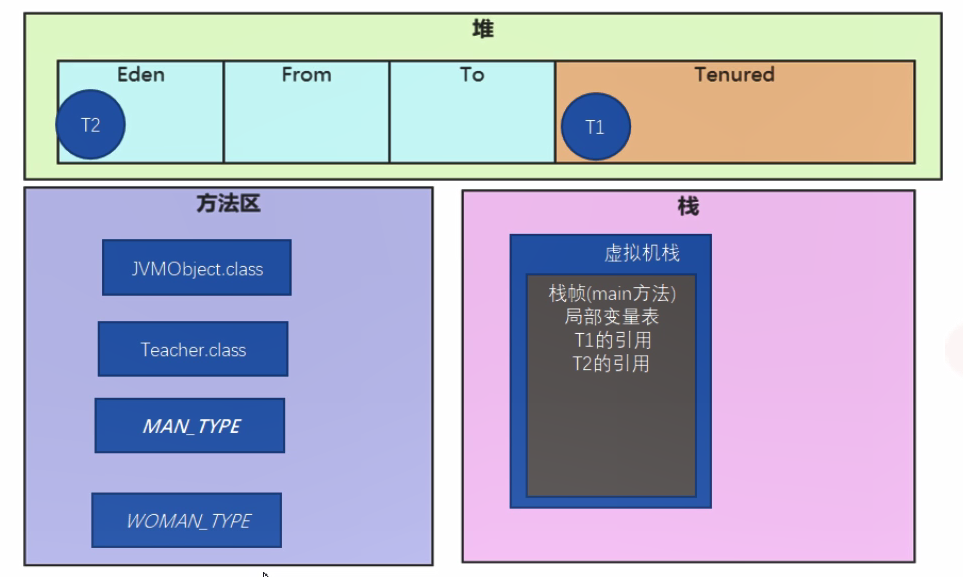
当然我们也可以使用内存可视化工具 HSDB 查看内存的具体情况。
HSDB 全名为 HotSpot Debugger,从 JDK1.8 开始存在,在 JDK1.9 可以可视化调用。JDK1.8 使用该工具的方法是:在 jdk/lib 目录下(为了运行该目录下的 sa-jdi.jar)运行 cmd 输入命令:
C:Program FilesJavajdk1.8.0_181lib>java -cp .sa-jdi.jar sun.jvm.hotspot.HSDB
然后就会弹出 HSDB 工具界面。在正式使用 HSDB 之前,先使用 jps 命令查看 Java 程序的进程号:
C:Users69129>jps
11056
5136 Jps
13332 HSDB
8668 JVMObject
可以看到示例程序进程 id 为 8668,HSDB 实际上也是个 Java 进程,id 为 13332。
接下来在 HSDB 中选择 File -> Attach to HotSpot process -> 输入要监控的 pid,会弹出一个 Java Threads 窗口:
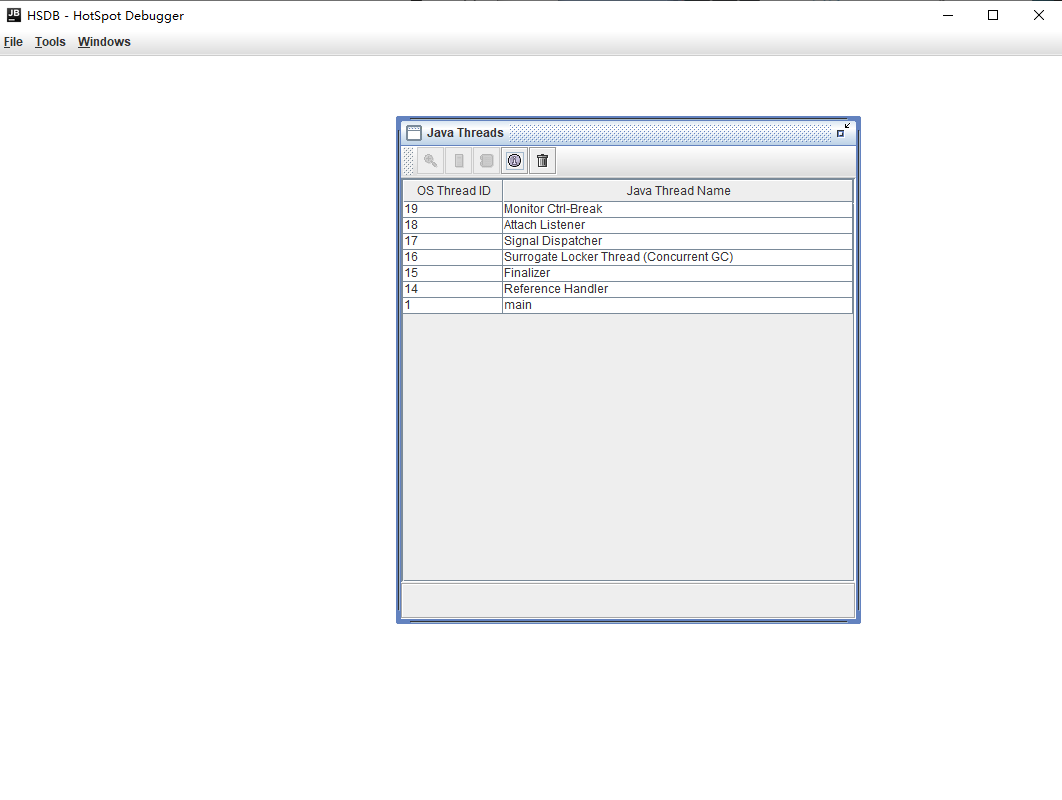
选定要查看的 main 线程,点击工具栏的第二个按钮 Stack Memory:

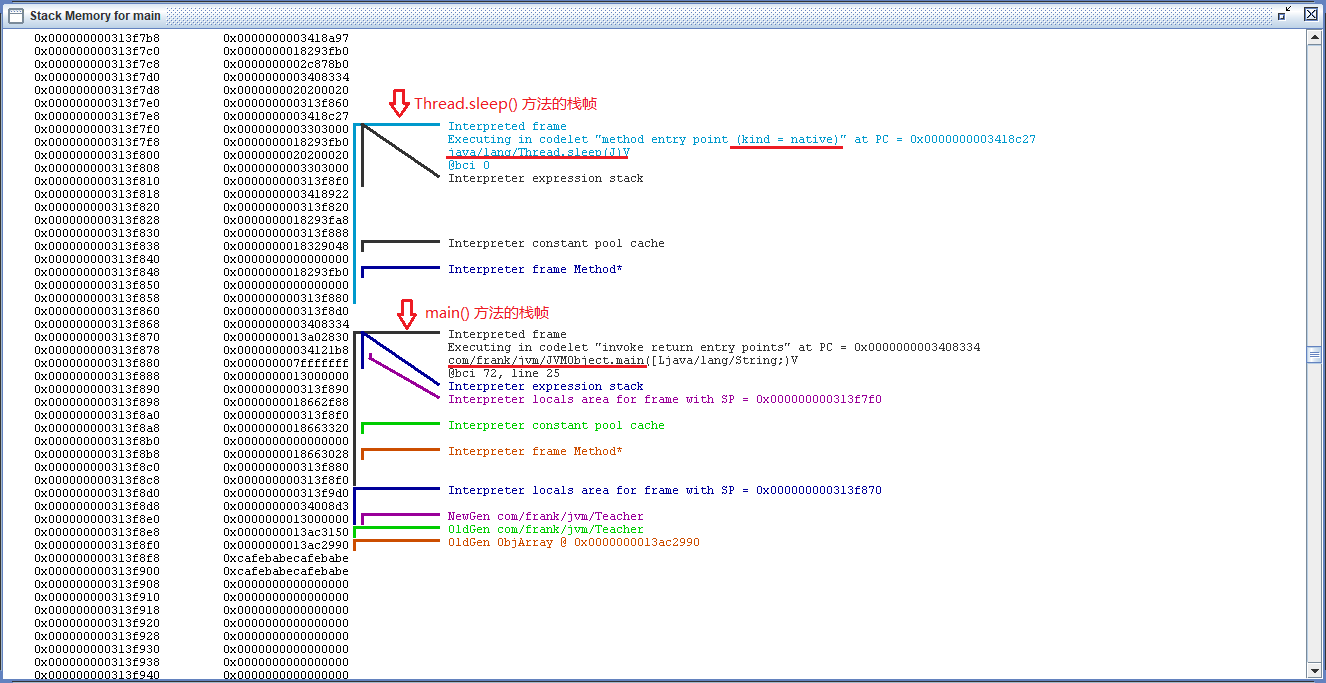
图中可以清晰的看到 main 方法与 Thread.sleep 方法的栈帧以及地址范围,更可以看到 Thread.sleep 作为一个本地方法,它的栈帧与虚拟机栈存放的 main 方法栈帧相邻存放,也印证了前面说到的 HotSpot 虚拟机将虚拟机栈和本地方法栈合二为一的说法。
另外可以看出一点,虚拟机不仅将方法中的指令虚拟化了,其实也是通过栈帧将真实的内存地址给虚拟化了。
接下来看如何查看类及其对象的信息。在 HSDB 工具栏上选择 Tools -> Object Histogram -> 输入要查看类的全类名 -> 双击查看对象信息 -> Inspect 查看单个对象的详细信息:
