1、Hadoop、HDFS、YARN介绍
Hadoop解决两件事情:海量数据的存储(使用HDFS)和海量数据的计算(使用MapReduce)。
(1)Hadoop简介与优势
简介:
1)Hadoop是一个由Apachc基金会所开发的分布式系统基础架构。
2)主要解决,海量数据的存储和海量数据的分析计算问题。
3)广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
优势:
1)高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。
2)高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
3)高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
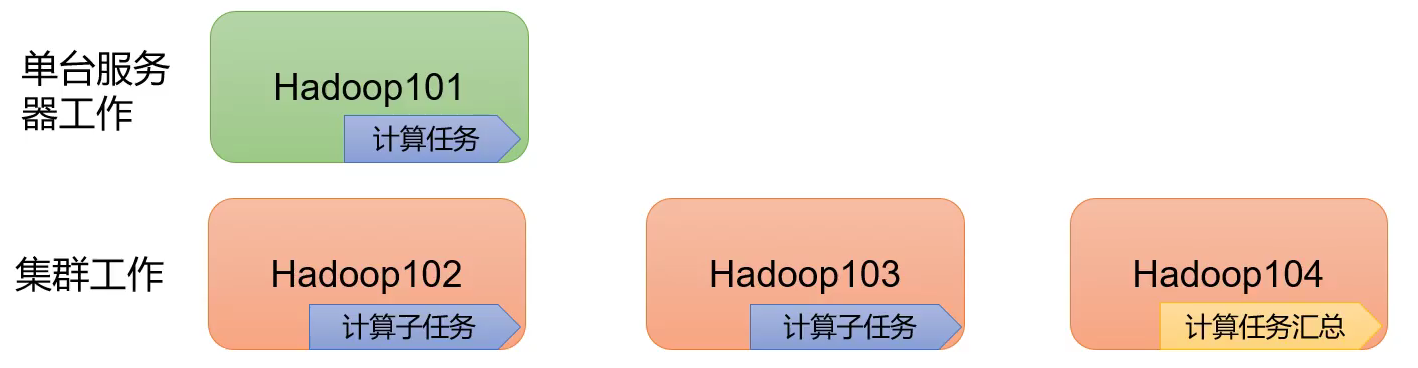
