文章目录
- 视图函数
- 1、get():获取模型对象
- 2、all():查询所有数据
- 3、filter():进行过滤,方法中可以传递多个参数
- 4、exclude():反向过滤
- 5、order_by():排序
- 6、first()
- 7、last()
- 8、exists()
- 9、count()
- 10、切片操作
- 11、values()(重点)
- 12、values_list()(重点)
- 13、startswith:用于查询以什么字段开头
- 14、endswith:用于查询以什么字段结尾
- 15、contains:用于查询包含什么的字段
- 16、in:用于查询在特定范围的字段
- 17、not in:用于查询不在特定范围的字段
- 18、in_range:用于查询在区间范围的字段
- 19、not in_range:用于查询在区间范围的字段
- 20、exact:精确查询
- 21、F:可以实现查询属性与属性之间的关系
- 22、Q:实现属性之间(与|或|非)的功能
- 23、annotate():分组(有疑问)
- 24、aggregate()
- 25、gt、gte、lt、lte:大于、大于等于、小于、小于等于
- 26、only:只取某列的值(重点)
- 27、defer:取出除了某列以外其他列的值(重点)
视图函数
import json
import logging
import os
from datetime import datetime
from django.conf import settings
from django.db.models import Q, F
from rest_framework import status, filters, mixins, generics, viewsets, permissions
from rest_framework.decorators import action
from rest_framework.response import Response
from configures.models import Configures
from envs.models import Envs
from interfaces.models import Interfaces
from projects.serializers import ProjectsSerializer, ProjectsNamesSerializer, ProjectsInterfacesSerializer,
ProjectsRunSerializer, ProjectsNames1Serializer
from testcases.models import Testcases
from testsuites.models import Testsuits
from utils import common
logger=logging.getLogger('mytest')
from projects.models import Projects
from utils.pagination import PageNumberPagination
class ProjectsViewSet(viewsets.ModelViewSet):
queryset=Projects.objects.all()
serializer_class = ProjectsSerializer
pagination_class = PageNumberPagination
def get_serializer_class(self):
elif self.action=='names1':
return ProjectsNames1Serializer
else:
return super().get_serializer_class()
def paginate_queryset(self, queryset):
if self.action == 'names1':
return
else:
return super().paginate_queryset(queryset)
def get_queryset(self):
if self.action=='names1':
else:
return super().get_queryset()
1、get():获取模型对象
def get_queryset(self):
if self.action=='names1':
print(Projects.objects.get(id=1))
return Projects.objects.all()
else:
return super().get_queryset()
2、all():查询所有数据
def get_queryset(self):
if self.action=='names1':
print(Projects.objects.all())
return Projects.objects.all()
else:
return super().get_queryset()
查询结果:
<QuerySet [<Projects: 自动化测试平台项目>, <Projects: 前程贷P2P金融项目>, <Projects: 项目4>, <Projects: 项目5>, <Projects: 项目6>, …]>
3、filter():进行过滤,方法中可以传递多个参数
查询项目编号大于等于5的项目有哪些
def get_queryset(self):
if self.action=='names1':
print(Projects.objects.filter(id__gte=5))
return Projects.objects.all()
else:
return super().get_queryset()
<QuerySet [<Projects: 项目4>, <Projects: 项目5>, <Projects: 项目6>, <Projects: 2022-5-21-2项目>, <Projects: 2022-5-21-3项目>, …]>
4、exclude():反向过滤
过滤项目编号不在2到5之间的项目
def get_queryset(self):
if self.action=='names1':
print(Projects.objects.exclude(id__range=[2,5]))