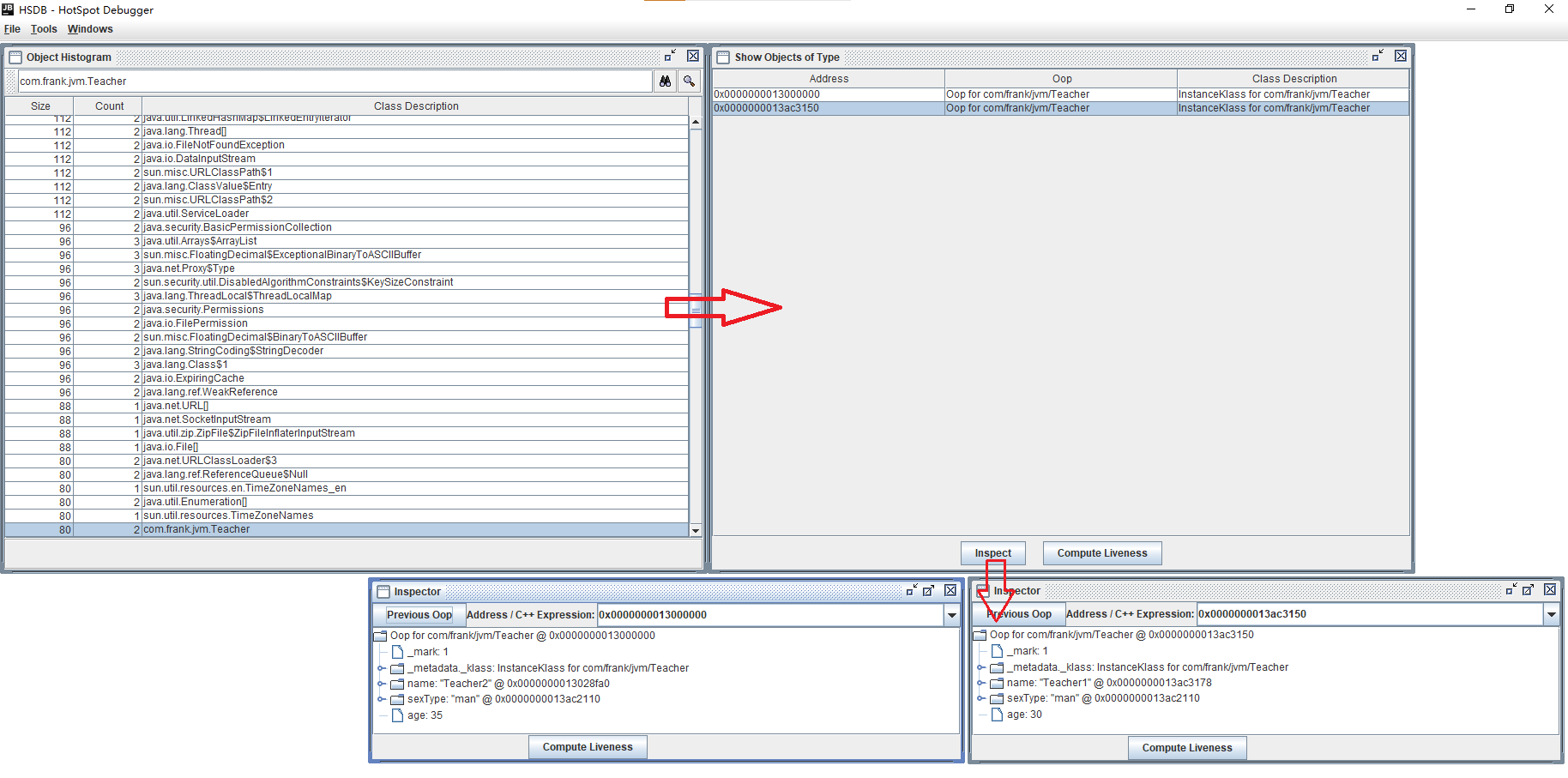
Teacher 类的两个对象都在堆区,依据就是这两个对象的地址都在堆区地址的范围内。两个对象的地址分别为 0x0000000013ac3150 和 0x0000000013000000,而我们在 HSDB -> Tools -> Heap Parameters 下能看到堆的数据:
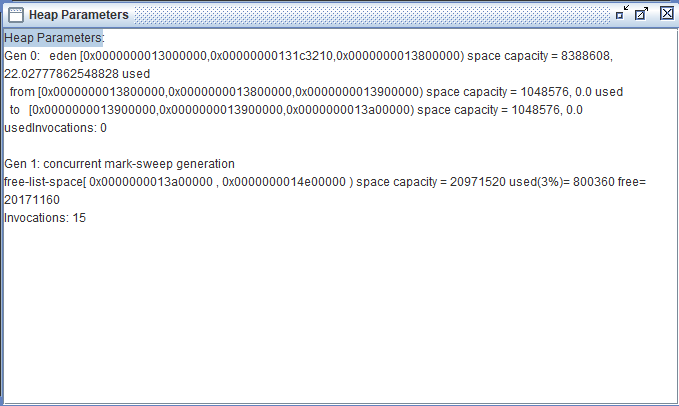
通过以上数据可以看到堆中是进行了分代划分的,Gen0 是年轻代,Gen1 是老年代,年轻代中又分为 eden区、from 区和 to 区,可以看到 Gen0 与 Gen1 的内存区域是相连的,并且两个 Teacher 对象的地址一个在 eden 区一个在 Gen1 区,所以说这两个对象在堆区中。
4、内存溢出
示例代码需要配合虚拟机参数才能看出效果。Android Studio 中设置虚拟机参数的方法是 选择要运行的程序或模块 -> Edit Configurations -> 将参数填入 VM options 中。
4.1 栈溢出
一个方法递归调用自己,就会产生栈溢出 StackOverflowError:
/**
* 栈溢出 -Xss1m
*/
public class StackOverFlow {
public void king(){//一个栈帧--虚拟机栈运行
king();//无穷的递归
}
public static void main(String[] args)throws Throwable {
StackOverFlow javaStack = new StackOverFlow(); //new一个对象
javaStack.king();
}
}
还有一种情形是 OutOfMemoryError,比如要创建 1000 个线程同时执行,每个虚拟机栈的大小默认为 1M,那么总共需要 1000M 的内存,但是如果当前系统仅有 500M 就无法满足这 1000 个线程同时执行需要的内存,就会产生 OutOfMemoryError。
