文章目录
前言
其中包含很多楼盘信息:https://newhouse.fang.com/house/s/b81-b91/
我在网站上进行了一步筛选,即选取北京及北京周边的房源,各位要是想爬取其他城市的房源信息也很简单,改一下url信息即可。
一、数据采集的准备
1.观察url规律
观察到北京及周边地区的房源有很多网页,翻几页就能发现url的规律:
网址就是:https://newhouse.fang.com/house/s/ + b81-b9X + / ;其中X是页码

for i in range(33): # 每页20个小区,共648个小区
url = 'https://newhouse.fang.com/house/s/b81-b9' + str(i+1) + '/'fake–useragent可以伪装生成headers请求头中的User Agent值,将爬虫伪装成浏览器正常操作。
!pip install fake_useragent## 导包
from lxml import etree
import requests
from fake_useragent import UserAgent
import pandas as pd
import random
import time
import csv设置请求参数:需要大家替换的有’cookie‘和’referer‘两项的值:
‘cookie‘:每次访问网站服务器的时候,服务器都会在本地设置cookie,表明访问者的身份。记得每次使用时,都要按照固定方法人工填入一个 cookie。
# 设置请求头参数:User-Agent, cookie, referer
headers = {
'User-Agent' : UserAgent().random,
'cookie' : "global_cookie=kxyzkfz09n3hnn14le9z39b9g3ol3wgikwn; city=www; city.sig=OGYSb1kOr8YVFH0wBEXukpoi1DeOqwvdseB7aTrJ-zE; __utmz=147393320.1664372701.10.4.utmcsr=mp.csdn.net|utmccn=(referral)|utmcmd=referral|utmcct=/mp_blog/creation/editor; csrfToken=KUlWFFT_pcJiH1yo3qPmzIc_; g_sourcepage=xf_lp^lb_pc'; __utmc=147393320; unique_cookie=U_bystp5cfehunxkbjybklkryt62fl8mfox4z*3; __utma=147393320.97036532.1606372168.1664431058.1664433514.14; __utmt_t0=1; __utmt_t1=1; __utmt_t2=1; __utmt_t3=1; __utmt_t4=1; __utmb=147393320.5.10.1664433514",
# 设置从何处跳转过来
'referer': 'https://newhouse.fang.com/house/s/b81-b91/'
}【腾讯文档】’cookie’和 ‘referer’的更改方法:
https://docs.qq.com/doc/DR2RzUkJTQXJ5ZGt6
2.设定爬取位置和路径(xpath)
因为爬取数据主要依托于’目标数据所在位置的确定’,所以一定先要搞清楚目标数据的位置(位于div的哪一块);
先发送请求:
url = 'https://newhouse.fang.com/house/s/b81-b91/'# 首页网址URL
page_text = requests.get(url=url, headers=headers).text# 请求发送
tree = etree.HTML(page_text)#数据解析我想爬取的数据主要就是:楼盘名称、评论数、房屋面积、详细地址、所在区域、均价 5项数据。
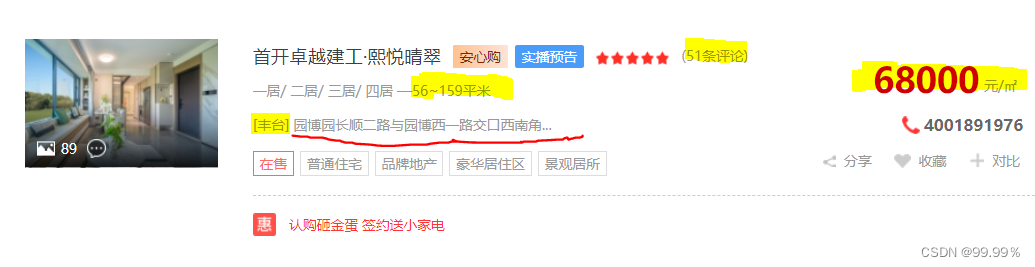
【腾讯文档】获取具体爬取位置的讲解
https://docs.qq.com/doc/DR3BFRW1lVGFRU0Na
# 小区名称
name = [i.strip() for i in tree.xpath("//div[@class='nlcd_name']/a/text()")]
print(name)
print(len(name))
# 评论数
commentCounts = tree.xpath("//span[@class='value_num']/text()")
print(commentCounts)
print(len(commentCounts))
# 房屋面积
buildingarea = [i.strip() for i in tree.xpath("//div[@class='house_type clearfix']/text()")]
print(buildingarea)
print(len(buildingarea))
# 详细地址
detailAddress = tree.xpath("//div[@class='address']/a/@title")
print(detailAddress)
print(len(detailAddress))
# 所在区
district = [i.strip() for i in tree.xpath("//div[@class='address']//span[@class='sngrey']/text()")]
print(district)
print(len(district))
# 均价
num = tree.xpath("//div[@class='nlc_details']/div[@class='nhouse_price']/span/text() | //div[@class='nlc_details']/div[@class='nhouse_price']/i/text()")
