本文介绍: dd
文章目录
环境启动
启动hadoop图形化界面
cd /opt/server/hadoop-3.1.0/sbin/
./start-dfs.sh
./start-yarn.sh
# 或者
./start-all.sh
启动hive
hive
一、爬取数据
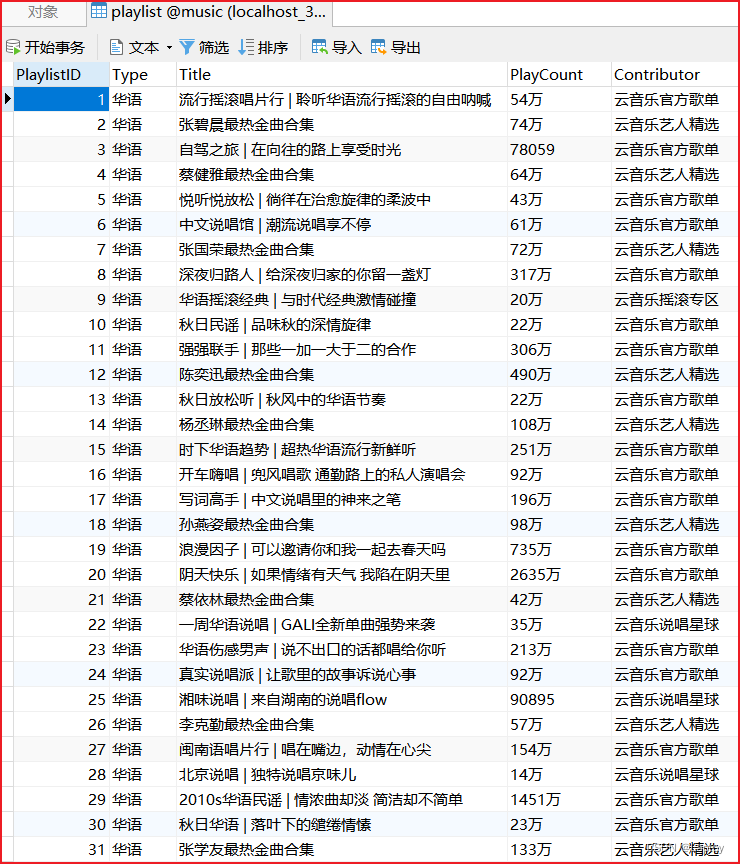
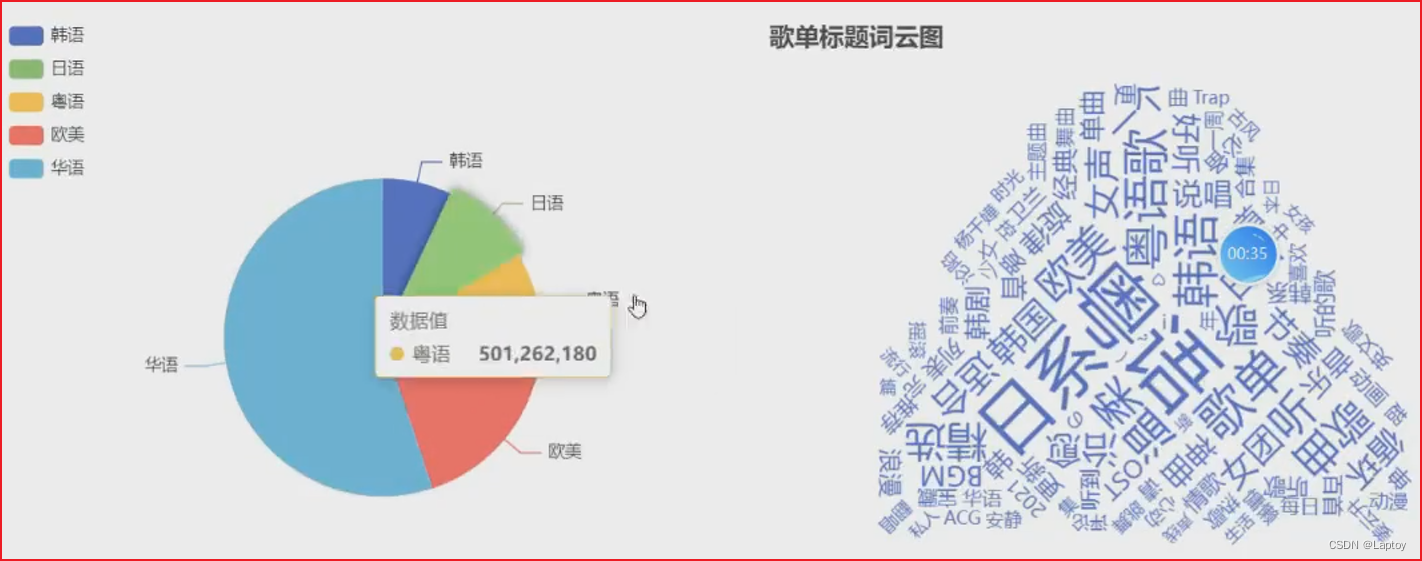
1.1、歌单信息
CREATE TABLE playlist (
PlaylistID INT AUTO_INCREMENT PRIMARY KEY,
Type VARCHAR(255),
Title VARCHAR(255),
PlayCount VARCHAR(255),
Contributor VARCHAR(255)
);
# _*_ coding : utf-8 _*_
# @Time : 2023/11/15 10:26
# @Author : Laptoy
# @File : 01_playlist
# @Project : finalDesign
import requests
import time
from bs4 import BeautifulSoup
import pymysql
db_connection = pymysql.connect(
host="localhost",
user="root",
password="root",
database="music"
)
cursor = db_connection.cursor()
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
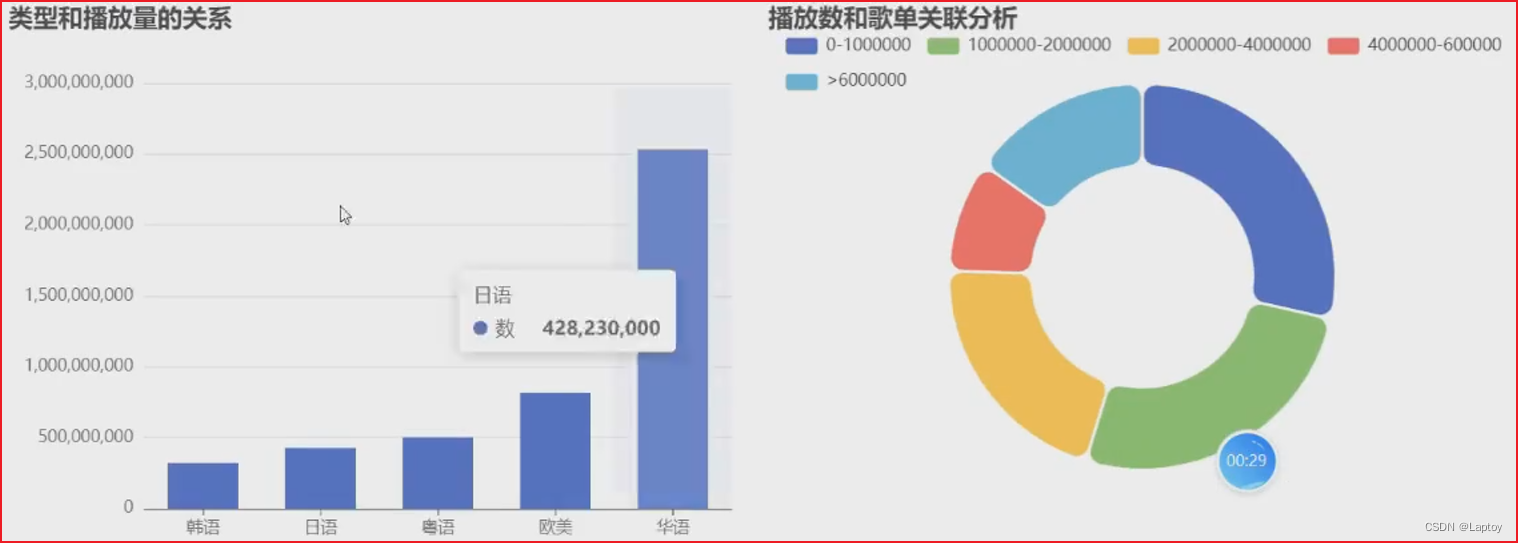
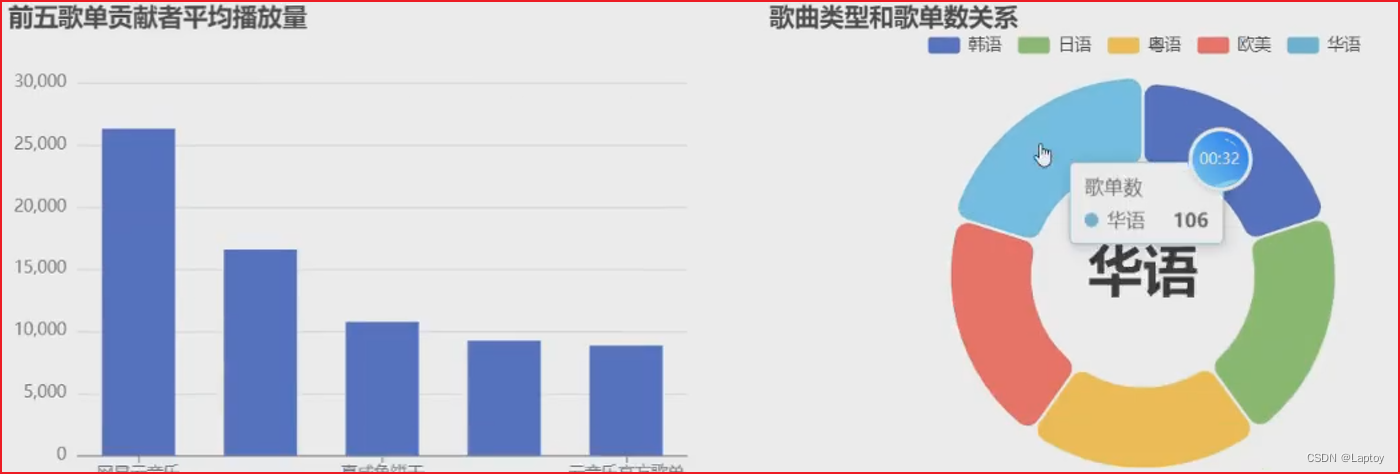
types = ['华语', '欧美', '日语', '韩语', '粤语']
for type in types:
# 按类型获取歌单
for i in range(0, 1295, 35):
url = 'https://music.163.com/discover/playlist/?cat=' + type + '&order=hot&limit=35&offset=' + str(i)
response = requests.get(url=url, headers=headers)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
# 获取包含歌单详情页网址的标签
ids = soup.select('.dec a')
# 获取包含歌单索引页信息的标签
lis = soup.select('#m-pl-container li')
print(len(lis))
print('类型', '标题', '播放量', '歌单贡献者', '歌单链接')
for j in range(len(lis)):
# 标准歌单类型
type = type
# 获取歌单标题,替换英文分割符
title = ids[j]['title'].replace(',', ',')
# 获取歌单播放量
playCount = lis[j].select('.nb')[0].get_text()
# 获取歌单贡献者名字
contributor = lis[j].select('p')[1].select('a')[0].get_text()
# 输出歌单索引页信息
print(type, title, playCount, contributor)
insert_query = "INSERT INTO playlist (Type, Title, PlayCount, Contributor) VALUES (%s, %s, %s, %s)"