return Projects.objects.all()
else:
return super().get_queryset()
5、order_by():排序
通过order_by 方法, 前面加”-“就是降序,默认升序
Projects.objects.order_by(‘id’):升序
Projects.objects.order_by(‘-id’):降序
可以多次排序 先按name字段降序,如果name相同,就按id字段升序
Projects.objects.order_by(“-name”,“id”)
def get_queryset(self):
if self.action=='names1':
print(Projects.objects.order_by('id'))
print(Projects.objects.order_by('id'))
return Projects.objects.all()
else:
return super().get_queryset()
6、first()
def get_queryset(self):
if self.action=='names1':
print(Projects.objects.all().first())
return Projects.objects.all()
else:
return super().get_queryset()
7、last()
def get_queryset(self):
if self.action=='names1':
print(Projects.objects.all().last())
return Projects.objects.all()
else:
return super().get_queryset()
8、exists()
Projects.objects.filter(id__gte=3).exists():exists():判断查询集中是否有数据,如果有则返回True,没有则返回False。
def get_queryset(self):
if self.action=='names1':
print(Projects.objects.filter(id__gte=3).exists())
return Projects.objects.all()
else:
return super().get_queryset()
执行结果:True
9、count()
def get_queryset(self):
if self.action=='names1':
print(Projects.objects.filter(id__gte=3).count())
return Projects.objects.all()
else:
return super().get_queryset()
执行结果:49
10、切片操作
同列表操作一致,返回查询集对象
limit 通过索引进行切片[10:20] 代表从10取到20 前闭后开
查询集不支持负数索引:Projects.objects.filter()[-1]
def get_queryset(self):
if self.action=='names1':
print(Projects.objects.all()[2:4])
return Projects.objects.all()
else:
return super().get_queryset()
执行结果:
<QuerySet [<Projects: 项目4>, <Projects: 项目5>]>
11、values()(重点)
Projects.objects.values(“name”,“tester”)
返回查询集对象,列表中套字典,只取”name”,”tester”字段
def get_queryset(self):
if self.action=='names1':
print(Projects.objects.values("name","tester"))
return Projects.objects.all()
else:
return super().get_queryset()
执行结果:
<QuerySet [{‘name’: ‘自动化测试平台项目’, ‘tester’: ‘优优’}, {‘name’: ‘前程贷P2P金融项目’, ‘tester’: ‘小可可’}, {‘name’: ‘项目4’, ‘tester’: ‘某人’}, {‘name’: ‘项目5’, ‘tester’: ‘某人’}, {‘name’: ‘项目6’, ‘tester’: ‘某人’},…]>
12、values_list()(重点)
Projects.objects.values_list(“name”,“tester”)
返回查询集对象,列表中套元组,只取”name”,”tester”字段
def get_queryset(self):
if self.action=='names1':
print(Projects.objects.values_list("name","tester"))
return Projects.objects.all()
else:
return super().get_queryset()
执行结果:
<QuerySet [(‘自动化测试平台项目’, ‘优优’), (‘前程贷P2P金融项目’, ‘小可可’), (‘项目4’, ‘某人’), (‘项目5’, ‘某人’), (‘项目6’, ‘某人’), (‘2022-5-21-2项目’, ‘kobe11’), (‘2022-5-21-3项目’, ‘qweq’), (‘2022-5-21-4项目’, ‘12311’), …]>>
13、startswith:用于查询以什么字段开头
where name like “获取%” 代表查询名字以获取开头的所有
name__istartswith 表示不区分大小写,以什么什么为开头
Projects.objects.filter(name__startswith=‘获取’):返回查询集对象
def get_queryset(self):
if self.action=='names1':
print(Projects.objects.filter(name__startswith='获取'))
return Projects.objects.all()
else:
return super().get_queryset()
执行结果:<QuerySet [<Projects: 获取总部城市>]>
