3.用phantomjs调用echarts-converts.js生成图片
前言
本次任务:要求不经过web页面,Java如何按月定时生成含有Echarts图的PDF。
与我之前一篇文章中介绍的(Java如何根据前台Echarts图表生成PDF,并下载)区别在于,该文章中的Echarts图片可以从已有的web页面获取,而本次任务没有页面。Echarts图需要由后台生成。那么整个流程分为以下三步:
一、如何后台生成Echarts图片?
1.PhantomJS
后台生成Echarts图,需要使用到PhantomJS:一个自带JavaScript API的无头WebKit脚本,简单理解就是:它能干浏览器能干的几乎所有事情,能解析js、能渲染等等,但是没有页面让你看。
2.PhantomJS的下载
http://wenku.kuryun.com/docs/phantomjs/index.html
打开我的文件:根据你使用的操作系统,选择一个进行下载并解压。
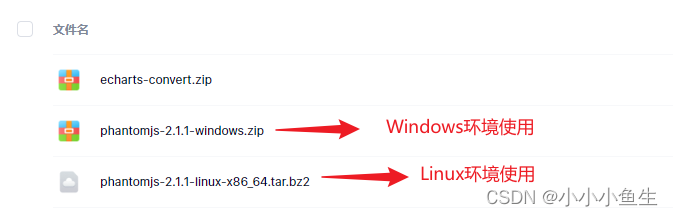
打开我的文件,除phantomjs文件外,可见还有一个文件夹echarts–convert,有2个文件:
1.echarts:里面是echarts和jquery,可以用你们自己本地或项目中的。
2.echarts–converts.js:是自己写的js文件,用来渲染生成echarts图片,可根据自己需求改写。
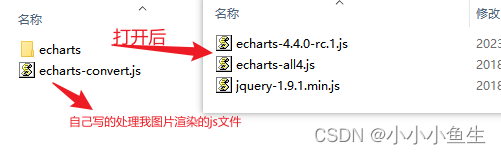
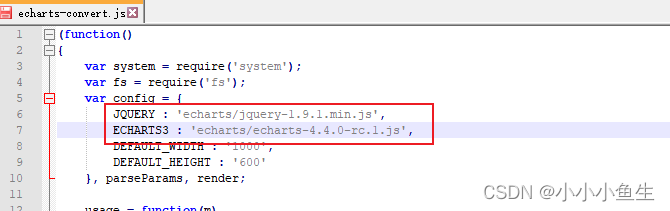
注意:若使用自己本地的echarts和jquery文件,echarts-converts.js里面的文件路径需要改写,指向你的文件所在的位置。
3.用phantomjs调用echarts-converts.js生成图片
1.从echarts官网随便选择一个图,将option复制本地某个文件中(例:G:testtestOption.txt)
2.手动创建一个空的png文件(例:G:test111.png)

3.cmd调用phantomjs进程,让它去解析echarts-converts.js,并传入一些参数(如图):
G:testphantomjs-2.1.1-windowsbinphantomjs.exe G:testecharts-convertecharts-convert.js -txtPath G:testtestOption.txt -picTmpPath G:test111.png -picPath G:test222.png 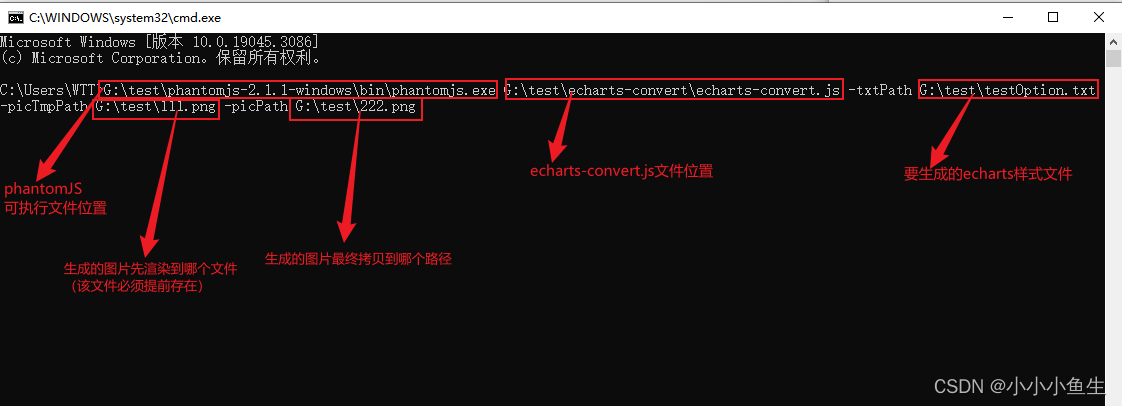

4.执行完成,完成后,111.png图片有内容,且生成了一张222.png。

二、Java如何将Echarts图生成到PDF
2、将生成的图片生成出PDF
3、下载PDF
1.生成PDF依赖
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itextpdf</artifactId>
<version>5.5.13.3</version>
</dependency> 2.Java代码测试例子:
public static void main(String[] args)
{
try
{
// 测试同时生成两张图
// 注意:要先手动创建两个空文件G:\test\1.png和G:\test\2.png;要提前将echarts的option数据写到G:\test\testOption.txt和G:\test\testOption2.txt中
doExecPhantomJS_deleteFileAfterException("G:\test\testOption.txt,G:\test\testOption2.txt", "G:\test\1.png,G:\test\2.png", "G:\test\111.png,G:\test\222.png");
}
catch (Exception e)
{
e.printStackTrace();
}
Paragraph ph1 = ReportFormUtil.createImageParagraphByPath("1、段落标题111", "G:\test\111.png", 35, 35,"这是一段前缀描述信息111", "这是一段后缀描述信息111");
Paragraph ph2 = ReportFormUtil.createImageParagraphByPath("2、段落标题222", "G:\test\222.png", 35, 35, "这是一段前缀描述信息222", "这是一段后缀描述信息222");
List<Paragraph> phs = new ArrayList<Paragraph>();
phs.add(ph1);
phs.add(ph2);
ReportFormUtil.createPDFDocumentToDisk("封面名称", "小标题", "", phs, "G:\test\document.pdf");
}Tips:
二、关于如何自动生成默认样式的option.txt文件,不过多赘述:
我的主要做法是:option配置可以看成一个json格式的字符串,然后:
2、将option中的数据部分(想自定义的部分)用符号占位;
3、在需要生成图片时,结合业务计算出自定义数据并转成json,替换掉占位符填到option字符串中生成完整的带数据的option字符串。
3.测试结果

三、下载生成的PDF
@Override
public void download(HttpServletResponse response, HttpServletRequest request) throws BusinessException
{
// 选中的要导出的文档id
String id = request.getParameter("id");
if (StringUtils.isBlank(id))
{
return;
}
// 1.根据id找出文档信息
DocumentTaskModel taskModel = documentTaskDao.findById(Integer.valueOf(id));