playlist_data = (type, title, playCount, contributor)
cursor.execute(insert_query, playlist_data)
db_connection.commit()
time.sleep(0.1)
cursor.close()
db_connection.close()
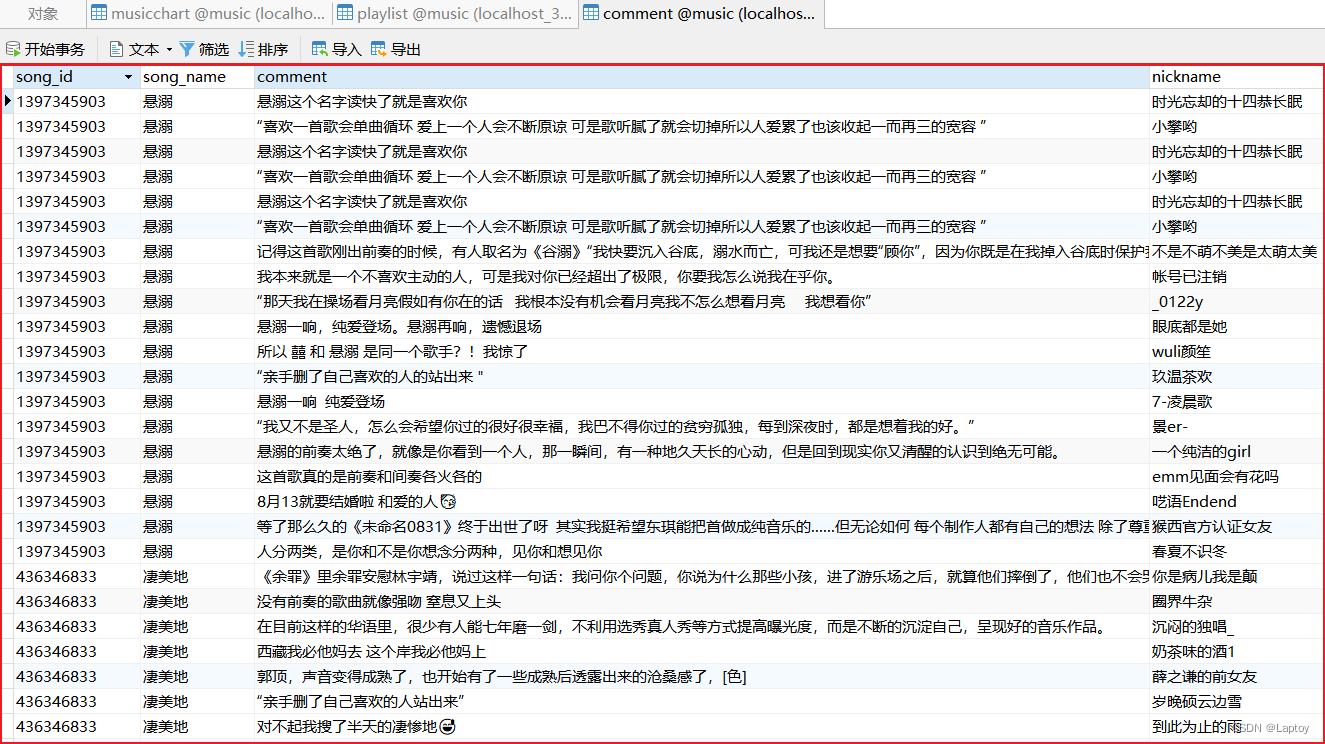
1.2、每首歌前20条评论
CREATE TABLE `comment` (
`song_id` varchar(20),
`song_name` varchar(255),
`comment` varchar(255),
`nickname` varchar(50)
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci ROW_FORMAT = Dynamic;
# _*_ coding : utf-8 _*_
# @Time : 2023/11/15 15:09
# @Author : Laptoy
# @File : ces
# @Project : finalDesign
import requests
from Crypto.Cipher import AES
from lxml import etree
from binascii import b2a_base64
import json
import time
import pymysql
from pymysql.converters import escape_string
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
e = '010001'
f = '00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7'
g = '0CoJUm6Qyw8W8jud'
# 随机值
i = 'vDIsXMJJZqADRVBP'
def get_163():
# 热歌榜URL
toplist_url = 'https://music.163.com/discover/toplist?id=3778678'
response = requests.get(toplist_url, headers=headers)
html = response.content.decode()
html = etree.HTML(html)
namelist = html.xpath("//div[@id='song-list-pre-cache']/ul[@class='f-hide']/li")
# 可选择保存到文件
# f = open('./wangyi_hotcomments.txt',mode='a',encoding='utf-8')
for name in namelist:
song_name = name.xpath('./a/text()')[0]
song_id = name.xpath('./a/@href')[0].split('=')[1]
content = get_hotConmments(song_id)
print(song_name, song_id)
save_mysql(song_id, song_name, content)
# f.writelines(song_id+song_name)
# f.write('n')
# f.write(str(content))
# f.close()
def get_encSecKey():
