1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
辣椒是一种重要的经济作物,被广泛种植和消费。然而,辣椒的产量预测一直是农业生产中的重要问题。准确地预测辣椒的产量可以帮助农民合理安排种植计划、优化农业资源配置、提高农业生产效益,从而推动农业可持续发展。
传统的辣椒产量预测方法主要依赖于人工经验和统计模型,这些方法往往受限于数据采集的不完整性和主观性,预测精度较低。随着互联网和深度学习技术的快速发展,基于Web和深度学习的辣椒检测产量预测系统成为可能。
首先,基于Web的辣椒检测产量预测系统可以通过互联网收集大量的辣椒生长环境数据和农业管理数据。这些数据包括土壤湿度、温度、光照强度、气象条件等,以及农民的种植管理记录。通过分析这些数据,可以建立辣椒生长环境与产量之间的关系模型,从而实现对辣椒产量的准确预测。
其次,深度学习技术在图像识别和模式识别方面取得了巨大的突破。辣椒的生长过程中,叶片颜色、形状、大小等特征会发生变化,这些特征与辣椒的产量密切相关。基于深度学习的图像识别算法可以从辣椒生长过程中获取的图像中提取这些特征,并通过训练模型实现对辣椒产量的预测。
基于Web和深度学习的辣椒检测产量预测系统具有以下几个重要意义:
-
提高辣椒产量预测的准确性:传统的预测方法受限于数据采集和模型建立的局限性,预测精度较低。基于Web和深度学习的系统可以充分利用大量的数据和强大的模式识别能力,提高辣椒产量预测的准确性。
-
优化农业资源配置:准确地预测辣椒的产量可以帮助农民合理安排种植计划,避免资源的浪费和过度投入。农民可以根据预测结果调整施肥、浇水、病虫害防治等农业管理措施,提高农业生产效益。
-
推动农业可持续发展:辣椒产量的准确预测可以帮助农民提前做好市场调研和销售计划,避免产量过剩或供不应求的情况发生。合理的产量预测可以平衡供需关系,稳定市场价格,促进农业可持续发展。
-
拓展农业科技应用:基于Web和深度学习的辣椒检测产量预测系统是农业科技与互联网、人工智能的结合,为农业科技应用拓展了新的领域。该系统的研究和应用可以为其他作物的产量预测提供借鉴和参考,推动农业科技的创新和发展。
综上所述,基于Web和深度学习的辣椒检测产量预测系统具有重要的研究背景和意义。通过充分利用互联网和深度学习技术,该系统可以提高辣椒产量预测的准确性,优化农业资源配置,推动农业可持续发展,拓展农业科技应用。这对于提高农业生产效益、保障粮食安全、促进农村经济发展具有重要的实际意义。
2.图片演示



3.视频演示
基于Web和深度学习的辣椒检测产量预测系统_哔哩哔哩_bilibili
4.数据集的采集&标注和整理
图片的收集
首先,我们需要收集所需的图片。这可以通过不同的方式来实现,例如使用现有的公开数据集LJDatasets。
labelImg是一个图形化的图像注释工具,支持VOC和YOLO格式。以下是使用labelImg将图片标注为VOC格式的步骤:
(1)下载并安装labelImg。
(2)打开labelImg并选择“Open Dir”来选择你的图片目录。
(3)为你的目标对象设置标签名称。
(4)在图片上绘制矩形框,选择对应的标签。
(5)保存标注信息,这将在图片目录下生成一个与图片同名的XML文件。
(6)重复此过程,直到所有的图片都标注完毕。
由于YOLO使用的是txt格式的标注,我们需要将VOC格式转换为YOLO格式。可以使用各种转换工具或脚本来实现。

下面是一个简单的方法是使用Python脚本,该脚本读取XML文件,然后将其转换为YOLO所需的txt格式。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
classes = [] # 初始化为空列表
CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('./label_xml%s.xml' % (image_id), encoding='UTF-8')
out_file = open('./label_txt%s.txt' % (image_id), 'w') # 生成txt格式文件
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
classes.append(cls) # 如果类别不存在,添加到classes列表中
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + 'n')
xml_path = os.path.join(CURRENT_DIR, './label_xml/')
# xml list
img_xmls = os.listdir(xml_path)
for img_xml in img_xmls:
label_name = img_xml.split('.')[0]
print(label_name)
convert_annotation(label_name)
print("Classes:") # 打印最终的classes列表
print(classes) # 打印最终的classes列表
整理数据文件夹结构
我们需要将数据集整理为以下结构:
-----data
|-----train
| |-----images
| |-----labels
|
|-----valid
| |-----images
| |-----labels
|
|-----test
|-----images
|-----labels
确保以下几点:
所有的训练图片都位于data/train/images目录下,相应的标注文件位于data/train/labels目录下。
所有的验证图片都位于data/valid/images目录下,相应的标注文件位于data/valid/labels目录下。
所有的测试图片都位于data/test/images目录下,相应的标注文件位于data/test/labels目录下。
这样的结构使得数据的管理和模型的训练、验证和测试变得非常方便。
模型训练
Epoch gpu_mem box obj cls labels img_size
1/200 20.8G 0.01576 0.01955 0.007536 22 1280: 100%|██████████| 849/849 [14:42<00:00, 1.04s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:14<00:00, 2.87it/s]