// 2.下载
File file = new File(taskModel.getUrl());// taskModel.getUrl():该PDF文件的存放路径
try (FileInputStream in = new FileInputStream(file); ServletOutputStream out = response.getOutputStream();)
{
// 若未定义文件名,则使用文档配置中的默认文档名
String fileName = StringUtils.isNotBlank(taskModel.getName()) ? taskModel.getName()
: ReportFormEngine.getDocumentByKey(taskModel.getDocumentKey()).getName();
response.reset();
response.setContentType("application/x-msdownload");
response.setHeader("Content-Length", "" + file.length());
response.addHeader("Content-Disposition",
"attachment; filename=" + new String((fileName + ".pdf").getBytes("utf-8"), "iso8859-1"));
byte[] buff = new byte[CommonConstants.BYTE_BUFFER_LENGTH_5120];
int hasRead = -1;
while ((hasRead = in.read(buff, 0, buff.length)) > 0)
{
out.write(buff, 0, hasRead);
}
}
catch (FileNotFoundException e)
{
logger.error(e);
}
catch (IOException e)
{
logger.error(e);
}
catch (Exception e)
{
logger.error(taskModel.getUrl() + "下载文件失败!", e);
}
}ReportFormUtil
package com.smartsecuri.bp.cbb.reportform;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLEncoder;
import java.nio.charset.Charset;
import java.util.ArrayList;
import java.util.List;
import javax.servlet.ServletOutputStream;
import javax.servlet.http.HttpServletResponse;
import org.apache.commons.codec.binary.Base64;
import org.apache.commons.collections4.CollectionUtils;
import org.apache.commons.lang.StringUtils;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
import com.itextpdf.text.BaseColor;
import com.itextpdf.text.Chunk;
import com.itextpdf.text.Document;
import com.itextpdf.text.DocumentException;
import com.itextpdf.text.Element;
import com.itextpdf.text.Font;
import com.itextpdf.text.Image;
import com.itextpdf.text.PageSize;
import com.itextpdf.text.Paragraph;
import com.itextpdf.text.Phrase;
import com.itextpdf.text.pdf.BaseFont;
import com.itextpdf.text.pdf.PdfPCell;
import com.itextpdf.text.pdf.PdfPTable;
import com.itextpdf.text.pdf.PdfWriter;
import com.smartsecuri.bp.cbb.exception.BusinessException;
import com.smartsecuri.bp.cbb.utils.file.FileUtils;
import com.smartsecuri.bp.cbb.utils.other.CommonUtils;
import com.smartsecuri.bp.cbb.utils.system.IoUtils;
/**
* ClassName : ReportFormUtil <br/>
* Function : (PDF文档相关-主要用于生成报表) <br/>
* date : 2022年11月29日 下午5:32:18 <br/>
*
* @author
* @version
* @since JDK 1.8
*/
public class ReportFormUtil
{
private static final Logger logger = LogManager.getLogger(ReportFormUtil.class);
/**
* DEFAULT_LEADING : (默认行间距).
*/
public static final float DEFAULT_LEADING = 16f;
/**
* fontSize_normal : (正文字体大小11号).
*/
public static final float FONTSIZE_NORMAL = 11f;
/**
* fontSize_titile : (标题字体大小14号).
