列表
在实际开发中,经常需要将一组(不只一个)数据存储起来,以便后边的代码使用。列表就是这样的一个数据结构。
列表会将所有元素都放在一对中括号[ ]里面,相邻元素之间用逗号,分隔,如下所示:
[element1, element2, element3, ..., elementn]不同于C,java等语言的数组,python的列表可以存放不同的,任意的数据类型对象。
l = [123,"yuan",True]
print(l,type(l))
# 注意
a,b = [1,2]
print(a,b)序列操作
列表是 Python 序列的一种,我们可以使用索引(Index)访问列表中的某个元素(得到的是一个元素的值),也可以使用切片访问列表中的一组元素(得到的是一个新的子列表)。
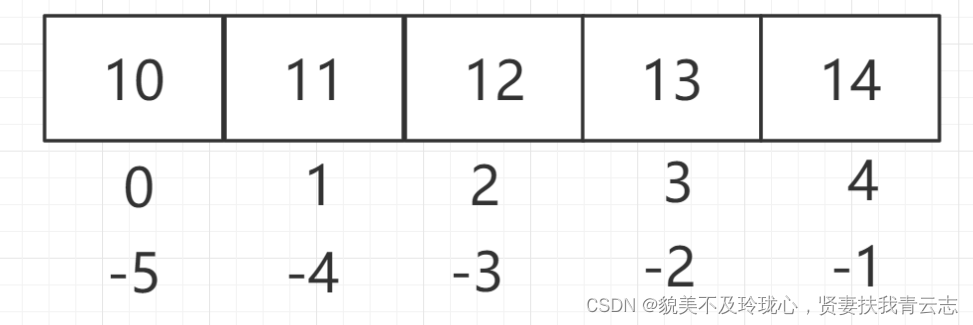
l = [10,11,12,13,14]
print(l[2]) # 12
print(l[-1]) # 14l = [10,11,12,13,14]
print(l[2:5])
print(l[-3:-1])
print(l[:3])
print(l[1:])
print(l[:])
print(l[2:4])
print(l[-3:-1])
print(l[-1:-3])
print(l[-1:-3:-1])
print(l[::2])2、取出元素不包含结束位置对应的索引,列表最后一个元素使用
list[len(slice)]获取;5、两者同时缺省时,与列表本身等效;
l = [10,11,12,13,14]
print(20 in l) # False
print(12 in l) # Truel1 = [1,2,3]
l2 = [4,5,6]
print(l1+l2) # [1, 2, 3, 4, 5, 6]- 循环列表
for name in ["张三",'李四',"王五"]:
print(name)
for i in range(10): # range函数: range(start,end,step)
print(i)
# 基于for循环从100打印到1
for i in range(100,0,-1):
print(i)列表内置方法
l = [1,2,3]| 方法 | 作用 | 示例 | 结果 |
|---|---|---|---|
append() |
向列表追加元素 | l.append(4) |
l:[1, 2, 3, 4] |
insert() |
向列表任意位置添加元素 | l.insert(0,100) |
l:[100, 1, 2, 3] |
extend() |
向列表合并一个列表 | l.extend([4,5,6]) |
l:[1, 2, 3, 4, 5, 6] |
pop() |
根据索引删除列表元素(为空删除最后一个元素) | l.pop(1) |
l:[1, 3] |
remove() |
根据元素值删除列表元素 | l.remove(1) |
l:[2, 3] |
clear() |
清空列表元素 | l.clear() |
l:[] |
sort() |
排序(升序) | l.sort() |
l:[1,2,3] |
reverse() |
翻转列表 | l.reverse() |
l:[3,2,1] |
count() |
元素重复的次数 | l.count(2) |
返回值:1 |
index() |
查找元素对应索引 | l.index(2) |
返回值:1 |
# 增删改查: [].方法()
# (1) ******************************** 增(append,insert,extend) ****************
l1 = [1, 2, 3]
# append方法:追加一个元素
l1.append(4)
print(l1) # [1, 2, 3, 4]
# insert(): 插入,即在任意位置添加元素
l1.insert(1, 100) # 在索引1的位置添加元素100
print(l1) # [1, 100, 2, 3, 4]
# 扩展一个列表:extend方法
l2 = [20, 21, 22, 23]
# l1.append(l2)
l1.extend(l2)
print(l1) # [1, 100, 2, 50, 3, 4,[20,21,22,23]]
# 打印列表元素个数python内置方法:
print(len(l1))
# (2) ******************************** 删(pop,remove,clear) **********************
l4 = [10, 20, 30, 40, 50]
# 按索引删除:pop,返回删除的元素
# ret = l4.pop(2)
# print(ret)
# print(l4) # [10, 20, 40, 50]
# 按着元素值删除
l4.remove(30)
print(l4) # [10, 20, 40, 50]
# 清空列表
l4.clear()
print(l4) # []
# (3) ******************************** 修改(没有内置方法实现修改,只能基于索引赋值) ********
l5 = [10, 20, 30, 40, 50]
# 将索引为1的值改为200
l5[1] = 200
print(l5) # [10, 200, 30, 40, 50]
# 将l5中的40改为400 ,step1:查询40的索引 step2:将索引为i的值改为400
i = l5.index(40) # 3
l5[i] = 400
print(l5) # [10, 20, 30, 400, 50]