14、endswith:用于查询以什么字段结尾
where name like “%4” 表示匹配以4结尾的所有单词
name__iendswith 表示不区分大小写,以什么什么为结尾
Projects.objects.filter(name__endswith=‘4’):返回查询集对象
def get_queryset(self):
if self.action=='names1':
print(Projects.objects.filter(name__endswith='4'))
return Projects.objects.all()
else:
return super().get_queryset()
执行结果:<QuerySet [<Projects: 项目4>]>
15、contains:用于查询包含什么的字段
where name like “%自动化%” 表示匹配中间有 自动化 字的所有单词
name__icontains 表示不区分大小写,包含什么什么的单词
Projects.objects.filter(name__contains=‘自动化’):返回查询集对象
def get_queryset(self):
if self.action=='names1':
print(Projects.objects.filter(name__contains='自动化'))
return Projects.objects.all()
else:
return super().get_queryset()
执行结果:<QuerySet [<Projects: 自动化测试平台项目>]>
16、in:用于查询在特定范围的字段
通过 字段名__in = [1,2] 查询
Projects.objects.filter(id__in=[1,2,3,4,5,6]):返回查询集对象
def get_queryset(self):
if self.action=='names1':
print(Projects.objects.filter(id__in=[1,2,3,4,5,6]))
return Projects.objects.all()
else:
return super().get_queryset()
17、not in:用于查询不在特定范围的字段
Projects.objects.exclude(id__in=[1,2,3,4,5,6]):返回查询集对象
def get_queryset(self):
if self.action=='names1':
print(Projects.objects.exclude(id__in=[1,2,3,4,5,6]))
return Projects.objects.all()
else:
return super().get_queryset()
18、in_range:用于查询在区间范围的字段
between … and… 通过 列名__range = [开始位置,结束位置] 闭区间
Projects.objects.filter(id__range=[2,5]):返回查询集对象
def get_queryset(self):
if self.action=='names1':
print(Projects.objects.filter(id__range=[2,5]))
return Projects.objects.all()
else:
return super().get_queryset()
19、not in_range:用于查询在区间范围的字段
def get_queryset(self):
if self.action=='names1':
print(Projects.objects.exclude(id__range=[2,5]))
return Projects.objects.all()
else:
return super().get_queryset()
20、exact:精确查询
Projects.objects.filter(name__exact=‘自动化测试平台项目’):返回查询集对象
iexact:不区分大小写
def get_queryset(self):
if self.action=='names1':
print(Projects.objects.filter(name__exact='自动化测试平台项目'))
return Projects.objects.all()
else:
return super().get_queryset()
执行结果:<QuerySet [<Projects: 自动化测试平台项目>]>
21、F:可以实现查询属性与属性之间的关系
查询id属性值大于name属性值的项目
需要导入:from django.db.models import F
Projects.objects.filter(id__gte=F(‘name’))
def get_queryset(self):
if self.action=='names1':
print(Projects.objects.filter(id__gte=F('name')))
return Projects.objects.all()
else:
return super().get_queryset()
22、Q:实现属性之间(与|或|非)的功能
需要导入:from django.db.models import Q
Projects.objects.filter(Q(id__gte=5) | Q(name__contains=“2022”))
| 表示 或
& 表示 与
查询项目编号大于等于5,或者项目名称包含2022的所有项目
def get_queryset(self):
if self.action=='names1':
print(Projects.objects.filter(Q(id__gte=5) | Q(name__contains="2022")))
return Projects.objects.all()
else:
return super().get_queryset()
23、annotate():分组(有疑问)
如果你想要对数据集先进行分组然后再进行某些聚合操作或排序时,需要使用annotate方法来实现。与aggregate方法不同的是,annotate方法返回结果的不仅仅是含有统计结果的一个字典,而是包含有新增统计字段的查询集(queryset).