4)高容错性:能够自动将失败的任务自动分配。
(2)Hadoop组成
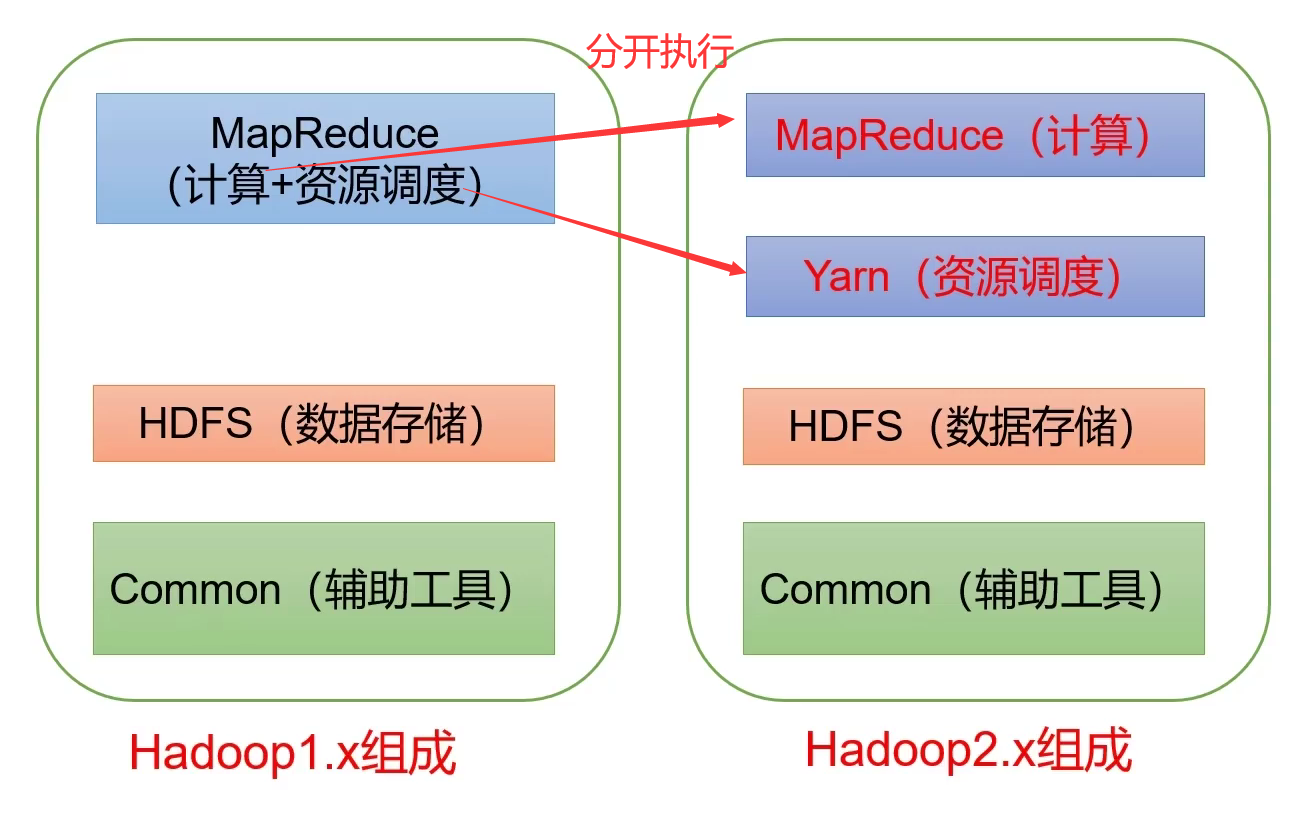
- 在Hadoop1.x时代,Hadoop中的MapReduce同时处理业务逻辑运算和资源的调度,耦合性较大。
- 在Hadoop2.x时代,增加了Yarn。Yarn只负责资源的调度,MapReduce只负责运算。
- 而Hadoop3.x在组成上没有变化。
(3)HDFS概述
Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。主要解决海量数据存储的问题。
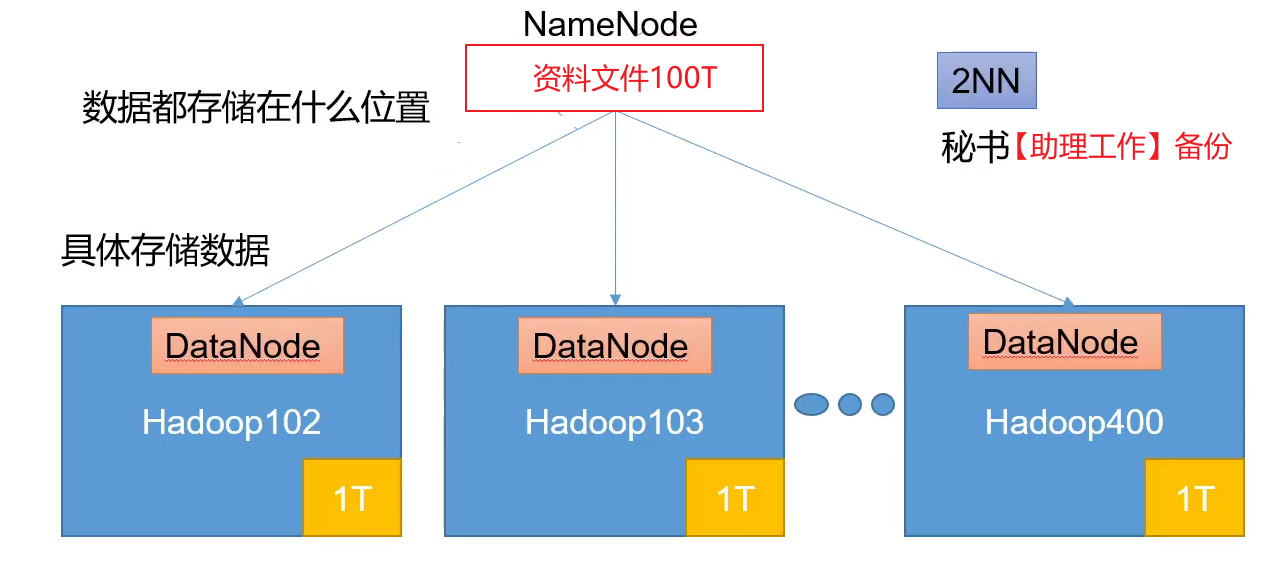
- NameNode(nn)︰存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数.文件权限),以及每个文件的块列表和块所在的DataNodc等。【记录数据存储在哪个节点上】
- DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。【负责数据的存储】
- Secondary NameNode(2nn):每隔一段时间对NameNode元数据备份。【防止NameNode突然瘫痪,进行备份】
(4)YARN概述
Yet Another Resource Negotiator简称YARN,另一种资源协调者,是Hadoop的资源管理器。
- Resource Maneger(RM):所有资源的管理者,是整个集群资源(内存、CPU等)的老大,管理所有的内存和CPU。
- NodeManager(NM):单节点资源的管理者,是单个节点服务器资源的老大。
- ApplicationMaster(AM):单个任务运行的老大。
- Container:容器,相当于一台独立的服务器,里面封装了任务运行所需要的资源,如内存、CPU、磁盘、网络等。

说明1:客户端可以有多个
说明2∶集群上可以运行多个ApplicationMaster【相当于Hadoop的并行运算】
说明3:每个NodeManager上可以有多个Container
- 一个Container默认的内存是1-8G。由于一个NodeManager是4G的内存,因此一个NodeManager上最多开辟4个Container【每个Container=1G】,而一个Container最少需要分配一个CPU,因此最终一个NodeManager上最多开辟2个Container。
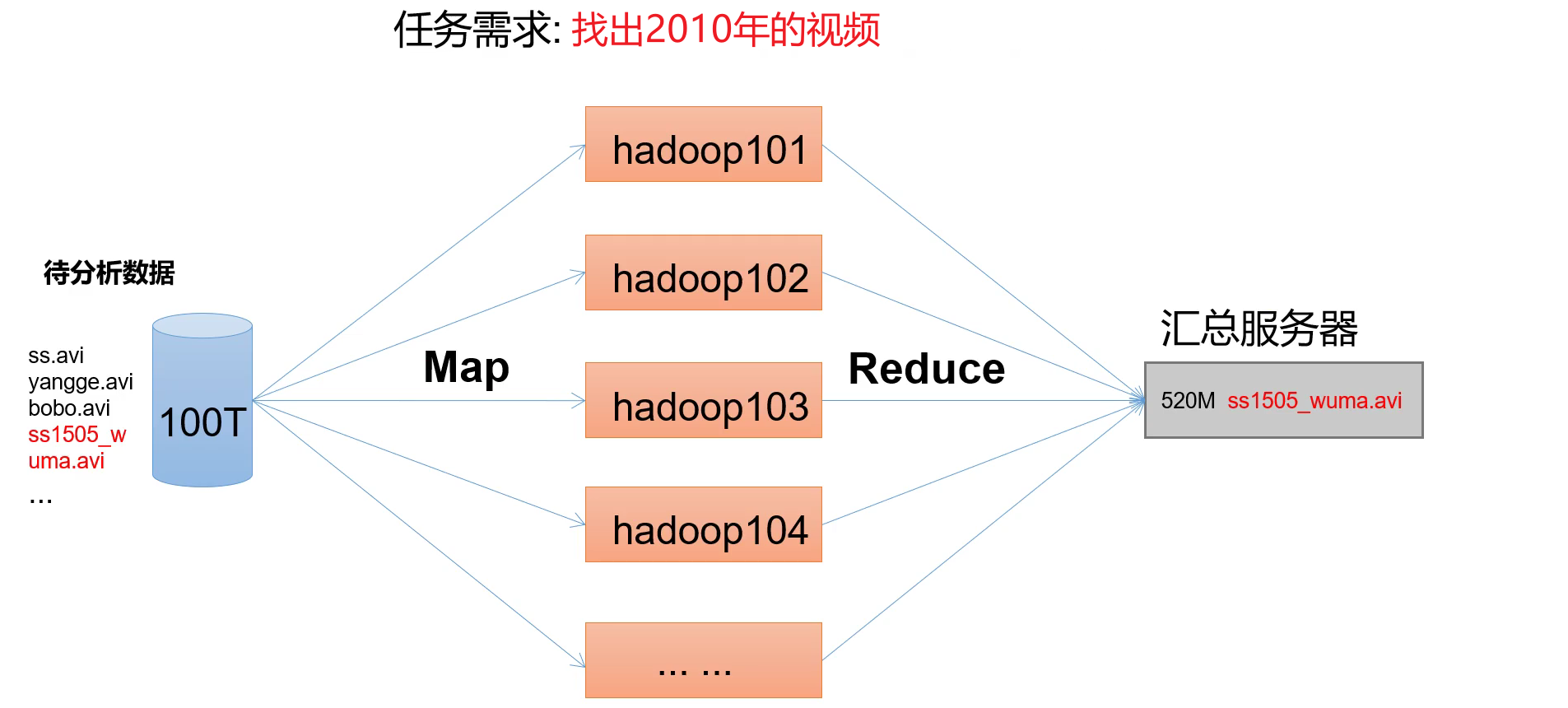
(5)MapReduce概述
MapReduce将计算过程分为两个阶段:Map和 Reduce。
2、安装