# (4) ******************************** 查(index,sort) *******************************
l6 = [10, 50, 30, 20,40]
l6.reverse() # 只是翻转 [40, 20, 30, 50, 10]
print(l6) # []
# # 查询某个元素的索引,比如30的索引
# print(l6.index(30)) # 2
# 排序
# l6.sort(reverse=True)
# print(l6) # [50, 40, 30, 20, 10]列表推到式
列表推导式(又称列表解析式)提供了一种简明扼要的方法来创建列表。
它的结构是在一个中括号里包含一个表达式,然后是一个for语句,然后是 0 个或多个 for 或者 if 语句。那个表达式可以是任意的,意思是你可以在列表中放入任意类型的对象。返回结果将是一个新的列表,在这个以 if 和 for 语句为上下文的表达式运行完成之后产生。
列表推导式的执行顺序:各语句之间是嵌套关系,左边第二个语句是最外层,依次往右进一层,左边第一条语句是最后一层。
[x*y for x in range(1,5) if x > 2 for y in range(1,4) if y < 3]for x in range(1,5)
if x > 2
for y in range(1,4)
if y < 3
x*y字典
字典是Python提供的唯一内建的映射(Mapping Type)数据类型。
声明字典
python使用 { } 创建字典,由于字典中每个元素都包含键(key)和值(value)两部分,因此在创建字典时,键和值之间使用冒号:分隔,相邻元素之间使用逗号,分隔,所有元素放在大括号{ }中。
dictname = {'key':'value1', 'key2':'value2', ...}字典基本操作
# (1) 查键值
print(book["title"]) # 返回字符串 西游记
print(book["authors"]) # 返回列表 ['rain', 'yuan']
# (2) 添加或修改键值对,注意:如果键存在,则是修改,否则是添加
book["price"] = 299 # 修改键的值
book["publish"] = "北京出版社" # 添加键值对
# (3) 删除键值对 del 删除命令
print(book)
del book["publish"]
print(book)
del book
print(book)
# (4) 判断键是否存在某字典中
print("price" in book)
# (5) 循环
for key in book:
print(key,book[key])列表内置方法
d = {"name":"yuan","age":18}| 方法 | 作用 | 示例 | 结果 |
|---|---|---|---|
get() |
查询字典某键的值, 取不到返回默认值 | d.get("name",None) |
"yuan" |
setdefault() |
查询字典某键的值, 取不到给字典设置键值,同时返回设置的值 | d.setdefault("age",20) |
18 |
keys() |
查询字典中所有的键 | d.keys() |
['name','age'] |
values() |
查询字典中所有的值 | d.values() |
['yuan', 18] |
items() |
查询字典中所有的键和值 | d.items() |
[('name','yuan'), ('age', 18)] |
pop() |
删除字典指定的键值对 | d.pop(‘age’) |
{'name':'yuan'} |
popitem() |
删除字典最后的键值对 | d.popitem() |
{'name':'yuan'} |
clear() |
清空字典 | d.clear() |
{} |
update() |
更新字典 | t={"gender":"male","age":20} d.update(t) |
{'name':'yuan', 'age': 20, 'gender': 'male'} |
dic = {"name": "yuan", "age": 22, "sex": "male"}
# (1)查字典的键的值
print(dic["names"]) # 会报错
name = dic.get("names")
sex = dic.get("sexs", "female")
print(sex)
print(dic.keys()) # 返回值:['name', 'age', 'sex']
print(dic.values()) # 返回值:['yuan', 22, 'male']
print(dic.items()) # [('name', 'yuan'), ('age', 22), ('sex', 'male')]
# setdefault取某键的值,如果能取到,则返回该键的值,如果没有改键,则会设置键值对
print(dic.setdefault("name")) # get()不会添加键值对 ,setdefault会添加
print(dic.setdefault("height", "180cm"))
print(dic)
# (2)删除键值对 pop popitem
sex = dic.pop("sex") # male
print(sex) # male
print(dic) # {'name': 'yuan', 'age': 22}
dic.popitem() # 删除最后一个键值对
print(dic) # {'name': 'yuan'}
dic.clear() # 删除键值对
# (3) 添加或修改 update
add_dic = {"height": "180cm", "weight": "60kg"}