encSecKey = "516070c7404b42f34c24ef20b659add657c39e9c52125e9e9f7f5441b4381833a407e5ed302cac5d24beea1c1629b17ccb86e0d9d57f6508db5fb7a6df660089ac57b093d19421d386101676a1c8d1e312e099a3463f81fbe91f28211f9eccccfbfc64148fdd65e2b9f5fcf439a865b95fb656e36f75091957f0a1d39ca8ddd3"
return encSecKey
def get_params(data):
first = enconda_params(data, g)
second = enconda_params(first, i)
return second
# 加密params
def enconda_params(data, key):
d = 16 - len(data) % 16
data += chr(d) * d
data = data.encode('utf-8')
aes = AES.new(key=key.encode('utf-8'), IV='0102030405060708'.encode('utf-8'), mode=AES.MODE_CBC)
bs = aes.encrypt(data)
# b64解码
params = b2a_base64(bs).decode('utf-8')
# params = b64decode(bs)
return params
def get_hotConmments(id):
# print(id)
# 提交的信息
data = {
'cursor': '-1',
'offset': '0',
'orderType': '1',
'pageNo': '1',
'pageSize': '20',
'rid': f'R_SO_4_{id}',
'threadId': f'R_SO_4_{id}'
}
post_data = {
'params': get_params(json.dumps(data)),
'encSecKey': get_encSecKey()
}
# 获取评论的URL
song_url = 'https://music.163.com/weapi/comment/resource/comments/get?csrf_token=ce10dc34c626dc6aef3e07c86be16d70'
response = requests.post(url=song_url, data=post_data, headers=headers)
# time.sleep(1)
json_dict = json.loads(response.content)
# print(json_dict)
hotcontent = {}
for content in json_dict['data']['hotComments']:
content_text = content['content']
content_id = content['user']['nickname']
hotcontent[content_id] = content_text
return hotcontent
# 保存到MySQL数据库
def save_mysql(song_id, song_name, content):
connect = pymysql.Connect(
host='localhost',
port=3306,
user='root',
passwd='root',
db='music',
# charset='utf8mb4'
)
cursor = connect.cursor()
# sql = "inster into music_163 velues(%d,'%s','%s','%s')"
sql = """
