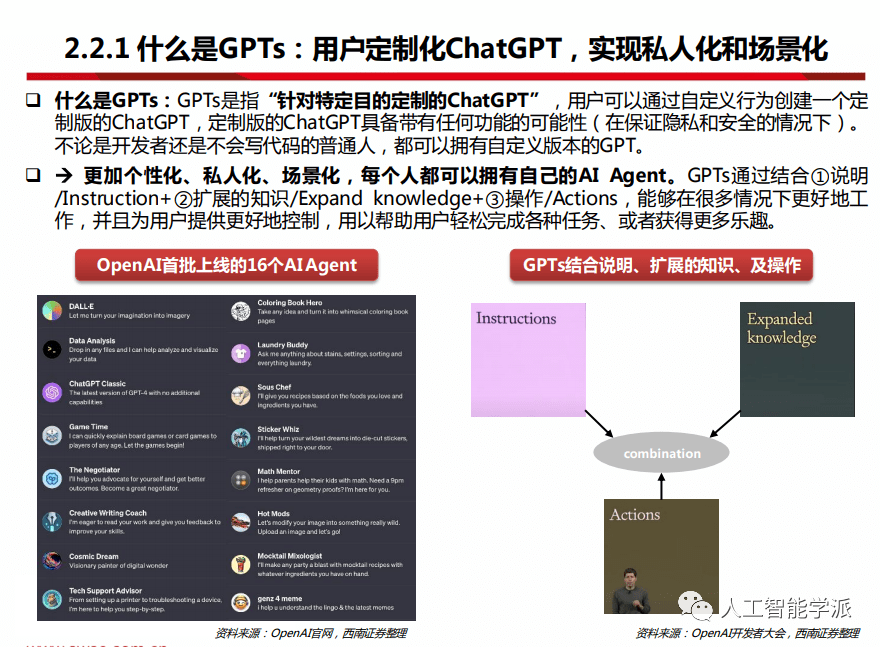
本文介绍: 什么是GPTs:GPTs是指“针对特定目的定制的ChatGPT”,用户可以通过自定义行为创建一个定 制版的ChatGPT,定制版的ChatGPT具备带有任何功能的可能性(在保证隐私和安全的情况下)。不论是开发者还是不会写代码的普通人,都可以拥有自定义版本的GPT。更加个性化、私人化、场景化,每个人都可以拥有自己的AI Agent。
今天分享的是GPT4-Turb系列深度研究报告:《GPT4-Turbo技术原理研发现状及未来应用潜力分析报告》。
报告共计:46页