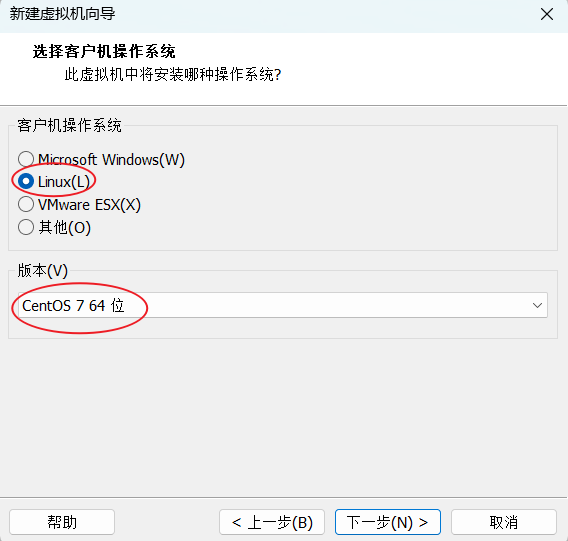
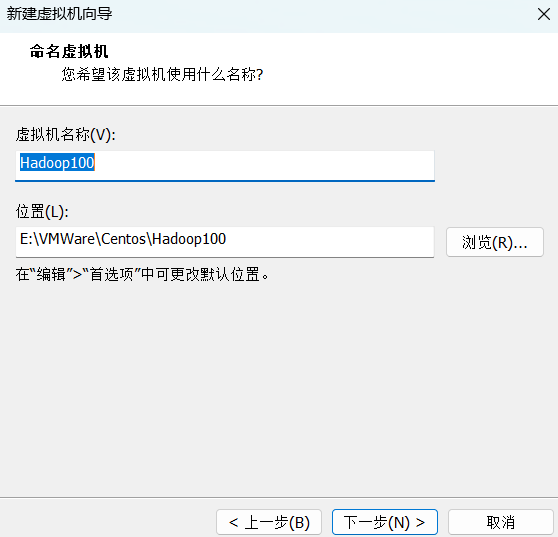
(1)Centos7.5软硬件安装


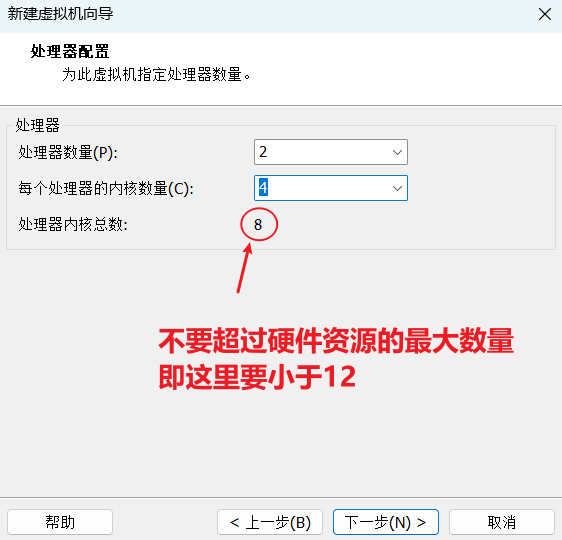
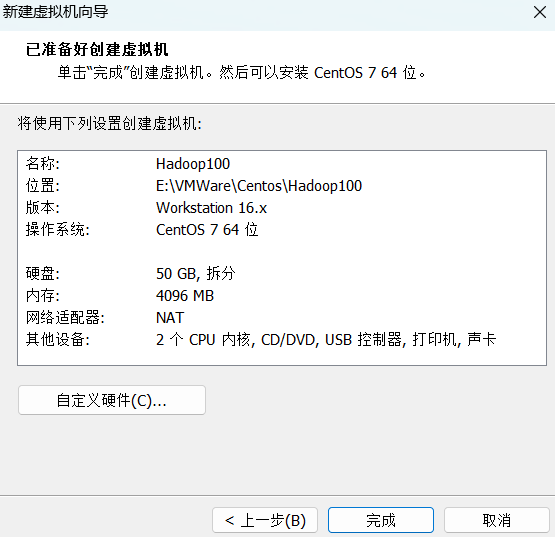
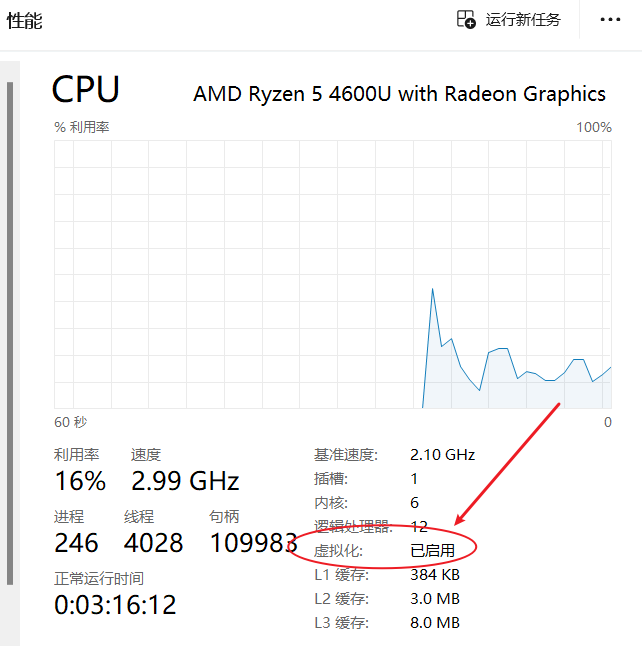
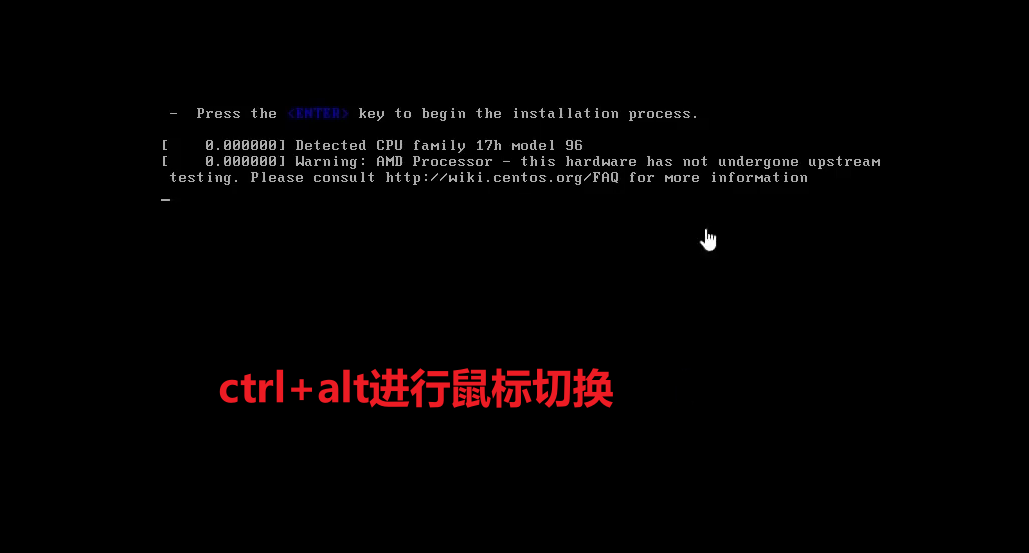
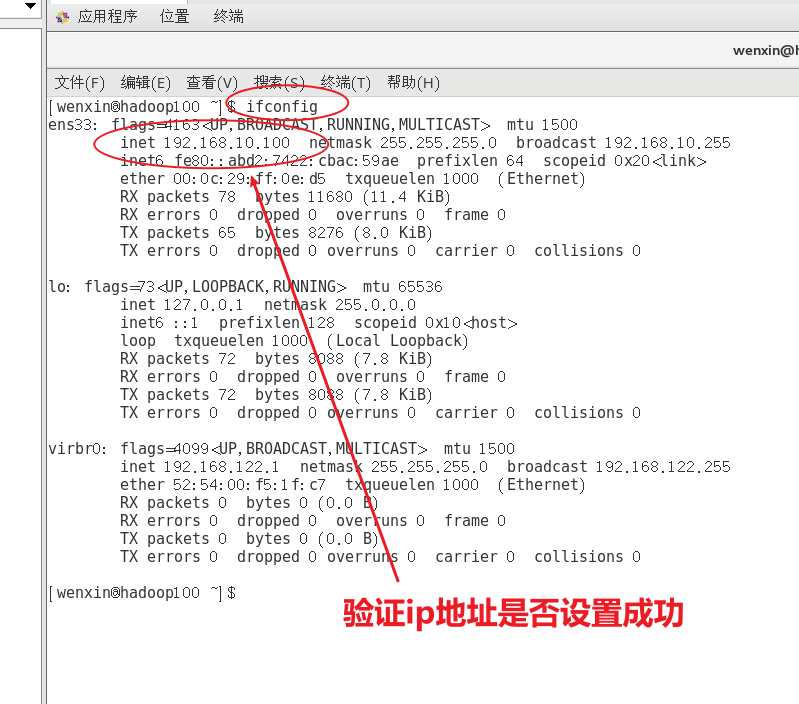
(2)配置服务器IP地址
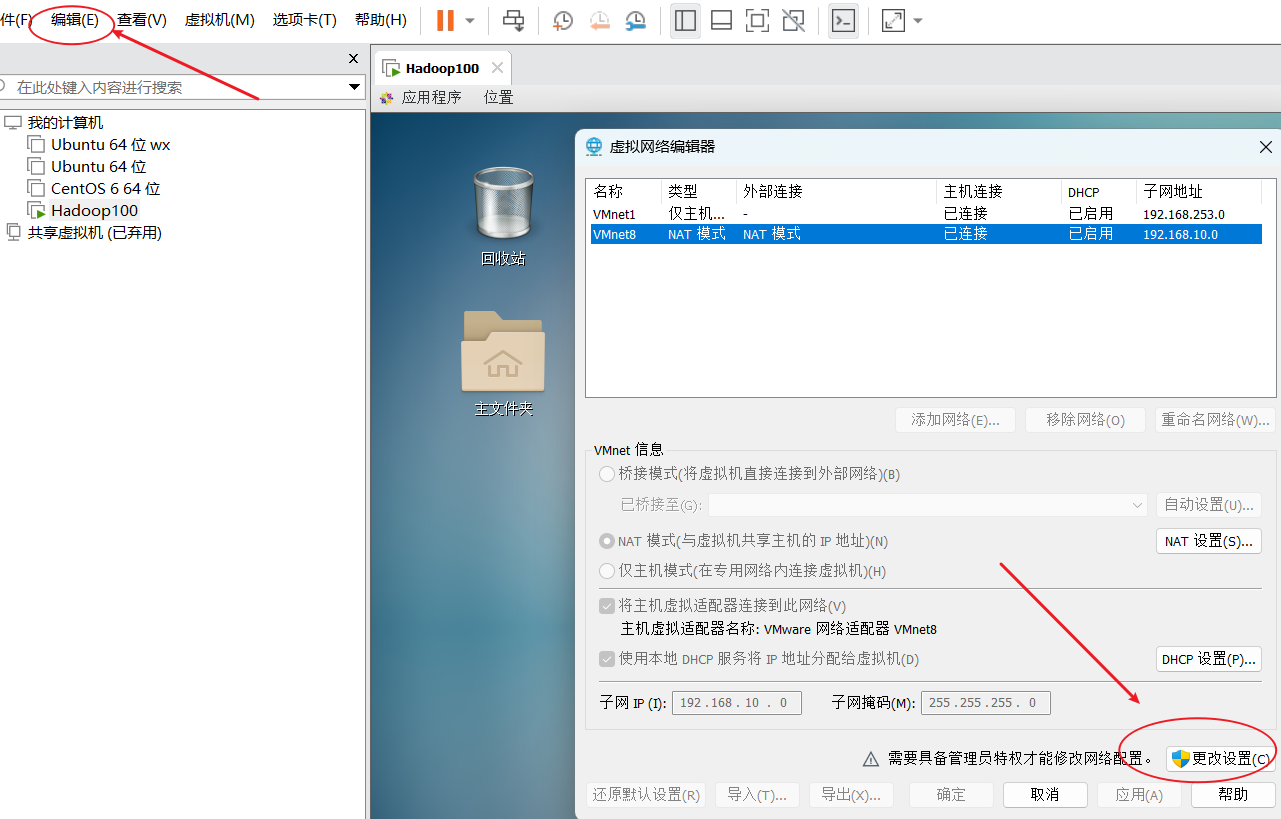

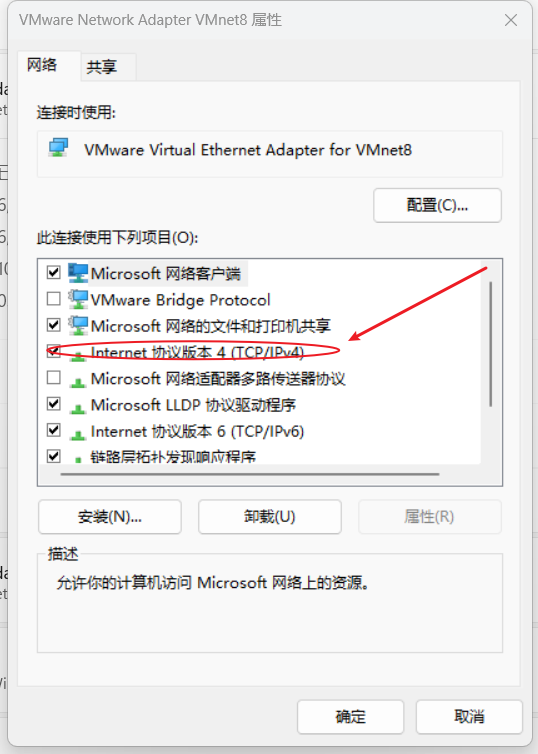

