|
你好,我是安然无虞。 |

聚合函数:怎么高效地进行分组统计?
MySQL中有5种聚合函数较为常用,分别是求和函数sum(), 求平均函数avg(), 最大值函数max(), 最小值函数min()和计数函数count()。
在超市项目中有一个需求是这样的:经营者提出,他们需要统计一个门店,每天、每个单品的销售情况,包括销售数量和销售金额等。这里涉及3个数据表,具体信息如下所示:



sum( )
我们可以用它来获取用户某个门店,每天、每种商品的销售总计数据:
mysql> select
-> left(b.transdate, 10), -- 从关联表获取交易时间,并且通过LEFT函数,获取交易时间字符串的左边10个字符,得到年月日的数据
-> c.goodsname, -- 从关联表获取商品名称
-> sum(a.quantity), -- 数量求和
-> sum(a.salesvalue) -- 金额求和
-> from
-> demo.transactiondetails a
-> join
-> demo.transactionhead b on (a.transactionid = b.transactionid)
-> join
-> demo.goodsmaster c on (a.itemnumber = c.itemnumber)
-> group by left(b.transdate, 10) , c.goodsname -- 分组
-> order by left(b.transdate, 10) , c.goodsname; -- 排序
+-----------------------+-----------+-----------------+-------------------+
| LEFT(b.transdate, 10) | goodsname | SUM(a.quantity) | SUM(a.salesvalue) |
+-----------------------+-----------+-----------------+-------------------+
| 2020-12-01 | 书 | 2.000 | 178.00 |
| 2020-12-01 | 笔 | 5.000 | 25.00 |
| 2020-12-02 | 书 | 4.000 | 356.00 |
| 2020-12-02 | 笔 | 16.000 | 80.00 |
+-----------------------+-----------+-----------------+-------------------+
4 rows in set (0.01 sec)
对上面出现的2个关键字:left 和 order by进行解释:
left(str, n):表示返回字符串str最左边的n个字符。我们这里的 left(a.transdate,10),表示返回交易时间字符串最左边的 10 个字符。在 MySQL 中,DATETIME 类型的默认格式是:YYYY-MM-DD,也就是说,年份 4 个字符,之后是“-”,然后是月份 2 个字符,之后又是“-”,然后是日 2 个字符,所以完整的年月日是 10 个字符。用户要求按照日期统计,所以,我们需要从日期时间数据中,把年月日的部分截取出来。
order by:表示按照指定的字段排序。超市经营者指定按照日期和单品统计,那么,统计的结果按照交易日期和商品名称的顺序排序,会更加清晰。
第一步,完成3个表的连接。

第二步,对结果集按照交易时间和商品名称进行分组,我们可以分成下面4组。
组一:

组二:

组三:

组四:

第三步,对各组的销售数量和销售金额进行统计,并且按照交易日期和商品名称排序,这样就得到了我们需要的结果,如下所示:
+-----------------------+-----------+-----------------+-------------------+
| LEFT(b.transdate, 10) | goodsname | SUM(a.quantity) | SUM(a.salesvalue) |
+-----------------------+-----------+-----------------+-------------------+
| 2020-12-01 | 书 | 2.000 | 178.00 |
| 2020-12-01 | 笔 | 5.000 | 25.00 |
| 2020-12-02 | 书 | 4.000 | 356.00 |
| 2020-12-02 | 笔 | 16.000 | 80.00 |
+-----------------------+-----------+-----------------+-------------------+
4 rows in set (0.01 sec)
需要注意的是,求和函数获取的是分组中的合计数据,所以你要对分组的结果有准确的把握,否则就很容易搞错。这也就是说,你要知道是按什么字段进行分组的。如果是按多个字段分组,你要知道字段之间有什么样的层次关系;如果是按照以字段作为变量的某个函数进行分组的,你要知道这个函数的返回值是什么,返回值又是如何影响分组的等。
avg( ) & max( ) & min( )
1.avg( )
首先,我们来学习下计算平均值的函数avg( )。它的作用是,通过计算分组内指定字段值的和,以及分组内的记录数,算出分组内指定字段的平均值。
举个例子,如果用户需要计算每天、每种商品,平均一次卖出多少个、多少钱,这个时候,我们就可以用到avg( )函数了,如下所示:
mysql> select
-> left(a.transdate, 10),
-> c.goodsname,
-> avg(b.quantity), -- 平均数量
-> avg(b.salesvalue) -- 平均金额
-> from
-> demo.transactionhead a
-> join
-> demo.transactiondetails b on (a.transactionid = b.transactionid)
-> join
-> demo.goodsmaster c on (b.itemnumber = c.itemnumber)
-> group by left(a.transdate,10),c.goodsname
-> order by left(a.transdate,10),c.goodsname;
+-----------------------+-----------+-----------------+-------------------+
| LEFT(a.transdate, 10) | goodsname | AVG(b.quantity) | AVG(b.salesvalue) |
+-----------------------+-----------+-----------------+-------------------+
| 2020-12-01 | 书 | 2.0000000 | 178.000000 |
| 2020-12-01 | 笔 | 5.0000000 | 25.000000 |
| 2020-12-02 | 书 | 2.0000000 | 178.000000 |
| 2020-12-02 | 笔 | 8.0000000 | 40.000000 |
+-----------------------+-----------+-----------------+-------------------+
4 rows in set (0.00 sec)
2.max( )和min( )
MAX( ) 表示获取指定字段在分组中的最大值,MIN( ) 表示获取指定字段在分组中的最小值。
它们的实现原理差不多,下面重点讲一下 MAX( ),知道了它的用法,MIN( ) 也就很好理解了。我们还是来看具体的例子。假如用户要求计算每天里的一次销售的最大数量和最大金额,就可以用下面的代码,得到我们需要的结果:
mysql> select
-> left(a.transdate, 10),
-> max(b.quantity), -- 数量最大值
-> max(b.salesvalue) -- 金额最大值
-> from
-> demo.transactionhead a
-> join
-> demo.transactiondetails b on (a.transactionid = b.transactionid)
-> join
-> demo.goodsmaster c on (b.itemnumber = c.itemnumber)
-> group by left(a.transdate,10)
-> order by left(a.transdate,10);
+-----------------------+-----------------+-------------------+
| LEFT(a.transdate, 10) | MAX(b.quantity) | MAX(b.salesvalue) |
+-----------------------+-----------------+-------------------+
| 2020-12-01 | 5.000 | 178.00 |
| 2020-12-02 | 10.000 | 267.00 |
+-----------------------+-----------------+-------------------+
2 rows in set (0.00 sec)
代码很简单,你一看就明白了。但是,这里有个问题你要注意:千万不要以为 MAX(b.quantity)和 MAX(b.salesvalue)算出的结果一定是同一条记录的数据。实际上,MySQL 是分别计算的。下面我们就来分析一下刚刚的查询。
查询中用到 3 个相互关联的表:销售流水明细表、销售流水单头表和商品信息表。这 3 个表连接完成之后,MySQL 进行了分组。
组一:

组二:
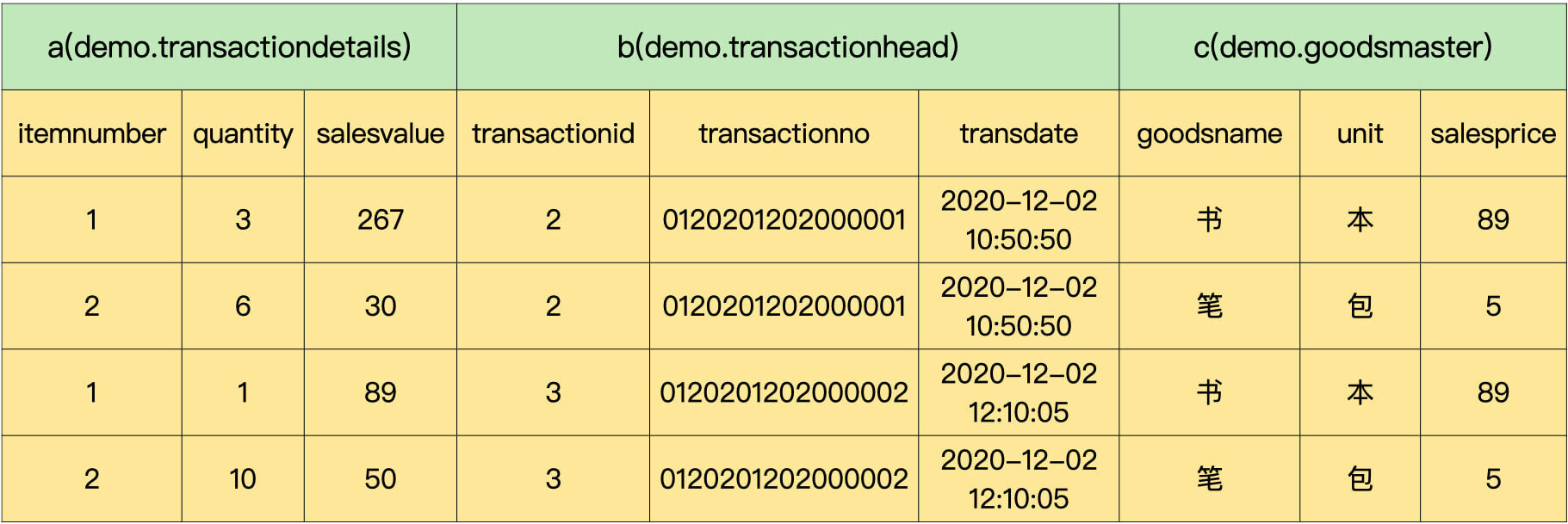
在第一组中,最大数量出现在第 2 条记录,是 5;最大金额出现在第 1 条记录,是 178。同样道理,在第二组中,最大数量出现在第 4 条记录,是 10;最大金额则出现在第 1 条记录,是 267。
所以,max(字段)这个函数返回分组集中最大的那个值。如果你要查询max(字段1)和max(字符2),而它们是相互独立、分别计算的,所以我们千万不要想当然的认为结果在同一条记录上,那样的话就掉到坑里面了。
count( )
通过count( ), 我们可以了解数据集的大小,这对系统优化十分重要。
举个小例子,由于用户的销售数据很多,而且每天都在增长,因此,在做销售查询的时候,经常会遇到卡顿的问题。这是因为,查询的数据量太大了,导致系统不得不花很多时间来处理数据,并给数据集分配资源,比如内存什么的。
怎么解决卡顿的问题呢?我们想到了分页的策略。
所谓的分页策略,其实就是,不把查询的结果一次性全部返回给客户端,而是根据用户电脑屏幕的大小,计算一屏可以显示的记录数,每次只返回用户电脑屏幕可以显示的数据集。接着,再通过翻页、跳转等功能按钮,实现查询目标的精准锁定。这样一来,每次查询的数据量较小,也就大大提高了系统的响应速度。
这个策略的实现的一个关键,就是要计算出符合条件的记录有多少条,之后才能计算出一共有几页,能不能翻页或者跳转。
要计算记录数,就要用到count( )函数了,这个函数有两种情况:
count(*): 统计一共有多少条记录;count(字段): 统计有多少个不为空的字段值。
1.count(*)
如果count(*)与group by一起使用,就表示统计分组内有多少条数据。它也可以单独使用,这就相当于数据集全体是一个分组,统计全部数据集的记录数。
举个例子,假设我们有个销售流水明细表如下:
mysql> select *
-> from demo.transactiondetails;
+---------------+------------+----------+-------+------------+
| transactionid | itemnumber | quantity | price | salesvalue |
+---------------+------------+----------+-------+------------+
| 1 | 1 | 2.000 | 89.00 | 178.00 |
| 1 | 2 | 5.000 | 5.00 | 25.00 |
| 2 | 1 | 3.000 | 89.00 | 267.00 |
| 2 | 2 | 6.000 | 5.00 | 30.00 |
| 3 | 1 | 1.000 | 89.00 | 89.00 |
| 3 | 2 | 10.000 | 5.00 | 50.00 |
+---------------+------------+----------+-------+------------+
6 rows in set (0.00 sec)
如果我们一屏可以显示30行,需要多少页才能显示完这个表的数据呢?
mysql> select count(*)
-> from demo.transactiondetails;
+----------+
| COUNT(*) |
+----------+
| 6 |
+----------+
1 row in set (0.03 sec)
我们这里只有 6 条数据,一屏就可以显示了,所以一共 1 页。
那么,如果超市经营者想知道,每天、每种商品都有几次销售,我们就需要按天、按商品名称,进行分组查询:
mysql> select
-> left(a.transdate, 10), c.goodsname, count(*) -- 统计销售次数
-> from
-> demo.transactionhead a
-> join
-> demo.transactiondetails b on (a.transactionid = b.transactionid)
-> join
-> demo.goodsmaster c on (b.itemnumber = c.itemnumber)