dic.update(add_dic)
print(dic) # {'name': 'yuan', 'age': 22, 'sex': 'male', 'height': '180cm', 'weight': '60kg'}
update_dic = {"age": 33, "height": "180cm", "weight": "60kg"}
dic.update(update_dic)
print(dic) # {'name': 'yuan', 'age': 33, 'sex': 'male', 'height': '180cm', 'weight': '60kg'}
# (4) 字典的循环
dic = {"name": "yuan", "age": 22, "sex": "male"}
# 遍历键值对方式1
# for key in dic: # 将每个键分别赋值给key
# print(key, dic.get(key))
# 遍历键值对方式2
# for i in dic.items(): # [('name', 'yuan'), ('age', 22), ('sex', 'male')]
# print(i[0],i[1])
# 关于变量补充
# x = (10, 20)
# print(x, type(x)) # (10, 20) <class 'tuple'>
# x, y = (10, 20)
# print(x, y)
for key, value in dic.items():
print(key, value)字典进阶使用
# 案例1:列表嵌套字典
data = [
{"name": "rain", "age": 22},
{"name": "eric", "age": 32},
{"name": "alvin", "age": 24},
]
# 循环data,每行按着格式『姓名:rain,年龄:22』将每个学生的信息逐行打印
for stu_dic in data: # data是一个列表
# print(stu_dic) #
print("『姓名:%s,年龄:%s』" % (stu_dic.get("name"), stu_dic.get("age")))
# 将data中第二个学生的年龄查询出来
print(data[1].get("age"))
# 案例2:字典嵌套字典
data2 = {
1001: {"name": "rain", "age": 22},
1002: {"name": "eric", "age": 32},
1003: {"name": "alvin", "age": 24},
}
# 循环data2,每行按着格式『学号1001, 姓名:rain,年龄:22』将每个学生的信息逐行打印
for stu_id, stu_dic in data2.items():
# print(stu_id,stu_dic)
name = stu_dic.get("name")
age = stu_dic.get("age")
print("『学号: %s, 姓名 %s,年龄:%s』" % (stu_id, name, age))
# name = "yuan"
# age = 22
# sex = "male"
#
# print("『姓名:", name, "年龄:", age, "性别:", sex, "』")
# print("『姓名: %s 年龄: %s 性别: %s 』" % (name, age, sex))
# print("姓名:name")字典生成式
同列表生成式一样,字典生成式是用来快速生成字典的。通过直接使用一句代码来指定要生成字典的条件及内容,替换了使用多行条件或者是多行循环代码的传统方式。
格式:
{字典内容+循环条件+判断条件}stu = {"id": "1001", "name": "alvin", "age": 22, "score": 100, "weight": "50kg"}
stu = {k: v for k, v in stu.items() if k == "score" or k == "name"}
print(stu)将一个字典中的键值倒换
dic = {"1": 1001, "2": 1002, "3": 1003}
new_dic = {v: k for k, v in dic.items()}
print(new_dic)print({k.upper():v for k,v in d.items()})附录
列表.py
# 列表和字典 太重要
# 基本数据类型(不可变数据类型)
a = 1
b = 3.14
c = "yuan"
d = True
# 列表和字典(可变数据类型)
name1 = "张三"
name2 = "李四"
name3 = "王五"
names = "张三 李四 王五"
names.split(" ") # ["张三","李四","王五"]
s = "hello"
# names = ["张三", "李四", "王五", "", "", "", "", ""]
names = ["张三", "", "", "", "", "", "李四", "王五"]
ages = [18, 19, 20]
l = [1, True, "hello"]
# ------------------- 列表的基本操作(序列操作)
# 一:支持索引取值
print(names[1])
print(names[2])
print(names[-1])
names[0] = "张三三"
# 二:切片操作
print(names[1:3]) # ["李四", "王五"]
print(names[-2:-1]) # ["李四", "王五"]
print(names[-2:]) # ["李四", "王五"]