*/
public static final float FONTSIZE_TITILE = 14f;
/**
* FONTSIZE_COVER : (封面字体大小32号).
*/
public static final float FONTSIZE_COVER = 32f;
/**
* normalFont : (通用字体样式:宋体、11号).
*/
private static Font normalFont = null;
/**
* titleFont : (通用标题字体样式:宋体、14号、加粗).
*/
private static Font titleFont = null;
/**
* coverFont : (通用封面字体样式:宋体、28号、加粗).
*/
private static Font coverFont = null;
// windows 测试环境
private static final String phantomPath = "G:\test\phantomjs-2.1.1-windows\bin\phantomjs.exe";
private static final String JSpath = "G:\test\echarts-convert\echarts-convert.js";
// linux 环境
// private static String phantomPath = "/usr/local/phantomjs/bin/phantomjs";
// private static String JSpath = PathUtils.getProjectPath() + "common/reportform/echarts-convert.js";
/**
* getBaseFont : (获取可以解析中文的字体:使用宋体). <br/>
*
* @author
* @return
* @since JDK 1.8
*/
public static BaseFont getBaseFontChinese()
{
try
{
// 宋体资源文件路径
URL path = ReportFormUtil.class.getResource("/config/fonts/simsun.ttc");
return BaseFont.createFont(path + ",0", BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED);
// 本地main方法测试:使用windows自带的宋体文件
//return BaseFont.createFont("C://Windows//Fonts//simsun.ttc,0", BaseFont.IDENTITY_H, false);
}
catch (Exception e)
{
logger.error("设置字体样式失败", e);
return null;
}
}
/**
* getNormalFont : (获取普通正文字体样式). <br/>
*
* @author
* @return
* @since JDK 1.8
*/
public static Font getNormalFont()
{
if (normalFont == null)
{
BaseFont bfChinese = getBaseFontChinese();
normalFont = new Font(bfChinese, FONTSIZE_NORMAL, Font.NORMAL);
}
return normalFont;
}
/**
* getTitleFont : (获取标题通用字体). <br/>
*
* @author
* @return
* @since JDK 1.8
*/
public static Font getTitleFont()
{
if (titleFont == null)
{
BaseFont bfChinese = getBaseFontChinese();
titleFont = new Font(bfChinese, FONTSIZE_TITILE, Font.BOLD);
}
return titleFont;
}
/**
* getTitleFont : (获取封面通用字体). <br/>
*
* @author
* @return
* @since JDK 1.8
*/
public static Font getCoverFontFont()
{
if (coverFont == null)
{
BaseFont bfChinese = getBaseFontChinese();
coverFont = new Font(bfChinese, FONTSIZE_COVER, Font.BOLD);
}
return coverFont;
}
/**
* genFrontCover : (构建封面的文字和样式). <br/>
*
* @author
* @param coverName 封面标题
* @param subtitle 小标题——封面标题下一行文字,可以为null或空串,表示不填
* @param subscript 下标,可以为null或空串,表示不填
* @return
* @since JDK 1.8
*/
public static Paragraph genFrontCover(String coverName, String subtitle, String subscript)
{
if (StringUtils.isBlank(coverName))
{
return null;
}
// 生成封面
Paragraph frontCover = new Paragraph();
frontCover.setAlignment(Element.ALIGN_CENTER);
// 空10行
ReportFormUtil.addBlankLine(frontCover, Integer.parseInt("10"));
// 封面标题
frontCover.add(new Chunk(coverName, ReportFormUtil.getCoverFontFont()));
if (StringUtils.isNotBlank(subtitle))
{
ReportFormUtil.addBlankLine(frontCover, Integer.parseInt("2"));// 换行
// 小标题
frontCover.add(new Chunk(subtitle, ReportFormUtil.getTitleFont()));
}
if (StringUtils.isNotBlank(subscript))
{
// 换行
ReportFormUtil.addBlankLine(frontCover, Integer.parseInt("25"));
// companyName公司签名如:"慧盾信息安全科技(苏州)股份有限公司"
frontCover.add(new Chunk(subscript, ReportFormUtil.getNormalFont()));
}
return frontCover;
}
/**
* addBlankLine : (添加换行). <br/>
*
* @author
* @param paragraph 需要添加空行的段落
* @param lineNum 需要添加空行的个数
* @since JDK 1.8
*/
public static void addBlankLine(Paragraph paragraph, int lineNum)
{
if (paragraph == null)
{
return;
}
for (int i = 0; i < lineNum; i++)
{
paragraph.add(Chunk.NEWLINE);
}
}
/**
* createTable : (创建table段落). <br/>
*
* @author
* @param <T>
* @param list 构建table的数据
* @param title 该段落取的名字,标题默认居左
* @param methodNames 需要调用的方法名,用来获取单元格数据。通常是某个属性的get方法
* @param prefixDescribe 前缀附加文字描述
* @param suffixDescribe 后缀附加文字描述
* @return
* @since JDK 1.8
*/
public static <T> Paragraph createTable(List<T> list, String title, String[] tableHead, String[] methodNames,
