
数据集链接:Titanic – Machine Learning from Disaster | Kaggle
Step1:导入函数库
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.ensemble import RandomForestRegressor
from sklearn import metrics
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 忽略警告
import warnings
warnings.filterwarnings("ignore")
#显示中文
plt.rcParams['font.sans-serif']=['SimHei'] #显示中文标签
plt.rcParams['axes.unicode_minus']=False #这两行需要手动设置Step2:导入数据并查看
data_train = pd.read_csv('D:/jupyter-notebook/kaggle/Titanic/train.csv')
#训练集
data_train
# 查看训练集大致情况,发现Age、Cabin、Embarked有缺失值
data_train.info()
# 查看训练集缺失值情况
data_train.isnull().sum()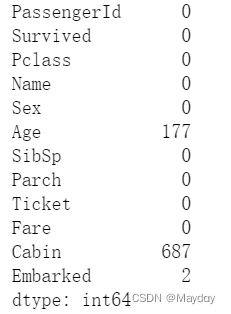
# 查看有无极端值以及数值分布情况
data_train.describe()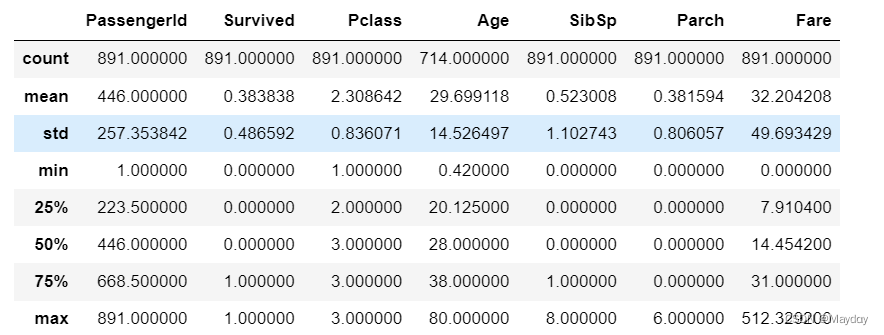
获救比例为38.38%,高等客舱获救的人更多,年龄小的获救更多
Step3:初步画图分析关系
1、查看survived和性别(Sex)的关系:获救的女性更多
# 有多少比例的男、女性获救
men_sur = data_train.loc[data_train.Sex == 'male']['Survived']
men_rate = men_sur.sum() / men_sur.count()
women_sur = data_train.loc[data_train.Sex == 'female']['Survived']
women_rate = women_sur.sum()/women_sur.count()
print('男性获救的比例:%.2f' % men_rate) #结果为0.19
print('女性获救的比例:%.2f' % women_rate) #结果为0.74
# 获救的男女之比
sur_sum = sum(data_train['Survived'] == 1)
print('总获救人数:%.d' % sur_sum) #结果为342
men_women_rate = men_sur.sum() / women_sur.sum()
print('获救的男女比例:%.2f' % men_women_rate) #结果为0.47# 各性别获救情况
plt.figure()
survived_m = data_train.loc[data_train.Sex == 'male']['Survived'].value_counts()
survived_w = women_sur = data_train.loc[data_train.Sex == 'female']['Survived'].value_counts()
df = pd.DataFrame({'男性':survived_m,'女性':survived_w})
df.plot(kind='bar',stacked=True)
plt.title('按性别看获救情况')