all 3395 17314 0.994 0.957 0.0957 0.0843
Epoch gpu_mem box obj cls labels img_size
2/200 20.8G 0.01578 0.01923 0.007006 22 1280: 100%|██████████| 849/849 [14:44<00:00, 1.04s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:12<00:00, 2.95it/s]
all 3395 17314 0.996 0.956 0.0957 0.0845
Epoch gpu_mem box obj cls labels img_size
3/200 20.8G 0.01561 0.0191 0.006895 27 1280: 100%|██████████| 849/849 [10:56<00:00, 1.29it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|███████ | 187/213 [00:52<00:00, 4.04it/s]
all 3395 17314 0.996 0.957 0.0957 0.0845
5.核心代码讲解
5.1 export.py
def export_formats():
# YOLOv5 export formats
x = [
['PyTorch', '-', '.pt', True, True],
['TorchScript', 'torchscript', '.torchscript', True, True],
['ONNX', 'onnx', '.onnx', True, True],
['OpenVINO', 'openvino', '_openvino_model', True, False],
['TensorRT', 'engine', '.engine', False, True],
['CoreML', 'coreml', '.mlmodel', True, False],
['TensorFlow SavedModel', 'saved_model', '_saved_model', True, True],
['TensorFlow GraphDef', 'pb', '.pb', True, True],
['TensorFlow Lite', 'tflite', '.tflite', True, False],
['TensorFlow Edge TPU', 'edgetpu', '_edgetpu.tflite', False, False],
['TensorFlow.js', 'tfjs', '_web_model', False, False],
['PaddlePaddle', 'paddle', '_paddle_model', True, True],]
return pd.DataFrame(x, columns=['Format', 'Argument', 'Suffix', 'CPU', 'GPU'])
def try_export(inner_func):
# YOLOv5 export decorator, i..e @try_export
inner_args = get_default_args(inner_func)
def outer_func(*args, **kwargs):
prefix = inner_args['prefix']
try:
with Profile() as dt:
f, model = inner_func(*args, **kwargs)
LOGGER.info(f'{prefix} export success ✅ {dt.t:.1f}s, saved as {f} ({file_size(f):.1f} MB)')
return f, model
except Exception as e:
LOGGER.info(f'{prefix} export failure ❌ {dt.t:.1f}s: {e}')
return None, None
return outer_func
@try_export
def export_torchscript(model, im, file, optimize, prefix=colorstr('TorchScript:')):
# YOLOv5 TorchScript model export
LOGGER.info(f'n{prefix} starting export with torch {torch.__version__}...')
f = file.with_suffix('.torchscript')
ts = torch.jit.trace(model, im, strict=False)
d = {"shape": im.shape, "stride": int(max(model.stride)), "names": model.names}
extra_files = {'config.txt': json.dumps(d)} # torch._C.ExtraFilesMap()
if optimize: # https://pytorch.org/tutorials/recipes/mobile_interpreter.html
optimize_for_mobile(ts)._save_for_lite_interpreter(str(f), _extra_files=extra_files)
else:
ts.save(str(f), _extra_files=extra_files)
return f, None
@try_export
def export_onnx(model, im, file, opset, dynamic, simplify, prefix=colorstr('ONNX:')):
# YOLOv5 ONNX export
check_requirements('onnx>=1.12.0')
import onnx
LOGGER.info(f'n{prefix} starting export with onnx {onnx.__version__}...')