String prefixDescribe, String suffixDescribe)
{
return createTable(list, FONTSIZE_NORMAL, FONTSIZE_TITILE, title, tableHead, methodNames,
prefixDescribe, suffixDescribe);
}
/**
* createTableByList : (创建table段落). <br/>
*
* @author
* @param <T>
* @param listData
* @param normalFontSize 正文字体大小
* @param titleFontSize 标题字体大小
* @param title 段落名称
* @param methodNames 获取表格属性的方法名
* @param prefixDescribe 前缀附加文字描述
* @param suffixDescribe 后缀附加文字描述
* @return
* @since JDK 1.8
*/
public static <T> Paragraph createTable(List<T> listData, float normalFontSize, float titleFontSize, String title,
String[] tableHead, String[] methodNames, String prefixDescribe, String suffixDescribe)
{
// 1.创建一个表格
PdfPTable table = new PdfPTable(methodNames.length);// 列数
// 2.构造表头
for (String head : tableHead)
{
head = StringUtils.isBlank(head) ? "" : head;
PdfPCell cell = new PdfPCell(new Phrase(head, getNormalFont()));
cell.setBackgroundColor(
new BaseColor(Integer.parseInt("124"), Integer.parseInt("185"), Integer.parseInt("252")));// 背景色
cell.setMinimumHeight(Float.parseFloat("15"));// 单元格最小高度
cell.setHorizontalAlignment(Element.ALIGN_CENTER);// 水平居中
cell.setVerticalAlignment(Element.ALIGN_CENTER);// 垂直居中
table.addCell(cell);
}
// 3.构造table数据
if (CollectionUtils.isEmpty(listData))
{
// 没有数据,添加一行空单元格,并返回
for (int i = 0; i < methodNames.length; i++)
{
table.addCell(new Phrase(" "));// 有一个空格,否则添加不了
}
}
else
{
// 有数据:构造table数据
for (T li : listData)
{
for (String name : methodNames)
{
Object obj = CommonUtils.invokeMethod(li, name);
String valueStr = obj == null ? " " : StringUtils.isEmpty(obj.toString()) ? " " : obj.toString();
PdfPCell cell = new PdfPCell(new Phrase(valueStr, getNormalFont()));
cell.setHorizontalAlignment(Element.ALIGN_CENTER);// 水平居中
table.addCell(cell);
}
}
}
// 4.返回段落
return createParagraph(table, title, prefixDescribe, suffixDescribe);
}
/**
* addDataToTable : (从段落中找到table元素,向该table中追加数据). <br/>
*
* @author
* @param <T>
* @param paragraph table表格段落
* @param listData 需要追加的数据
* @param methodNames 每个数据获取的方法名
* @since JDK 1.8
*/
public static <T> void addDataToTable(Paragraph paragraph, List<T> listData, List<String> methodNames)
{
for (Element ele : paragraph)
{
if (!(ele instanceof PdfPTable))
{
// 不是table元素,直接跳过
continue;
}
// 找到第一个table元素
PdfPTable table = (PdfPTable) ele;
for (T data : listData)
{
for (String name : methodNames)
{
String valueStr = CommonUtils.invokeMethod(data, name).toString();
PdfPCell cell = new PdfPCell(new Phrase(valueStr, getNormalFont()));
cell.setHorizontalAlignment(Element.ALIGN_CENTER);// 单元格文字水平居中
table.addCell(cell);
}
}
break;
}
}
/**
* createImage : (根据图片的base64加密文件创建pdf图片段落). <br/>
*
* @author
* @param picBase64Info 传入图片的base64信息,或传入前台echart通过调用getDataURL()方法获取的图片信息都可以
* @param title 段落标题
* @param percentX 图片缩放比例X轴
* @param percentY 图片缩放比例Y轴
* @param prefixDescribe 前缀附加文字描述
* @param suffixDescribe 后缀附加文字描述
*
* @return 返回图片段落
* @since JDK 1.8
*/
public static Paragraph createImageFromEncodeBase64(String picBase64Info, String title, float percentX,
float percentY, String prefixDescribe, String suffixDescribe)
{
// 1.获取图片
Element element = analysisPicBase64Info(picBase64Info);
// 2.创建段落,并添加标题,设置缩放
return createImageParagraph(element, title, percentX, percentY, prefixDescribe, suffixDescribe);
}
/**
* createImageFromEncodeBase64_batch : (批量创建图片段落). <br/>
*
* @author
* @param picBase64Infos 传入图片的base64信息,或传入前台echart通过调用getDataURL()方法获取的图片信息都可以
* @param titles 每个段落的标题
* @param percentXs X轴缩放比例
* @param percentYs Y轴缩放比例
* @param titleCenter 标题是否居中,true-居中、false-默认居左
* @return 返回由多个图片段落组合后的整个段落
* @since JDK 1.8
*/
public static Paragraph createImageFromEncodeBase64_batch(List<String> picBase64Infos, List<String> titles,
List<Float> percentXs, List<Float> percentYs)
{
Paragraph paragraphs = new Paragraph(DEFAULT_LEADING);
