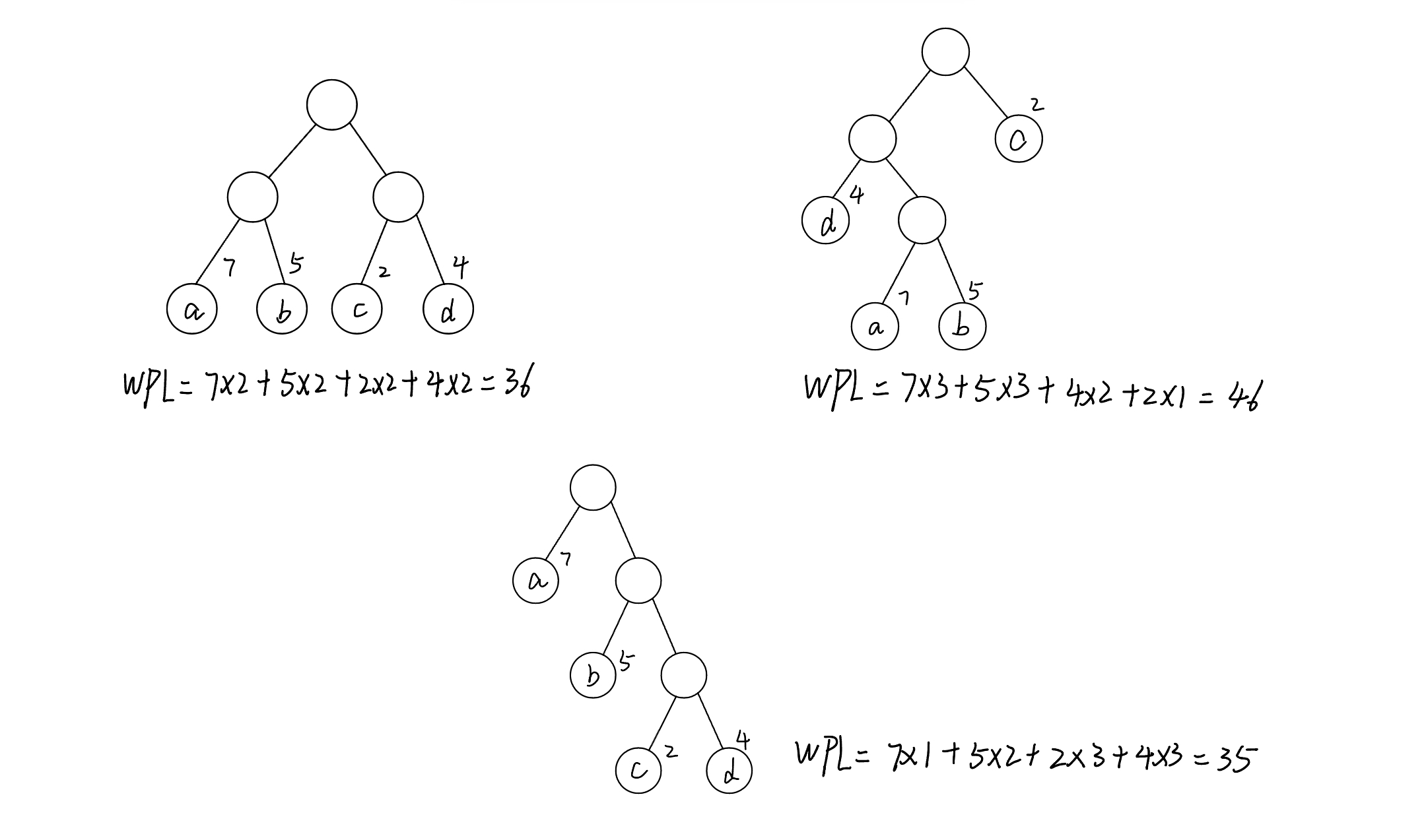
本文介绍: 分类决策树算法详解以及确定最优划分点例题详解
1、介绍
① 定义
分类决策树通过树形结构来模拟决策过程,决策树由结点和有向边组成。结点有两种类型:内部结
点和叶结点。内部结点表示一个特征或属性,叶子节点表示一个类。
② 生成过程
用决策树分类,从根结点开始,对样本的某一特征进行测试,根据测试结果,将样本分配到其他子
结点;这时,每一个子结点对应着该特征的一个取值,如此递归地对样本进行分配,直至达到叶结
点。最后将实例分到叶结点的类中。
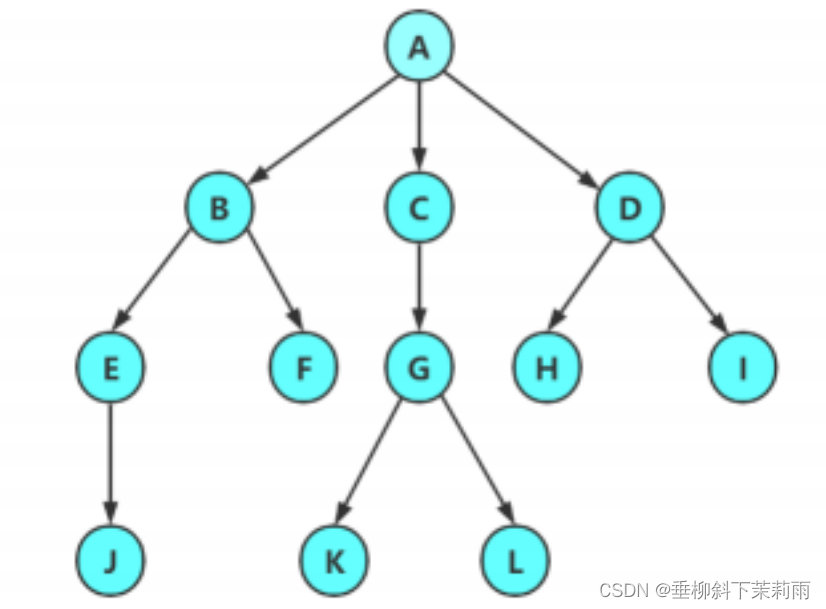
③ 示意图

2、特征选择–信息增益或信息增益比
(1)信息增益
① 熵的定义
② 信息增益算法

③ 例题:对于上述表所给的训练数据集,根据信息增益准则选择最优特征。



(2)信息增益比

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。