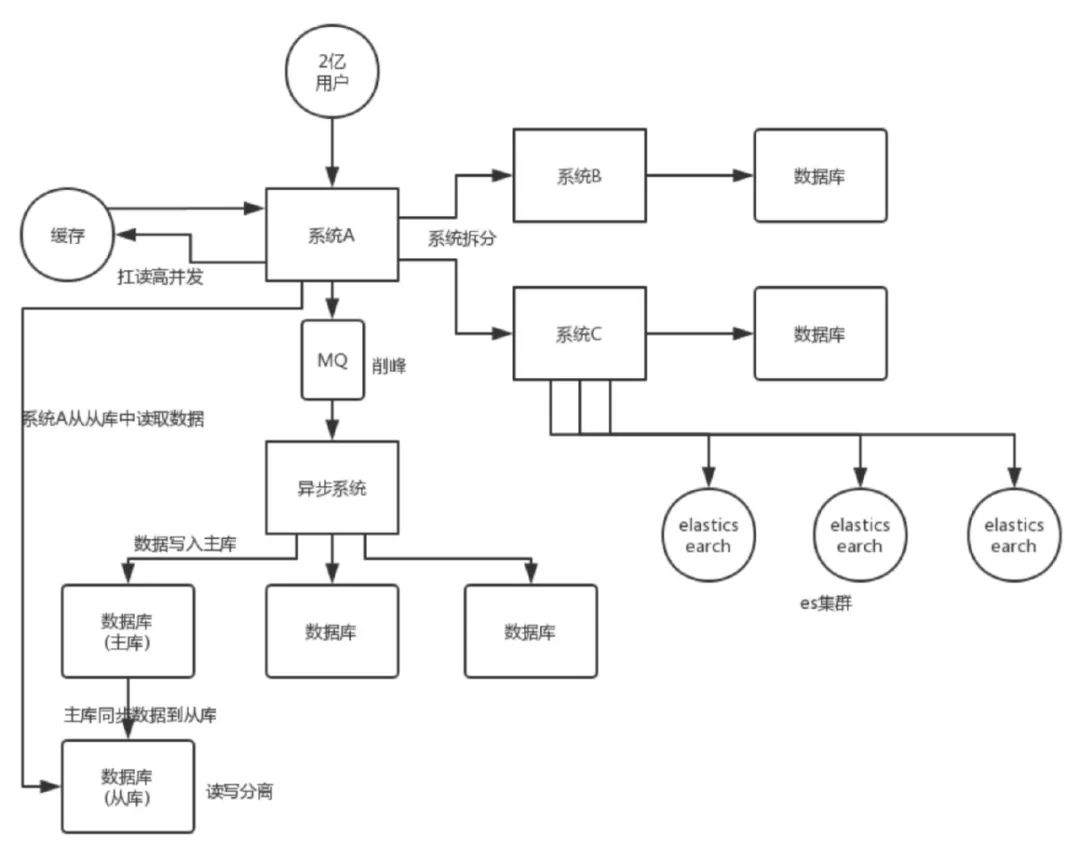
前言
Databricks 已经成为了数据科学的必备工具,今时今日你已经很难抛开它来谈大数据,它常用于做复杂的ETL中的T, 数据分析,数据挖掘等,特别适用于做数据建模,机器学习等。
那么顺应时代,现在也来看看这个工具的内容。首先要有一个环境,基于Azure 的Databricks简称ADB。托管在Azure 上的Databricks已经被Azure进行了很大的优化, 在搭建时只需要简单的几步即可拥有一个环境,不过要提醒一句ADB的集群并不便宜,用完马上删掉或停止, 否则一晚过百美金就会烧掉。
搭建环境
