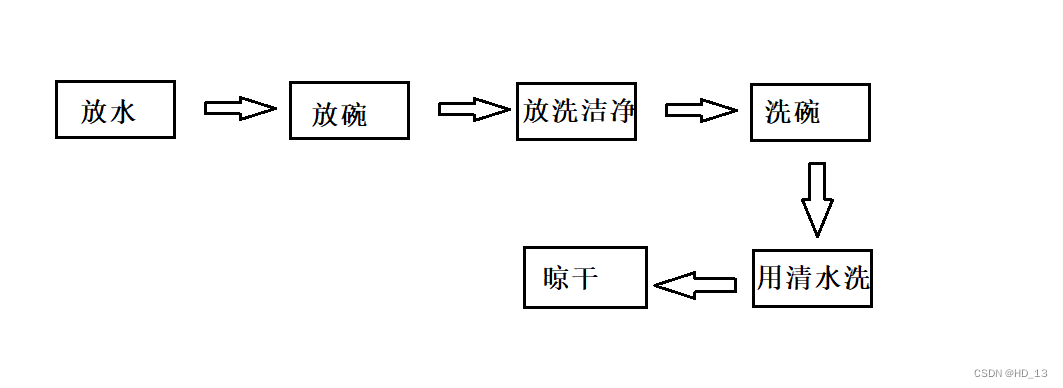
1. 模型训练过程划分
if __name__ == '__main__':
...
1.1. 定义过程
1.1.1. 全局参数设置
| 参数名 | 作用 |
|---|---|
learning_rate |
控制模型参数的更新步长 |
device |
指定模型训练使用的设备(CPU或GPU) |
num_epochs |
指定在训练集上训练的轮数 |
batch_size |
指定每批数据的样本数 |
num_workers |
指定加载数据集的进程数 |
prefetch_factor |
指定每个进程预加载的批数 |
1.1.2. 模型定义
| 组件 | 作用 |
|---|---|
writer |
定义tensorboard的事件记录器 |
net |
定义神经网络结构 |
net.apply(init_weights) |
模型参数初始化 |
criterion |
定义损失函数 |
optimizer |
定义优化器 |
1.2. 数据集加载过程
1.2.1. Dataset类:创建数据集
1.2.2. Dataloader类:加载数据集
- 作用
- 主要参数
参数 作用 dataset指定数据集 batch_size指定每批数据的样本数 shuffle=False指定是否在每个训练周期(epoch)开始时进行数据打乱 sampler=None指定如何从数据集中选择样本,如果指定这个参数,那么shuffle必须设置为False batch_sampler=None指定生成每个批次中应包含的样本数据的索引。与batch_size、shuffle 、sampler and drop_last参数不兼容 num_workers=0指定进行数据加载的进程数 collate_fn=None指定将一列表的样本合成mini–batch的方法,用于映射型数据集 pin_memory=False是否将数据缓存在物理RAM中以提高GPU传输效率 drop_last=False是否在批次结束时丢弃剩余的样本(当样本数量不是批次大小的整数倍时) timeout=0定义在每个批次上等待可用数据的最大秒数。如果超过这个时间还没有数据可用,则抛出一个异常。默认值为0,表示永不超时。 worker_init_fn=None指定在每个工作进程启动时进行的初始化操作。可以用于设置共享的随机种子或其他全局状态。 multiprocessing_context=None指定多进程数据加载的上下文环境,即多进程库 generator=None指定一个生成器对象来生成数据批次 prefetch_factor=2控制数据加载器预取数据的数量,默认预取比实际所需的批次数量多2倍的数据 persistent_workers=False控制数据加载器的工作进程是否在数据加载完成后继续存在
1.3. 训练循环
for epoch in trange(num_epochs):
...
- 循环内部主要有以下模块:
- 训练模型
for X, y in dataloader_train: X, y = X.to(device), y.to(device) loss = criterion(net(X), y) optimizer.zero_grad() loss.mean().backward() optimizer.step()def evaluate_loss(dataloader): """评估给定数据集上模型的损失""" metric = d2l.Accumulator(2) # 损失的总和, 样本数量 with torch.no_grad(): for X, y in dataloader: X, y = X.to(device), y.to(device) loss = criterion(net(X), y) metric.add(loss.sum(), loss.numel()) return metric[0] / metric[1]
2. 优化分析
2.1. 定义过程
2.2. 数据集加载过程
- 特点:只是定义数据加载的方式,并没有加载数据。
- 优化思路:合理设置数据加载参数,如
batch_size:一般取能被训练集大小整除的值。过小,则每次参数更新时所用的样本数较少,模型无法充分地学习数据的特征和分布,同时参数更新频繁,模型收敛速度提高,CPU到GPU的数据传输次数增加,CPU和内存的消耗总量增加;过大,则每次参数更新时所用的样本数较多,模型性能更稳定,对GPU、CPU和内存的单次消耗增加,对硬件配置要求更高,同时参数更新缓慢,模型收敛速度下降。num_workers:一般取CPU内核数。过小,则数据加载进程少,数据加载缓慢;过大,则数据加载进程多,对CPU要求高。pin_memory:当设置为True时,它告诉DataLoader将加载的数据张量固定在CPU内存中,使数据传输到GPU的过程更快。prefetch_factor:决定每次从磁盘加载多少个batch的数据到内存中,预先加载batch越多,在处理数据时,不会因为数据加载的延迟而影响整体的训练速度,同时可以让GPU在处理数据时保持忙碌,从而提高GPU利用率;过大,则会导致CPU和内存消耗增加。
2.3. 训练循环
2.3.1. 训练模型
- 特点:训练结构固定
- 优化思路:
- 将数据转移到GPU,同时
non_blocking=True。 - 优化训练结构:比如使用自动混合精度(AMP,要求pytorch>=1.6.0),通过将模型和数据转换为低精度的形式(如FP16),可以显著减少内存使用,即
from torch.cuda.amp import autocast, GradScaler grad_scaler = GradScaler() for epoch in range(num_epochs): start_time = time.perf_counter() for X, y in dataloader_train: X, y = X.to(device, non_blocking=True), y.to(device, non_blocking=True) with autocast(): loss = criterion(net(X), y) optimizer.zero_grad() grad_scaler.scale(loss.mean()).backward() grad_scaler.step(optimizer) grad_scaler.update() - 将数据转移到GPU,同时
2.3.2. 评估模型
原文地址:https://blog.csdn.net/weixin_45725295/article/details/134813577
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_47708.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。