plt.xticks(rotation=0)
plt.xlabel('获救情况(获救=1,未获救=0)')
plt.ylabel('人数')
plt.show()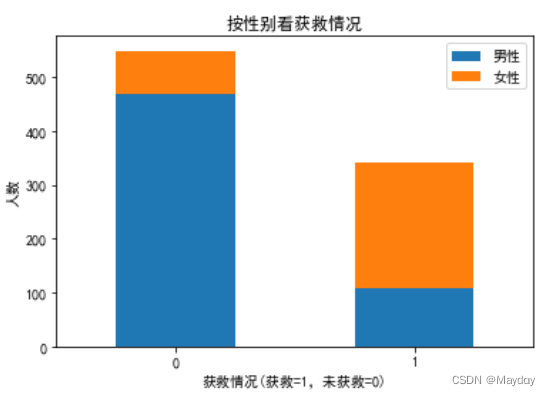
2、查看survived和客舱等级(Pclass)的关系:高等级客舱获救比例更大
# 各等级客舱获救情况
plt.figure()
survived_0 = data_train.loc[data_train.Survived == 0]['Pclass'].value_counts()
survived_1 = data_train.loc[data_train.Survived == 1]['Pclass'].value_counts()
df = pd.DataFrame({'获救':survived_1,'未获救':survived_0})
df.plot(kind='bar',stacked=True,)
plt.title('各等级客舱获救情况')
plt.xticks(rotation=0)
plt.xlabel('客舱等级(高等舱=1,中等舱=2,低等舱=3)')
plt.ylabel('人数')
plt.show()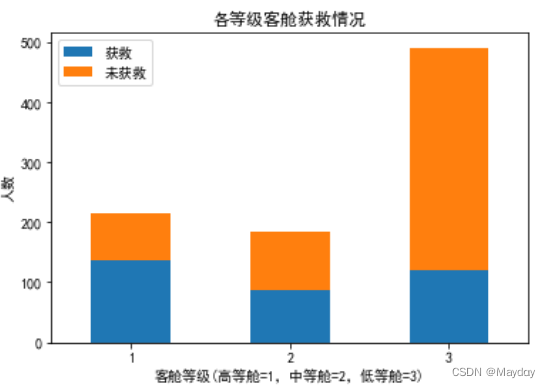
# 各等级客舱获救性别分布
fig = plt.figure(figsize=(12,10))
ax1 = plt.subplot(321)
f_1 = data_train.Survived[data_train.Pclass == 1][data_train.Sex == 'female'].value_counts().sort_index()
f_1.plot(kind='bar',label='female Pclass=1',color='red')
ax1.set_ylabel('人数',rotation=0)
ax1.set_xticklabels(['未获救','获救'],rotation=0)
ax1.legend(['高等舱 女性'],loc='best')
ax2 = plt.subplot(322)
m_1 = data_train.Survived[data_train.Pclass == 1][data_train.Sex == 'male'].value_counts().sort_index()
m_1.plot(kind='bar',label='male Pclass=1',color='red')
ax2.set_xticklabels(['未获救','获救'],rotation=0)
ax2.legend(['高等舱 男性'],loc='best')
ax3 = plt.subplot(323)
f_2 = data_train.Survived[data_train.Pclass == 2][data_train.Sex == 'female'].value_counts().sort_index()
f_2.plot(kind='bar',label='female Pclass=2',color='green')
ax3.set_xticklabels(['未获救','获救'],rotation=0)
ax3.legend(['中等舱 女性'],loc='best')
ax4 = plt.subplot(324)
m_2 = data_train.Survived[data_train.Pclass == 2][data_train.Sex == 'male'].value_counts().sort_index()