print(Projects.objects.values(“name”).annotate(Count(“id”))):表示对name字段进行分组,分组后对id进行统计
例一:
def get_queryset(self):
if self.action=='names1':
print(Projects.objects.values("leader").annotate(Count("id")))
return Projects.objects.all()
else:
return super().get_queryset()
执行结果:
<QuerySet [{‘leader’: ‘可可’, ‘id__count’: 1}, {‘leader’: ‘可优’, ‘id__count’: 1}, {‘leader’: ‘某人’, ‘id__count’: 1}, {‘leader’: ‘某人’, ‘id__count’: 1}, {‘leader’: ‘某人’, ‘id__count’: 1}, {‘leader’: ‘kobe11’, ‘id__count’: 1}, …]>
例二:
先查询项目编号大于等于5
接着以id、name、tester进行分组
分组后按照tester进行统计
def get_queryset(self):
if self.action=='names1':
querys=Projects.objects.filter(id__gte=5).values('id','name','tester').annotate(Count("tester"))
print(querys)
return Projects.objects.all()
else:
return super().get_queryset()
执行结果:
<QuerySet [{‘id’: 11, ‘name’: ‘项目4’, ‘tester’: ‘某人’, ‘tester__count’: 1}, {‘id’: 12, ‘name’: ‘项目5’, ‘tester’: ‘某人’, ‘tester__count’: 1}, {‘id’: 13, ‘name’: ‘项目6’, ‘tester’: ‘某人’, ‘tester__count’: 1}, …’]>
24、aggregate()
aggregate的中文意思是聚合, 源于SQL的聚合函数。Django的aggregate()方法作用是对一组值(比如queryset的某个字段)进行统计计算,并以字典(Dict)格式返回统计计算结果。django的aggregate方法支持的聚合操作有AVG / COUNT / MAX / MIN /SUM 等。
def get_queryset(self):
if self.action=='names1':
print(Projects.objects.aggregate(Count("id")))
return Projects.objects.all()
else:
return super().get_queryset()
执行结果:{‘tester__count’: 49}
其他结果为:
{‘tester__sum’: 49}
{‘tester__max’: 49}
{‘tester__min’: 49}
{‘tester__avg’: 49}
同时获取最大值、最小值、平均值、求和
def get_queryset(self):
if self.action=='names1':
print(Projects.objects.aggregate(Count("tester"),Max('tester'),Min('tester'),Avg('tester'),Sum('tester')))