4.2 堆溢出
第一种情况,对象所需要的内存空间大于堆空间,比如使用参数设置堆区大小为 30M,然后申请一个 35M 的数组:
/**
* VM Args:-Xms30m -Xmx30m -XX:+PrintGCDetails
* 堆内存溢出(直接溢出)
*/
public class HeapOom {
public static void main(String[] args) {
String[] strings = new String[35 * 1000 * 1000]; //35m的数组(堆)
}
}
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at com.frank.jvm.HeapOom.main(HeapOom.java:9)
这些 OutOfMemoryError 的实例,也可以通过 HSDB 的 Object histogram 查看。
第二种情况,频繁 GC 后出现堆溢出:
/**
* VM Args:-Xms30m -Xmx30m -XX:+PrintGC 堆的大小30M
* 造成一个堆内存溢出(分析下JVM的分代收集)
* GC调优---生产服务器推荐开启(默认是关闭的)
* -XX:+HeapDumpOnOutOfMemoryError
*/
public class HeapOom2 {
public static void main(String[] args) {
//GC ROOTS
List<Object> list = new LinkedList<>(); // list 当前虚拟机栈(局部变量表)中引用的对象 是1,不是走2
int i = 0;
while (true) {
i++;
if (i % 10000 == 0) System.out.println("i=" + i);
list.add(new Object()); // GC 频繁回收 new 出的 Object
}
}
}
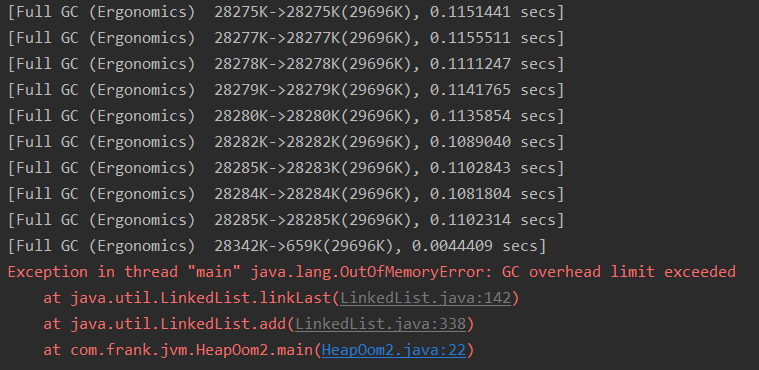
4.3 方法区溢出