f = file.with_suffix('.onnx')
output_names = ['output0', 'output1'] if isinstance(model, SegmentationModel) else ['output0']
if dynamic:
dynamic = {'images': {0: 'batch', 2: 'height', 3: 'width'}} # shape(1,3,640,640)
if isinstance(model, SegmentationModel):
dynamic['output0'] = {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
dynamic['output1'] = {0: 'batch', 2: 'mask_height', 3: 'mask_width'} # shape(1,32,160,160)
elif isinstance(model, DetectionModel):
dynamic['output0'] = {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
torch.onnx.export(
model.cpu() if dynamic else model, # --dynamic only compatible with cpu
im.cpu() if dynamic else im,
f,
verbose=False,
opset_version=opset,
do_constant_folding=True, # WARNING: DNN inference with torch>=1.12 may require do_constant_folding=False
input_names=['images'],
output_names=output_names,
dynamic_axes=dynamic or None)
# Checks
model_onnx = onnx.load(f) # load onnx model
onnx.checker.check_model(model_onnx) # check onnx model
# Metadata
d = {'stride': int(max(model.stride)), 'names': model.names}
for k, v in d.items():
meta = model_onnx.metadata_props.add()
meta.key, meta.value = k, str(v)
onnx.save(model_onnx, f)
# Simplify
if simplify:
try:
cuda = torch.cuda.is_available()
check_requirements(('onnxruntime-gpu' if cuda else 'onnxruntime', 'onnx-simplifier>=0.4.1'))
import onnxsim
LOGGER.info(f'{prefix} simplifying with onnx-simplifier {onnxsim.__version__}...')
model_simp, check = onnxsim.simplify(f, check=True)
assert check, 'assert check failed'
onnx.save(model_simp, f)
except Exception as e:
LOGGER.info(f'{prefix} simplifier failure {e}')
return f, None
export.py是一个用于将YOLOv5 PyTorch模型导出为其他格式的程序文件。它支持导出的格式包括PyTorch、TorchScript、ONNX、OpenVINO、TensorRT、CoreML、TensorFlow SavedModel、TensorFlow GraphDef、TensorFlow Lite、TensorFlow Edge TPU、TensorFlow.js和PaddlePaddle。通过运行export.py文件,可以根据命令行参数指定要导出的格式,以及模型权重文件的路径。导出的模型文件将保存在指定的输出路径中。
export.py文件中定义了一些辅助函数,如export_torchscript和export_onnx,用于实际执行导出操作。这些函数使用PyTorch和ONNX库来导出模型,并将导出的模型保存为相应的文件格式。
export.py文件还包含一些用于解析命令行参数、检查环境要求和打印日志的辅助函数。这些函数确保导出过程顺利进行,并提供必要的信息和反馈。
使用export.py文件时,可以通过命令行参数指定要导出的模型权重文件和要导出的格式。导出的模型文件将保存在当前目录或指定的输出目录中。导出过程中会打印出导出的进度和结果。
此外,export.py文件还提供了一个示例用法和一些与TensorFlow.js相关的说明。示例用法演示了如何使用导出的模型进行推理。与TensorFlow.js相关的说明介绍了如何在TensorFlow.js中使用导出的模型。
总之,export.py文件是一个用于将YOLOv5 PyTorch模型导出为其他格式的工具文件,提供了丰富的导出选项和灵活的使用方式。
5.2 web.py
import cv2
import torch
import torch.backends.cudnn as cudnn
from models.common import DetectMultiBackend
from utils.augmentations import letterbox
from utils.general import (non_max_suppression, scale_coords)
from utils.torch_utils import select_device, time_sync
import numpy as np
class ObjectDetector:
def __init__(self, weights='./best.pt', data='./data/coco128.yaml', device='', half=False, dnn=False):
self.device = select_device(device)
self.model = self.load_model(weights, data, half, dnn)
self.names = self.model.module.names if hasattr(self.model, 'module') else self.model.names
def load_model(self, weights, data, half, dnn):
device = select_device(self.device)
model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data)
stride, names, pt, jit, onnx, engine = model.stride, model.names, model.pt, model.jit, model.onnx, model.engine
half &= (pt or jit or onnx or engine) and device.type != 'cpu'
if pt or jit:
model.model.half() if half else model.model.float()
return model
def detect_objects(self, img, imgsz=(640, 640), conf_thres=0.25, iou_thres=0.05, max_det=1000, classes=None, agnostic_nms=False, augment=False, half=False):
cal_detect = []
im = letterbox(img, imgsz, self.model.stride, self.model.pt)[0]
im = im.transpose((2, 0, 1))[::-1]
im = np.ascontiguousarray(im)
im = torch.from_numpy(im).to(self.device)
im = im.half() if half else im.float()
im /= 255
if len(im.shape) == 3:
im = im[None]
pred = self.model(im, augment=augment)
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
for i, det in enumerate(pred):
if len(det):
det[:, :4] = scale_coords(im.shape[2:], det[:, :4], img.shape).round()
for *xyxy, conf, cls in reversed(det):
c = int(cls)
label = f'{self.names[c]}'
cal_detect.append([label, xyxy, float(conf)])
return cal_detect
......