-> group by left(a.transdate, 10) , c.goodsname
-> order by left(a.transdate, 10) , c.goodsname;
+-----------------------+-----------+----------+
| LEFT(a.transdate, 10) | goodsname | COUNT(*) |
+-----------------------+-----------+----------+
| 2020-12-01 | 书 | 1 |
| 2020-12-01 | 笔 | 1 |
| 2020-12-02 | 书 | 2 |
| 2020-12-02 | 笔 | 2 |
+-----------------------+-----------+----------+
4 rows in set (0.00 sec)
运行这段代码,我们就得到了每天、每种商品有几次销售的全部结果。
2.count (字段)
count (字段)用来统计分组内这个字段的值出现了多少次。如果字段值是空,就不统计。
假设我们有一个商品信息表,里面包括了商品编号、条码、名称、规格、单位和售价的信息。
mysql> select *
-> from demo.goodsmaster;
+------------+---------+-----------+---------------+------+------------+
| itemnumber | barcode | goodsname | specification | unit | salesprice |
+------------+---------+-----------+---------------+------+------------+
| 1 | 0001 | 书 | 16开 | 本 | 89.00 |
| 2 | 0002 | 笔 | NULL | 支 | 5.00 |
| 3 | 0002 | 笔 | NULL | 支 | 10.00 |
+------------+---------+-----------+---------------+------+------------+
3 rows in set (0.01 sec)
如果我们要统计字段“goodsname”出现了多少次,就要用到函数 COUNT(goodsname),结果是 3 次:
mysql> select count(goodsname) -- 统计商品名称字段
-> from demo.goodsmaster;
+------------------+
| COUNT(goodsname) |
+------------------+
| 3 |
+------------------+
1 row in set (0.00 sec)
如果我们统计字段“specification”,用 COUNT(specification),结果是 1 次:
mysql> select count(specification) -- 统计规格字段
-> from demo.goodsmaster;
+----------------------+
| COUNT(specification) |
+----------------------+
| 1 |
+----------------------+
1 row in set (0.00 sec)
说明:3 条记录里面的字段“goodsname”没有空值,因此被统计了 3 次;而字段“specification”有 2 个空值,因此只统计了 1 次。
|
遇见安然遇见你,不负代码不负卿。 |
|
谢谢老铁的时间,咱们下篇再见~ |

原文地址:https://blog.csdn.net/weixin_57544072/article/details/134276481
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_4951.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!