for (int i = 0; i <= picBase64Infos.size(); i++)
{
Paragraph imagePara = createImageFromEncodeBase64(picBase64Infos.get(i), titles.get(i), percentXs.get(i),
percentYs.get(i), null, null);
if (!imagePara.isEmpty())
{
paragraphs.add(imagePara);
// 换行
paragraphs.add(Chunk.NEWLINE);
}
}
return paragraphs;
}
/**
* createPicParagraphByPath : (根据图片位置生成图片段落段落). <br/>
*
* @author
* @param title 段落标题
* @param picPath 图片所在磁盘路径
* @param percentX 图片缩放比例X轴
* @param percentY 图片缩放比例Y轴
* @param titleCenter 标题是否居中,true-居中、false-默认居左
* @param prefixDescribe 前缀附加文字描述
* @param suffixDescribe 后缀附加文字描述
* @return
* @since JDK 1.8
*/
public static Paragraph createImageParagraphByPath(String title, String picPath, float percentX, float percentY,
String prefixDescribe, String suffixDescribe)
{
// 1.获取图片
Element element = analysisPicByPath(picPath);
// 2.创建段落,并添加标题,设置缩放
return createImageParagraph(element, title, percentX, percentY, prefixDescribe, suffixDescribe);
}
/**
* createPicParagraphByPath : (根据图片位置生成图片段落段落). <br/>
*
* @author
* @param picElement 图片元素
* @param title 段落标题
* @param percentX 图片缩放比例X轴
* @param percentY 图片缩放比例Y轴
* @param prefixDescribe 前缀附加文字描述
* @param suffixDescribe 后缀附加文字描述
* @return
* @since JDK 1.8
*/
public static Paragraph createImageParagraph(Element picElement, String title, float percentX, float percentY,
String prefixDescribe, String suffixDescribe)
{
if (picElement == null)
{
return new Paragraph();
}
try
{
if (!(picElement instanceof Image))
{
// 1. 图片解析失败
logger.error(title + ":picElement is not instanceof Image");
return new Paragraph();
}
// 2.设置图片缩放比例
Image image = (Image) picElement;
image.scalePercent(percentX, percentY);
image.setAlignment(Element.ALIGN_CENTER);
// 3.创建并返回图片段落
return createParagraph(image, title, prefixDescribe, suffixDescribe);
}
catch (Exception e)
{
logger.error(e);
// 空段落
return new Paragraph();
}
}
/**
* createTxtParagraph : (创建文本段落). <br/>
*
* @author
* @param strings 多行句子
* @param title 段落标题
* @param titleCenter 标题居中
* @param prefixDescribe 前缀附加文字描述
* @param suffixDescribe 后缀附加文字描述
* @return
* @since JDK 1.8
*/
public static Paragraph createTxtParagraph(List<String> strings, String title, String prefixDescribe,
String suffixDescribe)
{
Phrase phrase = new Phrase();
for (String li : strings)
{
// 多行句子拼装
phrase.add(new Chunk(li, getNormalFont()));
phrase.add(Chunk.NEWLINE);
}
return createParagraph(phrase, title, prefixDescribe, suffixDescribe);
}
/**
* createParagraph : (根据元素创建段落). <br/>
*
* @author
* @param element
* @param title 段落标题
* @param prefixDescribe 前缀附加文字描述
* @param suffixDescribe 后缀附加文字描述
* @return
* @since JDK 1.8
*/
public static Paragraph createParagraph(Element element, String title, String prefixDescribe,
String suffixDescribe)
{
title = StringUtils.isEmpty(title) ? "" : title;
try
{
// 1.创建段落,并添加标题,添加前缀描述
Paragraph paragraph = createParagraph(title, prefixDescribe);
paragraph.add(element);
// 2.后缀描述
if (StringUtils.isNotBlank(suffixDescribe))
{
addBlankLine(paragraph, 1);// 换行符
paragraph.add(new Paragraph(DEFAULT_LEADING, suffixDescribe, getNormalFont()));
}
return paragraph;
}
catch (Exception e)
{
logger.error(e);
// 空段落
return new Paragraph();
}
}
/**
* createParagraph : (创建段落). <br/>
*
* @author
* @param title
* @param prefixDescribe 前缀附加文字描述
* @return
* @since JDK 1.8
*/
public static Paragraph createParagraph(String title, String prefixDescribe)
{
Paragraph paragraph = new Paragraph(DEFAULT_LEADING);
if (StringUtils.isNotEmpty(title))
{
paragraph.add(new Phrase(DEFAULT_LEADING, title, getTitleFont()));
addBlankLine(paragraph, 2);
}
// 2.前缀描述
if (StringUtils.isNotBlank(prefixDescribe))
{
paragraph.add(new Paragraph(prefixDescribe, getNormalFont()));
ReportFormUtil.addBlankLine(paragraph, Integer.parseInt("1"));// 换行
}
return paragraph;
}
/**
* createPDFDocument : (创建文档,默认纸张大小A4). <br/>
*