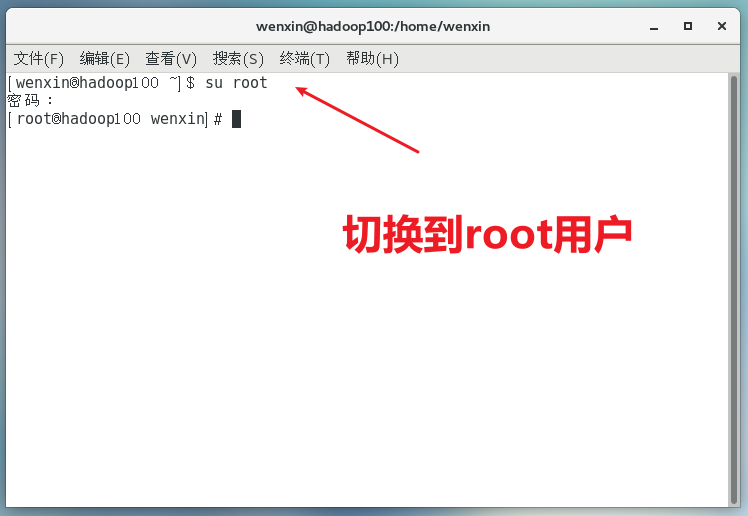
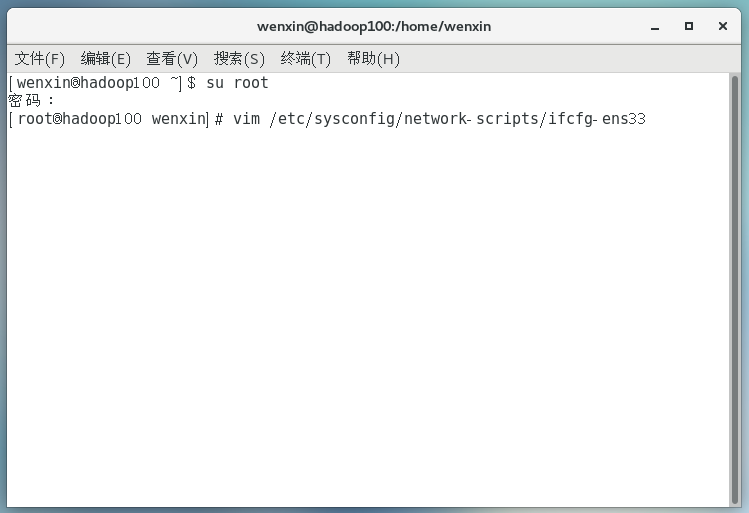
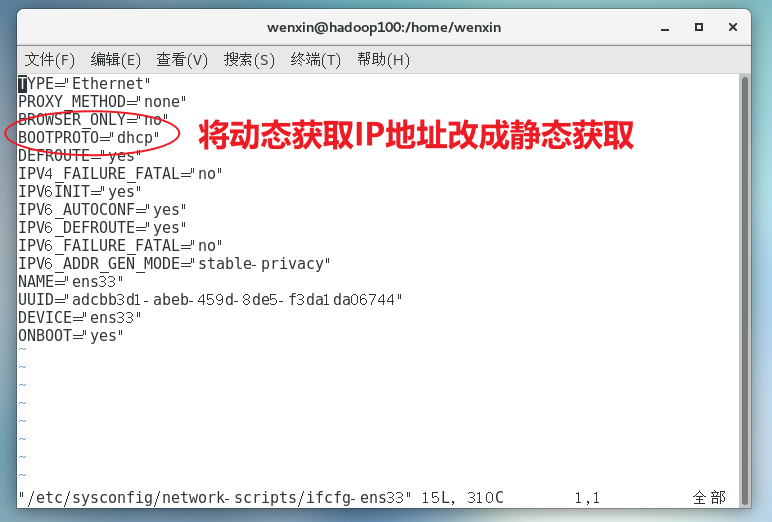
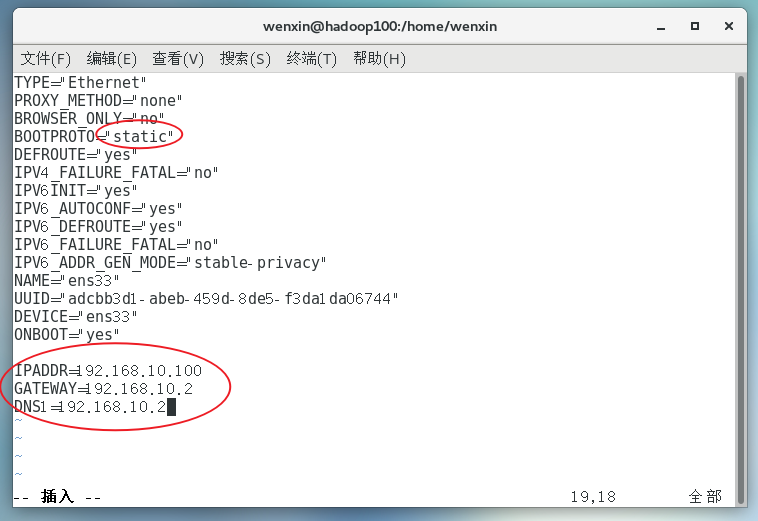
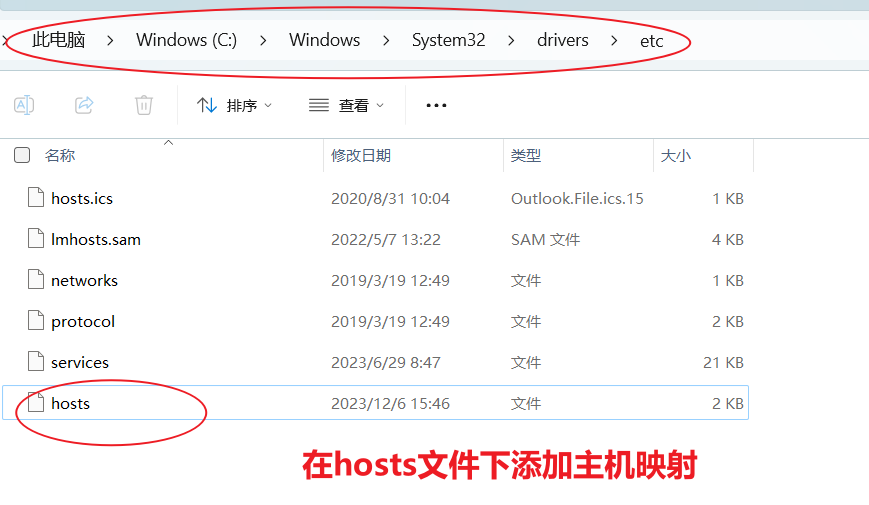
主机名称映射:
配置Linux克隆机主机名称映射hosts文件,打开/etc/hosts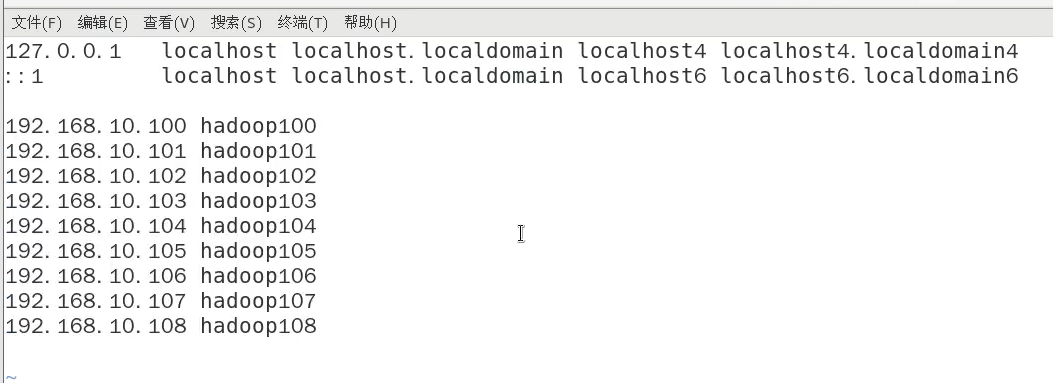
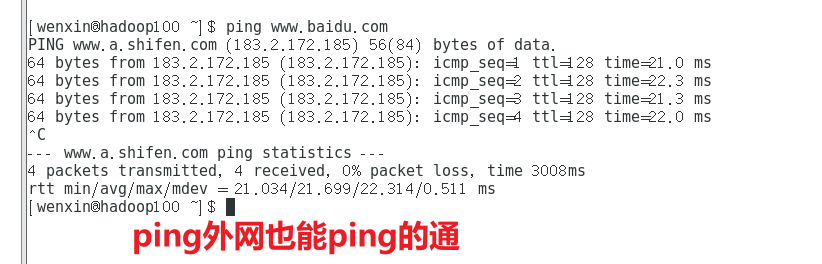
(3)Xshell远程访问

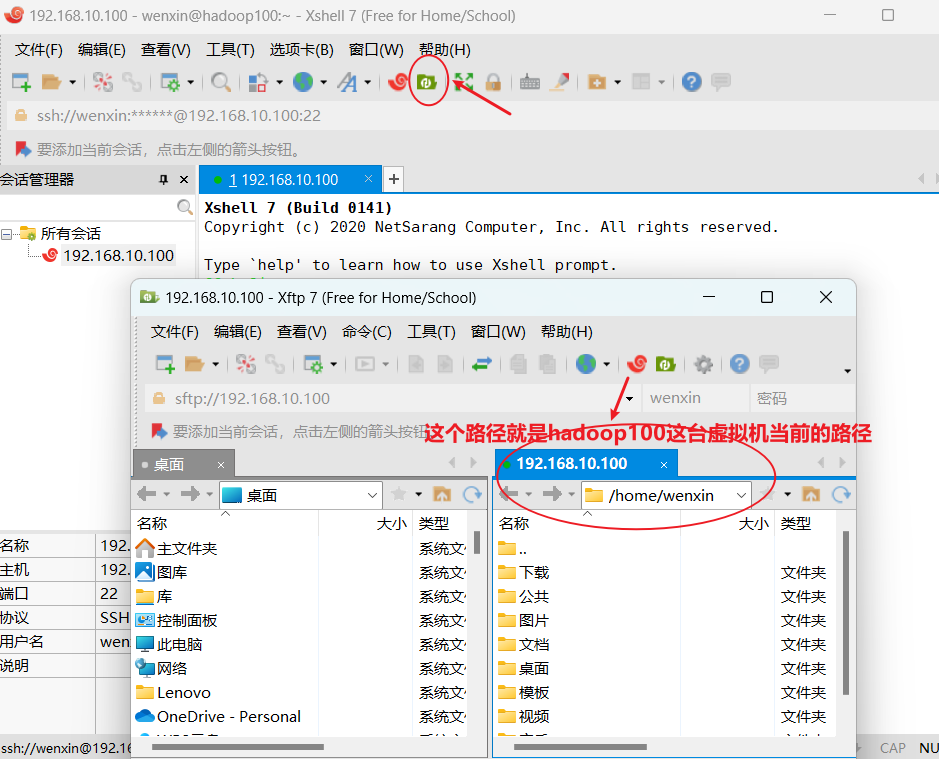
(4)安装epel–release

(5)关闭防火墙,关闭防火墙开机自启