步骤1: 创建ADB workspace
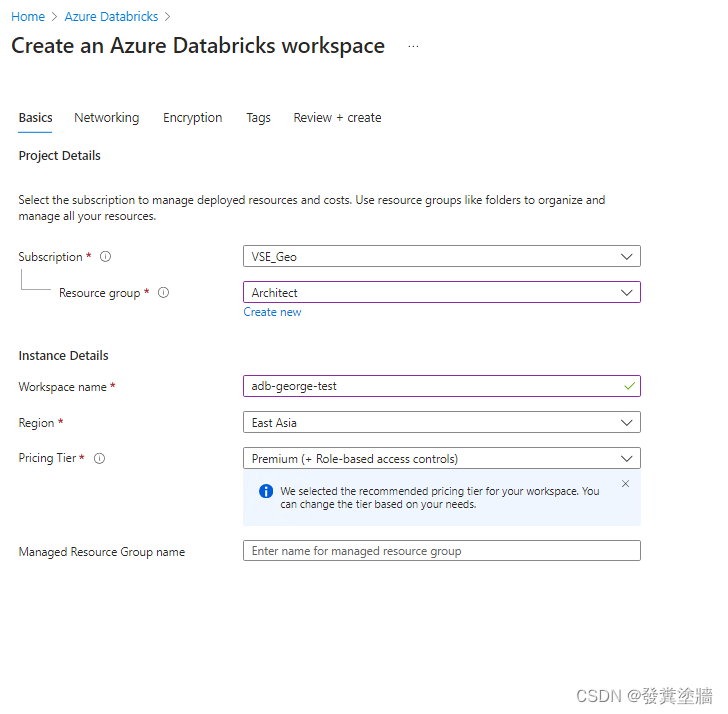
可以把Workspace想象成一个装在Azure上的应用程序,然后通过它进入Databricks的环境。通过下图,创建一个workspace:
创建的步骤很简单,提供一些简单信息,对于pricing tier处,可以先按默认选择,在实际环境中则需要考虑具体的费用和用法。
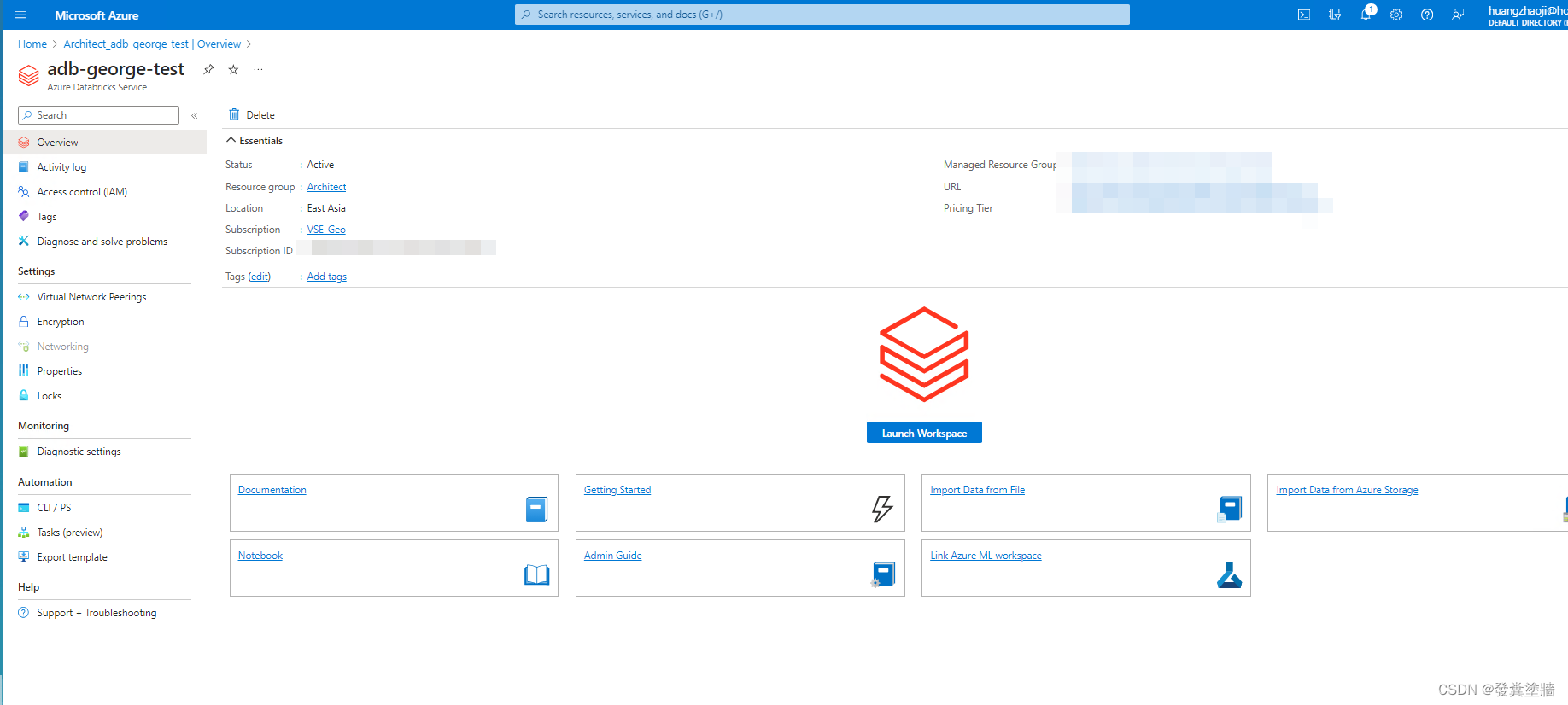
Databricks 内部布局
通过workspace进去之后可以看到下图的布局,ADB 的版本更新可能会导致布局的偏差,不过基本功能都不会变。