* @author WuTingTing
* @return
* @since JDK 1.8
*/
public static Document createPDFDocument()
{
return new Document(PageSize.A4, Float.parseFloat("36"), Float.parseFloat("36"), Float.parseFloat("36"),
Float.parseFloat("36"));
}
/**
* createPDFDocumentToDisk : (生成PDF文档保存到磁盘). <br/>
*
* @author WuTingTing
* @param coverName 封面标题
* @param subtitle 小标题——封面标题下一行文字,可以为null或空串,表示不填
* @param subscript 下标,可以为null或空串,表示不填
* @param paragraphs 段落
* @param documentPath 文件保存全路径
* @return
* @since JDK 1.8
*/
public static boolean createPDFDocumentToDisk(String coverName, String subtitle, String subscript,
List<Paragraph> paragraphs, String documentPath)
{
// 1.创建文档,设置文档页面大小,页边距
Document document = createPDFDocument();
// 2.封面
Paragraph cover = genFrontCover(coverName, subtitle, subscript);
// 3.生成文档并保存到指定路径
return downloadDocument(document, cover, paragraphs, documentPath);
}
/**
* exportDocument : (生成并下载PDF文档-通过response响应实现下载). <br/>
*
* @author
* @param document 文档对象
* @param cover 封面:若不是null,则会先添加封面,并另起新页面添加段落;若是null表示没有封面。
* @param paragraphs 需要组成PDF文件的各个段落
* @param response 请求的响应对象(提示:前台无法通过ajax请求触发浏览器的下载,可以通过表单提交的方式)
* @param fileName 生成的文件名称,不需要加pdf后缀
* @since JDK 1.8
*/
public static void exportDocument(Document document, Paragraph cover, List<Paragraph> paragraphs,
HttpServletResponse response, String fileName)
{
try (ServletOutputStream out = response.getOutputStream())
{
response.setContentType("application/binary;charset=UTF-8");
response.setHeader("Content-Disposition", "attachment;fileName=" + URLEncoder.encode(fileName + ".pdf", "UTF-8"));
PdfWriter writer = PdfWriter.getInstance(document, out);
writer.setStrictImageSequence(true);// 设置图片位置精确放置
// 1.打开文档
document.open();
if (cover != null)
{
// 2.有封面:添加封面,并另起一页,用来塞后面的段落
document.add(cover);
document.newPage(); // 另起一页
}
StringBuilder errorMsg = new StringBuilder();
for (int i = 0; i < paragraphs.size(); i++)
{
try
{
// 将段落添加到文档
document.add(paragraphs.get(i));
// 换行
document.add(Chunk.NEWLINE);
}
catch (DocumentException e)
{
errorMsg.append("PDF文件生成出错,请检查第:").append(i).append("个段落");
}
}
if (!StringUtils.isEmpty(errorMsg.toString()))
{
logger.error(errorMsg);
}
// 关闭文档
document.close();
// 将数据输出
out.flush();
out.close();
}
catch (IOException e)
{
logger.error("生成PDF文档并下载,IOException:", e);
}
catch (DocumentException e)
{
logger.error("生成PDF文档并下载,DocumentException:", e);
}
finally
{
document.close();
}
}
/**
* downloadDocument : (生成PDF文档并保存到磁盘). <br/>
*
* @author
* @param document 文档对象
* @param cover 封面:若不是null,则会先添加封面,并另起新页面添加段落
* @param paragraphs 需要组成PDF文件的段落
* @param response 请求的响应对象
* @param fileName 生成的文件名称,不需要加pdf后缀
* @return true成功、false失败
* @since JDK 1.8
*/
public static boolean downloadDocument(Document document, Paragraph cover, List<Paragraph> paragraphs,
String documentPath)
{
FileOutputStream out = null;
try
{
File file = new File(documentPath);
if (!FileUtils.createFile(file))
{
return false;
}
out = new FileOutputStream(file);
PdfWriter writer = PdfWriter.getInstance(document, out);
writer.setStrictImageSequence(true);// 设置图片位置精确放置
// 打开文档
document.open();
if (cover != null)
{
document.add(cover);
// 起新页面
document.newPage();
}
StringBuilder errorMsg = new StringBuilder();
for (int i = 0; i < paragraphs.size(); i++)
{
try
{
// 将段落添加到文档
document.add(paragraphs.get(i));
// 换行
document.add(Chunk.NEWLINE);
}
catch (DocumentException e)
{
errorMsg.append("PDF文件生成出错,请检查第:").append(i).append("个段落");
}
}
if (!StringUtils.isBlank(errorMsg.toString()))
{
logger.error(errorMsg);
}
// 关闭文档
document.close();
out.flush();
IoUtils.close(out);
}
catch (Exception e)
{
logger.error("生成PDF文档并下载,出错:", e);
return false;
}
finally
{
// 关闭文档
document.close();
IoUtils.close(out);
}
return true;
}
/**
* analysisPicBase64Info : (解析base64图片信息). <br/>
*
* @author
* @param picBase64Info 传入图片的base64信息,或传入前台echart通过调用getDataURL()方法获取的图片信息都可以