INSERT INTO comment(song_id, song_name, comment,nickname)
VALUES(%d, '%s', '%s', '%s')
"""
for nikename in content:
data = (int(song_id), escape_string(song_name), escape_string(content[nikename]), escape_string(nikename))
print(data)
cursor.execute(sql % data)
connect.commit()
if __name__ == '__main__':
get_163()
1.3、排行榜
CREATE TABLE `chart` (
`Chart` varchar(255),
`Rank` varchar(255),
`Title` varchar(255),
`Times` varchar(255),
`Singer` varchar(255)
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
# _*_ coding : utf-8 _*_
# @Time : 2023/11/15 14:20
# @Author : Laptoy
# @File : 02_musicChart
# @Project : finalDesign
from selenium import webdriver
from selenium.webdriver.common.by import By
import pymysql
import time
db_connection = pymysql.connect(
host="localhost",
user="root",
password="root",
database="music"
)
cursor = db_connection.cursor()
driver = webdriver.Chrome()
ids = ['19723756', '3779629', '2884035', '3778678']
charts = ['飙升榜', '新歌榜', '原创榜', '热歌榜']
for id, chart in zip(ids, charts):
driver.get('https://music.163.com/#/discover/toplist?id=' + id)
driver.switch_to.frame('contentFrame')
time.sleep(1)
divs = driver.find_elements(By.XPATH, '//*[@class="g-wrap12"]//tr[contains(@id,"1")]')
for div in divs:
# 榜单类型
chart = chart
# 标题
title = div.find_element(By.XPATH, './/div[@class="ttc"]//b').get_attribute('title')
# 排名
rank = div.find_element(By.XPATH, './/span[@class="num"]').text
# 时长
times = div.find_element(By.XPATH, './/span[@class="u-dur "]').text
# 歌手
singer = div.find_element(By.XPATH, './td/div[@class="text"]/span').get_attribute('title')
print(chart, title, rank, times, singer)