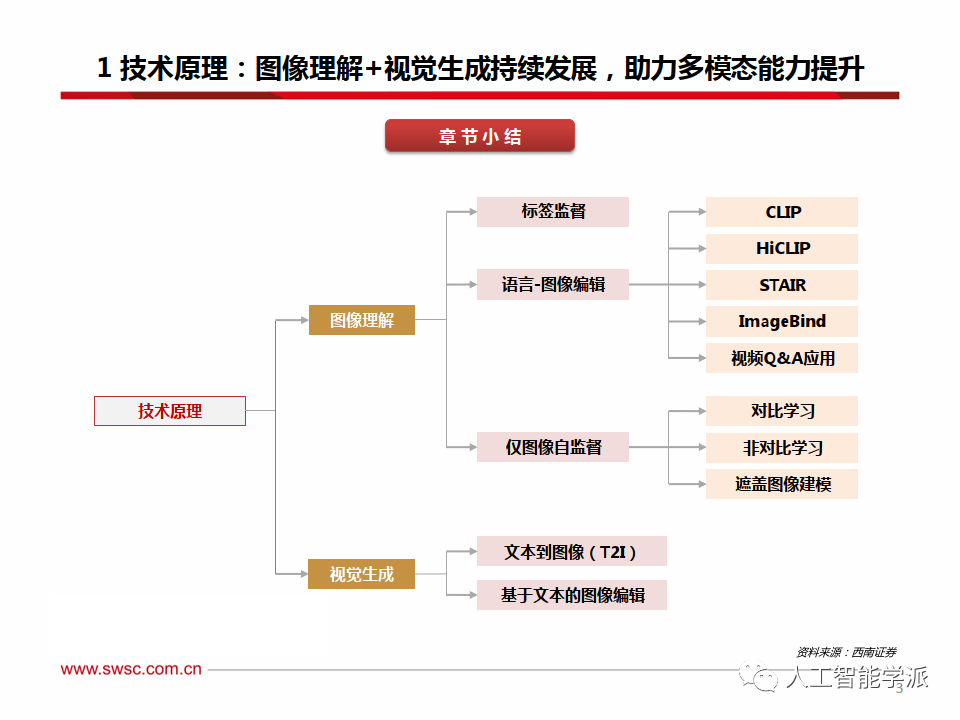
图像理解能力提升:三大视觉学习方法
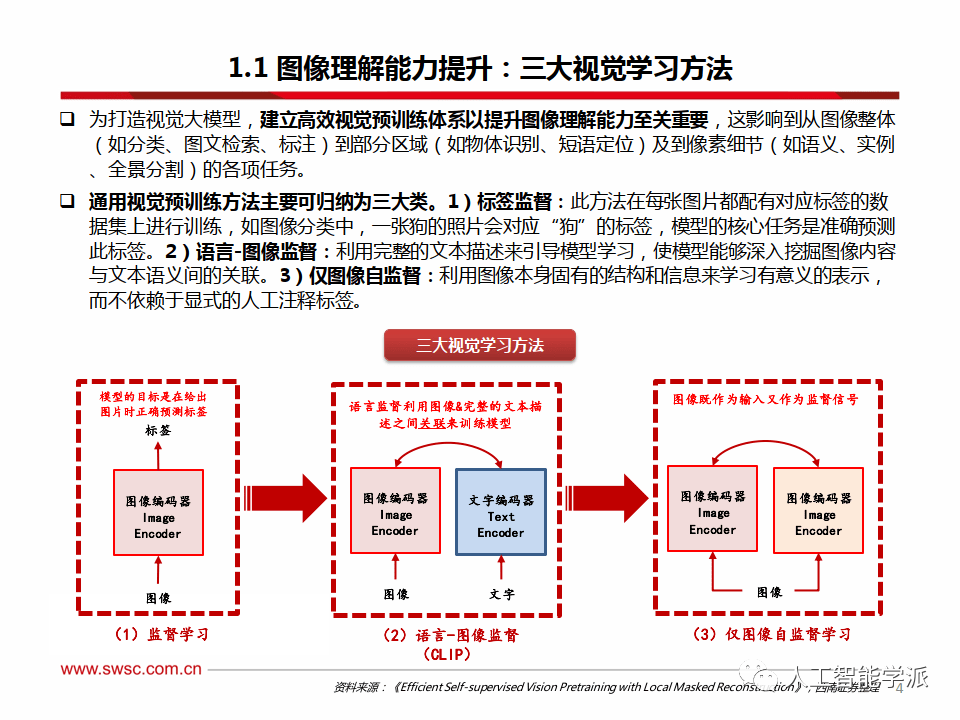
图像理解能力提升:标签监督