# 三、in操作
print("yuan " in "hello yuan")
print("张三" in names)
print("张" in names)
# 四、+
l1 = [1, 2, 3]
l2 = [4, 5, 6]
print(l1 + l2) # [1,2,3,4,5,6]
print(l1)
print(type(l1)) # <class 'list'>
print(type(l2)) # <class 'list'>
# ------------------- 列表的内置方法
# 列表的内置方法帮助我们对该列表对象的数据元素进行管理(增删改查)
l = [1, 2, 3, 4]
print(type(l)) # <class 'list'>
# <1>添加元素 append insert extend
l.append(5)
l.append([6, 7])
print(l) # [1, 2, 3, 4,5,[6, 7]]
print(len(l))
l.insert(1, 100)
print(l)
l2 = [5, 6, 7]
l.extend(l2) # [1, 2, 3, 4,5, 6, 7]
print(l) # [1, 2, 3, 4, 5, 6, 7]
# <2>删除元素
l = [100, 200, 300, 400]
l.remove(300)
print(l) # [100, 200, 400]
l.pop(1)
print(l)
l.clear()
print(l) # []
# <3>更改元素
l = [100, 200, 300, 400]
l[0] = 1
print(l)
# <4>查看元素
l = [34, 56, 1, 23, 23, 100]
l.reverse()
print(l)
l.sort(reverse=True)
print(l)
print(l.count(23)) # 2
print(l.index(56))
# 遍历
names = ["zhangsan", "lisi", "wangwu"]
print(names[0])
print(names[1])
print(names[2])
for item in names:
print(item.upper())
nums = [11, 2, 3, 45, 7, 43]
s = 0
for i in nums:
s += i
print(s)
字典.py
# 列表和字典 太重要
names = ["张三", "李四", "王五"]
ages = [18, 19, 20]
print(ages[names.index("李四")])
stus = [["张三", 19], ["李四", 20], ["李四", 21]]
print(stus[1][1])
stu = ["yuan", 18]
print(stu[0])
print(stu[1])
stu = {"name": "yuan", "age": 18}
print(type(stu)) # <class 'dict'>
print(stu["name"])
print(stu["age"])
# 字典的基本操作(面向增删改查)
stu = {}
stu["name"] = "yuan"
stu["age"] = 18
stu["age"] = 22
print(stu)
print(stu["age"])
# del stu
# print(stu)
del stu["age"]
print(stu)
print("name" in stu)
# 字典的内置方法(面向增删改查)
stu = {"name": "yuan", "age": 32, "gender": "male"}
# 查看
print(stu["name"])
print(stu.get("names", None))
print(stu.items()) # [('name', 'yuan'), ('age', 32), ('gender', 'male')]
stu.popitem()
print(stu)
stu.pop("age")
print(stu)
stu.clear()
print(stu)
stu.update({"age": 18, "height": "182cm", "weight": "90kg"})
print(stu)
# 知识补充
x = [1, 2]
x, y = [1, 2]
print(x, y)
x, y, z = [1, 2, 3]
print(x, y, z)
x, y, *z = [1, 2, 3, 4, 5]
print(x, y, z)
# 遍历
stu = {"name": "yuan", "age": 32, "gender": "male"}
for key in stu:
print(key, stu[key])
for i in stu.items(): # [['name', 'yuan'], (['age', 32], ['gender', 'male']]
print(i[0], i[1])
# # 推荐
stu = {"name": "yuan", "age": 32, "gender": "male"}
for k, v in stu.items(): # [('name', 'yuan'), ('age', 32), (gender', 'male')]
print(k, v)
原文地址:https://blog.csdn.net/qq_61553520/article/details/134746223
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_41584.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!