cglib 不断的编译代码会造成方法区内存溢出,运行示例之前需要先将 cglib、asm 两个 jar 包添加到项目中:
/**
* cglib动态生成
* Enhancer中 setSuperClass和setCallback, 设置好了SuperClass后, 可以使用create制作代理对象了
* 限制方法区的大小导致的内存溢出
* VM Args: -XX:MetaspaceSize=10M -XX:MaxMetaspaceSize=10M
*/
public class MethodAreaOutOfMemory {
public static void main(String[] args) {
while (true) {
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(MethodAreaOutOfMemory.TestObject.class);
enhancer.setUseCache(false);
enhancer.setCallback(new MethodInterceptor() {
public Object intercept(Object arg0, Method arg1, Object[] arg2, MethodProxy arg3) throws Throwable {
return arg3.invokeSuper(arg0, arg2);
}
});
enhancer.create();
}
}
public static class TestObject {
private double a = 34.53;
private Integer b = 9999999;
}
}
给虚拟机设置元空间 MetaspaceSize 大小为 10M,运行异常 log 如下:

cglib是一个强大的,高性能,高质量的Code生成类库,它可以在运行期扩展Java类与实现Java接口。
CGLIB包的底层是通过使用一个小而快的字节码处理框架ASM,来转换字节码并生成新的类。除了CGLIB包,脚本语言例如Groovy和BeanShell,也是使用ASM来生成java的字节码。当然不鼓励直接使用ASM,因为它要求你必须对JVM内部结构包括class文件的格式和指令集都很熟悉。
4.4 本机直接内存溢出
/**
* VM Args:-XX:MaxDirectMemorySize=100m
* 堆外内存(直接内存溢出)
*/
public class DirectOom {
public static void main(String[] args) {
//直接分配128M的直接内存(100M)
ByteBuffer bb = ByteBuffer.allocateDirect(128*1024*1204);
}
}
指定直接内存为 100M,申请 128M 发生溢出,log:
Exception in thread "main" java.lang.OutOfMemoryError: Direct buffer memory
at java.nio.Bits.reserveMemory(Bits.java:694)
at java.nio.DirectByteBuffer.<init>(DirectByteBuffer.java:123)
at java.nio.ByteBuffer.allocateDirect(ByteBuffer.java:311)
at com.frank.jvm.DirectOom.main(DirectOom.java:14)
5、虚拟机优化技术
5.1 编译优化技术
public class MethodDeal {
public static void main(String[] args) {
// max(1,2);//调用max方法: 虚拟机栈 --入栈(max 栈帧)
boolean i1 = 1 > 2;
}
public static boolean max(int a, int b) {//方法的执行入栈帧。
return a > b;
}
}