m_2.plot(kind='bar',label='male Pclass=2',color='green')
ax4.set_xticklabels(['未获救','获救'],rotation=0)
ax4.legend(['中等舱 男性'],loc='best')
ax5 = plt.subplot(325)
f_3 = data_train.Survived[data_train.Pclass == 3][data_train.Sex == 'female'].value_counts().sort_index()
f_3.plot(kind='bar',label='female Pclass=3')
ax5.set_xticklabels(['未获救','获救'],rotation=0)
ax5.legend(['中等舱 女性'],loc='upper left')
ax6 = plt.subplot(326)
m_3 = data_train.Survived[data_train.Pclass == 3][data_train.Sex == 'male'].value_counts().sort_index()
m_3.plot(kind='bar',label='male Pclass=3')
ax6.set_xticklabels(['未获救','获救'],rotation=0)
ax6.legend(['中等舱 男性'],loc='best')
plt.show()
#将Sex进行编码
d_t = data_train.drop(['Name','PassengerId','Cabin','Ticket'],axis = 1)
print(d_t['Sex'].value_counts())
d_t['Sex'] = d_t['Sex'].map({'male':1,'female':0}).astype(int)
#对Embarked进行编码
embarked_mode = d_t['Embarked'].value_counts().index[0]
d_t['Embarked'] = d_t['Embarked'].fillna(embarked_mode)
print(d_t['Embarked'].value_counts())
d_t['Embarked'] = d_t['Embarked'].map({'S':2,'C':1,'Q':0})
# Age特征有177个缺失值
d_t.Age.isnull().sum(),d_t.Embarked.isnull().sum() #结果为(177,0)# 填补缺失值
## 使用随机森林进行对年龄的预测并填补数据
def set_missing_data(df,loc):
#取出已知的数值特征
df_age = df[['Age','Pclass','Sex','SibSp','Parch','Fare','Embarked']]
#将已知年龄和未知年龄数据分开
known_age = df_age[df_age[loc].notnull()].values
unknown_age = df_age[df_age[loc].isnull()].values
#将已知年龄部分定位训练集,分为样本特征和样本标签
y_age_train = known_age[:,0]
x_age_train = known_age[:,1:]
#确定测试集样本特征
x_age_test = unknown_age[:,1:]
#构建模型
rfr = RandomForestRegressor(random_state=1998,n_jobs=-1,n_estimators=2000)
#拟合模型
rfr.fit(x_age_train,y_age_train)