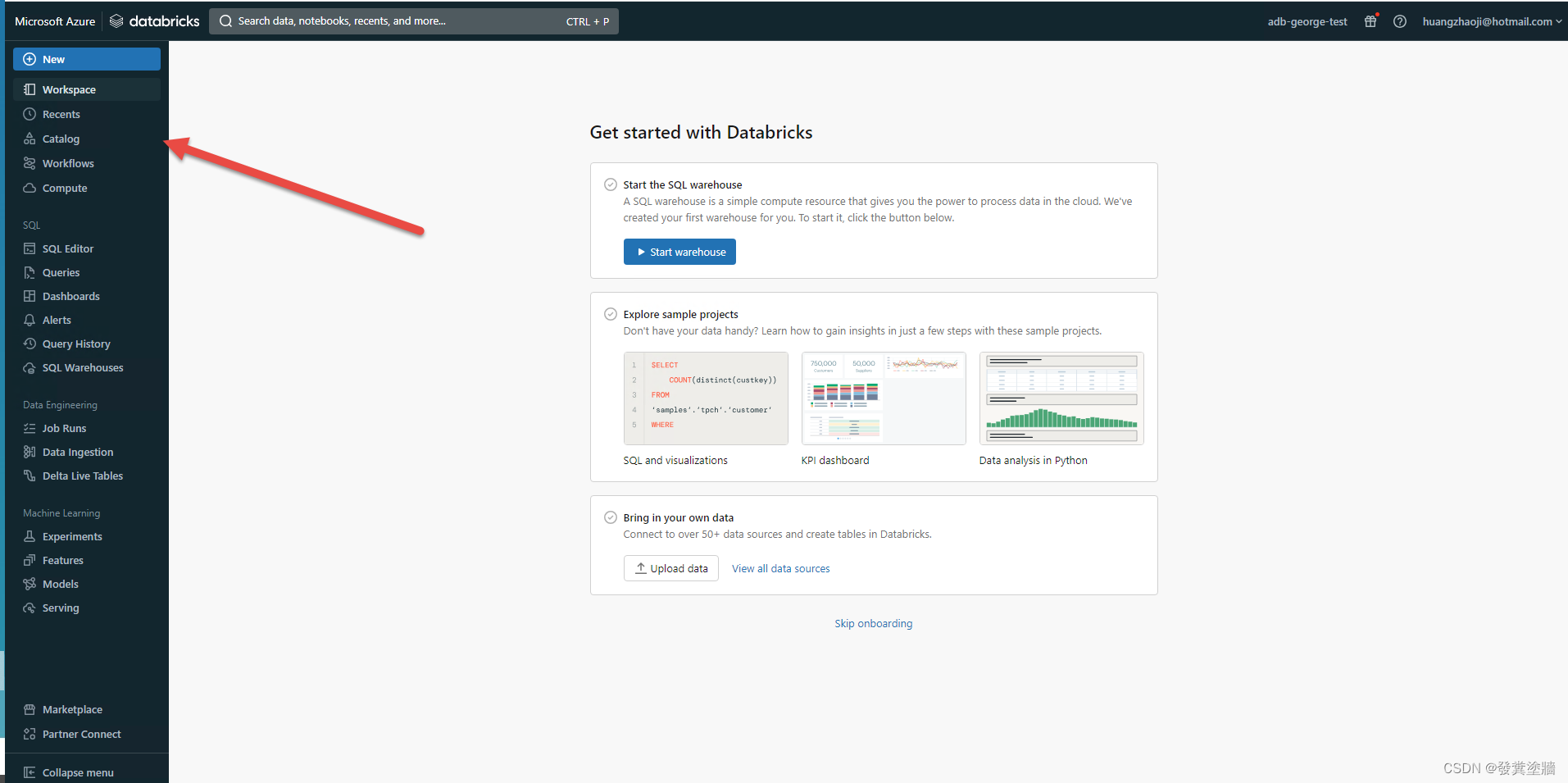
我们主要用到的一些导航栏有:
- Workspace: 通过一个“文件系统”把你的notebooks进行逻辑分组。默认情况下会有两个:Shared 和Users, Shared 文件夹用来存储共同协作notebooks。 users则只给创建的用户自己访问。可以在这里进行权限控制来保证多用户使用时的安全性。
- Recents:存储最近访问的资源列表。
- Compute:ADB的核心运算组件——集群所在地。
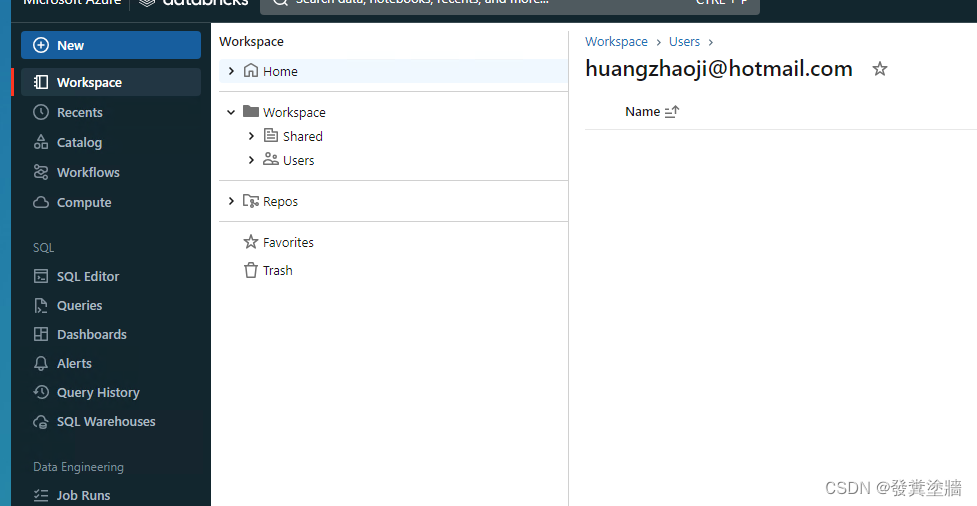
步骤3 创建集群