* @return 图片经过base64解码后的信息
* @since JDK 1.8
*/
public static Element analysisPicBase64Info(String picBase64Info)
{
if (StringUtils.isEmpty(picBase64Info))
{
// 空段落
return new Paragraph();
}
// 1.获取图片base64字符串信息:若入参是通过前台echarts调用getDataURL()方法获取的,则该字符串包含逗号,且则逗号后面的内容才是图片的信息
String pictureInfoStr = picBase64Info.indexOf(",") == -1 ? picBase64Info : picBase64Info.split(",")[1];
// 2.将图片信息进行base64解密
byte[] imgByte = Base64.decodeBase64(pictureInfoStr);
// 对异常的数据进行处理
/**
* .图片的原始表达ascii码范围是0-255,
* .这里面有一些不可见的编码。然后为了图片正确传输才转成编码base64的0-63,
* .当从base64转成byte时,byte的范围是[-128,127],那么此时就会可能产生负数,而负数不是在ascii的范围里,所以需要转换一下
*/
for (int i = 0; i < imgByte.length; i++)
{
if (imgByte[i] < 0)
{
imgByte[i] += 256;
}
}
try
{
return Image.getInstance(imgByte);
}
catch (Exception e)
{
logger.error("analysisPicBase64Info error", e);
return new Paragraph();
}
}
/**
* analysisPicBase64Info : (根据图片地址解析并生成图片段落). <br/>
*
* @author
* @param picPath 图片路径
* @return
* @since JDK 1.8
*/
public static Element analysisPicByPath(String picPath)
{
if (StringUtils.isEmpty(picPath))
{
return null;// 空段落
}
File file = new File(picPath);
if (!file.exists())
{
// 图片文件不存在
return null;// 空段落
}
try (FileInputStream in = new FileInputStream(file))
{
byte[] imgByte = new byte[(int) file.length()];
in.read(imgByte);
/**
* .图片的原始表达ascii码范围是0-255,
* .这里面有一些不可见的编码。然后为了图片正确传输才转成编码base64的0-63,
* .当从base64转成byte时,byte的范围是[-128,127],那么此时就会可能产生负数,而负数不是在ascii的范围里,所以需要转换一下
*/
for (int i = 0; i < imgByte.length; i++)
{
if (imgByte[i] < 0)
{
imgByte[i] += 256;
}
}
return Image.getInstance(imgByte);
}
catch (Exception e)
{
logger.error("analysisPicBase64Info error", e);
return null;
}
}
/**
* analysisPicBase64Info_batch : (批量解析base64加密的图片信息,生成Image对象). <br/>
*
* @author
* @param picBase64Infos 传入图片的base64信息,或传入前台echart通过调用getDataURL()方法获取的图片信息都可以
* @return
* @since JDK 1.8
*/
public static List<Element> analysisPicBase64Info_batch(List<String> picBase64Infos)
{
List<Element> images = new ArrayList<Element>();
for (String li : picBase64Infos)
{
Element image = analysisPicBase64Info(li);
images.add(image);
}
return images;
}
/**
* doExecPhantomJS_deleteFileAfterException : (执行:浏览器加载option,渲染并截图保存到制定文件,若过程中出现错误则删除picTmpPath、picPath中生成的文件). <br/>
* .【注意】支持一次多个,多个时路径以逗号隔开,且jsonPath和picPath的个数要一致。
*/
public static void doExecPhantomJS_deleteFileAfterException(String txtPath, String picTmpPath, String picPath)
throws BusinessException, Exception
{
doExecPhantomJS_deleteFileAfterException(txtPath, picTmpPath, picPath, null, null);
}
/**
* doExecPhantomJS_deleteFileAfterException : (执行:浏览器加载option,渲染并截图保存到制定文件,若过程中出现错误则删除picTmpPath、picPath中生成的文件). <br/>
* .【注意】支持一次多个,多个时路径以逗号隔开,且jsonPath和picPath的个数要一致。
* .单个例子:
* txtPath="/a/a.json"
* picTmpPath="/a/tmp/a.png"
* picPath="/a/a.png"
* width=1000
* height=600
*
* .多个例子:
* txtPath="/a/a.txt,/b/b.json,/c/c.txt"
* picTmpPath="/a/tmp/a.png,/b/tmp/b.png,/c/tmp/c.png"
* picPath="/a/a.png,/b/b.png,/c/c.png"
* width=1000,1000,1000
* height=600,600,600,600
*
* @author WuTingTing
* @param txtPath 图表option信息的txt文件全路径
* @param picTmpPath 图片临时存放路径,生成后将转移到picPath路径下
* @param picPath 图片文件全路径
* @param width 自定义截图宽度
* @param height 自定义截图高度
* @throws Exception
* @since JDK 1.8
*/
public static void doExecPhantomJS_deleteFileAfterException(String txtPath, String picTmpPath, String picPath,
String width, String height) throws BusinessException, Exception
{
try
{
doExecPhantomJS(txtPath, picTmpPath, picPath, width, height);
}
catch (Exception e)
{
// 执行过程中出错,删除本次执行中可能生成的文件,不删除txtPath是防止该文件为默认内置文件
String[] picTmpPaths = picTmpPath.split(",");
String[] picPaths = picPath.split(",");
for (String li : picTmpPaths)
{
FileUtils.delFile(li);
}
for (String li : picPaths)
{
FileUtils.delFile(li);
}
if (e instanceof BusinessException)
{