#使用模型对测试集标签进行预测
predict_age = rfr.predict(x_age_test).astype(int)
#将预测结果进行填补
df.loc[df_age[loc].isnull(),loc] = predict_age
return df
d_t1 = set_missing_data(d_t,'Age')
#此时我们的数据已经全部补填,并且都是数值型
d_t1.isnull().sum()
查看survived与年龄(Age)的关系:获救者中婴幼儿及中年人居多
fig = plt.figure(figsize=(16,6))
sns.set_style("darkgrid")
sns.set_style('darkgrid',{'font.sans-serif':['SimHei','Arial']})
ax1 = fig.add_subplot(1,2,1)
ax1.set_title('获救者年龄分布')
ax1.set_xlabel('Age')
ax1.set_ylabel('人数')
ax = sns.distplot(x=d_t1[d_t1['Survived'] == 1]['Age'],bins=20,color='green',kde=False,ax=ax1)
ax2 = fig.add_subplot(1,2,2)
ax2.set_title('未获救者年龄分布')
ax2.set_xlabel('Age')
ax = sns.distplot(x=d_t1[d_t1['Survived'] == 0]['Age'],bins=20,color='red',kde=False,ax=ax2)
plt.show()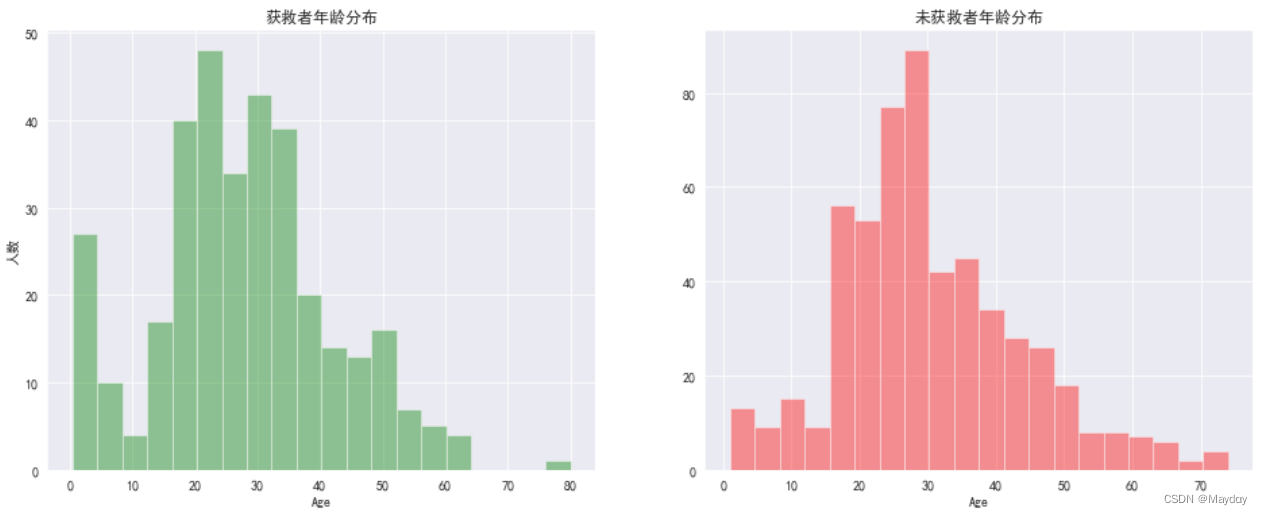
4、 查看上船港口(Embarked)变量
查看各港口人员的客舱等级分布情况:S港口上船的人最多,C港口富人相对更多
#补齐Embarked,不进行编码
d_t2 = data_train.drop(['Name','PassengerId','Cabin','Ticket'],axis = 1)
embarked_mode = d_t2['Embarked'].value_counts().index[0]
d_t2['Embarked'] = d_t2['Embarked'].fillna(embarked_mode)
plt.figure()
ax = sns.factorplot(x='Pclass',col='Embarked',data=d_t2,kind='count')
ax.set_ylabels('人数')
plt.show()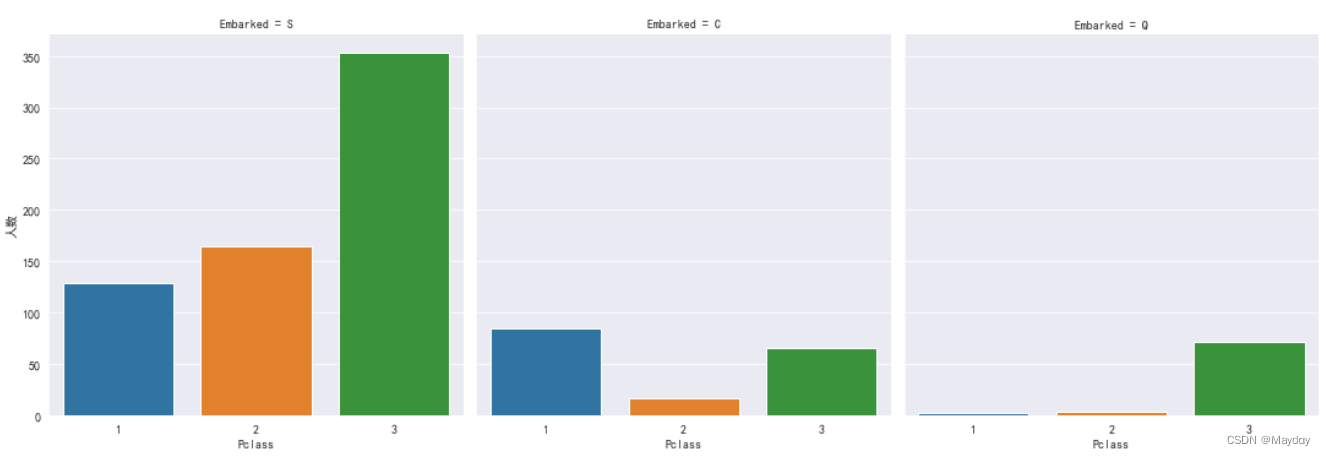
查看各港口男女获救情况
plt.figure()
ax = sns.factorplot(x='Embarked',y='Survived',hue='Sex',data=d_t2)
plt.show()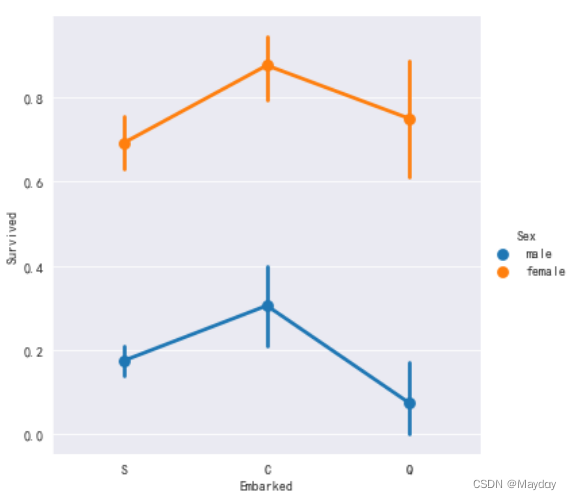
plt.figure()
ax = sns.factorplot(x='SibSp',y='Survived',kind='bar',data=d_t1)
ax.set_ylabels('survival probability')
plt.show()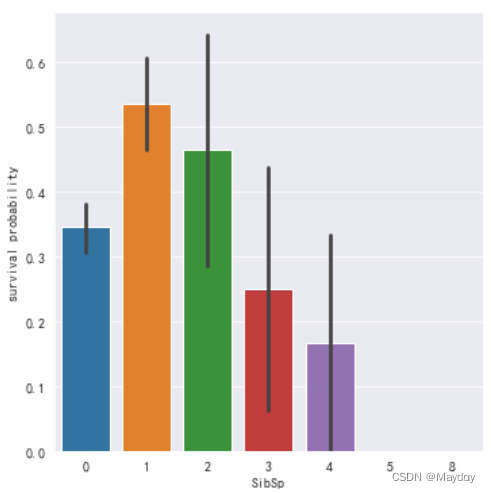
6、查看survived和父母与小孩个数(Parch)的关系
plt.figure()
ax = sns.factorplot(x='Parch',y='Survived',kind='bar',data=d_t1)
