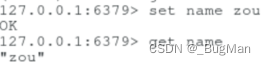
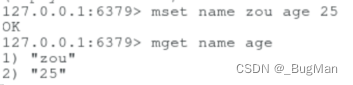
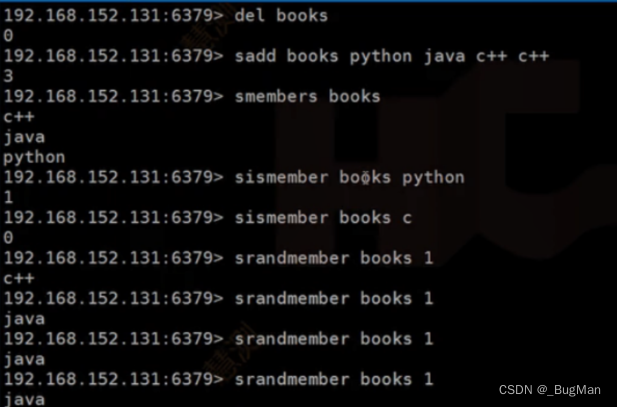
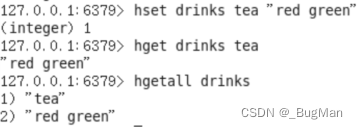
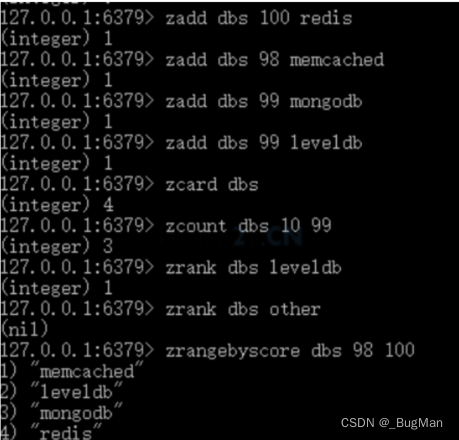
当前位置: 首页redis正文 本文介绍: 图文详解redis五种基础数据的操作,建议可以收藏起来,用的时候查一下。 作者简介 目录 1.概述 2.String 3.List 4.Set 5.Hash 6.zSet 1.概述 redis中一共提供了五种数据结构: String List Set Hash zSet 很多时候无法记全这五种数据结构,这里教大家一种办法,这样来记忆即可: 1.Redis是一个KV形式的内存数据库,所以其数据组织方式其实就是以KV为基准然后进行扩展,由KV的一对一到List的一对多再到Map的一类KV的集合。 2.实际业务场景中,Redis中存的数据很可能具有唯一性(比如用户信息)或者顺序性(比如需要根据用户VIP等级来顺序拿用户),所以”辨重“、”排序“,是两个很关键的能力。 首先redis基于基础一对一的kv进行扩展,提供了三种基础结构: String List Hash redis本质上是个KV形式的内存数据库,所以KV形式是它的基础形式,也就是String类型的数据结构。 除了一个Key对应一个Value外,业务上有时候还需要一个key对应多个value,也就是链表类型,也就是Redis中的List类型的数据结构。 业务上有时候需要将一类KV键值对聚集在一起做成一个集合,就像JAVA中的Map一样,一类KV键值对的集合,也就是Hash类型的数据结构。 接下来为了业务使用上的友好,又提供了两种结构: Set zSet List中的数据可能重复,所以给出了不能重复的一个key对应多个value的结构——Set。 为了方便按照权重字段进行排序,专门给出了一种用来排序的结构——zSet。 2.String 设置/获取单个key 设置/获取多个key 如果value是数值形式的,String支持对数值进行操作: 自增 incr age 自减 decr age 增加指定值 incrby age 5 减少指定值 decrby age 5 批量操作 mset gender 男 height 170 mget gender height 追加 append name 追加内容 如果内存中没有key,会自动创建一个新的KV对放入内存。 截取 获取值的范围,类似于java String中的substring getrange <key><起始位置><结束位置> 3.List 一个key对应多个value,value可以重复。 压入/弹出 可以头压,尾压。头弹,尾弹。 在压的时候就会根据参数,自动建List。 查看 lrange 名称 起始位 结束位 0 -1 表示查看所有。 llen <key> 获取长度 删除 删除元素: ltrim 名称 个数(正数从左往右删、负数从右往左删,0删除所有) value 删除List: 在List弹出所有元素以后,其实就会自动删除数据结构。 也可以通过命令来手动删除: del 名称 4.Set 一个key对应多个value,value不可以重复。 添加元素 sadd 获取所有元素 smembers 判断是否是集合的成员 sismember 随机取出一个元素 srandmember 5.Hash 插入单个kv hset <XXX> <key> <value> 取出单个kv hget <XXX> <key> 插入多个kv hmset <XXX> <key1> <value>:<key2> <value> 查看某个key是否存在 hexists <XXX> <key> 查看所有key hkeys <XXX> 查看所有value hvals<XXX> 放单个值的时候不需要”” 放多个值的时候需要”” 支持批量放入、批量查看 6.zSet Redis有序集合zset与普通集合set非常相似,是一个没有重复元素的字符串集合。不同之处是有序集合的每个成员都关联了一个评分 (score),这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复了。因为元素是有序的,所以你也可以很快的根据评分(score) 或者次序 (position)来获取一个范围的元素。访问有序集合的中间元素也是非常快的,因此你能够使用有序集合作为一个没有重复成员的智能列表。 相同分数,相同元素无法插入, 相同分数,不同元素可以插入 不同分数,相同元素,分数会被替换。 查询所有:zrank dbs 0 -1 原文地址:https://blog.csdn.net/Joker_ZJN/article/details/132925567 本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若转载,请注明出处:http://www.7code.cn/show_43640.html 如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除! 主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网显示所有内容声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。kvlistredis 代码007普通 打赏 收藏 海报 链接