return Projects.objects.all()
else:
return super().get_queryset()
执行结果:
{‘tester__count’: 49, ‘tester__max’: ‘小姐姐’, ‘tester__min’: ‘12311’, ‘tester__avg’: 2763.9591836734694, ‘tester__sum’: 135434.0}
25、gt、gte、lt、lte:大于、大于等于、小于、小于等于
def get_queryset(self):
if self.action=='names1':
print(Projects.objects.filter(id__gt=1))
print(Projects.objects.filter(id__gte=1))
print(Projects.objects.filter(id__lt=5))
print(Projects.objects.filter(id__lte=5))
return Projects.objects.all()
else:
return super().get_queryset()
26、only:只取某列的值(重点)
p=Projects.objects.only(“tester”,“name”)
查询tester和name字段不会走数据库,走的是查询集
查询其他字段,会重新走数据库查询;
而p=Projects.objects.all()就不用走数据库查询了
def get_queryset(self):
if self.action=='names3':
p=Projects.objects.only("tester","name")
print(p)
return Projects.objects.only("tester","name")
else:
return super().get_queryset()

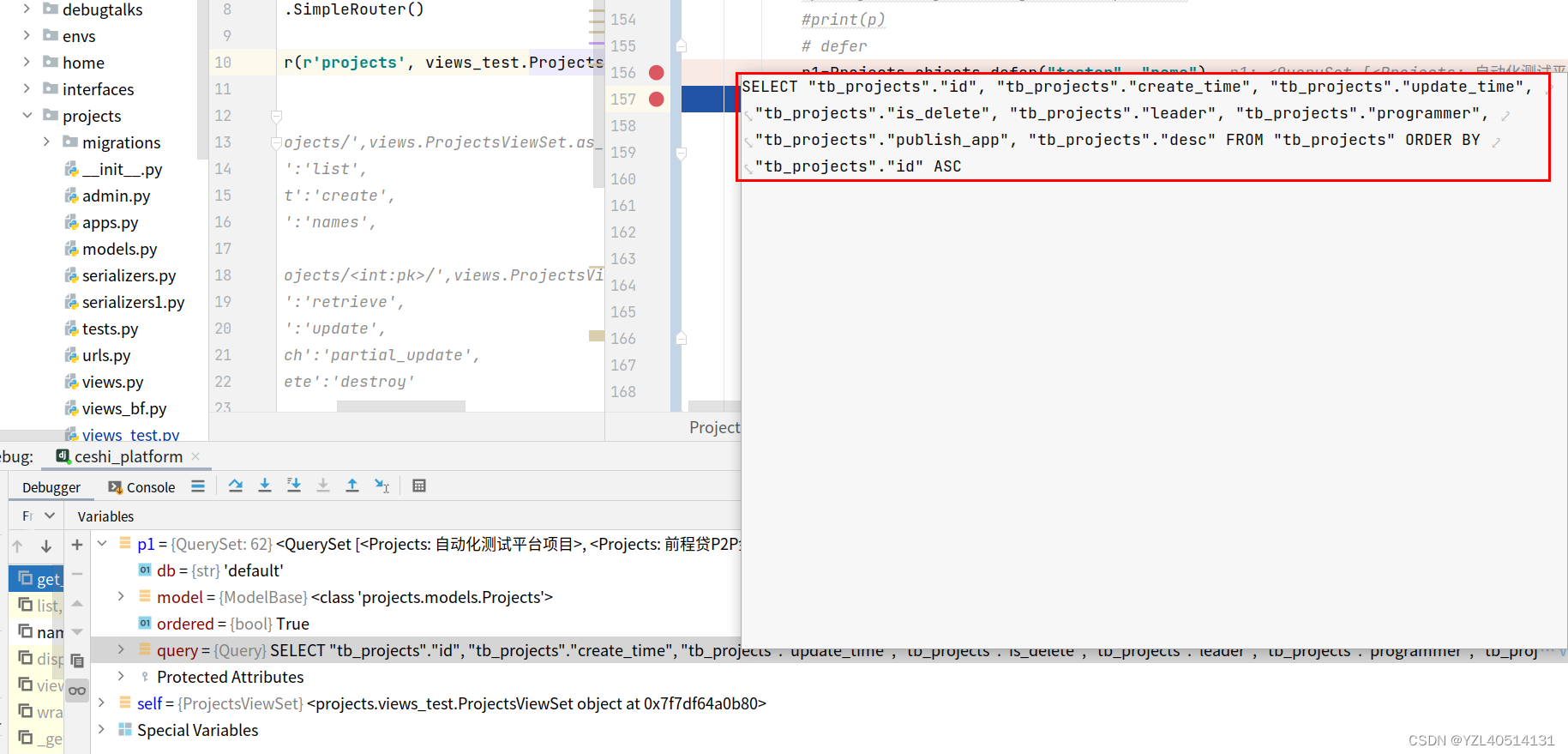
27、defer:取出除了某列以外其他列的值(重点)
p=Projects.objects.defer(“tester”,“name”)
defer括号内放的字段不在查询出来的对象里面,查询该字段需要重新走数据
而如果查询的是非括号内的字段 则不需要走数据库了
def get_queryset(self):
if self.action=='names3':
p=Projects.objects.defer("tester","name")
print(p)
return Projects.objects.defer("tester","name")
else:
return super().get_queryset()
SELECT “tb_projects”.“id”, “tb_projects”.“create_time”, “tb_projects”.“update_time”, “tb_projects”.“is_delete”, “tb_projects”.“leader”, “tb_projects”.“programmer”, “tb_projects”.“publish_app”, “tb_projects”.“desc” FROM “tb_projects” ORDER BY “tb_projects”.“id” ASC


原文地址:https://blog.csdn.net/YZL40514131/article/details/126215095
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_43998.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!