ax.set_ylabels('survival probability')
plt.show()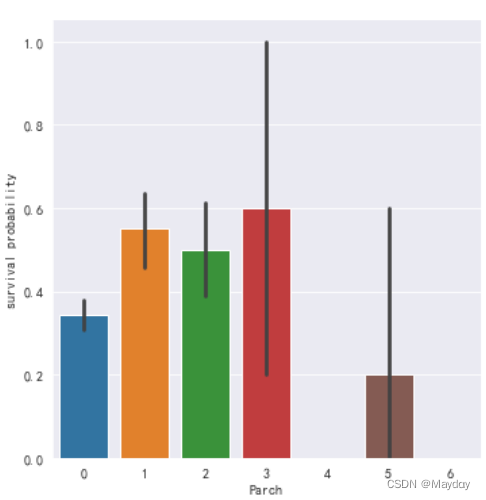
Step4:补齐测试集数据
data_test = pd.read_csv('D:/jupyter-notebook/kaggle/Titanic/test.csv')
#测试集
data_test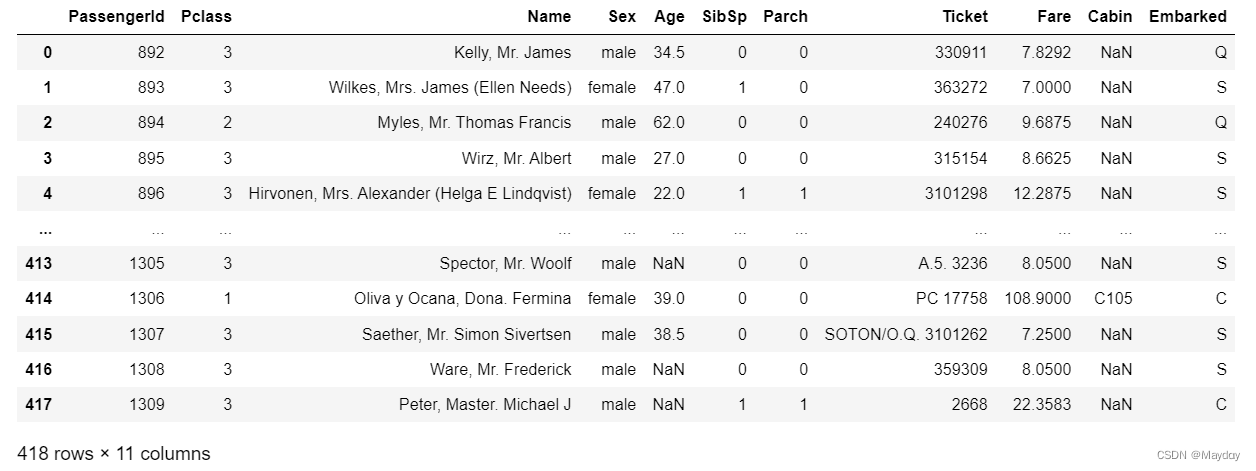
# 查看测试集大致情况,发现Age、Cabin、Fare有缺失值
data_test.info()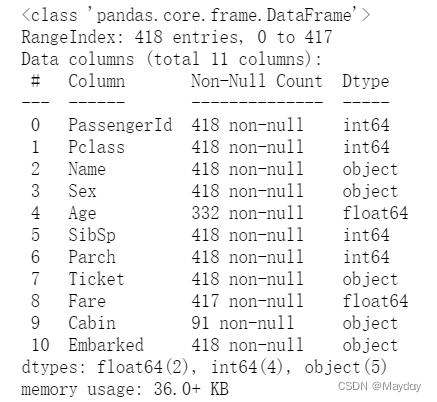
# 用中位数补全Fare
d_te = data_test.drop(['Name','PassengerId','Cabin','Ticket'],axis = 1)
fare_median = d_te['Fare'].median()
d_te['Fare'] = d_te['Fare'].fillna(fare_median)
# 将性别编码
d_te['Sex'] = d_te['Sex'].map({'male':1,'female':0}).astype(int)
# 将Embarked编码
d_te['Embarked'] = d_te['Embarked'].map({'S':2,'C':1,'Q':0})
# 用模型补全Age
d_te = set_missing_data(d_te,'Age')
# 查看测试集缺失值情况
d_te.isnull().sum()
Step5:各种算法建模
#划分训练集,采用20%的训练集计算不同模型的准确度
train_features = d_t1.drop(['Survived'],axis=1)
train_labels = d_t1[['Survived']]
x_train,x_test,y_train,y_test = train_test_split(train_features,train_labels,test_size=0.2,random_state=1998)1、逻辑回归(Logistic Regression):结果为75.98
from sklearn.linear_model import LogisticRegression
logistic = LogisticRegression()
logistic.fit(x_train,y_train)
y_pred1 = logistic.predict(x_test)
logistic_acc = round(metrics.accuracy_score(y_test,y_pred1)*100,2)
print(logistic_acc)
2、朴素贝叶斯(Gaussian Naive Bayes):结果为74.86
from sklearn.naive_bayes import GaussianNB
gaussian = GaussianNB()
gaussian.fit(x_train,y_train)
y_pred2 = gaussian.predict(x_test)
gaussian_acc = round(metrics.accuracy_score(y_test,y_pred2)*100,2)
print(gaussian_acc)3、K-近邻(KNN or k-Nearest Neighbors):结果为68.72
from sklearn.neighbors import KNeighborsClassifier
KNN = KNeighborsClassifier()
