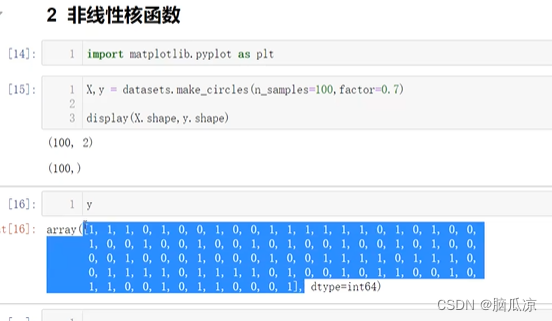
本文介绍: X += np.random.randn(100,2) 我们从正太分布中拿出100行2列的数据来,拼接到X生成的100行2列的数据里面,现在的原来的X,就变成了。- `X[:,0]`:这是第一个维度(通常是x轴)的值,X 是一个二维数组,`X[:,0]` 表示取X数组的第一列。- `X[:,1]`:这是第二个维度(通常是y轴)的值,X 是一个二维数组,`X[:,1]` 表示取X数组的第二列。这个是5,5 表示图形的大小,x轴,y轴的大小,设置好以后生成的就圆了,要不然是椭圆的,可以看到上面显示的.
人工智能_机器学习059_非线性核函数介绍—人工智能工作笔记0099

那么我们应该如何调整这个SVC的参数,也就是我们应该使用哪种核函数,比较合适呢?这取决于我们的数据,适合使用哪个核函数,正好我们有
提供的score = accuracy_score(y_test,y_pred) 这样的评分函数,我们可以根据具体的评分情况,选择评分比较高的核函数来使用.

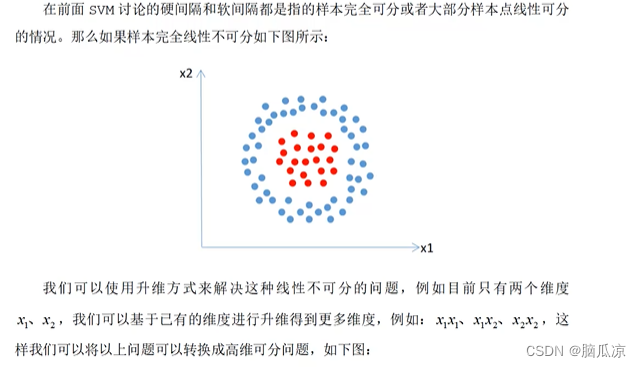
之前我们学习到的都是线性核函数,使用一条线来进行对数据进行划分,但是
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。