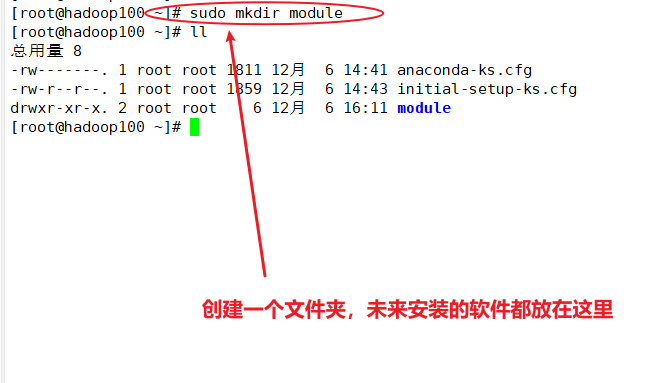
(6)卸载自带JDK

rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
3、克隆三台虚拟机
(1)克隆虚拟机
注意:克隆之前先关机
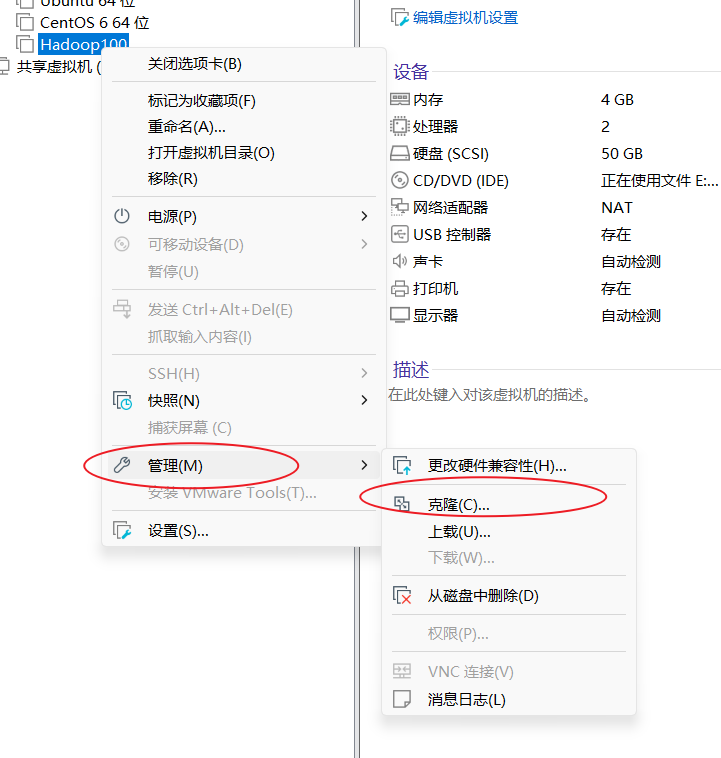
克隆之后需要修改三台虚拟机的主机名称以及IP地址
(2)在hadoop102上安装JDK
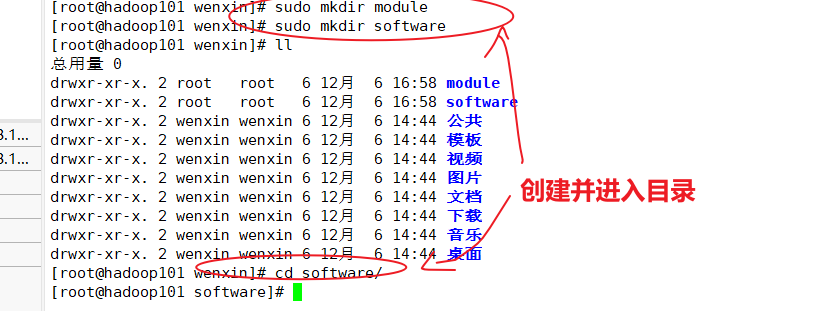
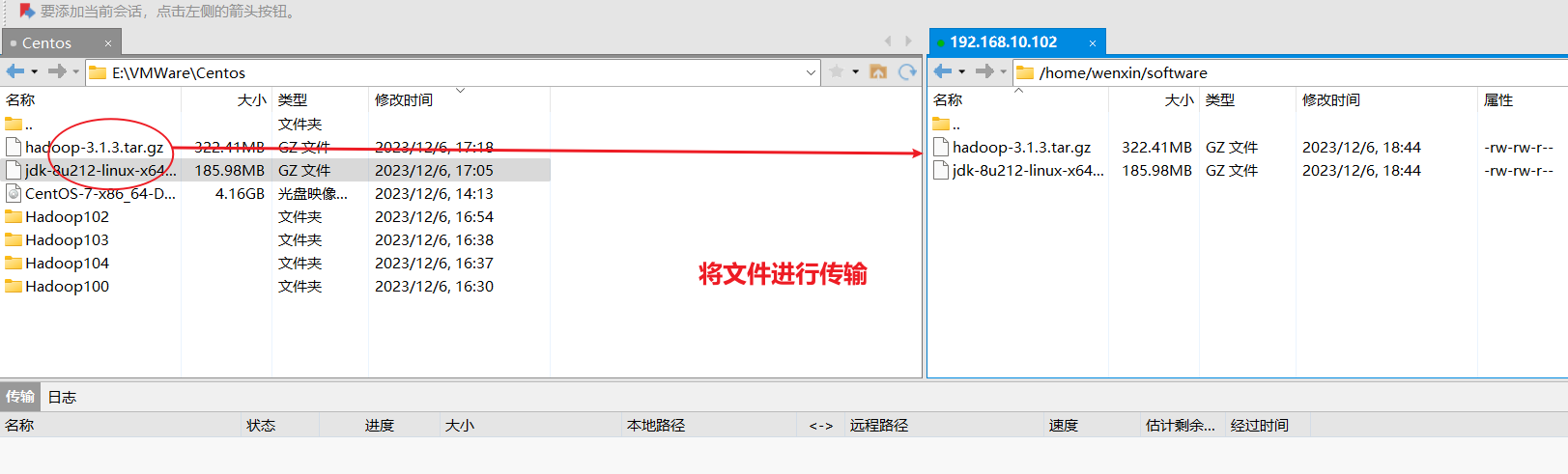
当时遇到一个错误,查阅这篇博客之后解决:xftp传输文件状态错误解决办法

linux退出当前目录使用:cd …
linux查看当前目录所在路径:pwd

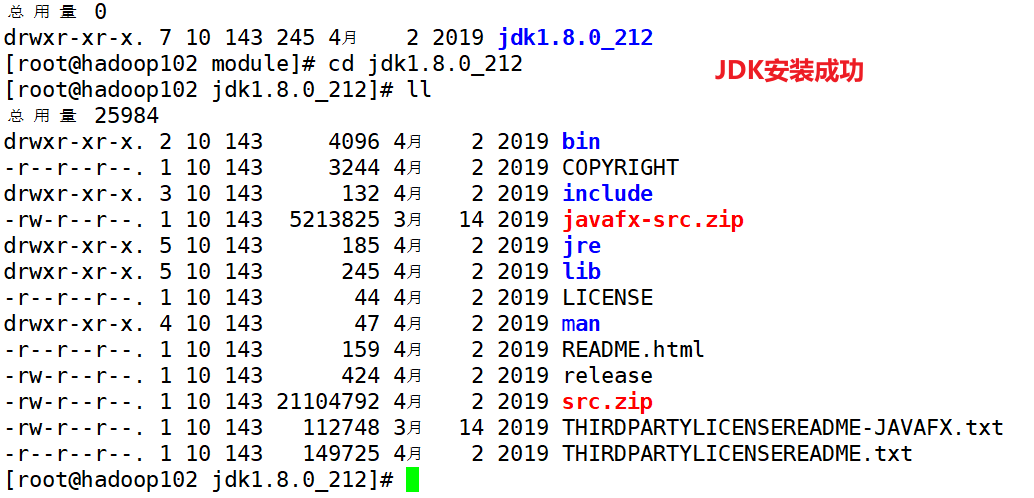