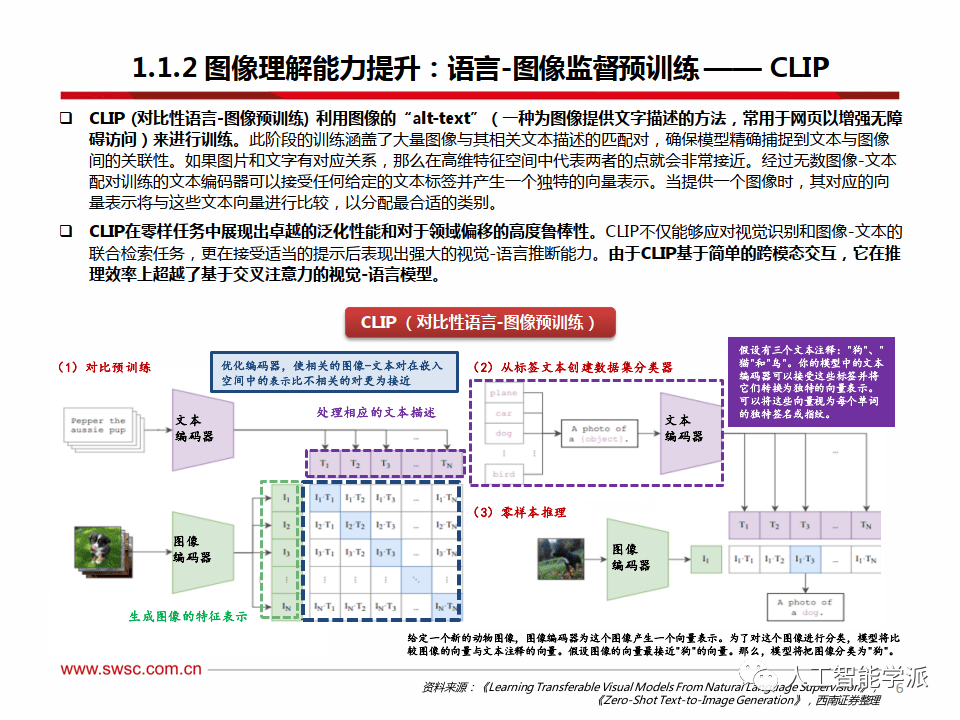
图像理解能力提升:语言-图像监督预训练—— CLIP
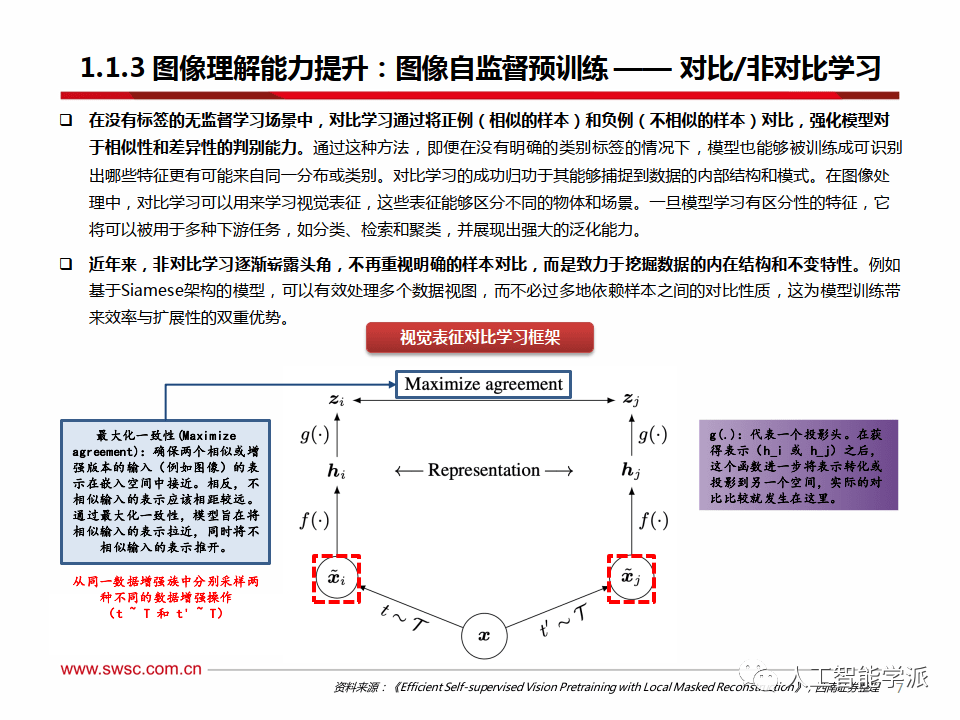
图像理解能力提升:图像自监督预训练 —— 对比/非对比学习
视觉生成:多模态内容理解和生成的闭环