logger.error(((BusinessException) e).getMsg());
throw new BusinessException().setMsg(((BusinessException) e).getMsg());
}
else
{
throw new Exception(e);
}
}
}
/**
* doExecPhantomJS : (执行:浏览器加载option,渲染并截图保存到制定文件). <br/>
* .【注意】支持一次多个,多个时路径以逗号隔开,且jsonPath和picPath的个数要一致。
* .单个例子:
* txtPath="/a/a.json"
* picTmpPath="/a/tmp/a.png"
* picPath="/a/a.png"
*
* .多个例子:
* txtPath="/a/a.txt,/b/b.json,/c/c.txt"
* picTmpPath="/a/tmp/a.png,/b/tmp/b.png,/c/tmp/c.png"
* picPath="/a/a.png,/b/b.png,/c/c.png"
*
* @author WuTingTing
* @param txtPath 图表option信息的txt文件全路径
* @param picTmpPath 图片临时存放路径,生成后将转移到picPath路径下
* @param picPath 图片文件全路径
* @throws Exception
* @since JDK 1.8
*/
private static void doExecPhantomJS(String txtPath, String picTmpPath, String picPath, String width, String height)
throws BusinessException, Exception
{
String cmd = getCMD(txtPath, picTmpPath, picPath, width, height);
logger.info("图片生成命令:" + cmd);
BufferedReader processInput = null;
// 检查文件是否存在
boolean existP = FileUtils.fileExists(phantomPath);
boolean existJ = FileUtils.fileExists(JSpath);
if (!existP || !existJ)
{
throw new BusinessException()
.setMsg("生成图片必要文件缺失:" + (!existP ? "phantomjs " : "") + (!existJ ? "echarts-convert.js、" : ""));
}
try
{
Process process = Runtime.getRuntime().exec(cmd);
processInput = new BufferedReader(
new InputStreamReader(process.getInputStream(), Charset.forName("UTF-8")));
String line = "";
while ((line = processInput.readLine()) != null)
{
// 执行信息打印
logger.info(line);
}
int waitFor = process.waitFor();
if (waitFor != 0)
{
logger.info("图片生成过程,非正常退出,请检查是否存在异常");
}
}
finally
{
if (processInput != null)
{
try
{
processInput.close();
}
catch (IOException e)
{
logger.error("io close fail");
}
}
}
}
/**
* getCMD : (拼接命令). <br/>
*
* @author
* @param txtPath 图表option信息的txt文件全路径
* @param picTmpPath 图片临时存放路径,生成后将转移到picPath路径下
* @param picPath 图片文件全路径
* @param width 自定义截图宽度
* @param height 自定义截图高度
* @return
* @throws BusinessException
* @since JDK 1.8
*/
private static String getCMD(String txtPath, String picTmpPath, String picPath, String width, String height)
throws BusinessException
{
if (StringUtils.isBlank(txtPath) || StringUtils.isBlank(picTmpPath) || StringUtils.isBlank(picPath))
{
logger.error("txtPath or picTmpPath or picPath is blank");
throw new BusinessException().setMsg("doExecPhantomJS 入参错误");
}
if (StringUtils.isNotBlank(width) && StringUtils.isNotBlank(height))
{
return phantomPath + " " + JSpath + " -txtPath " + txtPath + " -picTmpPath " + picTmpPath + " -picPath "
+ picPath + " -width " + width + " -height " + height;
}
else
{
// 未自定义截图宽度和高度,会使用默认宽、高
return phantomPath + " " + JSpath + " -txtPath " + txtPath + " -picTmpPath " + picTmpPath + " -picPath "
+ picPath;
}
}
public static void main(String[] args)
{
try
{
// 测试同时生成两张图
// 注意:要先手动创建两个空文件G:\test\1.png和G:\test\2.png;要提前将echarts的option数据写到G:\test\testOption.txt和G:\test\testOption2.txt中
doExecPhantomJS_deleteFileAfterException("G:\test\testOption.txt,G:\test\testOption2.txt", "G:\test\1.png,G:\test\2.png", "G:\test\111.png,G:\test\222.png");
}
catch (Exception e)
{
e.printStackTrace();
}
Paragraph ph1 = ReportFormUtil.createImageParagraphByPath("1、段落标题111", "G:\test\111.png", 35, 35,"这是一段前缀描述信息111", "这是一段后缀描述信息111");
Paragraph ph2 = ReportFormUtil.createImageParagraphByPath("2、段落标题222", "G:\test\222.png", 35, 35, "这是一段前缀描述信息222", "这是一段后缀描述信息222");
List<Paragraph> phs = new ArrayList<Paragraph>();
phs.add(ph1);
phs.add(ph2);
ReportFormUtil.createPDFDocumentToDisk("封面名称", "小标题", "", phs, "G:\test\document.pdf");
}
}
注意:
我自己尝试后发现,phantomJS调用的js里面若用了一些较新的语法,phantomJS是不支持的,例如:const、let、=>、带默认值的函数function test( a=1,b=[] ){} 、
原文地址:https://blog.csdn.net/qq_41773784/article/details/131592864
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_38238.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!