insert_query = "INSERT INTO chart(chart, title, rank, times,singer) VALUES (%s, %s, %s, %s, %s)"
chart_data = (chart, title, rank, times, singer)
cursor.execute(insert_query, chart_data)
db_connection.commit()
time.sleep(1)
cursor.close()
db_connection.close()
二、搭建环境
1.1、搭建JAVA
mkdir /opt/tools
mkdir /opt/server
tar -zvxf jdk-8u131-linux-x64.tar.gz -C /opt/server
vim /etc/profile
# 文件末尾增加
export JAVA_HOME=/opt/server/jdk1.8.0_131
export PATH=${JAVA_HOME}/bin:$PATH
source /etc/profile
java -version
1、配置免密登录
vim /etc/hosts
# 文件末尾增加
192.168.88.110 [主机名]
ssh-keygen -t rsa
cd ~/.ssh
cat id_rsa.pub >> authorized_keys
chmod 600 authorized_keys
1.2、配置hadoop
tar -zvxf hadoop-3.1.0.tar.gz -C /opt/server/
# 进入/opt/server/hadoop-3.1.0/etc/hadoop
vim hadoop-env.sh
# 文件添加
export JAVA_HOME=/opt/server/jdk1.8.0_131
vim core-site.xml
<configuration>
<property>
<!--指定 namenode 的 hdfs 协议文件系统的通信地址-->
<name>fs.defaultFS</name>
<value>hdfs://[主机名]:8020</value>
</property>
<property>
<!--指定 hadoop 数据文件存储目录-->
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<!--由于我们这里搭建是单机版本,所以指定 dfs 的副本系数为 1-->
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
vim workers
# 配置所有从属节点的主机名或 IP 地址,由于是单机版本,所以指定本机即可:
server
1、关闭防火墙
# 查看防火墙状态
sudo firewall-cmd --state
# 关闭防火墙:
sudo systemctl stop firewalld
# 禁止开机启动
sudo systemctl disable firewalld
2、初始化
cd /opt/server/hadoop-3.1.0/bin
./hdfs namenode -format
3、配置启动用户
cd /opt/server/hadoop-3.1.0/sbin/
# 编辑start-dfs.sh、stop-dfs.sh,在顶部加入以下内容
# 编辑start-all.sh、stop-all.sh,在顶部加入以下内容
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
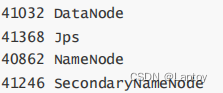
4、启动
cd /opt/server/hadoop-3.1.0/sbin/
./start-dfs.sh
jps
5、访问
192.168.88.110:9870