unit = tree.xpath("//div[@class='nlc_details']/div[@class='nhouse_price']/em/text()")
price = [i+j for i,j in zip(num, unit)]
print(price)
print(len(price))此时采集到的数据还包含着:[]方括号、—横杠、“平米”等符号或者单位,所以要对数据进行简单的split处理,把真正需要的数据提取出来:
# 评论数处理
commentCounts = [int(i.split('(')[1].split('条')[0]) for i in commentCounts]
print(commentCounts)
# 详细地址处理
detailAddress = [i.split(']')[1] for i in detailAddress]
print(detailAddress)
# 所在区字段处理
district = [i.split('[')[1].split(']')[0] for i in district]
print(district)
# 房屋面积处理
t = []
for i in buildingarea:
if i != '/' and i != '':
t.append(i.split('—')[1].split('平米')[0])
print(t)
print(len(t))二、数据采集
1. 建立存放数据的dataframe
df = pd.DataFrame(columns = ['小区名称', '详细地址', '所在区', '均价', '评论数'])
df2. 开始爬取
这里图方便就只爬取了前10页,因为后面的房源就经常少信息,要么没有面积信息,要么没有所在区域。
for k in range(10):
url = 'https://newhouse.fang.com/house/s/b81-b9' + str(k+1) + '/'
page_text = requests.get(url=url, headers=headers).text #请求发送
tree = etree.HTML(page_text) #数据解析
# 小区名称
name = [i.strip() for i in tree.xpath("//div[@class='nlcd_name']/a/text()")]
# 评论数
commentCounts = tree.xpath("//span[@class='value_num']/text()")
# 详细地址
detailAddress = tree.xpath("//div[@class='address']/a/@title")
# 所在区
district = [i.strip() for i in tree.xpath("//div[@class='address']//text()")]
# 均价
num = tree.xpath("//div[@class='nlc_details']/div[@class='nhouse_price']/span/text() | //div[@class='nlc_details']/div[@class='nhouse_price']/i/text()")
unit = tree.xpath("//div[@class='nlc_details']/div[@class='nhouse_price']/em/text()")
price = [i+j for i,j in zip(num, unit)]
#评论数处理
commentCounts = [int(i.split('(')[1].split('条')[0]) for i in commentCounts]
#详细地址处理
tmp1 = []
for i in detailAddress:
if ']' in i:
tmp1.append(i.split(']')[1])
continue
tmp1.append(i)
detailAddress = tmp1
#所在区处理
tmp2 = []
for i in district:
if ']' in i and '[' in i:
tmp2.append(i.split(']')[0].split('[')[1])
district = tmp2
dic = {'小区名称':name, '详细地址':detailAddress, '所在区':district, '均价':price, '评论数':commentCounts}
df2 = pd.DataFrame(dic)
df = pd.concat([df,df2], axis=0)
print('第{}页爬取成功, 共{}条数据'.format(k+1, len(df2)))
print('全部数据爬取成功')
3. 把数据导出成csv表格
df.to_csv('北京小区数据信息.csv',index=None)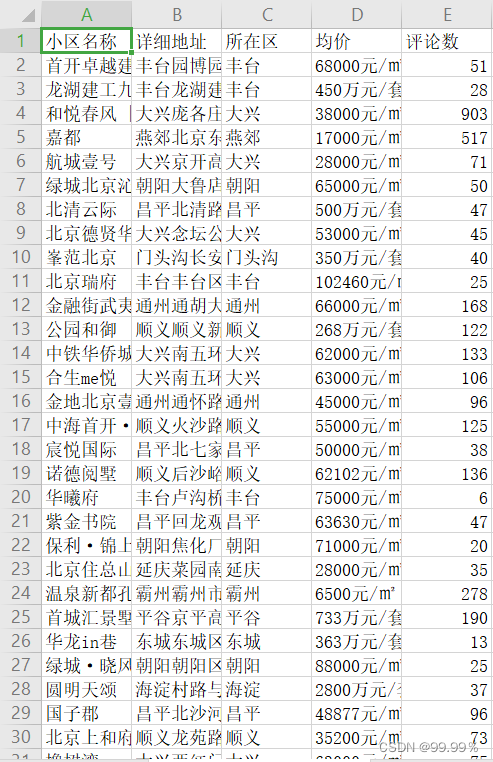
总结
说实话,本文使用的爬取方法简单而且信息正确,但是存在一些不足,比如面对楼盘的部分信息空缺时,就无法按照null来采集,而是会报错,所以我现有的解决方法就是在循环中人工去设置条件,跳过空缺信息。
原文地址:https://blog.csdn.net/weixin_50706330/article/details/127115265
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_46098.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!