这个程序文件是一个使用Remi库创建的GUI应用程序。它包含了一个名为MyApp的类,该类继承自Remi的App类。该应用程序的主要功能是显示一个界面,其中包含一个图像、一个计数器、一个文本输入框、一个标签和一个滑块。用户可以通过点击图像、选择文件、滑动滑块等操作与应用程序进行交互。应用程序还包含一些其他功能,如定时器、文件上传和下载等。此外,该应用程序还包含一个名为run的函数,用于运行目标检测模型并返回检测结果。
5.3 init.py
以下是封装为类后的代码:
import paddleocr
from .paddleocr import *
class PaddleOCR:
def __init__(self):
self.__version__ = paddleocr.VERSION
self.__all__ = ['PaddleOCR', 'PPStructure', 'draw_ocr', 'draw_structure_result', 'save_structure_res','download_with_progressbar']
这个程序文件是一个Python模块的初始化文件,文件名为__init__.py。该文件包含了一些版权信息和许可证,以及导入了paddleocr模块和一些函数和类。导入的函数和类包括PaddleOCR、PPStructure、draw_ocr、draw_structure_result、save_structure_res和download_with_progressbar。此外,该文件还定义了两个变量__version__和__all__,其中__version__存储了paddleocr的版本号,__all__列出了该模块对外暴露的函数和类的名称。
5.4 modelscommon.py
import math
import torch
import torch.nn as nn
class Conv(nn.Module):
# Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
class DWConv(Conv):
# Depth-wise convolution
def __init__(self, c1, c2, k=1, s=1, d=1, act=True): # ch_in, ch_out, kernel, stride, dilation, activation
super().__init__(c1, c2, k, s, g=math.gcd(c1, c2), d=d, act=act)
class DWConvTranspose2d(nn.ConvTranspose2d):
# Depth-wise transpose convolution
def __init__(self, c1, c2, k=1, s=1, p1=0, p2=0): # ch_in, ch_out, kernel, stride, padding, padding_out
super().__init__(c1, c2, k, s, p1, p2, groups=math.gcd(c1, c2))
class TransformerLayer(nn.Module):
# Transformer layer https://arxiv.org/abs/2010.11929 (LayerNorm layers removed for better performance)
def __init__(self, c, num_heads):
super().__init__()
self.q = nn.Linear(c, c, bias=False)
self.k = nn.Linear(c, c, bias=False)
self.v = nn.Linear(c, c, bias=False)
self.ma = nn.MultiheadAttention(embed_dim=c, num_heads=num_heads)
self.fc1 = nn.Linear(c, c, bias=False)
self.fc2 = nn.Linear(c, c, bias=False)
def forward(self, x):
x = self.ma(self.q(x), self.k(x), self.v(x))[0] + x
x = self.fc2(self.fc1(x)) + x
return x
class TransformerBlock(nn.Module):
# Vision Transformer https://arxiv.org/abs/2010.11929
def __init__(self, c1, c2, num_heads, num_layers):
super().__init__()
self.conv = None
if c1 != c2:
self.conv = Conv(c1, c2)
self.linear = nn.Linear(c2, c2) # learnable position embedding
self.tr = nn.Sequential(*(TransformerLayer(c2, num_heads) for _ in range(num_layers)))
self.c2 = c2
def forward(self, x):
if self.conv is not None:
x = self.conv(x)
b, _, w,
这个程序文件是YOLOv5的一个模块,主要包含了一些常用的模块和函数。文件中定义了一些卷积层、池化层、残差块等常用的神经网络模块,以及一些辅助函数和工具函数。这些模块和函数可以用于构建YOLOv5模型的各个组件,如backbone、neck和head等。
5.5 modelsexperimental.py
class Sum(nn.Module):
def __init__(self, n, weight=False):
super().__init__()
self.weight = weight
self.iter = range(n - 1)
if weight:
self.w = nn.Parameter(-torch.arange(1.0, n) / 2, requires_grad=True)
def forward(self, x):
y = x[0]
if self.weight:
w = torch.sigmoid(self.w) * 2
for i in self.iter:
y = y + x[i + 1] * w[i]
else:
for i in self.iter:
y = y + x[i + 1]
return y
class MixConv2d(nn.Module):
def __init__(self, c1, c2, k=(1, 3), s=1, equal_ch=True):
super().__init__()
n = len(k)
if equal_ch:
i = torch.linspace(0, n - 1E-6, c2).floor()
c_ = [(i == g).sum() for g in range(n)]
else:
b = [c2] + [0] * n
a = np.eye(n + 1, n, k=-1)
a -= np.roll(a, 1, axis=1)
a *= np.array(k) ** 2
a[0] = 1
c_ = np.linalg.lstsq(a, b, rcond=None)[0].round()
self.m = nn.ModuleList([
nn.Conv2d(c1, int(c_), k, s, k // 2, groups=math.gcd(c1, int(c_)), bias=False) for k, c_ in zip(k, c_)])
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU()
def forward(self, x):
return self.act(self.bn(torch.cat([m(x) for m in self.m], 1)))
class Ensemble(nn.ModuleList):
def __init__(self):
super().__init__()
def forward(self, x, augment=False, profile=False, visualize=False):
y = [module(x, augment, profile, visualize)[0] for module in self]
y = torch.cat(y, 1)
return y, None
def attempt_load(weights, device=None, inplace=True, fuse=True):
from models.yolo import Detect, Model
model = Ensemble()
for w in weights if isinstance(weights, list) else [weights]:
ckpt = torch.load(attempt_download(w), map_location='cpu')
ckpt = (ckpt.get('ema') or ckpt['model']).to(device).float()
if not hasattr(ckpt, 'stride'):
ckpt.stride = torch.tensor([32.])