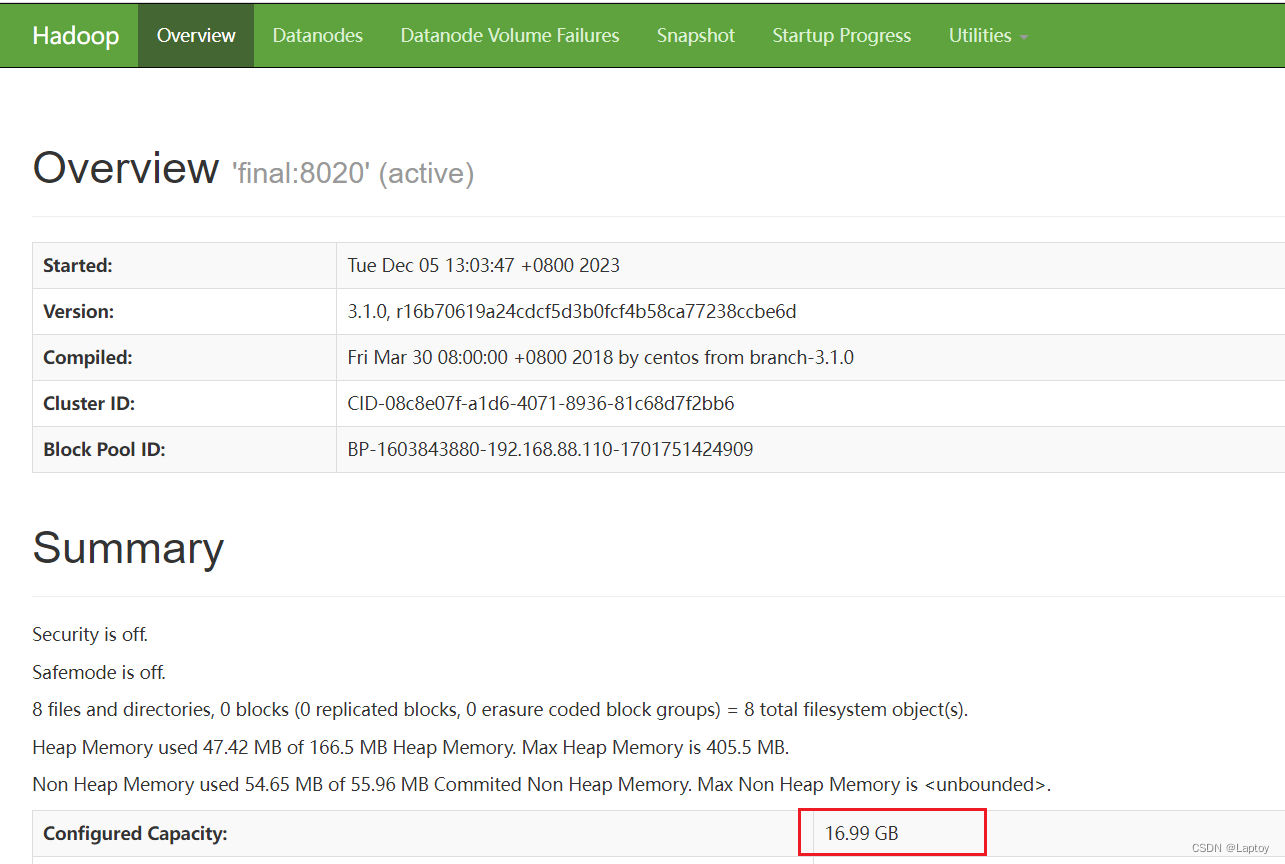
6、配置环境变量方便启动
vim /etc/profile
export HADOOP_HOME=/opt/server/hadoop-3.1.0
export PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
source /etc/profile
1.3、配置Hadoop环境:YARN
# 进入/opt/server/hadoop-3.1.0/etc/hadoop
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
vim yarn-site.xml
<configuration>
<property>
<!--配置 NodeManager 上运行的附属服务。需要配置成 mapreduce_shuffle 后才可
以在Yarn 上运行 MapRedvimuce 程序。-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
cd /opt/server/hadoop-3.1.0/sbin/
# start-yarn.sh stop-yarn.sh在两个文件顶部添加以下内容
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
./start-yarn.sh
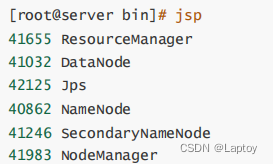

1.4、MYSQL
# 用于存放安装包
mkdir /opt/tools
# 用于存放解压后的文件
mkdir /opt/server
卸载Centos7自带mariadb
# 查找
rpm -qa|grep mariadb
# mariadb-libs-5.5.52-1.el7.x86_64
# 卸载
rpm -e mariadb-libs-5.5.52-1.el7.x86_64 --nodeps
# 创建mysql安装包存放点
mkdir /opt/server/mysql
# 解压
tar xvf mysql-5.7.34-1.el7.x86_64.rpm-bundle.tar -C /opt/server/mysql/
# 安装依赖
yum -y install libaio
yum -y install libncurses*
yum -y install perl perl-devel
# 切换到安装目录
cd /opt/server/mysql/
# 安装
rpm -ivh mysql-community-common-5.7.34-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-5.7.34-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-5.7.34-1.el7.x86_64.rpm
rpm -ivh mysql-community-server-5.7.34-1.el7.x86_64.rpm
#启动mysql
systemctl start mysqld.service
#查看生成的临时root密码
cat /var/log/mysqld.log | grep password

# 登录mysql
mysql -u root -p
Enter password: #输入在日志中生成的临时密码
# 更新root密码 设置为root
set global validate_password_policy=0;
set global validate_password_length=1;
set password=password('root');
grant all privileges on *.* to 'root' @'%' identified by 'root';