(3)配置JDK环境变量
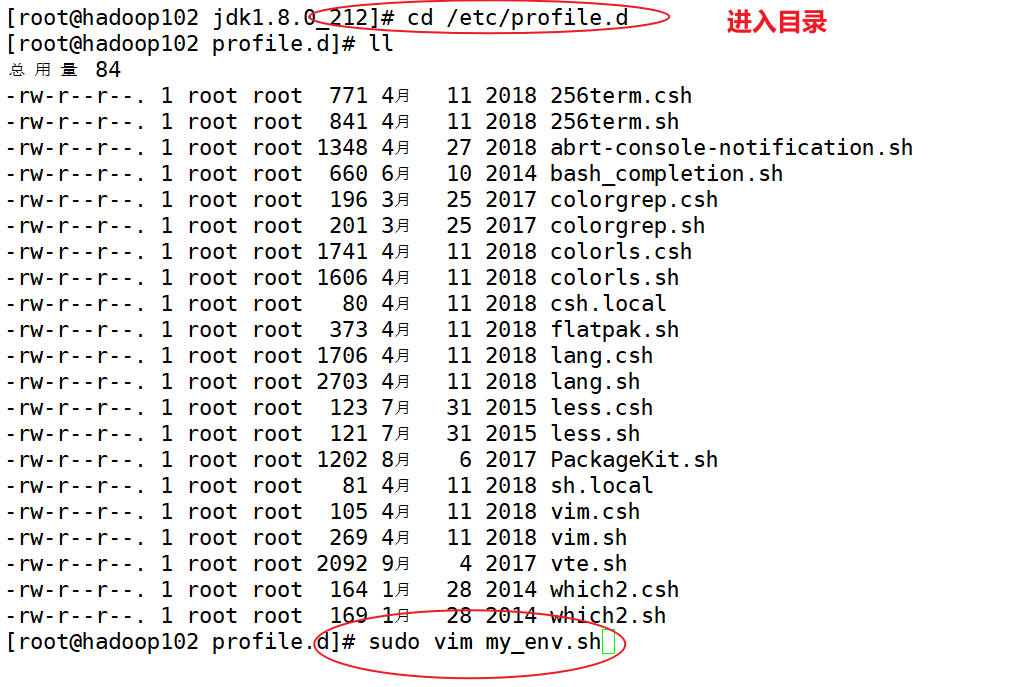
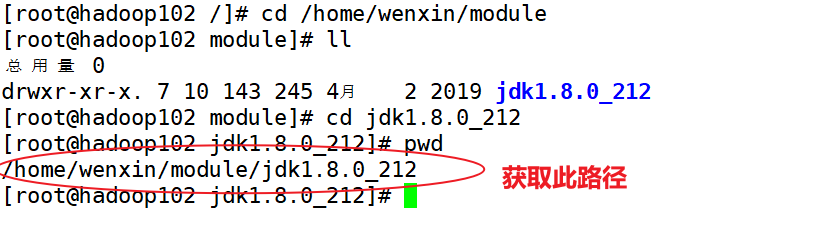

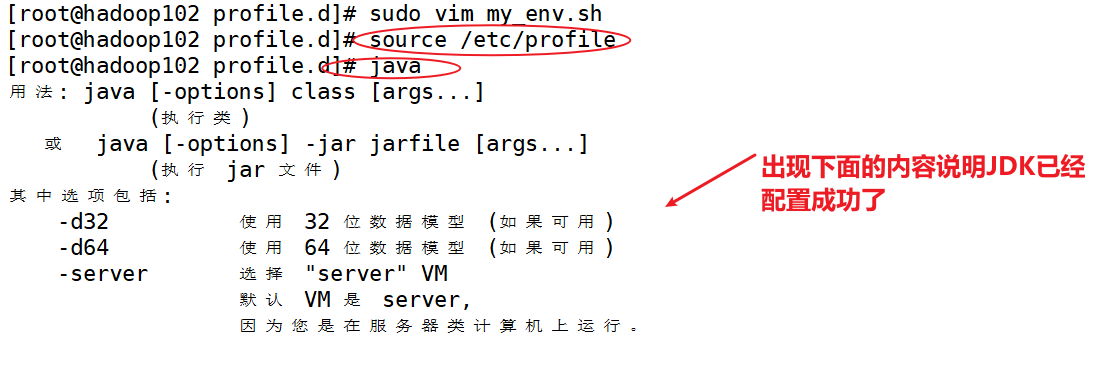
(4)在hadoop102按照hadoop

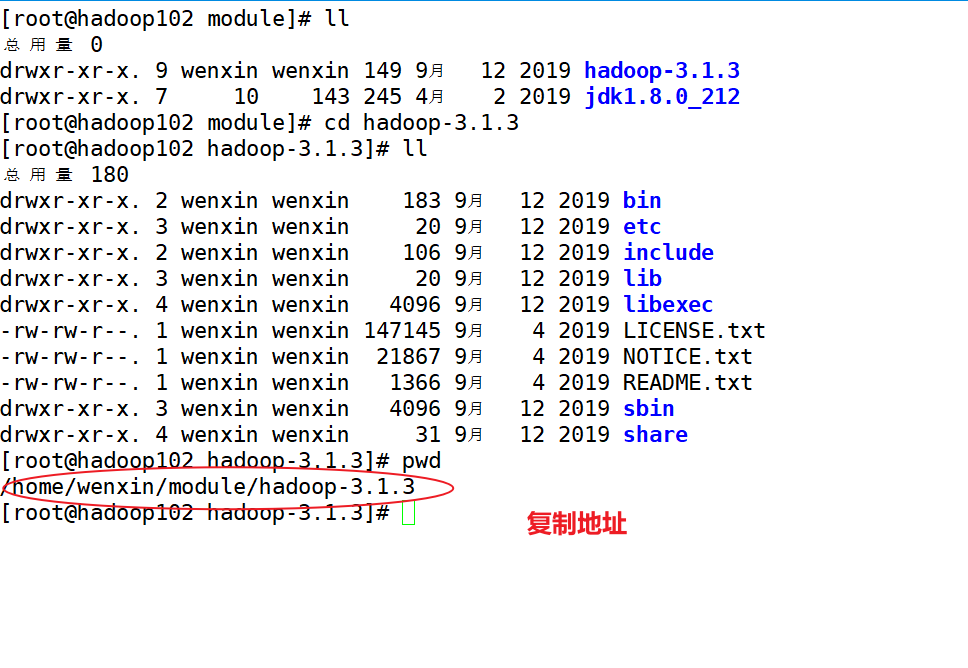
(5)配置hadoop环境变量



原文地址:https://blog.csdn.net/wxfighting/article/details/134794003
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_50062.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!