if hasattr(ckpt, 'names') and isinstance(ckpt.names, (list, tuple)):
ckpt.names = dict(enumerate(ckpt.names))
model.append(ckpt.fuse().eval() if fuse and hasattr(ckpt, 'fuse') else ckpt.eval())
for m in model.modules():
t = type(m)
if t in (nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU, Detect, Model):
m.inplace = inplace
if t is Detect and not isinstance(m.anchor_grid, list):
delattr(m, 'anchor_grid')
setattr(m, 'anchor_grid', [torch.zeros(1)] * m.nl)
elif t is nn.Upsample and not hasattr(m, 'recompute_scale_factor'):
m.recompute_scale_factor = None
if len(model) == 1:
return model[-1]
print(f'Ensemble created with {weights}n')
for k in 'names', 'nc', 'yaml':
setattr(model, k, getattr(model[0], k))
model.stride = model[torch.argmax(torch.tensor([m.stride.max() for m in model])).int()].stride
assert all(model[0].nc == m.nc for m in model), f'Models have different class counts: {[m.nc for m in model]}'
return model
这个程序文件是YOLOv5的实验模块。文件中定义了几个自定义的模块和函数。
-
Sum类:实现了多个层的加权求和。可以选择是否应用权重。
-
MixConv2d类:实现了混合的深度卷积。可以选择是否使用相同的通道数。
-
Ensemble类:模型的集合,可以同时处理多个模型的输出。
-
attempt_load函数:加载模型权重。可以加载单个模型或多个模型的集合。
该文件还导入了其他模块和函数,如utils.downloads模块和models.yolo模块。
总体来说,这个程序文件实现了YOLOv5的一些实验模块和加载模型权重的功能。
5.6 modelstf.py
import tensorflow as tf
from tensorflow import keras
class TFBN(keras.layers.Layer):
# TensorFlow BatchNormalization wrapper
def __init__(self, w=None):
super().__init__()
self.bn = keras.layers.BatchNormalization(
beta_initializer=keras.initializers.Constant(w.bias.numpy()),
gamma_initializer=keras.initializers.Constant(w.weight.numpy()),
moving_mean_initializer=keras.initializers.Constant(w.running_mean.numpy()),
moving_variance_initializer=keras.initializers.Constant(w.running_var.numpy()),
这是一个使用TensorFlow和Keras实现的YOLOv5模型的程序文件。它包含了一些自定义的层,如TFBN、TFPad、TFConv等,用于构建YOLOv5模型的各个组件。该文件还包含了TFDetect类,用于进行目标检测。程序中还包含了一些用于训练和推理的函数。
6.系统整体结构
整体功能和构架概述:
该项目是一个基于Web和深度学习的辣椒检测产量预测系统。它使用YOLOv5模型进行目标检测,并提供了一个Web界面供用户进行交互。系统的主要功能包括上传图片、进行目标检测、显示检测结果、计算产量预测等。
该项目的代码结构如下:
- export.py:将YOLOv5模型导出为其他格式的工具文件。
- web.py:使用Remi库创建的GUI应用程序,提供了一个图形界面供用户进行交互。
- init.py:模块的初始化文件,定义了一些导入的模块和函数。
- models目录:包含了YOLOv5模型的相关代码。
- utils目录:包含了一些辅助函数和工具类,用于模型训练、推理和日志记录等。
下面是每个文件的功能概述:
| 文件路径 | 功能 |
|---|---|
| export.py | 将YOLOv5模型导出为其他格式的工具文件 |
| web.py | 使用Remi库创建的GUI应用程序,提供图形界面供用户进行交互 |
| init.py | 模块的初始化文件,定义了一些导入的模块和函数 |
| modelscommon.py | 包含了一些常用的模块和函数,用于构建YOLOv5模型的各个组件 |
| modelsexperimental.py | 包含了YOLOv5的实验模块和加载模型权重的功能 |
| modelstf.py | 使用TensorFlow和Keras实现的YOLOv5模型的程序文件 |
| modelsyolo.py | 包含了YOLOv5模型的定义和相关函数 |
| models_init_.py | 模块的初始化文件,定义了一些导入的模块和函数 |
| utilsactivations.py | 包含了一些激活函数的定义和相关函数 |
| utilsaugmentations.py | 包含了一些数据增强的函数和类 |
| utilsautoanchor.py | 包含了自动锚框生成的函数和类 |
| utilsautobatch.py | 包含了自动批次大小调整的函数和类 |
| utilscallbacks.py | 包含了一些回调函数的定义和相关函数 |
| utilsdataloaders.py | 包含了数据加载器的定义和相关函数 |
| utilsdownloads.py | 包含了文件下载的函数和相关函数 |
| utilsgeneral.py | 包含了一些通用的辅助函数和工具函数 |
| utilsloss.py | 包含了一些损失函数的定义和相关函数 |
| utilsmetrics.py | 包含了一些评估指标的定义和相关函数 |
| utilsplots.py | 包含了一些绘图函数的定义和相关函数 |
| utilstorch_utils.py | 包含了一些与PyTorch相关的辅助函数和工具函数 |
| utilstriton.py | 包含了与Triton Inference Server相关的辅助函数和工具函数 |
| utils_init_.py | 模块的初始化文件,定义了一些导入的模块和函数 |
| utilsawsresume.py | 包含了AWS上的模型恢复功能的函数和类 |
| utilsaws_init_.py | 模块的初始化文件,定义了一些导入的模块和函数 |
| utilsflask_rest_apiexample_request.py | 包含了Flask REST API的示例请求的函数和类 |
| utilsflask_rest_apirestapi.py | 包含了Flask REST API的定义和相关函数 |
| utilsloggers_init_.py | 模块的初始化文件,定义了一些导入的模块和函数 |
| utilsloggersclearmlclearml_utils.py | 包含了ClearML日志记录工具的辅助函数和工具函数 |
| utilsloggersclearmlhpo.py | 包含了ClearML的超参数优化功能的函数和类 |
| utilsloggersclearml_init_.py | 模块的初始化文件,定义了一些导入的模块和函数 |
| utilsloggerscometcomet_utils.py | 包含了Comet日志记录工具的辅助函数和工具函数 |
| utilsloggerscomethpo.py | 包含了Comet的超参数优化功能的函数和类 |
| utilsloggerscomet_init_.py | 模块的初始化文件,定义了一些导入的模块和函数 |
| utilsloggerswandblog_dataset.py | 包含了WandB日志记录工具的数据集记录功能的函数和类 |
| utilsloggerswandbsweep.py | 包含了WandB的超参数优化功能的函数和类 |
| utilsloggerswandbwandb_utils.py | 包含了WandB日志记录工具的辅助函数和工具函数 |