除了权限, ADB 中常规的必要操作就是创建和管理集群, 从Compute导航栏进去,点击创建集群:
集群选项不是非常多,最主要的部分是节点(min/ max workers)这个决定你运行时的费用和性能。还有自动停止时间,如果你担心忘记了手动停止,那么就这下图第二个箭头处填上合适的时间,让集群在没有活动后的多少分钟内停止。
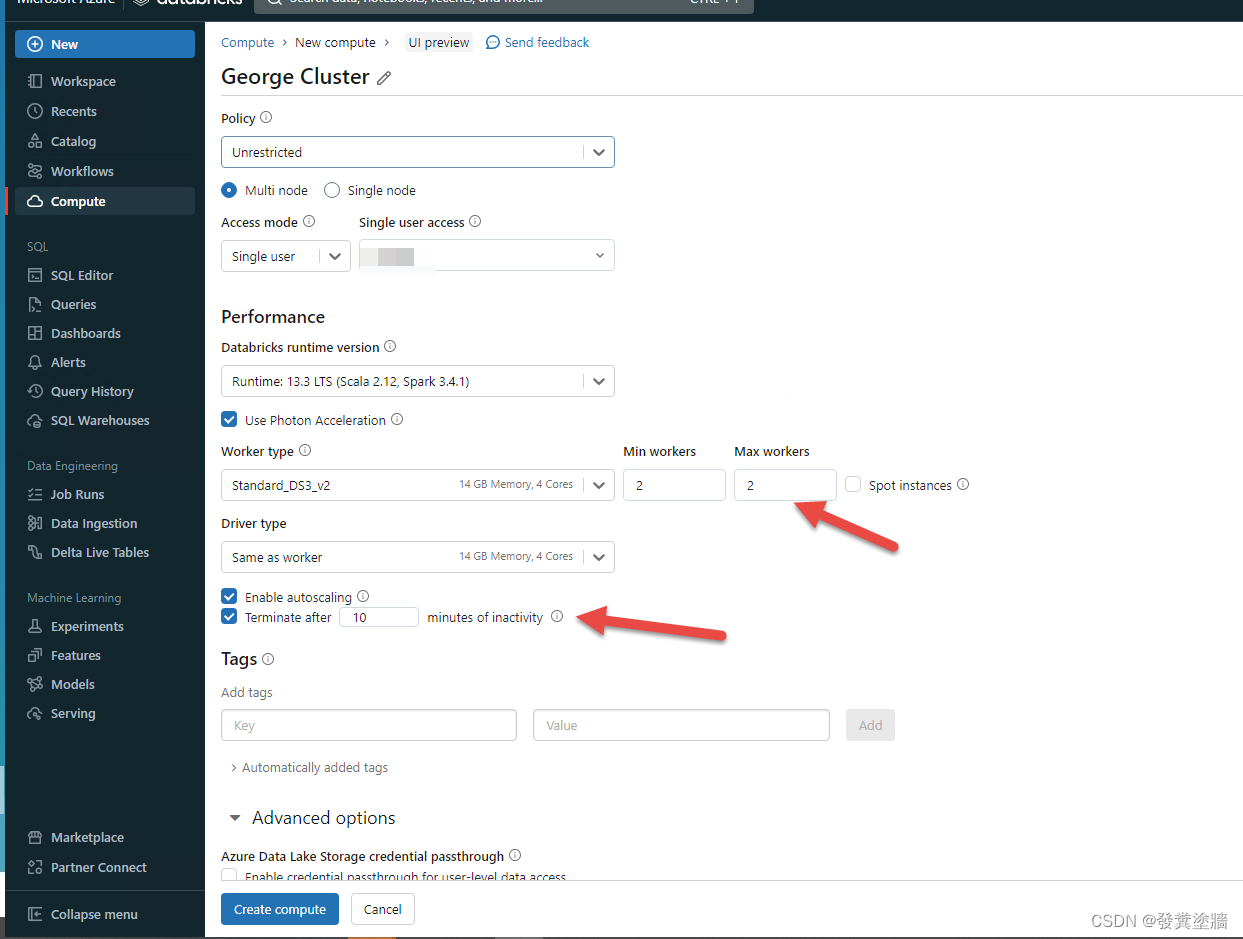
创建时会出现下面左边箭头的图标,叫作pin cluster, ADB 的集群有个特性, 当集群建立后闲置30天都没有被用过,就会自动销毁,通过pin住集群可以避免在重要的环境下集群的异常消失。
