1.单词统计流程(文字简单描述)
已知文件内容:
hadoop hive hadoop spark hive
flink hive linux hive mysql
计算每个单词出现的次数

2.MR底层计算原理[重点]
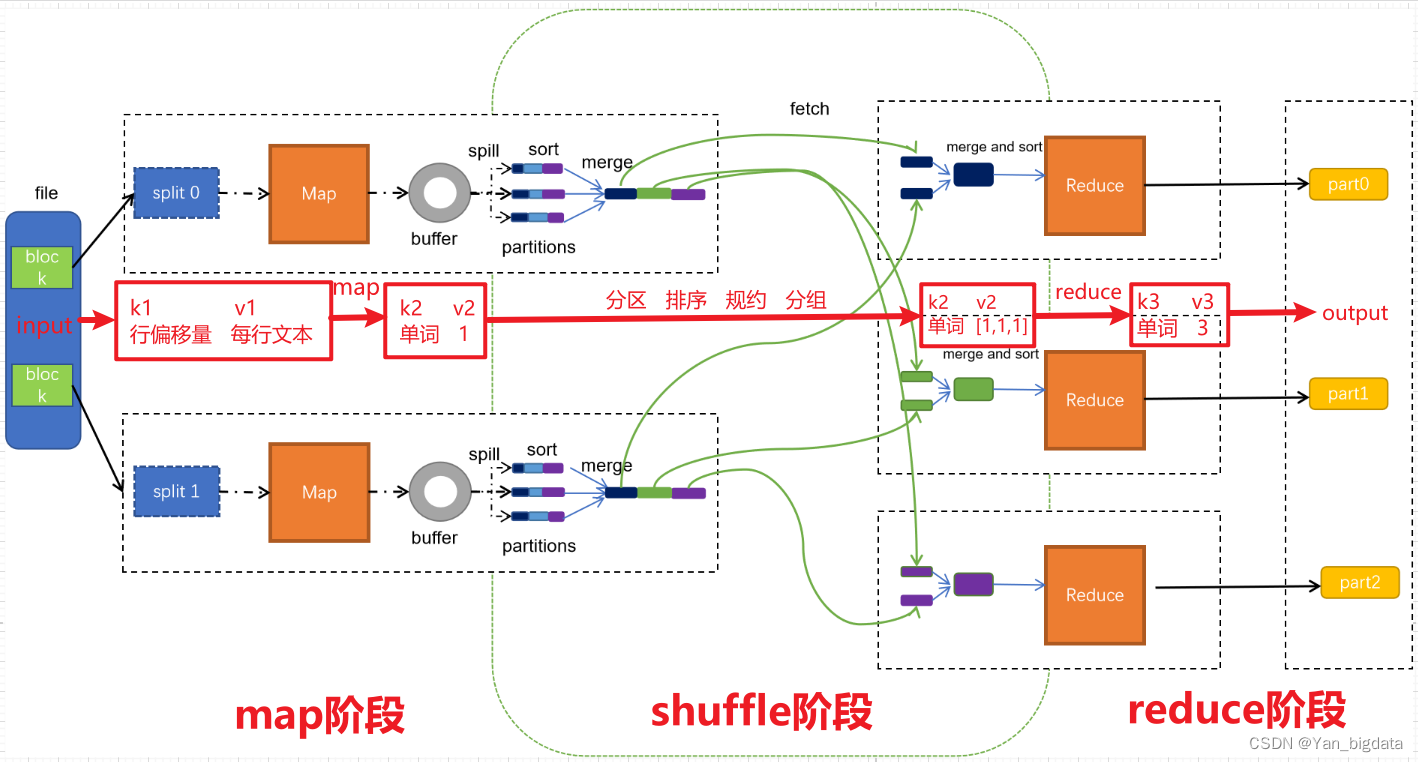
MAP阶段
第一阶段是把输入目录下文件按照一定的标准逐个进行逻辑切片,形成切片规划。默认情况下Split size 等于 Block size。每一个切片由一个MapTask处理(当然也可以通过参数单独修改split大小)
第二阶段是对切片中的数据按照一定的规则解析成对。默认规则是把每一行文本内容解析成键值对。key是每一行的起始位置(单位是字节),value是本行的文本内容。(TextInputFormat)
第三阶段是调用Mapper类中的map方法。上阶段中每解析出来的一个,调用一次map方法。每次调用map方法会输出零个或多个键值对
第四阶段是按照一定的规则对第三阶段输出的键值对进行分区。默认是只有一个区。分区的数量就是Reducer任务运行的数量。默认只有一个Reducer任务
第五阶段是对每个分区中的键值对进行排序。首先,按照键进行排序,对于键相同的键值对,按照值进行排序。比如三个键值对<2,2>、<1,3>、<2,1>,键和值分别是整数。那么排序后的结果是<1,3>、<2,1>、<2,2>
如果有第六阶段,那么进入第六阶段;如果没有,直接输出到文件中
第六阶段是对数据进行局部聚合处理,也就是combiner处理。键相等的键值对会调用一次reduce方法。经过这一阶段,数据量会减少。本阶段默认是没有的。
SHUFFLE阶段
shuffle是Mapreduce的核心,它分布在Mapreduce的map阶段和reduce阶段。一般把从Map产生输出开始到Reduce取得数据作为输入之前的过程称作shuffle。
**Collect阶段:**将MapTask的结果输出到默认大小为100M的环形缓冲区,保存的是key/value,Partition分区信息等
**Spill阶段:**当内存中的数据量达到一定的阀值(80%)的时候,就会将数据写入本地磁盘,在将数据写入磁盘之前需要对数据进行一次排序的操作,如果配置了combiner,还会将有相同分区号和key的数据进行排序
**Merge阶段:**把所有溢出的临时文件进行一次合并操作,以确保一个MapTask最终只产生一个中间数据文件
Copy阶段: ReduceTask启动Fetcher线程到已经完成MapTask的节点上复制一份属于自己的数据,这些数据默认会保存在内存的缓冲区中,当内存的缓冲区达到一定的阀值的时候,就会将数据写到磁盘之上
**Merge阶段:**在ReduceTask远程复制数据的同时,会在后台开启两个线程对内存到本地的数据文件进行合并操作。
**Sort阶段:**在对数据进行合并的同时,会进行排序操作,由于MapTask阶段已经对数据进行了局部的排序,ReduceTask只需保证Copy的数据的最终整体有效性即可
REDUCE阶段
第一阶段是Reducer任务会主动从Mapper任务复制其输出的键值对。Mapper任务可能会有很多,因此Reducer会复制多个Mapper的输出。
第二阶段是把复制到Reducer本地数据,全部进行合并,即把分散的数据合并成一个大的数据。再对合并后的数据排序。
第三阶段是对排序后的键值对调用reduce方法。键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对。最后把这些输出的键值对写入到HDFS文件中。
原文地址:https://blog.csdn.net/Yan_bigdata/article/details/134691817
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_41642.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!