# 刷新
flush privileges;
#mysql的启动和关闭 状态查看
systemctl stop mysqld
systemctl status mysqld
systemctl start mysqld
#建议设置为开机自启动服务
systemctl enable mysqld
#查看是否已经设置自启动成功
systemctl list-unit-files | grep mysqld
1.5、HIVE(数据仓库)
# 切换到安装包目录
cd /opt/tools
# 解压到/root/server目录
tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/server/
# 上传mysql-connector-java-5.1.38.jar到下面目录
cd /opt/server/apache-hive-3.1.2-bin/lib
配置文件
cd /opt/server/apache-hive-3.1.2-bin/conf
cp hive-env.sh.template hive-env.sh
vim hive-env.sh
# 加入以下内容
HADOOP_HOME=/opt/server/hadoop-3.1.0
cd /opt/server/apache-hive-3.1.2-bin/conf
vim hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 存储元数据mysql相关配置 /etc/hosts -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value> jdbc:mysql://[主机名]:3306/hive?
createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&chara
cterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
</configuration>
初始化表
cd /opt/server/apache-hive-3.1.2-bin/bin
./schematool -dbType mysql -initSchema
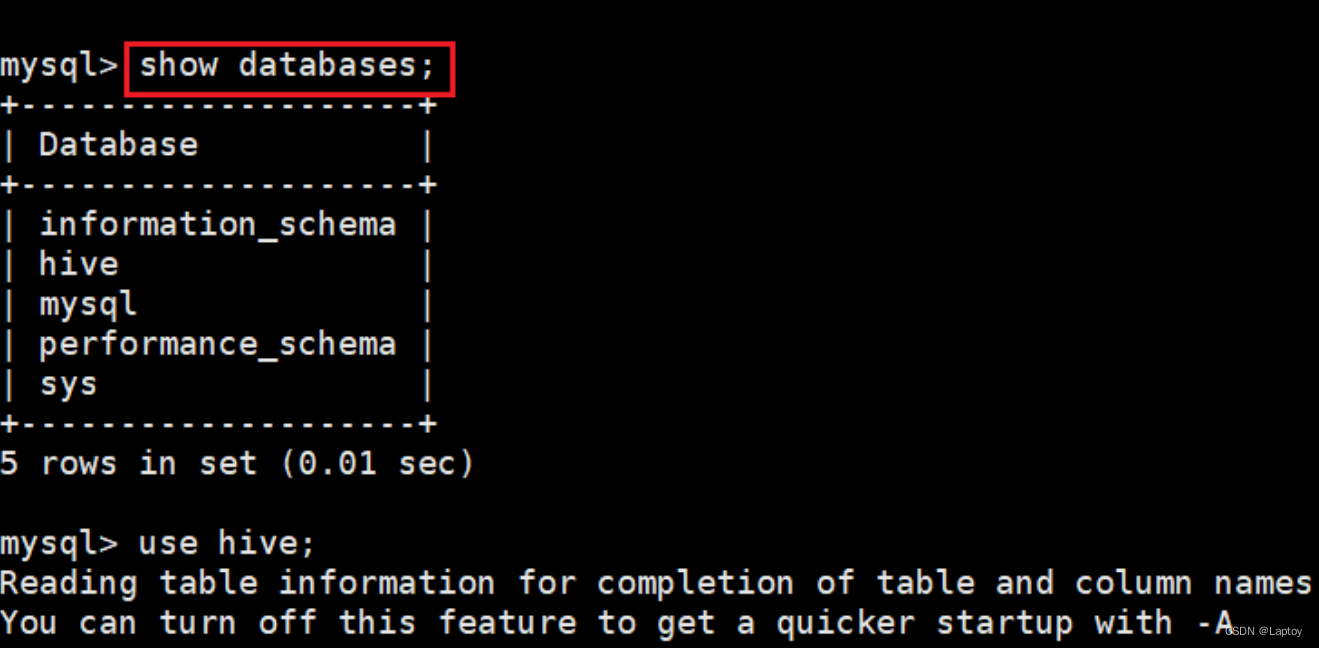
1.6、Sqoop(关系数据库数据迁移)
1、拉取sqoop
# /opt/tools
wget https://archive.apache.org/dist/sqoop/1.4.7/sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /opt/server/
2、配置
cd /opt/server/sqoop-1.4.7.bin__hadoop-2.6.0/conf
cp sqoop-env-template.sh sqoop-env.sh
vim sqoop-env.sh
# 加入以下内容
export HADOOP_COMMON_HOME=/opt/server/hadoop-3.1.0
export HADOOP_MAPRED_HOME=/opt/server/hadoop-3.1.0
export HIVE_HOME=/opt/server/apache-hive-3.1.2-bin
3、加入mysql的jdbc驱动包
cd /opt/server/sqoop-1.4.7.bin__hadoop-2.6.0/lib
# mysql-connector-java-5.1.38.jar
三、hadoop配置内存
修改yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
</property>