KNN.fit(x_train,y_train)
y_pred3 = KNN.predict(x_test)
KNN_acc = round(metrics.accuracy_score(y_test,y_pred3)*100,2)
print(KNN_acc)4、支持向量机(Support Vector Machines):结果为68.72
from sklearn.svm import SVC
svm = SVC()
svm.fit(x_train,y_train)
y_pred4 = svm.predict(x_test)
svm_acc = round(metrics.accuracy_score(y_test,y_pred4)*100,2)
print(svm_acc)from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier()
tree.fit(x_train,y_train)
y_pred5 = tree.predict(x_test)
tree_acc = round(metrics.accuracy_score(y_test,y_pred5)*100,2)
print(tree_acc)6、极限梯度提升算法(eXtreme Gradient Boosting / XGBoost):结果为78.21
from xgboost.sklearn import XGBClassifier
xgb = XGBClassifier()
xgb.fit(x_train,y_train)
y_pred6 = xgb.predict(x_test)
xgb_acc = round(metrics.accuracy_score(y_test,y_pred6)*100,2)
print(xgb_acc)7、Light Gradient Boosting Machine(LightGBM):结果为78.21
from lightgbm.sklearn import LGBMClassifier
lgbm = LGBMClassifier()
lgbm.fit(x_train,y_train)
y_pred7 = lgbm.predict(x_test)
lgbm_acc = round(metrics.accuracy_score(y_test,y_pred7)*100,2)
print(lgbm_acc)8、BP神经网络(BP neural_network):结果为78.77
from sklearn.neural_network import MLPClassifier
bp = MLPClassifier()
bp.fit(x_train,y_train)
y_pred8 = bp.predict(x_test)
bp_acc = round(metrics.accuracy_score(y_test,y_pred8)*100,2)
print(bp_acc)from sklearn.linear_model import Perceptron
perceptron = Perceptron()
perceptron.fit(x_train,y_train)
y_pred9 = perceptron.predict(x_test)
perceptron_acc = round(metrics.accuracy_score(y_test,y_pred9)*100,2)
print(perceptron_acc)10、随机森林(Random Forest):结果为76.54
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier()