假如在编译时已经能确定 max 方法两个参数的值,那么就直接使用具体值参与计算,而不是仍然使用 max 方法。因为调用方法要生成栈帧出入虚拟机栈,耗费性能,没必要通过方法调用增加无畏的性能消耗。而方法内联就是把 max 的方法体提前到 main 中执行,减少层级,提高运行效率。
5.2 栈的优化技术
栈帧之间数据共享。主要是在方法调用出现参数传递时,调用方的栈帧与被调用方的栈帧可以共享一部分区域来传递参数。
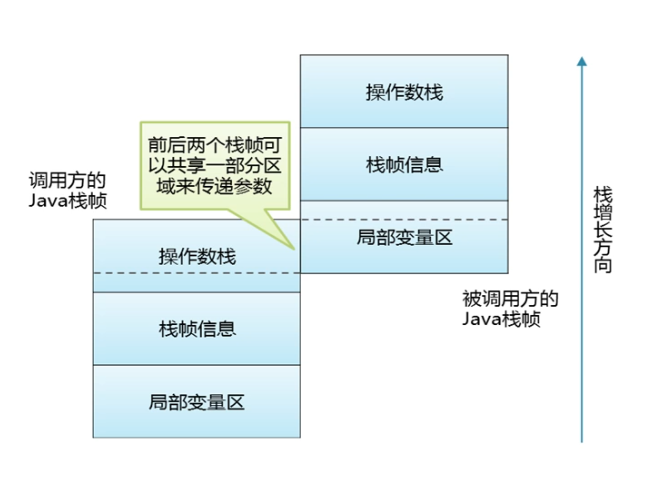
示例代码:
/**
* 栈帧之间数据的共享
*/
public class JVMStack {
public int work(int x) throws Exception {
int z = (x + 5) * 10; //局部变量表
Thread.sleep(Integer.MAX_VALUE); // 休眠线程以便使用HSDB查看
return z;
}
public static void main(String[] args) throws Exception {
JVMStack jvmStack = new JVMStack();
jvmStack.work(10); //10 放入main栈帧操作数栈
}
}
main 中调用 work 方法,传递的参数10是放在 main 方法栈帧的操作数栈中的,而 work 方法接收的参数10是放在栈帧的局部变量表中,那么 main 栈帧的操作数栈与 work 的局部变量表就可以通过共享区域传递参数10,。可以使用 HSDB 看一下:
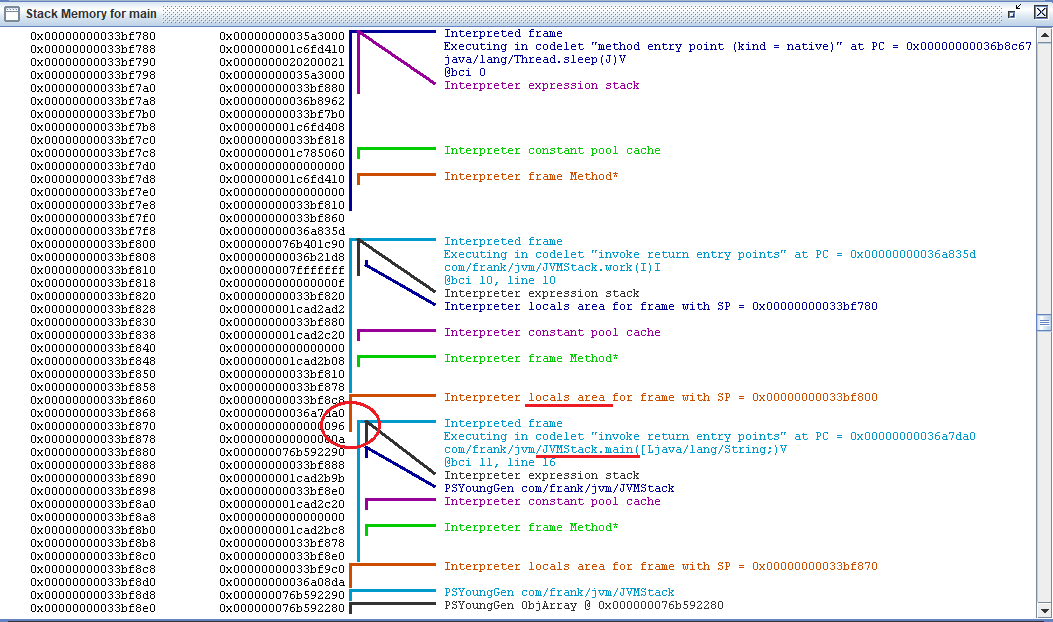
上图中地址尾数 096 位置的内存,是 main 方法操作数栈(黑色线)与 work 方法局部变量表(棕色线)重合的部分,表示传递参数的共享区域。
原文地址:https://blog.csdn.net/tmacfrank/article/details/134634729
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_34880.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!