本文主要讨论了
一. Hive Architecture
架构图:
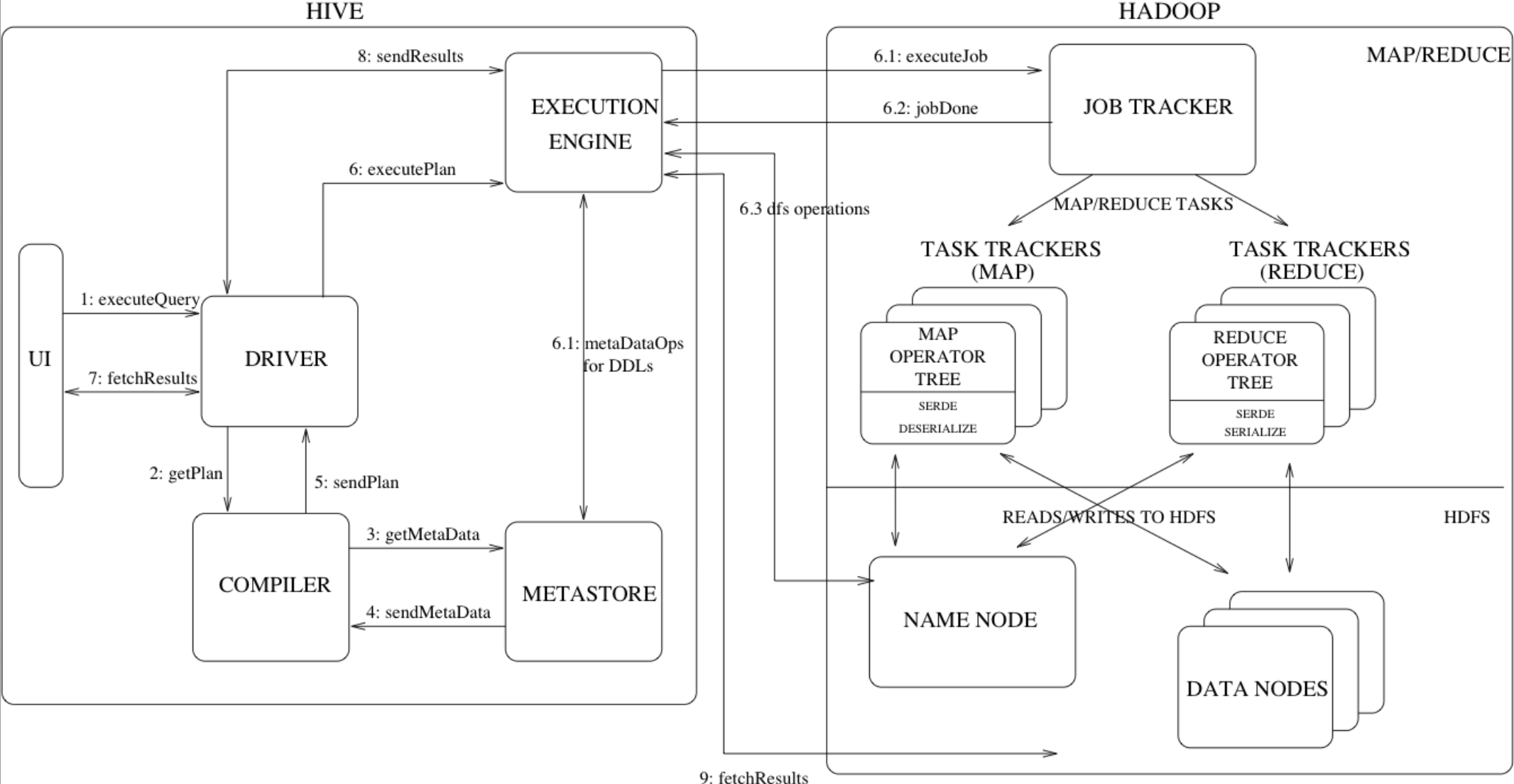
主要的hive组件:
- UI:用户提交接口,用于用户提交查询和其他操作等。
- Driver:接收查询的组件。该组件实现了会话句柄(ing),并提供基于 JDBC/ODBC 接口的execute、 fetch APIs。
- Compiler:该组件解析查询,在不同查询块和查询表达式中做语义分析,最终借助从metastore查找的表和分区元数据生成执行计划。
- MetaStore:存储所有表、分区的结构化信息包括:列和列类型信息、读写数据所需的序列化器和反序列化器以及相关存储的hdfs文件(?)。
- Execution Engine:执行由Compiler生成的执行计划。执行计划是一个由stages组成的有向无环图,执行引擎管理stage之间的依赖关系,并让合适的组件执行对应的stage。
UI调用执行接口将查询发送到Driver,Driver创建了查询的session handle(会话句柄),并发送查询到Compiler来产生执行计划。Compiler从metastore中获取必要的元数据,这些元数据用于对查询树中的表达式进行类型检查,并根据查询谓词修剪分区。
compiler生成的执行计划是一系列组成DAG的stages,每一个stage可能是map/reduce任务、元数据操作或在HDFS的操作。
对于map/reduce stage,执行计划包含了map操作符树(执行在mapper上),reduce操作符树(执行在reduce上)。执行引擎提交这些stage到合适的组件上(steps 6, 6.1, 6.2 and 6.3)。
和表或中间结果相关的反序列化器用于读取HDFS文件的行,并通过相关的算子树传递这些行。当产生输出结果时,(为了防止不需要reduce,)mapper会通过序列化器将结果写出到一个HDFS临时文件,用于给下游stage提供数据。
dml和查询操作:
对于DML操作,最终的临时文件会被移到表的位置。且因为文件重命名是HDFS的原子操作,所以保证了任务不会读取脏数据。
对于查询操作,执行引擎直接从HDFS读取临时文件的内容,作为Driver fetch call的一部分。
二. Metastore
Metastore提供了数据仓库的两个重要但经常被忽视的特性:数据概述和数据发现。
- 如果没有Hive提供的数据概述,用户必须在查询的同时提供有关数据格式、提取器和加载器的信息。在Hive中,这个信息在表创建时给出,并且在每次表被引用时重用。这与传统的仓储系统非常相似。
- 数据发现,它使用户能够发现和探索仓库中的相关和特定数据。可以使用此元数据构建其他工具,以公开并可能增强有关数据及其可用性的信息。
1. Metastore Architecture
