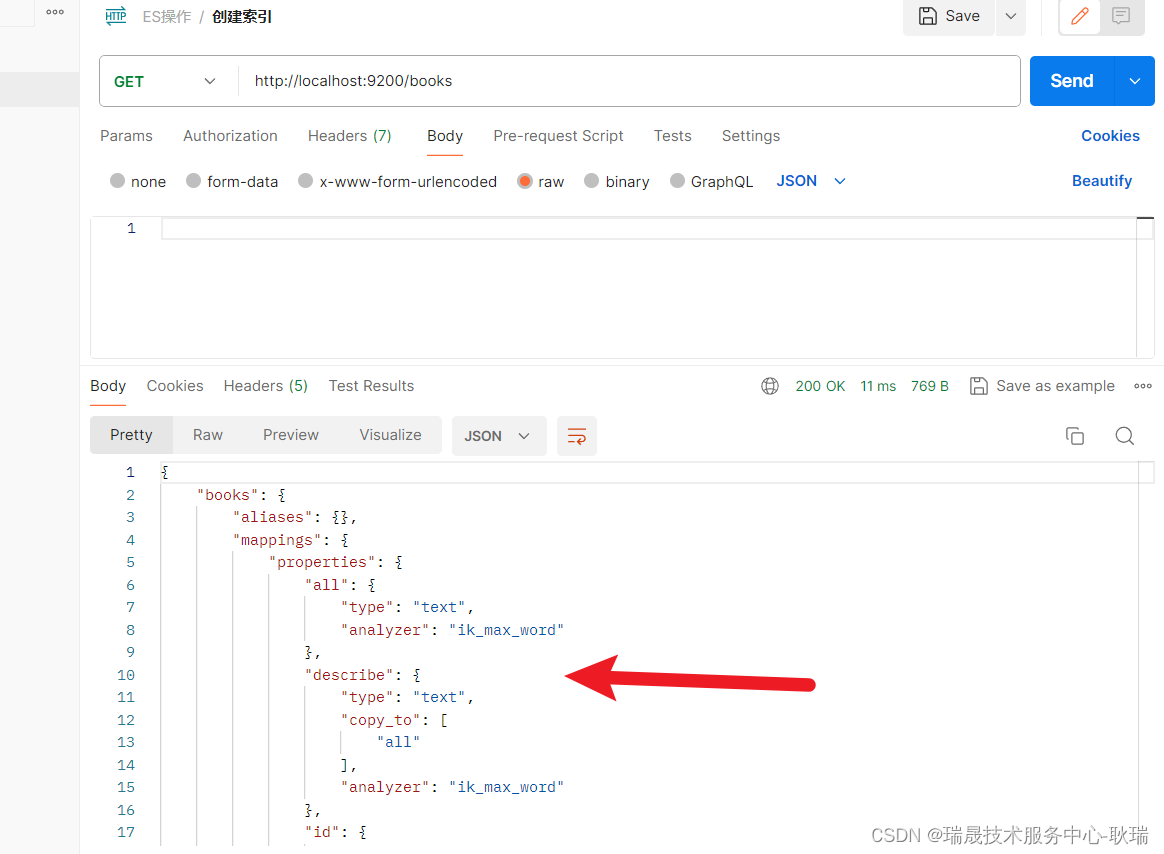
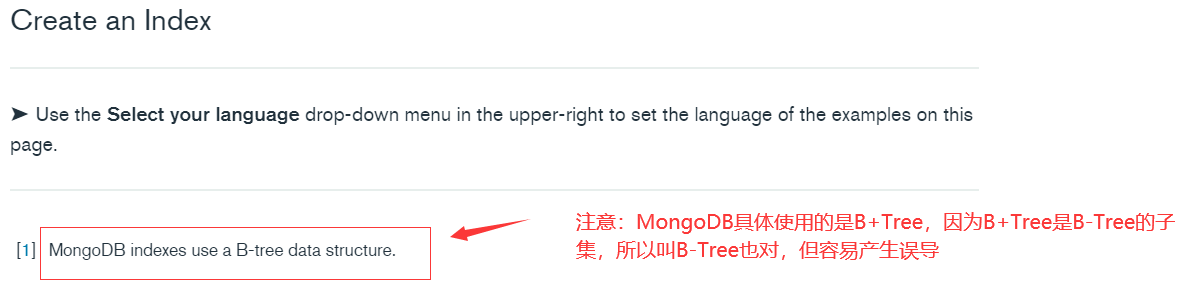
本文介绍: Hbase如何解决非索引查询速度慢的问题?原因:Hbase以Rowkey作为唯一索引现象:只要查询条件不是Rowkey前缀,不走索引解决:构建二级索引思想:自己建rowkey索引表,通过走两次索引来代替全表扫描步骤问题:不同查询条件需要不同索引表,维护原表数据与索引数据同步问题解决方案一:手动管理:自己建表、自己写入数据【原表、索引表】方案二:自己开发协处理器:协处理器的开发成本非常高方案三:第三方工具:PhoenixPhoenix支持哪几种索引,各自的区别和实现原理是什么?
Flume+Kafka+Hbase+Flink+FineBI的实时综合案例
01:课程回顾
02:课程目标
- 目标
- 架构
- 要求
03:案例需求
-
目标:了解案例的背景及需求
-
实施
-
小结
- 了解案例的背景及需求
原文地址:https://blog.csdn.net/xianyu120/article/details/133805789
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_5181.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。