</configuration>
重启
cd /opt/server/hadoop-3.1.0/sbin
./stop-all.sh
./start-all.sh
四、导入数据到hive
1、hive创建数据库
create database music;
use music;
2、hive创建数据表
# -- 将数据当做一列放入表中,后续再使用sql进行分割处理
CREATE TABLE chart_content(
content STRING
);
CREATE TABLE playlist_content (
content STRING
);
3、hive加载csv文件进hive表
load data local inpath '/opt/data/chart.csv' into table chart_content;
load data local inpath '/opt/data/playlist.csv' into table playlist;
4、创建表
CREATE TABLE `chart` (
`Chart` string,
`Rank` string,
`Title` string,
`Times` string,
`Singer` string
);
CREATE TABLE `playlist` (
`PlaylistID` string,
`Type` string,
`Title` string,
`PlayCount` string,
`Contributor` string
);
CREATE TABLE playlist (
`PlaylistID` string,
`Type` string,
`Title` string,
`PlayCount` string,
`Contributor` string
)
row format delimited
fields terminated by ',';
5、将数据插入表中去掉”,”
INSERT INTO TABLE `chart`
SELECT
split(content, ',')[0] AS `Chart`,
split(content, ',')[1] AS `Rank`,
split(content, ',')[2] AS `Title`,
split(content, ',')[3] AS `Times`,
split(content, ',')[4] AS `Singer`
FROM `chart_content`;
INSERT INTO TABLE `playlist`
SELECT
split(content, ',')[0] AS `PlaylistID`,
split(content, ',')[1] AS `Type`,
split(content, ',')[2] AS `Title`,
split(content, ',')[3] AS `PlayCount`,
split(content, ',')[4] AS `Contributor`
FROM `playlist_content`;

SELECT
PlaylistID,
Type,
Title,
CAST(PlayCount AS int) AS PlayCount,
Contributor
FROM playlist;
SELECT
REGEXP_REPLACE(Contributor, '"', '')
FROM playlist;
原文地址:https://blog.csdn.net/apple_53947466/article/details/134417437
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_51213.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。