元数据是存储在数据库或文件后端的对象存储。数据库支持的存储是使用称为DataNucleus的对象关系映射(ORM)解决方案实现的。
将其存储在关系数据库中的主要动机是元数据的可查询性。但会存在同步和伸缩性的问题。
对于存储在HDFS上,因为无法对文件的随机更新,现在还没有明确的方法在HDFS上实现对象存储。这一点,再加上关系存储的可查询性优势,使我们的方法变得合理。
可以通过远程和嵌入式两种方式来配置Metastore。详情见:
https://cwiki.apache.org/confluence/display/Hive/AdminManual+Metastore+Administration
2. Metastore Interface
Metastore提供了一个Thrift接口来操作和查询Hive元数据。Thrift可以绑定到许多流行语言中。第三方工具可以通过该接口将Hive元数据集到其他业务元数据存储库中。
三. Compiler
Parser :
Logical Plan Generator:逻辑计划产生器:
Query Plan Generator:查询计划产生器。
上述参考官网:hive-Design
四. hive架构小结
Hive主要由以下四个模块组成:
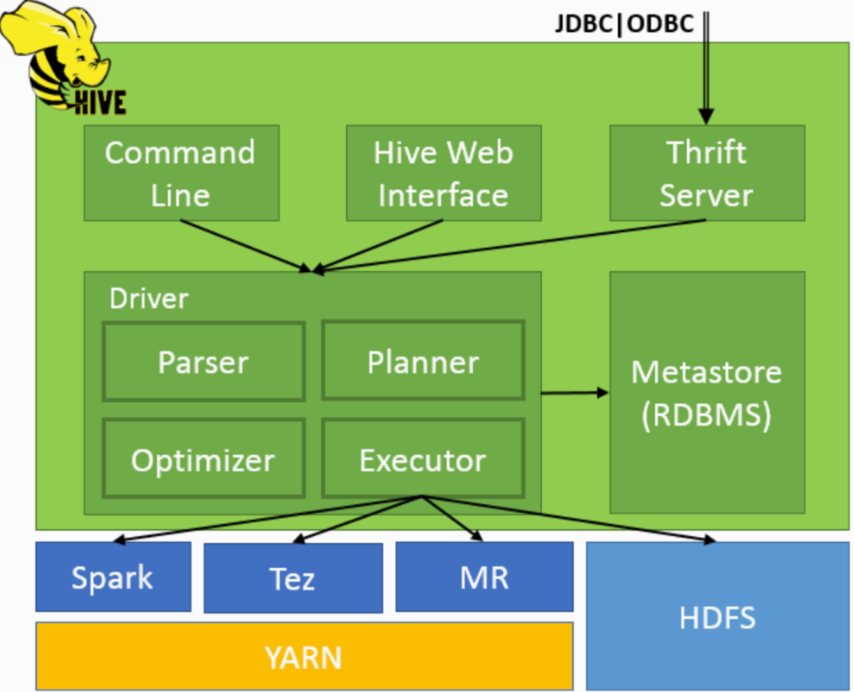
1.用户接口模块
用来实现对hive的访问,有CLI、HWI、JDBC、Thrift Server等
从上面的架构图可以看到,通过JDBC、ODBC连接,先会经过Thrift Server,然后再到Driver;其他通过command line和hive web interface则直接和Driver进行交互。
2.thrift server
即跨语言服务层:它将其他语言(java,c,python)转化为hive可识别的语言可以让不同的编程语言调用Hive的接口。
其中hive提供的Thrift 接口可以让用户通过JDBC连接发送HiveQL请求到thrift接口,然后交由 Driver,最后Thrift将执行结果返回客户端。
3.Driver
Hive执行的核心流程:
- Meta Store
1)hive元数据可以存储在mysql中。默认元数据存储在一个自带的关系型数据库derby,但因为是单用户企业不适用。
2)hive元数据的储存内容:表数据的字段信息(字段名,字段类型,字段顺序)、表名信息表、以及和hdfs目录对应的关系。
原文地址:https://blog.csdn.net/hiliang521/article/details/134640943
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_4293.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!