| utilsloggerswandb_init_.py | 模块的初始化文件,定义了一些导入的模块和函数 |
| utilssegmentaugmentations.py | 包含了图像分割任务的数据增强函数和类 |
| utilssegmentdataloaders.py | 包含了图像分割任务的数据加载器的定义和相关函数 |
| utilssegmentgeneral.py | 包含了图像分割任务的一些通用辅助函数和工具函数 |
| utilssegmentloss.py | 包含了图像分割任务的损失函数的定义和相关函数 |
| utilssegmentmetrics.py | 包含了图像分割任务的评估指标的定义和相关函数 |
| utilssegmentplots.py | 包含了图像分割任务的绘图函数的定义和相关函数 |
| utilssegment_init_.py | 模块的初始化文件,定义了一些导入的模块和函数 |
7.YOLOv5模型
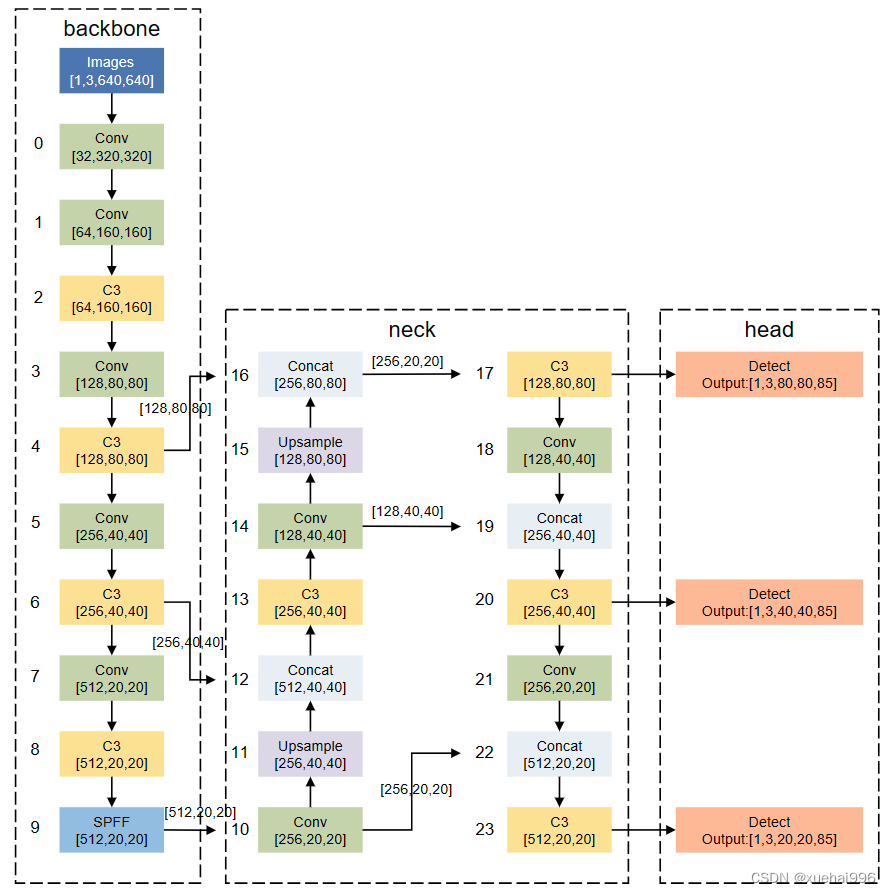
YOLO[15]系列网络模型是最为经典的one-stage算法,在目标检测的网络里面,它是在工业领域使用最多的网络模型。YOLOv5网络模型在继承了原有YOLO网络模型优点的基础上,具有更优的检测精度和更快的推理速度。模型的整体结构如图1所示。YOLOv5网络结构由输入端(Input)、Backbone、Neck、Head 组件组成。各部分完成的主要功能,所述如下:
(1)Input: YOLOv5采用了YOLOv4中的 Mosaic数据增强方法来丰富数据集,降低硬件需求,从而减少了GPU的使用。此外,自适应锚框计算功能被嵌入到整个训练代码中,可以根据需要自行调节开关,同时也实现了自适应图片缩放,这有助于提高目标检测的推理速度。
(2) Backbone: Focus模块将输入的图片数据分成四份,每一份数据相当于进行了2倍下采样,然后将这四份数据进行拼接,得到一个尺寸缩小一半的新特征图。最后,通过卷积操作将信息进行融合,并改变特征图的通道数。这种方法的优点是能够最大程度地减少信息损失和计算量,同时增加了难样本和数据的多样性。
(3)Neck:在 YOLOv5网络模型中,颈部网络主要负责对主干网络提取的特征进行增强处理,以提高后续预测的精度。原始的FPN结构采用自顶向下的特征融合方式来处理目标检测领域中的多尺度变化问题,已经在许多模型中得到了广泛应用。但是,如果仅使用FPN结构来融合上下文信息,则无法实现上层信息与底层信息的交流。因此,在FPN 的基础上,YOLOv5网络还加入了PAN结构,引入了一条自下而上的信息流,充分实现了网络上下信息流的融合,从而提高了网络的检测能力。
(4)Head: YOLOv5采用损失函数CIOU-Loss,可以将一些遮挡重叠的目标准确识别出来。
8.训练结果分析
本实验训练过程在Ubuntul8.0、CUDA11.0环境下进行,GPU配置:NVIDIA GeForce RTX 4090,24GB显存,调用GPU进行训练。所有实验训练参数设置:输入图片大小为640×640
优化器采用带动量的SGD优化器,初始学习率设置为0.001、批大小为16,共训练200轮。检测结果如图所示:

由测试结果可知,经过改进的网络识别准确度获得较大提高,从图(a)和图(b)两张图片中可以看出,改进后的CM-YOLO 网络的Map比原始YOLOv5s网络有所提升,如在有叶子遮挡的情况下,原始YOLOv5s网络识别目标框的Map为0.52,如图(a)所示,CM-YOLO模型的Map为0.82,如图(b)所示。因此CM-YOLO 网络目标识别框的位置更加精准。
通过实验结果比较原始YOLOv5s模型与CM-YOLO模型对于辣椒果实目标检测识别的效果,从准确率Precision,平均精度(mAP),召回率Recall对算法进行比较,比较结果如表所示,具体地。
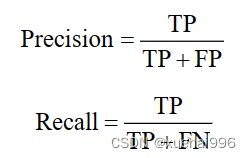
TP表示实际为正样本且被分类器正确预测为正样本的样本数量,FP表示实际为负样本但被分类器错误地预测为正样本的样本数量,FN表示实际为正样本但被分类器错误地预测为负样本的样本数量。Precision表示分类器正确预测为正样本的样本数量占分类器预测为正样本的所有样本数量的比例,Recall表示分类器正确预测为正样本的样本数量占所有实际为正样本的样本数量的比例。

由表1可以看出,基于CM-YOLO的辣椒检测平均精度和召回率更高,能够较好地完成辣椒检测任务。图是原始YOLOv5模型与CM-YOLO模型特征可视化对比,由图可以看出,CM-YOLO模型提取的辣椒线条更加明显。

9.系统整合

10.参考文献