集群创建后,在右边箭头中可以开始,停止集群。

创建完毕后的集群样子:
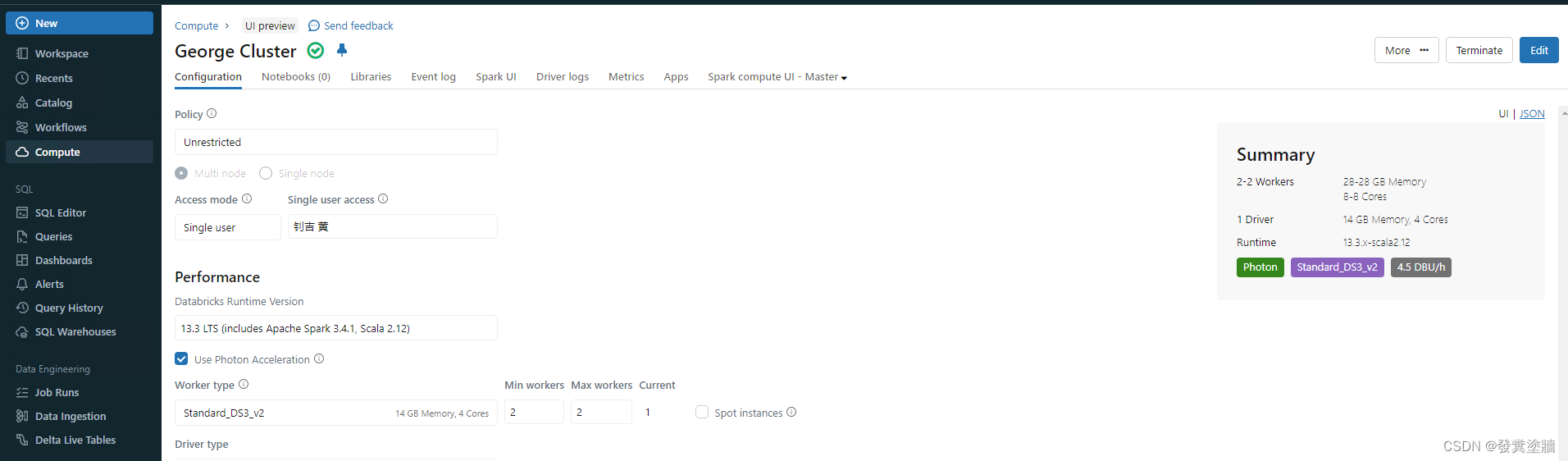
到此为止,物理上的搭建已经初步完成。下一文将对ADB 的集群进行更深入的研究,因为它实在太重要,而且费用贵。
原文地址:https://blog.csdn.net/DBA_Huangzj/article/details/134681201
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_41310.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!