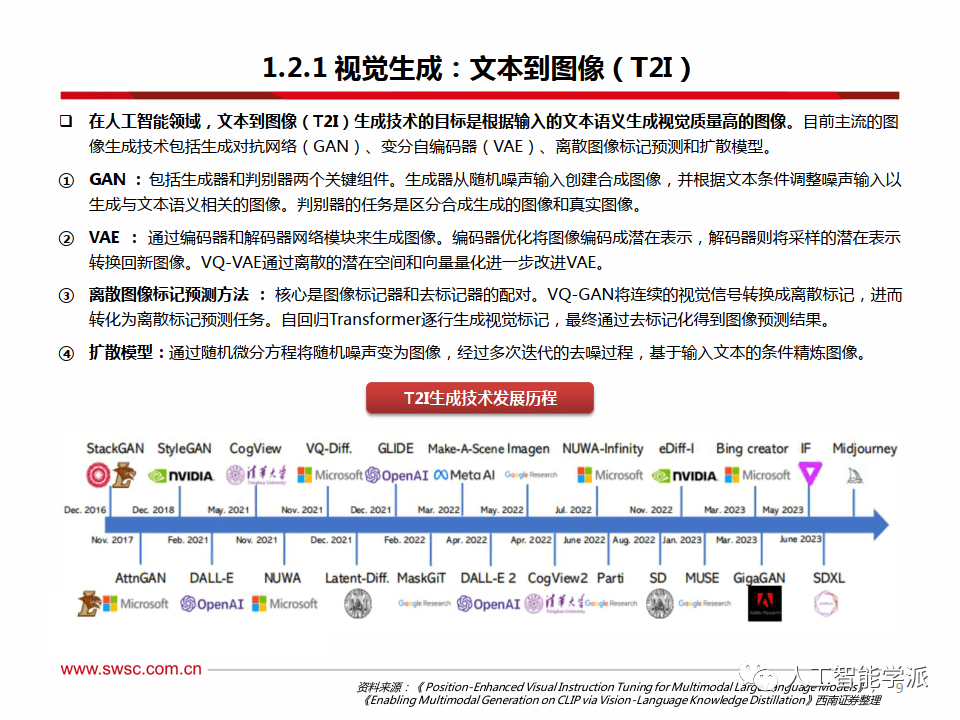
视觉生成:文本到图像(T2I)
视觉生成:基于文本的图像编辑


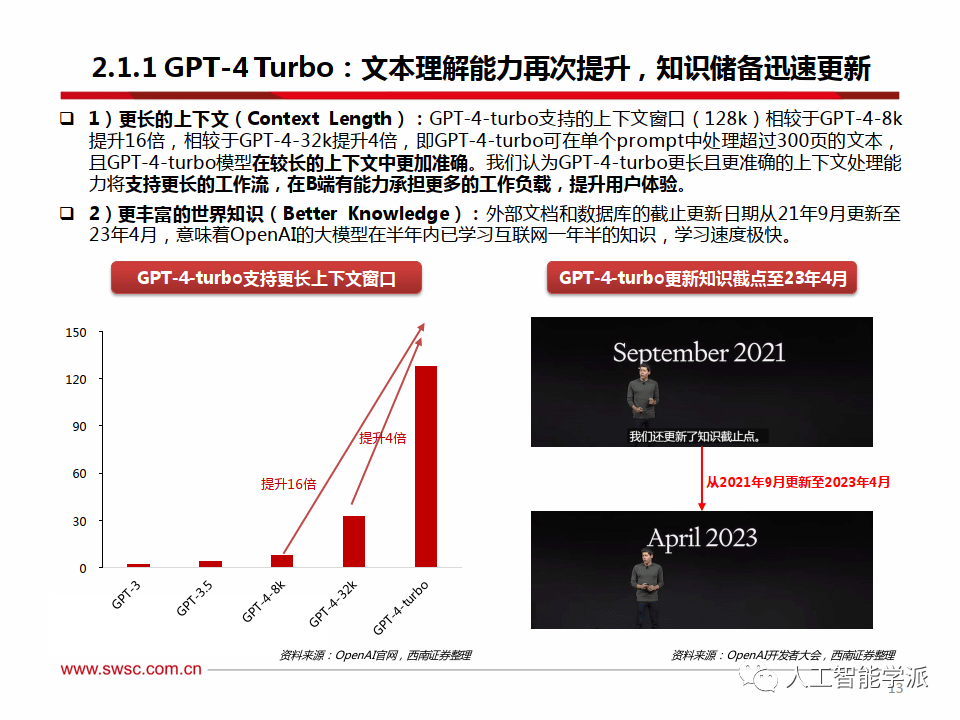
GPT-4 Turbo:文本理解能力再次提升,知识储备迅速更新

什么是GPTs:用户定制化ChatGPT,实现私人化和场景化
Assistant API:解决API开发者痛点,拓展OpenAI收入来源

Assistant API-函数调用

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。