[1] 朱智惟, 单建华, 余贤海, 等. 基于 YOLOv5s 的番茄采摘机器人目标检测技术[J]. 传感器与微统, 2023, 42(6):
129-132. https://doi.org/10.13873/J.1000-9787(2023)06-0129-04
[2] 赵敬, 王全有, 褚幼晖, 等. 农业采摘机器人发展分析及前景展望[J]. 农机使用与维修, 2023(6): 63-70.
https://doi.org/10.14031/j.cnki.njwx.2023.06.019
[3] 高帅, 刘永华, 高菊玲, 等. 基于 YOLOv3 算法与 3D 视觉的农业采摘机器人目标识别与定位研究[J]. 中国农机
化学报, 2022, 43(12): 178-183. https://doi.org/10.13733/j.jcam.issn.2095-5553.2022.12.026
[4] 李亚涛. 茶叶采摘机器人的视觉检测与定位技术研究[D]: [博士学位论文]. 杭州: 浙江理工大学, 2022.
https://doi.org/10.27786/d.cnki.gzjlg.2022.000006
[5] 魏天宇, 柳天虹, 张善文, 等. 基于改进 YOLOv5s 的辣椒采摘机器人识别定位方法[J]. 扬州大学学报(自然科学
版), 2023, 26(1): 61-69. https://doi.org/10.19411/j.1007-824x.2023.01.010
[6] 刘丽娟, 窦佩佩, 王慧. 自然环境下重叠与遮挡苹果图像识别方法研究[J]. 中国农机化学报, 2021, 42(6):
174-181. https://doi.org/10.13733/j.jcam.issn.2095-5553.2021.06.27
[7] Whittaker, D.E., Miles, G.R., Mitchell, O.D. and Gaultney, L. (1987) Fruit Location in a Partially Occluded Image.
Transactions of the ASAE, 30, 591-596. https://doi.org/10.13031/2013.30444
[8] Gongal, A., et al. (2016) Apple Crop-Load Estimation with Over-the-Row Machine Vision System. Computers and
Electronics in Agriculture, 120, 26-35. https://doi.org/10.1016/j.compag.2015.10.022
[9] 李杰. 结合改进注意力机制的 YOLO 目标检测算法[J]. 计算机时代, 2023(7): 108-113.
https://doi.org/10.16644/j.cnki.cn33-1094/tp.2023.07.025
[10] Liu, W., et al. (2016) SSD: Single Shot MultiBox Detector. In: Leibe, B., Matas, J., Sebe, N. and Welling, M., Eds.,
Computer Vision—ECCV, Springer International Publishing, Berlin, 21-37.
[11] Mehta, S.S., Ton, C., Asundi, S. and Burks, T.F. (2017) Multiple Camera Fruit Localization Using a Particle Filter.
Computers and Electronics in Agriculture, 142, 139-154. https://doi.org/10.1016/j.compag.2017.08.007
[12] Nyarko, E.K., Vidović, I., Radočaj, K. and Cupec, R. (2018) A Nearest Neighbor Approach for Fruit Recognition in
原文地址:https://blog.csdn.net/xuehai996/article/details/134808095
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_51395.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!