rfc.fit(x_train,y_train)
y_pred10 = rfc.predict(x_test)
rfc_acc = round(metrics.accuracy_score(y_test,y_pred10)*100,2)
print(rfc_acc)11、随机梯度下降(Stochastic Gradient Descent):结果为68.16
from sklearn.linear_model import SGDClassifier
sgd = SGDClassifier()
sgd.fit(x_train,y_train)
y_pred11 = sgd.predict(x_test)
sgd_acc = round(metrics.accuracy_score(y_test,y_pred11)*100,2)
print(sgd_acc)12、梯度提升决策树(Gradient Boosting Decision Tree / GBDT):结果为74.3
from sklearn.ensemble import GradientBoostingClassifier
gbdt = GradientBoostingClassifier()
gbdt.fit(x_train,y_train)
y_pred12 = gbdt.predict(x_test)
gbdt_acc = round(metrics.accuracy_score(y_test,y_pred12)*100,2)
print(gbdt_acc)对比各算法的accuracy
model_scores = pd.DataFrame({
'Model' : ['Logistic Regression','Gaussian Naive Bayes','KNN or k-Nearest Neighbors','Support Vector Machines',
'Decision Tree','XGBoost','LightGBM','BP neural_network','Perceptron','Random Forest',
'Stochastic Gradient Descent','Gradient Boosting Decision Tree / GBDT'],
'Scores' : [logistic_acc,gaussian_acc,KNN_acc,svm_acc,tree_acc,xgb_acc,lgbm_acc,bp_acc,perceptron_acc,rfc_acc,sgd_acc,gbdt_acc]
})
model_scores.sort_values(by='Scores',ascending=False)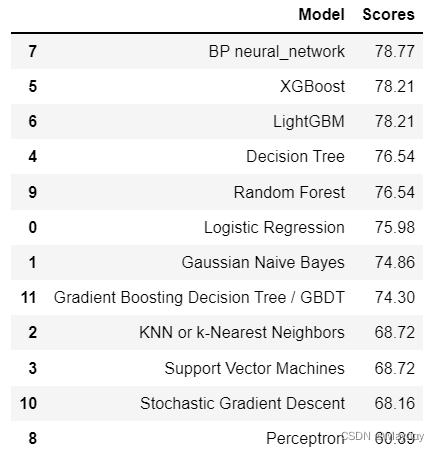
Step6:对d_te进行预测
passenger_id = data_test['PassengerId']
survived_pred = xgb.predict(d_te)
out_put = pd.DataFrame({'PassengerId' : passenger_id,'Survived' : survived_pred})
out_put.to_csv('submission.csv',index=False)原文地址:https://blog.csdn.net/weixin_57622629/article/details/127576698
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_45792.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!




