一、MMSegmentation介绍
MMSegmentation是openmmlab项目下开源的图像语义分割框架,目前支持pytorch,由于其拥有pipeline加速,完善的数据增强体系,完善的模型库,作为大数据语义分割训练及测试的代码框架是再好不过了。
二、MMSegmentation基本框架
理解MMSeg最重要的就是弄懂Config文件,共有4类:
(1)model config
(2)dataset config
(3)runtime config
(4)schedule config
1、model设置
如果采用的是MMSegmentation里面支持的模型,那么固然是不需要自己写class了,自己挑一个模型就可以了。这些model的目录保存在了configs/_base/models里面了。
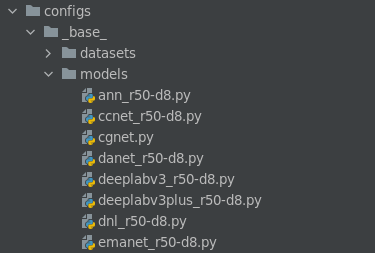
models文件夹下的模型名称:第一个下划线前面的都好理解,就是模型的名字,那r50-d8可能就是resnet的类型了,有人会问,那resnet101和resnet152哪去了,别急,其实这些只是baseline,它的backbone是可以改的,比如说我们要使用的是danet_r50-d8.py,我们先打开它(这部分,如果需要单GPU训练,将SyncBN改成BN):
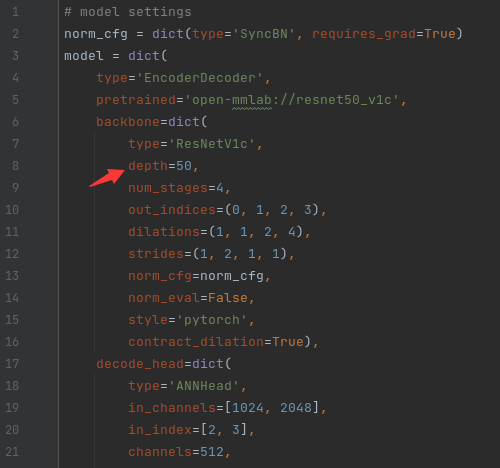
只需要把model.backbone.depth设为101或者152就可以使用resnet101或者resnet152啦,如果你的本地没有模型,mmSeg就会从model_zoo里面下载一个,如果本地有(应该是保存在了checkpoint里面),则自动加载本地的,不会重复下载。其他的操作后面会讲,另外如果你是多GPU操作就选择使用SyncBN,否则就使用BN就可以了。如果使用了SyncBN却只有一块可用的GPU,那可能会报类似AssertionError:Default process group is not initialized的错误。有人可能问那我直接改了这个文件不就把原来的默认参数给覆盖了嘛,不要紧,看到后面大家就会明白这个问题很容易解决,这里只是给大家做一个demo。
2、dataset设置
数据集设置比model的稍微复杂一点,这里会直接定义一个自己的数据集(Custom Dataset)来说明其原理。数据集需要准备的文件有三个:
(1)Dataset Class文件
(2)Dataset Config文件
(3)Total Config文件
在第四章中1节提到的config文件就是Total config(顶层设置文件),也是train.py文件直接调用的config文件,而Dataset Class文件是用来定义数据集的类别数和标签名称的,Dataset Config文件则是用来定义数据集目录、数据集信息(例如图片大小)、数据增强操作以及pipeline的。
2.1 Dataset Class文件配置
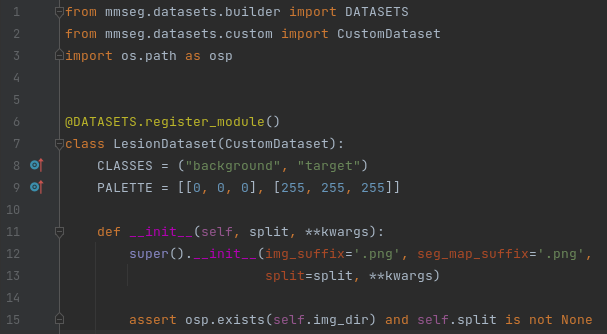
首先来说Dataset Class文件,这个文件存放在 mmseg/datasets/ 目录下:
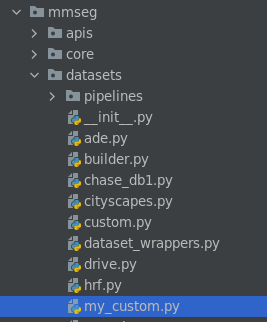
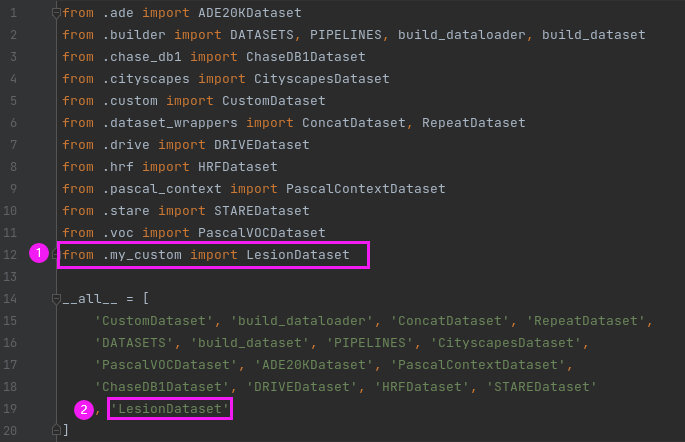
在这个目录下自己建一个数据集文件,并命个名,我这里命名为:my_custom.py。配置文件实际上是继承该目录下custom.py当中的CustomDataset父类的,这样写起了就简单多了,大多数情况下(当你的数据集是以一张张图片出现并且可用PIL模块读入时),你只需要设置两个参数即可——类别标签名称(CLASSES)和类别标签上色的RGB颜色(PALETTE)。以我的配置文件为例,代码如下: